上篇文章使用chatGPT翻译了db_tutorial 文章,文中使用的是c语言开发; 这篇文章使用chatGPT根据db_tutorial中的c源码,使用golang进行重写, 测试的ruby代码使用python进行重写;同理其他语言也适用。
注:利用已有知识结构,通过chatGPT来生成另一种表达(现实中这种转换经常出现,比如一个基础知识点,嚼碎了,揉烂了,底层相通,表达方式不同,变了个花样玩,而且还能通过认知差来盈利,也许精细利己主义会利益最大化吧),使用AGI工具进行效率编码的一种小小实践。在实践过程中,chatGPT生成的代码不可能都能正常运行,需要调试下(特别是指针操作)。
整体实现代码:https://github.com/weedge/baby-db/tree/main/golang
主要的btree数据结构为leafNode 和 internalNode,叶子节点表数据存放在value中,id存放在key中,序列化和遍历操作需要额外偏移操作;这里仅实现简单的insert和select操作。

第一部分 - 简介和设置REPL
制作一个简单的 REPL(Read-Eval-Print Loop) golang 版本
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
type InputBuffer struct {
buffer string
bufferLength int
inputLength int
}
func newInputBuffer() *InputBuffer {
return &InputBuffer{
buffer: "",
bufferLength: 0,
inputLength: 0,
}
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
input = strings.TrimSuffix(input, "\n")
inputBuffer.inputLength = len(input)
inputBuffer.buffer = input
}
func closeInputBuffer(inputBuffer *InputBuffer) {
inputBuffer = nil
}
func main() {
inputBuffer := newInputBuffer()
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if len(inputBuffer.buffer) == 0 {
continue
}
if inputBuffer.buffer == ".exit" {
closeInputBuffer(inputBuffer)
os.Exit(0)
} else {
fmt.Printf("Unrecognized command '%s'.\n", inputBuffer.buffer)
}
}
}
运行结果:
go run golang/1.go
db > .tables
Unrecognized command '.tables'.
db > .exit
第二部分 - 世界上最简单的SQL编译器和虚拟机
golang 版本
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
type InputBuffer struct {
buffer string
bufferLength int
inputLength int
}
type MetaCommandResult int
const (
META_COMMAND_SUCCESS MetaCommandResult = iota
META_COMMAND_UNRECOGNIZED_COMMAND
)
type PrepareResult int
const (
PREPARE_SUCCESS PrepareResult = iota
PREPARE_UNRECOGNIZED_STATEMENT
)
type StatementType int
const (
STATEMENT_INSERT StatementType = iota
STATEMENT_SELECT
)
type Statement struct {
Type StatementType
}
func newInputBuffer() *InputBuffer {
return &InputBuffer{
buffer: "",
bufferLength: 0,
inputLength: 0,
}
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
input = strings.TrimSuffix(input, "\n")
inputBuffer.inputLength = len(input)
inputBuffer.buffer = input
}
func doMetaCommand(inputBuffer *InputBuffer) MetaCommandResult {
if inputBuffer.buffer == ".exit" {
os.Exit(0)
}
return META_COMMAND_UNRECOGNIZED_COMMAND
}
func prepareStatement(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
if strings.HasPrefix(inputBuffer.buffer, "insert") {
statement.Type = STATEMENT_INSERT
return PREPARE_SUCCESS
}
if inputBuffer.buffer == "select" {
statement.Type = STATEMENT_SELECT
return PREPARE_SUCCESS
}
return PREPARE_UNRECOGNIZED_STATEMENT
}
func executeStatement(statement *Statement) {
switch statement.Type {
case STATEMENT_INSERT:
fmt.Println("This is where we would do an insert.")
case STATEMENT_SELECT:
fmt.Println("This is where we would do a select.")
