内存分析简介
在这个系列的原文博客文章中,你将学习如何收集有关程序与内存交互的高层次信息。这个过程通常被称为内存分析。内存分析帮助你理解应用程序随时间变化的内存使用情况,并帮助你构建程序行为的正确心理模型。以下是它可以回答的一些问题:
- 程序的总内存消耗是多少,以及它随时间如何变化?
- 程序何时何地进行堆分配?
- 哪些代码位置分配了最大量的内存?
- 程序每秒访问多少内存?
当开发者谈论内存消耗时,他们通常指的是堆使用情况。实际上,堆是大多数应用程序中最大的内存消费者,因为它容纳了所有动态分配的对象。但堆并不是唯一的内存消费者。为了完整性,让我们提及其他内存消费者:
- 栈:应用程序中帧栈使用的内存。应用程序中的每个线程都有自己的栈内存空间。通常,栈的大小只有几MB,如果超出限制,应用程序将崩溃。总的栈内存消耗与系统中运行的线程数量成正比。
- 代码:用于存储应用程序及其库的代码(指令)的内存。在大多数情况下,它对内存消耗的贡献不大,但也有例外。例如,Clang C++编译器和Chrome浏览器拥有庞大的代码库,它们的二进制文件中有数十MB的代码段。
接下来,我们将介绍内存使用(memory usage)和内存足迹(memory footprint)或者翻译成内存占用这两个术语,并看看如何对它们进行分析。
注: 主要是通过工具分析内存使用情况,尽量利用局部性原理:时间局部性和空间局部性,提高性能。
1. 内存使用和足迹
内存使用通常由虚拟内存大小(Virtual Memory Size, VSZ)和常驻集大小(Resident Set Size, RSS)来描述。VSZ包括进程可以访问的所有内存,例如栈、堆、用于编码可执行文件指令的内存,以及来自链接的共享库的指令,包括被交换到磁盘的内存。另一方面,RSS衡量分配给进程并实际驻留在RAM中的内存量。因此,RSS不包括被交换出去的内存或进程从未触及过的内存。此外,RSS不包括未加载到内存中的共享库的内存。
考虑一个例子。进程A有200K的栈和堆分配,其中100K驻留在主内存中,其余的被交换出去或未被使用。它有一个500K的二进制文件,其中只有400K被触及。进程A链接了2500K的共享库,并且只有1000K加载到了主内存中。
VSZ: 200K + 500K + 2500K = 3200K
RSS: 100K + 400K + 1000K = 1500K
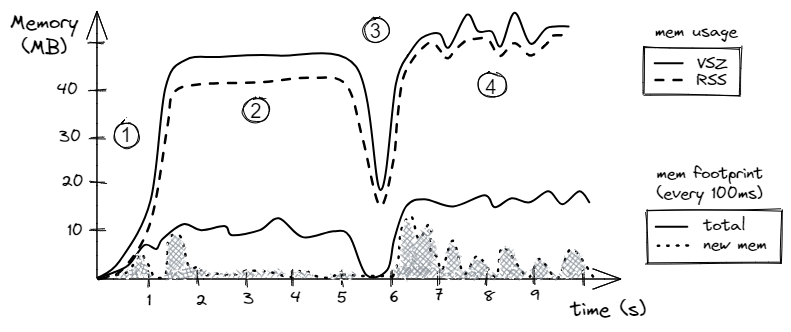
图1展示了一个假设程序的内存使用和足迹的可视化示例。这里的意图不是检查特定程序的统计数据,而是为分析内存分析建立框架。在后面的章节中,我们将检查一些允许我们收集此类信息的工具。
首先看看内存使用(上面的两行)。正如我们所预期的,RSS总是小于或等于VSZ。从图表中看,我们可以发现程序的四个阶段。阶段1是程序的启动阶段,在这个阶段它分配内存。阶段2是算法开始使用这些内存,注意内存使用保持恒定。在阶段3,程序释放了部分内存,然后分配了略高量的内存。阶段4比阶段2更加混乱,有许多对象被分配和释放。注意,VSZ的峰值并不一定伴随着RSS的相应峰值。这可能发生在内存被对象预留但从未使用的情况下。
 |
|---|
| 图1. 内存使用和足迹的示例(假设场景) |
现在让我们转向*内存足迹。它定义了在一段时间内进程占用了多少内存,例如每秒的MB数。在我们的假设情景中,如图1所示,我们绘制每100毫秒(每秒10次)的内存使用情况。实线跟踪每个100毫秒间隔期间访问的字节数。在这里,我们不计算某个内存位置被访问的次数。也就是说,如果在100毫秒间隔期间加载了某个内存位置两次,我们只计算占用到的内存一次。出于同样的原因,我们不能合并时间间隔。例如,我们知道在第2阶段,程序每100毫秒大约占用了10MB。然而,我们不能将连续的10个100毫秒间隔相加,并说内存占用量为每秒100MB,因为同一内存位置可能在相邻的100毫秒时间间隔内加载。只有在程序在每个1秒间隔内不重复内存访问时才会成立。