}
}
func main() {
inputBuffer := newInputBuffer()
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if len(inputBuffer.buffer) == 0 {
continue
}
if inputBuffer.buffer[0] == '.' {
switch doMetaCommand(inputBuffer) {
case META_COMMAND_SUCCESS:
continue
case META_COMMAND_UNRECOGNIZED_COMMAND:
fmt.Printf("Unrecognized command '%s'\n", inputBuffer.buffer)
continue
}
}
var statement Statement
switch prepareStatement(inputBuffer, &statement) {
case PREPARE_SUCCESS:
break
case PREPARE_UNRECOGNIZED_STATEMENT:
fmt.Printf("Unrecognized keyword at start of '%s'.\n", inputBuffer.buffer)
continue
}
executeStatement(&statement)
fmt.Println("Executed.")
}
}
运行结果:
go run golang/2.go
db > insert foo bar
This is where we would do an insert.
Executed.
db >
db > delete foo
Unrecognized keyword at start of 'delete foo'.
db > select
This is where we would do a select.
Executed.
db > .tables
Unrecognized command '.tables'
db > .exit
第三部分 - 内存中、追加方式、单表数据库
golang 版本
package main
import (
"bufio"
"fmt"
"os"
"strings"
"unsafe"
)
type InputBuffer struct {
buffer string
bufferLength int
inputLength int
}
type MetaCommandResult int
const (
META_COMMAND_SUCCESS MetaCommandResult = iota
META_COMMAND_UNRECOGNIZED_COMMAND
)
type PrepareResult int
const (
PREPARE_SUCCESS PrepareResult = iota
PREPARE_SYNTAX_ERROR
PREPARE_UNRECOGNIZED_STATEMENT
)
type StatementType int
const (
STATEMENT_INSERT StatementType = iota
STATEMENT_SELECT
)
const (
COLUMN_USERNAME_SIZE = 32
COLUMN_EMAIL_SIZE = 255
)
type Row struct {
id uint32
username [COLUMN_USERNAME_SIZE]byte
email [COLUMN_EMAIL_SIZE]byte
}
type Statement struct {
Type StatementType
rowToInsert Row //only used by insert statement
}
const (
ID_SIZE = int(unsafe.Sizeof(uint32(0)))
USERNAME_SIZE = int(unsafe.Sizeof([COLUMN_USERNAME_SIZE]byte{}))
EMAIL_SIZE = int(unsafe.Sizeof([COLUMN_EMAIL_SIZE]byte{}))
ID_OFFSET = 0
USERNAME_OFFSET = ID_OFFSET + ID_SIZE
EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE
ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE
)
const (
PAGE_SIZE = 4096
TABLE_MAX_PAGES = 100
ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE
TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES
)
type Table struct {
numRows uint32
pages [TABLE_MAX_PAGES][]byte
}
func printRow(row *Row) {
fmt.Printf("(%d, %s, %s)\n", row.id, strings.TrimRight(string(row.username[:]), "\x00"), strings.TrimRight(string(row.email[:]), "\x00"))
}
func serializeRow(source *Row, destination []byte) {
copy(destination[ID_OFFSET:], (*(*[ID_SIZE]byte)(unsafe.Pointer(&source.id)))[:])
copy(destination[USERNAME_OFFSET:], source.username[:])
copy(destination[EMAIL_OFFSET:], source.email[:])
}
func deserializeRow(source []byte, destination *Row) {
destination.id = *(*uint32)(unsafe.Pointer(&source[ID_OFFSET]))
copy(destination.username[:], source[USERNAME_OFFSET:USERNAME_OFFSET+USERNAME_SIZE])
copy(destination.email[:], source[EMAIL_OFFSET:EMAIL_OFFSET+EMAIL_SIZE])
}
func rowSlot(table *Table, rowNum uint32) []byte {
pageNum := rowNum / uint32(ROWS_PER_PAGE)
page := table.pages[pageNum]
if page == nil {
page = make([]byte, PAGE_SIZE)
table.pages[pageNum] = page
}
rowOffset := rowNum % uint32(ROWS_PER_PAGE)
byteOffset := rowOffset * uint32(ROW_SIZE)