虚线跟踪自程序开始以来访问的新数据大小。这里,我们计算在每个100毫秒间隔期间从未被程序占用过的字节数。在程序生命周期的前一秒,大多数访问都是新的,正如我们所预期的。在第二阶段,算法开始使用分配的缓冲区。在1.3秒到1.8秒的时间间隔内,程序访问了缓冲区中的大多数位置,例如,这是算法中循环的第一次迭代。这就是为什么我们从1.3秒到1.8秒看到新看到的内存位置有一个大峰值,但在那之后我们看不到很多新的访问。从2秒的时间戳到5秒,算法主要利用已经看到的内存缓冲区,并没有访问任何新数据。然而,阶段4的行为与阶段2不同。首先,在阶段4,算法比阶段2更消耗内存,因为总内存足迹(实线)大约是每100毫秒15MB。其次,算法以相对较大的爆发访问新数据(虚线)。这样的爆发可能与分配新内存区域、在其上工作,然后释放它们有关。
我们将在接下来的两个案例研究中展示如何获得这样的图表,但现在,你可能会想知道这些数据如何使用。嗯,首先,如果我们在每个间隔期间访问的新字节(点线)总和,我们将得到程序的总内存足迹。此外,通过查看图表,你可以观察阶段并将其与正在运行的代码相关联。问问自己:“它是否符合你的预期,或者工作负载正在做一些狡猾的事情?”你可能会在内存足迹中遇到意外的峰值。我们将在这系列文章中讨论的内存分析技术并不一定像常规热点分析那样指向问题所在,但它们确实帮助你更好地理解工作负载的行为。在许多情况下,内存分析帮助识别问题或作为在常规分析期间得出的结论的额外数据点。
在某些情况下,内存足迹帮助我们估计对内存子系统的压力。例如,如果内存足迹很小,比如每秒1MB,并且RSS适合L3缓存的大小,我们可能会怀疑内存子系统的压力很低;记住,现代处理器的可用内存带宽是以GB/s计算的,并且接近1TB/s。另一方面,当内存足迹相当大,例如每秒10GB,并且RSS远大于L3缓存的大小时,那么工作负载可能会对内存子系统造成显著压力。
2. 案例研究:Stockfish的内存使用
现在,让我们看看如何分析一个真实世界应用程序的内存使用情况。我们将使用由KDE开发的Linux堆内存分析器heaptrack。Ubuntu用户可以通过apt install heaptrack heaptrack-gui非常容易地安装它。Heaptrack可以找到代码中发生最大和最频繁分配的位置,以及其他许多事情。在Windows上,你可以使用Mtuner,它具有与Heaptrack相似的功能。
作为一个例子,我们采用了Stockfish内置的基准测试。我们使用Clang 15编译器和-O3 -mavx2选项编译了它。我们使用以下命令收集了在Intel Alderlake i7-1260P处理器上运行的单线程Stockfish内置基准测试的Heaptrack内存分析:
$ heaptrack ./stockfish bench 128 1 24 default depth
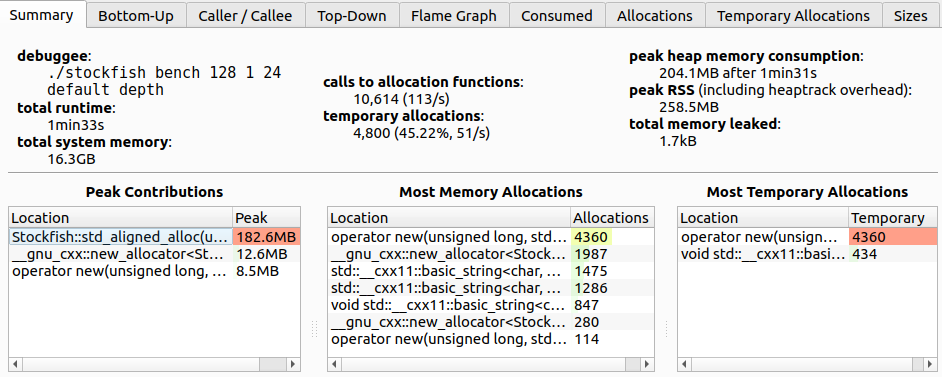
图2向我们展示了Stockfish内存分析的总结视图。我们可以从中学到一些有趣的事实:
- 总分配次数为10614次。
- 几乎一半的分配是临时的,即直接跟随其释放的分配。
- 峰值堆内存消耗为204MB。
Stockfish::std_aligned_alloc负责分配堆空间的最大部分(182MB)。但它并不在最频繁分配位置的列表中(中间表格),所以它可能是一次性分配并在程序结束前一直存在。- 几乎所有分配调用的一半来自
operator new,这些都是临时分配。我们能否消除临时分配? - 对于这个案例研究,泄漏内存不是一个问题。
 |
|---|
| 图2. 使用Heaptrack的Stockfish内存分析,总结视图。 |
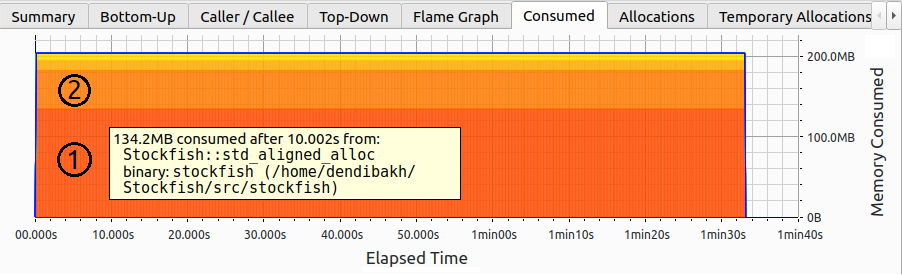
注意,图像顶部有许多标签页;接下来,我们将探索其中的一些。图3显示了Stockfish内置基准测试的内存使用情况。在整个程序运行过程中,内存使用量保持在200MB不变。总消耗的内存被分成几个部分,例如图像上的区域1和2。每个部分对应一个特定的分配。有趣的是,并不是我们之前认为的通过Stockfish::std_aligned_alloc进行的单个大的182MB分配。相反,有两个:区域1的134.2MB和区域2的48.4MB。尽管这两个分配一直持续到基准测试的最后。
 |
|---|
| 图3. 使用Heaptrack的Stockfish内存分析,内存使用随时间保持恒定。 |
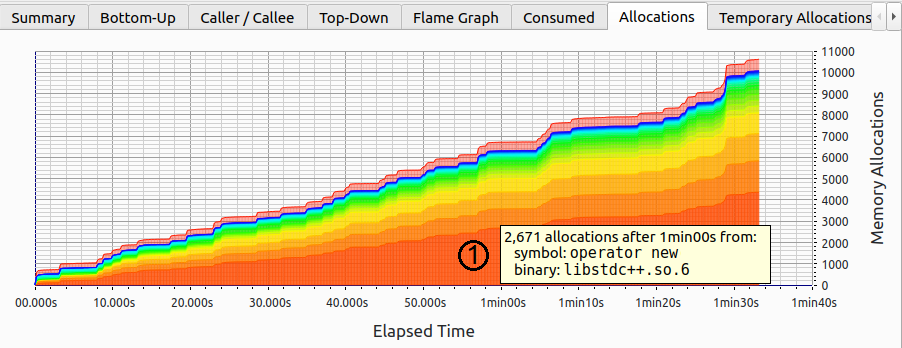
这是否意味着在启动阶段之后没有内存分配?让我们找出答案。图4显示了随时间累积的分配数量。与消耗内存图表(图3)类似,分配是根据归因于每个函数的累积内存分配数量进行切片的。我们可以看到,新的分配不仅来自一个地方,而是来自许多地方。最频繁的分配是通过operator new完成的,对应于图像上的区域1。
注意,程序的整个生命周期中,新分配以稳定的速度进行。然而,正如我们刚刚看到的,内存消耗没有变化;这怎么可能呢?嗯,如果我们释放之前分配的缓冲区并分配相同大小的新缓冲区(也称为临时分配),这是可能的。
 |
|---|
| 图4. 使用Heaptrack的Stockfish内存分析,分配数量在增长。 |
由于分配数量在增长,但总消耗内存没有变化,我们正在处理的是临时分配。让我们找出它们在代码中的来源。通过图5中的火焰图,我们可以很容易地做到这一点。总共有4800个临时分配,其中90.8%来自operator new。得益于火焰图,我们知道导致4360个临时分配的整个调用栈。有趣的是,这些临时分配是由std::stable_sort发起的,它分配了一个临时缓冲区来进行排序。消除这些临时分配的一种方法是使用就地(in-place)排序算法(不需要额外的空间)。然而,这样做观察到性能下降了8%,所以我们放弃了这个改变。
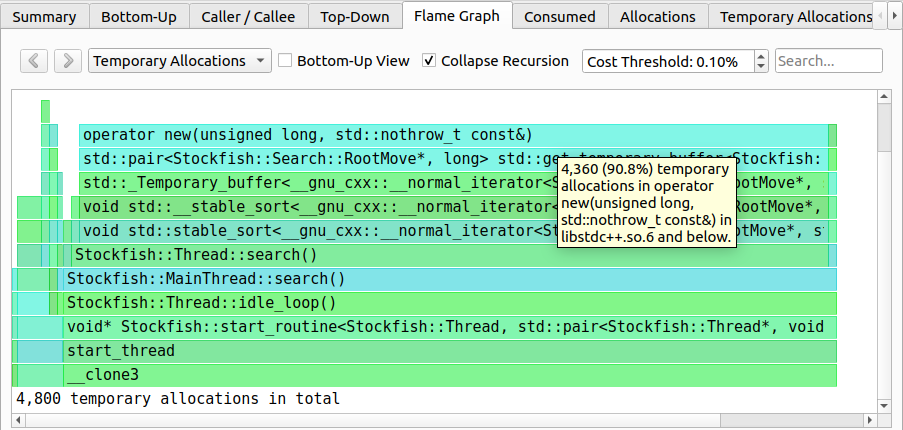 |
|---|
| 图5. 使用Heaptrack的Stockfish内存分析,临时分配火焰图。 |
与临时分配类似,你也可以找到导致程序中最大分配的路径。在顶部的下拉菜单中,你需要选择“消耗(Consumed)”火焰图。我们鼓励读者探索其他标签页。
3. 使用SDE分析内存足迹
现在让我们看看如何估计内存足迹。在第三部分,我们将通过测量一个简单程序的内存足迹来热身。在第四部分,我们将检查四个生产工作负载的内存足迹。
考虑下面左侧列出的简单的朴素矩阵乘法代码。该代码将两个4Kx4K的方阵a和b相乘,并将结果写入4Kx4K的方阵c。回想一下,为了计算结果矩阵c的一个元素,我们需要计算矩阵a中对应行和矩阵b中对应列的点积;这就是最内层循环k所做的。
constexpr int N = 1024*4; // 4K
std::array<std::array<float, N>, N> a, b, c; // 4K x 4K matrices
// init a, b, c
for (int i = 0; i < N; i++) { for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) { => for (int k = 0; k < N; k++) {