return page[byteOffset : byteOffset+uint32(ROW_SIZE)]
}
func newTable() *Table {
table := new(Table)
table.numRows = 0
return table
}
func freeTable(table *Table) {
for i := 0; i < TABLE_MAX_PAGES; i++ {
if table.pages[i] != nil {
table.pages[i] = nil
}
}
}
func doMetaCommand(inputBuffer *InputBuffer, table *Table) MetaCommandResult {
if inputBuffer.buffer == ".exit" {
closeInputBuffer(inputBuffer)
freeTable(table)
os.Exit(0)
}
return META_COMMAND_UNRECOGNIZED_COMMAND
}
func BytesToString(b []byte) string {
p := unsafe.SliceData(b)
return unsafe.String(p, len(b))
}
func StringToBytes(s string) []byte {
p := unsafe.StringData(s)
b := unsafe.Slice(p, len(s))
return b
}
func prepareStatement(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
if strings.HasPrefix(inputBuffer.buffer, "insert") {
statement.Type = STATEMENT_INSERT
var username string
var email string
// chatGPT generate code, need debug
//argsAssigned, _ := fmt.Sscanf(inputBuffer.buffer, "insert %d %s %s", &statement.rowToInsert.id, &statement.rowToInsert.username, &statement.rowToInsert.email)
argsAssigned, _ := fmt.Sscanf(inputBuffer.buffer, "insert %d %s %s", &statement.rowToInsert.id, &username, &email)
if argsAssigned < 3 {
return PREPARE_SYNTAX_ERROR
}
copy(statement.rowToInsert.username[:], StringToBytes(username))
copy(statement.rowToInsert.email[:], StringToBytes(email))
return PREPARE_SUCCESS
}
if inputBuffer.buffer == "select" {
statement.Type = STATEMENT_SELECT
return PREPARE_SUCCESS
}
return PREPARE_UNRECOGNIZED_STATEMENT
}
func executeInsert(statement *Statement, table *Table) error {
if table.numRows >= uint32(TABLE_MAX_ROWS) {
err := fmt.Errorf("Error: Table full.")
return err
}
rowToInsert := &statement.rowToInsert
serializeRow(rowToInsert, rowSlot(table, table.numRows))
table.numRows++
return nil
}
func executeSelect(table *Table) {
var row Row
for i := uint32(0); i < table.numRows; i++ {
deserializeRow(rowSlot(table, i), &row)
printRow(&row)
}
}
func executeStatement(statement *Statement, table *Table) error {
switch statement.Type {
case STATEMENT_INSERT:
return executeInsert(statement, table)
case STATEMENT_SELECT:
executeSelect(table)
}
return nil
}
func closeInputBuffer(inputBuffer *InputBuffer) {
inputBuffer = nil
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
input = strings.TrimSuffix(input, "\n")
inputBuffer.inputLength = len(input)
inputBuffer.buffer = input
}
func main() {
table := newTable()
inputBuffer := new(InputBuffer)
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if len(inputBuffer.buffer) == 0 {
continue
}
if inputBuffer.buffer[0] == '.' {
switch doMetaCommand(inputBuffer, table) {
case META_COMMAND_SUCCESS:
continue
case META_COMMAND_UNRECOGNIZED_COMMAND:
fmt.Printf("Unrecognized command '%s'\n", inputBuffer.buffer)
continue
}
}
var statement Statement
switch prepareStatement(inputBuffer, &statement) {
case PREPARE_SUCCESS:
break
case PREPARE_SYNTAX_ERROR:
fmt.Println("Syntax error. Could not parse statement.")
continue
case PREPARE_UNRECOGNIZED_STATEMENT:
fmt.Printf("Unrecognized keyword at start of '%s'\n", inputBuffer.buffer)
continue
}
if err := executeStatement(&statement, table); err != nil {
fmt.Println(err.Error())
continue
}
fmt.Println("Executed.")