for (int k = 0; k < N; k++) => for (int j = 0; j < N; j++) {
c[i][j] += a[i][k] * b[k][j]; c[i][j] += a[i][k] * b[k][j];
} }
} }
} }
为了展示内存足迹的减少,我们应用了一个简单的循环交换变换,交换了j和k的循环(标记为=>的行)。一旦我们测量了内存足迹并在两个版本之间进行比较,就很容易看到差异。内存访问模式变化的可视化结果如图6所示。我们从逐个计算矩阵c的每个元素转变为计算部分结果,同时在所有三个矩阵中保持行主遍历。
在原始代码(左侧)中,矩阵b以列主方式访问,这不利于缓存。观察图片,注意在内层循环的前N次迭代后触摸的内存区域。我们计算a中第0行和b中第0列的点积,并将结果保存在矩阵c的第一个元素中。在内层循环的下一个N次迭代期间,我们访问a中的相同第0行和b中的第1列,以在矩阵c中获得第二个结果。
在右侧转换后的代码中,内层循环仅访问矩阵a中的单个元素。我们将它与b中相应行的所有元素相乘,并将乘积累加到c的相应行中。因此,内层循环的前N次迭代计算a中元素0和b中第0行的乘积,并将部分结果累积到c的第0行中。接下来的N次迭代将a中的元素1和b中的第1行相乘,并再次将部分结果累积到c的第0行中。
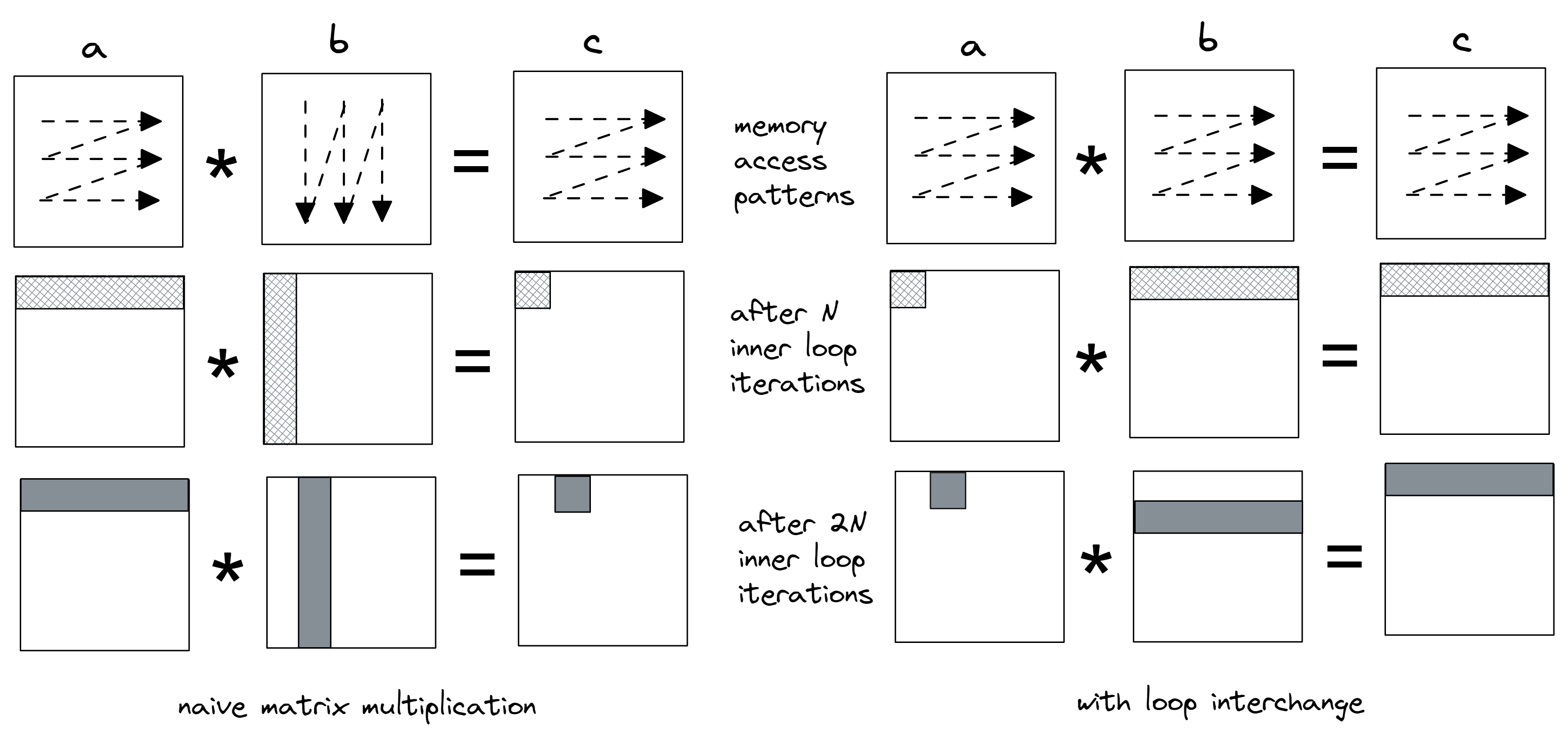 |
|---|
| 图6. 内层循环的前N次和2N次迭代后触摸的内存访问模式和缓存行(图片未按比例)。 |
让我们用Intel SDE,即x86平台的软件开发仿真器工具来确认这一点。SDE建立在动态二进制插桩机制之上,这使得它能够拦截每一条指令。这带来了巨大的成本。对于我们运行的实验,常见的是100倍的减速。
为了防止编译器干扰我们的实验,我们禁用了向量化和展开优化,以便每个版本只有一个热循环,恰好包含7条汇编指令。我们使用这个来统一比较内存足迹间隔。我们不是使用时间间隔,而是使用以机器指令为单位的间隔。我们用来收集SDE内存足迹的命令行,以及其输出的一部分,如下所示。注意我们使用了-fp_icount 28K选项,这表示测量每28K条指令间隔的内存足迹。这个值特别选择是因为它与“before”和“after”情况下内层循环的一次迭代相匹配:4K内层循环迭代 * 7条指令 = 28K。
默认情况下,SDE以缓存行(64字节)为单位测量足迹,但它也可以以内存页(x86上的4KB)为单位进行测量。我们将输出合并并并排放置。此外,从输出中删除了一些不相关的列。第一列PERIOD标记了新的28K指令间隔的开始。每个期间之间的差异是28K条指令。LOAD列告诉我们有多少缓存行被加载指令访问。回想一下之前的讨论,同一个缓存行被访问两次只计算一次。类似地,STORE列告诉我们有多少缓存行被存储。CODE列计算在该期间执行的包含指令的缓存行。最后,NEW计算在期间被触摸的之前未被程序看到的缓存行。
在我们继续之前的重要说明:SDE报告的内存足迹不等于利用的内存带宽。这是因为它没有考虑内存操作是从缓存还是内存中服务的。
$ sde64 -footprint -fp_icount 28K -- ./matrix_multiply.exe
============================= CACHE LINES =============================
PERIOD LOAD STORE CODE NEW | PERIOD LOAD STORE CODE NEW
-----------------------------------------------------------------------
... ...
2982388 4351 1 2 4345 | 2982404 258 256 2 511
3011063 4351 1 2 0 | 3011081 258 256 2 256
3039738 4351 1 2 0 | 3039758 258 256 2 256
3068413 4351 1 2 0 | 3068435 258 256 2 256
3097088 4351 1 2 0 | 3097112 258 256 2 256
3125763 4351 1 2 0 | 3125789 258 256 2 256
3154438 4351 1 2 0 | 3154466 257 256 2 255
3183120 4352 1 2 0 | 3183150 257 256 2 256
3211802 4352 1 2 0 | 3211834 257 256 2 256
3240484 4352 1 2 0 | 3240518 257 256 2 256
3269166 4352 1 2 0 | 3269202 257 256 2 256
3297848 4352 1 2 0 | 3297886 257 256 2 256
3326530 4352 1 2 0 | 3326570 257 256 2 256
3355212 4352 1 2 0 | 3355254 257 256 2 256
3383894 4352 1 2 0 | 3383938 257 256 2 256
3412576 4352 1 2 0 | 3412622 257 256 2 256
3441258 4352 1 2 4097 | 3441306 257 256 2 257
3469940 4352 1 2 0 | 3469990 257 256 2 256
3498622 4352 1 2 0 | 3498674 257 256 2 256
...
让我们讨论一下上面输出中的数字。看看从指令2982388开始的时间段(左侧)。这个时间段对应原始Matmul程序中内层循环的前4096次迭代。SDE报告称在这个时间段内,算法加载了4351个缓存行。我们来做一下数学计算,看看我们是否能得到相同的数字。原始的内层循环访问矩阵a的第0行。记住float类型的大小是4字节,缓存行的大小是64字节。所以,对于矩阵a,算法加载了(4096 * 4字节) / 64字节 = 256个缓存行。对于矩阵b,算法访问第0列。每个元素都位于自己的缓存行上,所以对于矩阵b它加载了4096个缓存行。对于矩阵c,我们将所有乘积累积到一个单独的元素中,所以有1个缓存行被存储在矩阵c中。我们计算出加载了4096 + 256 = 4352个缓存行,存储了1个缓存行。一个缓存行的差异可能与SDE开始计算28K指令间隔不是在第一个内层循环迭代的确切开始有关。我们看到在这个时间段内有两条包含指令的缓存行(CODE)被访问。内层循环的七条指令位于一个缓存行中,但28K间隔也可能捕获到中间循环,使其总共成为两个缓存行。最后,由于我们访问的所有数据之前都未被看到,所以所有的缓存行都是NEW。
现在让我们切换到下一个28K指令的时间段(3011063),它对应原始Matmul程序中内层循环的第二组4096次迭代。我们有与前一个时间段相同的LOAD、STORE和CODE缓存行数量,这是预期的。然而,没有新的NEW缓存行被占用。让我们理解为什么会这样。再次查看图6。内层循环的第二组4096次迭代再次访问矩阵a的第0行。但它也访问矩阵b的第1列,这是新的,但这些元素位于与第0列相同的缓存行集上,所以我们已经在前一个28K时间段内占用了它们。这种模式在接下来的14个时间段内重复。每个缓存行包含64字节 / 4字节(float的大小)= 16个元素,这解释了模式:我们每16次迭代在矩阵b中获取一组新的缓存行。最后一个剩下的问题是为什么我们在内层循环的前16次迭代后有4097个NEW行。答案很简单:算法不断访问矩阵a的第0行,所以所有这些新的缓存行都来自矩阵b。
对于转换后的版本,内存足迹看起来更加一致,除了第一个时间段之外,所有时间段的数字都非常相似。在第一个时间段,我们在矩阵a中访问了1个缓存行;(4096 * 4字节) / 64字节 = 256个缓存行在b中;(4096 * 4字节) / 64字节 = 256个缓存行被存储到c中,总共513行。再次,结果的差异与SDE开始计算28K指令间隔不是在第一个内层循环迭代的确切开始有关。在第二个时间段(3011081),我们访问了矩阵a中的相同缓存行,从矩阵b中访问了一组新的256个缓存行,以及从矩阵c中访问了相同的缓存行集。只有来自矩阵b的行之前未被看到,这就是为什么第二个时间段有NEW 256个缓存行。以指令3441306开始的时间段有257个NEW行被访问。一个额外的缓存行来自于访问矩阵a中的元素a[0][17],因为它之前未被访问过。
在我们探索的两种情况下,我们通过SDE输出确认了我们对算法的理解。但请注意,仅凭SDE足迹工具的输出,你无法判断算法是否对缓存友好。在我们的案例中,我们简单地查看了代码并相当容易地解释了数字。但如果没有知道算法在做什么,就无法做出正确的判断。这是为什么。现代x86处理器的L1缓存只能容纳大约1000个缓存行。当你看到一个算法访问,比如说,每1M条指令500行时,可能会诱人地得出结论,代码必须是对缓存友好的,因为500行可以轻松地适应L1缓存。但我们对这些访问的性质一无所知。如果这些访问是随机的,那么这样的代码远非“友好”。SDE足迹工具的输出仅仅告诉我们访问了多少内存,但我们不知道这些访问是否命中了缓存。
4. 案例研究:四个工作负载的内存足迹
在这个案例研究中,我们将使用Intel SDE工具来分析四个生产工作负载的内存足迹:Blender光线追踪、Stockfish国际象棋引擎、Clang++编译和AI_bench PSPNet分割。我们希望这项研究能给你一个直觉,让你知道在真实世界的应用中可能会看到什么。在第三部分,我们收集了每28K条指令间隔的内存足迹,这对于运行数千亿条指令的应用程序来说太小了。因此,我们将测量每十亿条指令的足迹。
图7展示了四个选定工作负载的内存足迹。你可以看到它们都有非常不同的行为。Clang编译在开始时内存活动非常高,有时每10亿条指令会飙升到100MB,但之后它减少到大约每10亿条指令15MB。图表上的任何峰值都可能引起Clang开发者的关注:它们是预期的吗?它们是否与某些内存密集型的优化过程有关?访问的内存位置可以被压缩吗?