}
}
运行结果:
go run golang/3.go
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 bob bob@example.com
Executed.
db > select
(1, cstack, foo@bar.com)
(2, bob, bob@example.com)
Executed.
db > insert foo bar 1
Syntax error. Could not parse statement.
db > .exit
第四部分 - 我们的第一个测试(Bug)
使用golang重写:
package main
import (
"bufio"
"fmt"
"os"
"strconv"
"strings"
"unsafe"
)
const (
COLUMN_USERNAME_SIZE = 32
COLUMN_EMAIL_SIZE = 255
ID_SIZE = 4
USERNAME_SIZE = COLUMN_USERNAME_SIZE + 1
EMAIL_SIZE = COLUMN_EMAIL_SIZE + 1
ID_OFFSET = 0
USERNAME_OFFSET = ID_OFFSET + ID_SIZE
EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE
ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE
PAGE_SIZE = 4096
TABLE_MAX_PAGES = 100
ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE
TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES
)
type Row struct {
id uint32
username [COLUMN_USERNAME_SIZE + 1]byte
email [COLUMN_EMAIL_SIZE + 1]byte
}
type Table struct {
numRows uint32
pages [TABLE_MAX_PAGES][]byte
}
type InputBuffer struct {
buffer []byte
bufferLength int
inputLength int
}
type StatementType int
const (
STATEMENT_INSERT StatementType = iota
STATEMENT_SELECT
)
type Statement struct {
stmtType StatementType
rowToInsert Row
}
type ExecuteResult int
const (
EXECUTE_SUCCESS ExecuteResult = iota
EXECUTE_TABLE_FULL
)
type MetaCommandResult int
const (
META_COMMAND_SUCCESS MetaCommandResult = iota
META_COMMAND_UNRECOGNIZED_COMMAND
)
type PrepareResult int
const (
PREPARE_SUCCESS PrepareResult = iota
PREPARE_NEGATIVE_ID
PREPARE_STRING_TOO_LONG
PREPARE_SYNTAX_ERROR
PREPARE_UNRECOGNIZED_STATEMENT
)
func newInputBuffer() *InputBuffer {
return &InputBuffer{
buffer: make([]byte, 0),
}
}
func newTable() *Table {
table := &Table{
numRows: 0,
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
table.pages[i] = nil
}
return table
}
func printRow(row *Row) {
fmt.Printf("(%d, %s, %s)\n", row.id, strings.TrimRight(string(row.username[:]), "\x00"), strings.TrimRight(string(row.email[:]), "\x00"))
}
func serializeRow(source *Row, destination []byte) {
copy(destination[ID_OFFSET:], (*(*[ID_SIZE]byte)(unsafe.Pointer(&source.id)))[:])
copy(destination[USERNAME_OFFSET:], source.username[:])
copy(destination[EMAIL_OFFSET:], source.email[:])
}
func deserializeRow(source []byte, destination *Row) {
destination.id = *(*uint32)(unsafe.Pointer(&source[ID_OFFSET]))
copy(destination.username[:], source[USERNAME_OFFSET:USERNAME_OFFSET+USERNAME_SIZE])
copy(destination.email[:], source[EMAIL_OFFSET:EMAIL_OFFSET+EMAIL_SIZE])
}
func rowSlot(table *Table, rowNum uint32) []byte {
pageNum := rowNum / ROWS_PER_PAGE
page := table.pages[pageNum]
if page == nil {
page = make([]byte, PAGE_SIZE)
table.pages[pageNum] = page
}
rowOffset := rowNum % ROWS_PER_PAGE
byteOffset := rowOffset * ROW_SIZE
return page[byteOffset : byteOffset+ROW_SIZE]
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
input, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
// Remove newline character
input = strings.TrimSpace(input)
inputBuffer.buffer = []byte(input)
inputBuffer.inputLength = len(inputBuffer.buffer)
}
func closeInputBuffer(inputBuffer *InputBuffer) {
// Go has automatic garbage collection, so no explicit freeing is needed
}
func doMetaCommand(inputBuffer *InputBuffer, table *Table) MetaCommandResult {