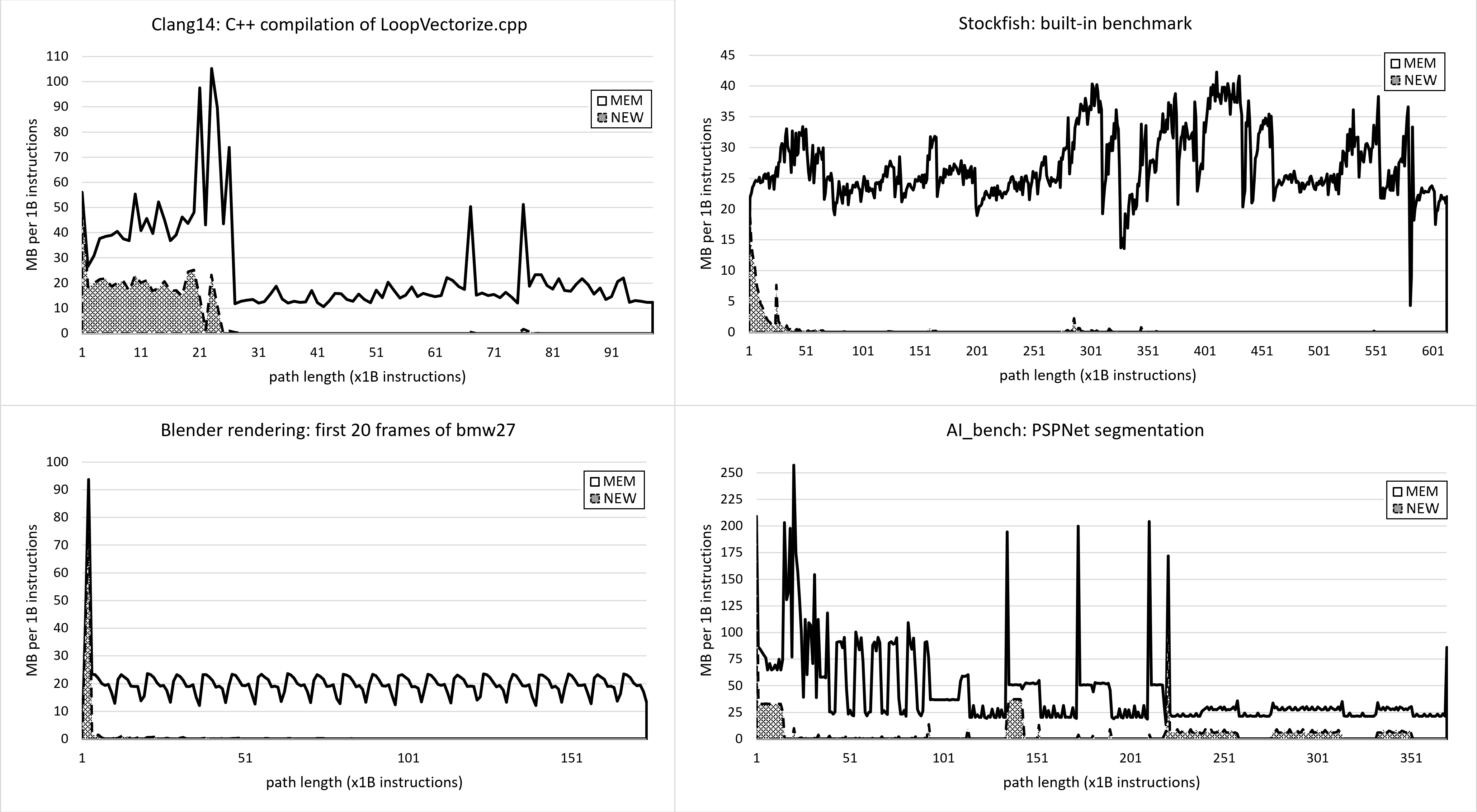 |
|---|
| 图7. 四个工作负载的内存足迹案例研究。MEM - 在1B指令间隔期间访问的总内存。NEW - 之前未被看到的访问内存。 |
Blender基准测试非常稳定;我们可以清楚地看到每个渲染帧的开始和结束。这使我们能够专注于单个帧,而不必看整个1000多个帧。Stockfish基准测试要混乱得多,可能是因为国际象棋引擎处理不同的位置,这些位置需要不同数量的资源。最后,AI_bench的内存足迹非常有趣,因为我们可以发现重复的模式。在初始启动之后,有五到六个从40B到95B的正弦波,然后是三个以锐利峰值结束的区域,达到200MB,然后又是三个每10亿条指令大约在25MB的区域。所有这些都可能是可以用来优化应用程序的可操作信息。
关于指令作为时间的衡量可能仍然有一些混淆,所以让我们来解决这个问题。如果你知道工作负载的IPC(每个时钟周期的指令数)和处理器运行的频率,你可以大致将时间线从指令转换为秒。例如,在IPC=1和处理器频率为4GHz的情况下,10亿条指令运行250毫秒,在IPC=2时,10亿条指令运行125毫秒,以此类推。这样,你可以将内存足迹图表的X轴从指令转换为秒。但请记住,只有在工作负载具有稳定的IPC且CPU频率在工作负载运行期间不改变时,它才会准确。
5. 数据局部性和重用距离
注:(这部分作者可能会变动,见: 原文评论)
正如从前面的案例研究中看到的,使用现代内存分析工具可以提取大量信息。然而,还存在一些限制,我们接下来将讨论。
考虑图7(第四部分)中显示的内存足迹图表。这样的图表告诉我们在10亿条指令期间访问了多少字节。然而,查看这些图表中的任何一个,我们都无法知道在10亿条指令期间,某个内存位置是被访问了一次、两次还是一百次。每次记录的内存访问只是为间隔期间的总内存足迹做出贡献,并且每个间隔只计算一次。知道每个字节在间隔期间被触摸重用了多少次,会给我们一些关于程序内存访问模式的直觉。例如,我们可以估计热点内存区域的大小,并查看它是否适合L3缓存。
然而,即使这些信息也不足以完全评估内存访问的时间局部性。想象一种情况,我们在10亿条指令的间隔期间,所有内存位置都被访问了两次。这是好还是坏?嗯,我们不知道,因为重要的是第一次(使用)和第二次访问(重用)之间的距离。如果距离很小,例如,小于L1缓存可以保持的缓存行数(今天大约是1000),那么数据很可能会被有效地重用。否则,所需的缓存行可能已经在这期间被驱逐了。
此外,到目前为止我们讨论的任何内存分析方法都没有给我们提供程序空间局部性的洞察。内存使用和内存足迹只告诉我们访问了多少内存,但我们不知道这些访问是顺序的、跨步的还是完全随机的。我们需要更好的方法。
应用程序的时间和空间局部性主题已经研究了很长时间,不幸的是,截至2024年初,还没有可用的生产质量工具可以提供这样的信息。衡量程序数据局部性的中心指标是重用距离(reuse distance),它是在两次连续访问特定内存位置之间访问的独特内存位置的数量。重用距离显示了在典型的最近最少使用(LRU)缓存中内存访问缓存命中的可能性。如果内存访问的重用距离大于缓存大小,那么后续的访问(重用)很可能会导致缓存未命中。
由于现代处理器中的内存访问单位是缓存行,我们定义了两个额外的术语:时间重用(temporal reuse) 发生在使用和重用访问完全相同的地址时,空间重用(spatial reuse) 发生在使用和重用访问位于同一缓存行的不同地址时。考虑图8中显示的一系列内存访问:a1,b1,e1,b2,c1,d1,a2,其中位置a、b和c占据缓存行N,位置d和e位于后续的缓存行N+1。在这个例子中,访问a2的时间重用距离是四,因为在两次连续访问a之间有四个独特的位置被访问,即b、c、d和e。访问d1不是时间重用,然而,它是空间重用,因为我们之前访问了位置e,它与d位于同一缓存行。访问d1的空间重用距离是二。
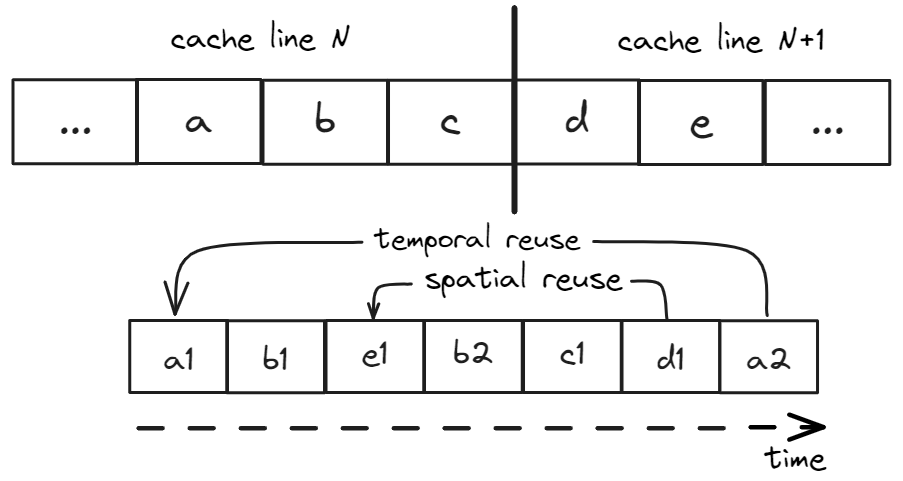 |
|---|
| 图8. 时间和空间重用的示例。 |
图9提供了一个假设程序的重用距离直方图示例。它的X轴以log2 bin为群集,每个bin乘以1000进行缩放。Y轴提供了发生率,即我们观察到某个特定重用距离的频率。理想情况下,我们希望看到所有的访问都在第一个bin [0;1000]中,无论是时间还是空间重用。例如,对于顺序访问大型数组,我们会看到一个大的时间重用距离(不好),但一个小的空间重用距离(好)。对于一个多次遍历1000个元素的二叉树(适合L1缓存)的程序,我们会看到一个相对较小的时间重用距离(好),但一个大的空间重用距离(不好)。对大型缓冲区的随机访问代表了时间和空间局部性都不好。一般来说,如果内存访问具有小的时间或空间重用距离,那么它很可能会命中CPU缓存。因此,如果一个访问具有大的时间和大的空间重用距离,那么它很可能会错过CPU缓存。
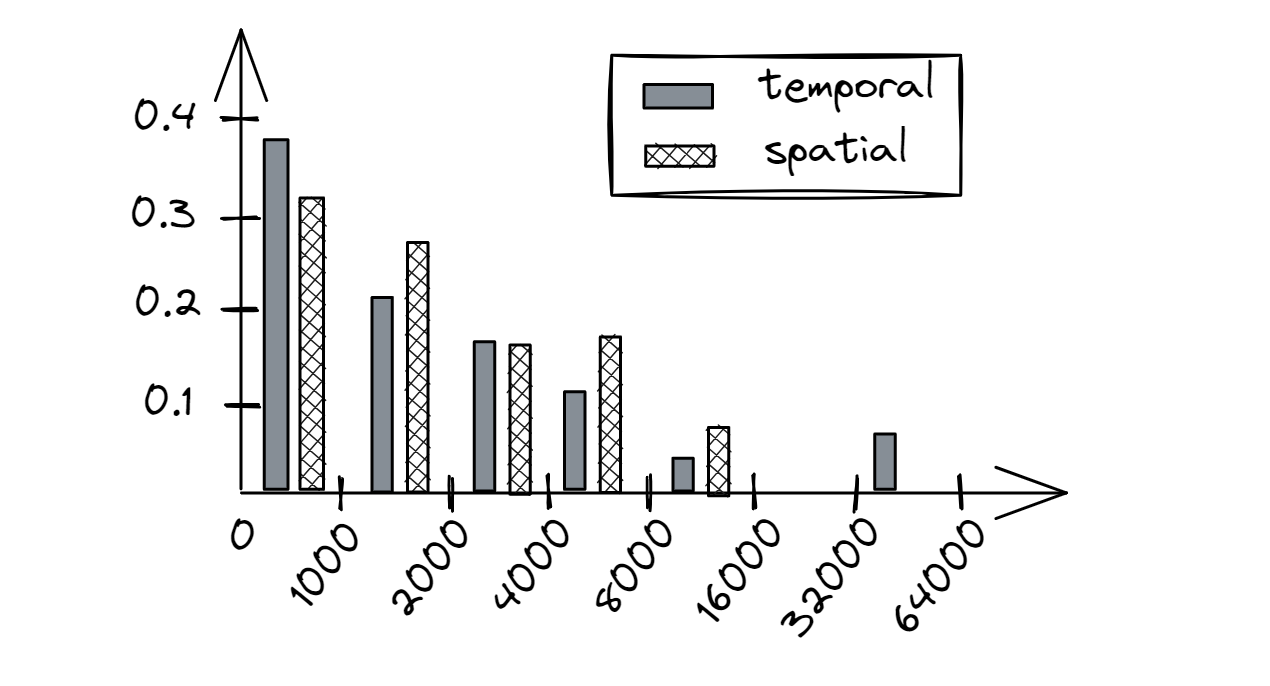 |
|---|
| 图9. 重用距离直方图的示例。X轴是重用距离,Y轴是发生率。 |
多年来开发了一些试图分析程序的时间和空间局部性的工具。以下是三个最新的工具及其简短描述和当前状态:
- loca,一个使用PIN二进制插桩工具实现的重用距离分析工具。它可以为整个程序打印重用距离直方图,但不能为个别加载提供类似的分解。由于它使用动态二进制插桩,它会产生巨大的运行时(约50倍)和内存(约40倍)开销,这使得该工具在实际应用中不实用。该工具不再维护,并且需要对源代码进行一些修改才能在新平台上工作。Github仓库, [LocaPaper]
- RDX,利用硬件性能计数器采样与硬件调试寄存器相结合来产生重用距离直方图。与
loca相比,它在保持90%准确性的同时,产生了一个数量级更小的开销。该工具不再维护,并且几乎没有关于如何使用该工具的文档。[RDXpaper] - ReuseTracker,基于
RDX构建,但它通过考虑缓存一致性和缓存行失效效应来扩展它。使用这个工具,我们能够在一个小程序上产生有意义的结果,然而,它还不是生产质量,并且不容易使用。Github仓库, [ReuseTrackerPaper]
聚合程序中所有内存访问的重用距离在某些情况下可能有用,但未来的分析工具也应该能够为个别加载提供重用距离直方图。幸运的是,并不是每个加载/存储汇编指令都需要彻底分析。性能工程师应该首先使用传统的抽样方法找到一个有问题的加载或存储指令。之后,应该能够请求该特定操作的时间和空间重用距离直方图。这应该是一个单独的收集,因为它可能涉及相对较大的开销。
时间和空间局部性分析提供了可以用来指导性能优化的独特见解。然而,仔细的实现并不简单,一旦我们开始考虑各种缓存一致性效应,可能会变得棘手。此外,大的开销可能会成为将此功能集成到生产分析器中的障碍。
参考阅读
- 内存归属于那个NUMA region,redhat 使用
numastat工具进行分析 Profiling memory allocation with numastat - 共享内存查看工具:shared_memory
- 大页相关操作在附录C: 原文 | 中文翻译