switch string(inputBuffer.buffer) {
case ".exit":
closeInputBuffer(inputBuffer)
os.Exit(0)
default:
return META_COMMAND_UNRECOGNIZED_COMMAND
}
return META_COMMAND_SUCCESS
}
func prepareInsert(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
statement.stmtType = STATEMENT_INSERT
tokens := strings.Fields(string(inputBuffer.buffer))
if len(tokens) != 4 {
return PREPARE_SYNTAX_ERROR
}
id, err := strconv.Atoi(tokens[1])
if err != nil || id < 0 {
return PREPARE_NEGATIVE_ID
}
if len(tokens[2]) > COLUMN_USERNAME_SIZE || len(tokens[3]) > COLUMN_EMAIL_SIZE {
return PREPARE_STRING_TOO_LONG
}
statement.rowToInsert.id = uint32(id)
copy(statement.rowToInsert.username[:], tokens[2])
copy(statement.rowToInsert.email[:], tokens[3])
return PREPARE_SUCCESS
}
func prepareStatement(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
tokens := strings.Fields(string(inputBuffer.buffer))
if len(tokens) == 0 {
return PREPARE_SUCCESS
}
switch tokens[0] {
case "insert":
return prepareInsert(inputBuffer, statement)
case "select":
statement.stmtType = STATEMENT_SELECT
return PREPARE_SUCCESS
default:
return PREPARE_UNRECOGNIZED_STATEMENT
}
}
func executeInsert(statement *Statement, table *Table) ExecuteResult {
if table.numRows >= TABLE_MAX_ROWS {
return EXECUTE_TABLE_FULL
}
rowToInsert := &statement.rowToInsert
serializeRow(rowToInsert, rowSlot(table, table.numRows))
table.numRows++
return EXECUTE_SUCCESS
}
func executeSelect(statement *Statement, table *Table) ExecuteResult {
var row Row
for i := uint32(0); i < table.numRows; i++ {
deserializeRow(rowSlot(table, i), &row)
printRow(&row)
}
return EXECUTE_SUCCESS
}
func executeStatement(statement *Statement, table *Table) ExecuteResult {
switch statement.stmtType {
case STATEMENT_INSERT:
return executeInsert(statement, table)
case STATEMENT_SELECT:
return executeSelect(statement, table)
default:
return EXECUTE_SUCCESS
}
}
func main() {
table := newTable()
inputBuffer := newInputBuffer()
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if inputBuffer.buffer[0] == '.' {
switch doMetaCommand(inputBuffer, table) {
case META_COMMAND_SUCCESS:
continue
case META_COMMAND_UNRECOGNIZED_COMMAND:
fmt.Printf("Unrecognized command '%s'\n", inputBuffer.buffer)
continue
}
}
var statement Statement
switch prepareStatement(inputBuffer, &statement) {
case PREPARE_SUCCESS:
break
case PREPARE_NEGATIVE_ID:
fmt.Println("ID must be positive.")
continue
case PREPARE_STRING_TOO_LONG:
fmt.Println("String is too long.")
continue
case PREPARE_SYNTAX_ERROR:
fmt.Println("Syntax error. Could not parse statement.")
continue
case PREPARE_UNRECOGNIZED_STATEMENT:
fmt.Printf("Unrecognized keyword at start of '%s'.\n", inputBuffer.buffer)
continue
}
switch executeStatement(&statement, table) {
case EXECUTE_SUCCESS:
fmt.Println("Executed.")
break
case EXECUTE_TABLE_FULL:
fmt.Println("Error: Table full.")
break
}
}
}
测试命令pipe: util.py
def run_script(commands,bin_file="./db",db_file=""):
raw_output = None
with subprocess.Popen([bin_file, db_file], stdin=subprocess.PIPE, stdout=subprocess.PIPE, text=True) as process:
for command in commands:
process.stdin.write(command + '\n')
process.stdin.close()
raw_output = process.stdout.read()
return raw_output.splitlines()
使用python重写测试:
import subprocess
import sys
from util import run_script
# 测试插入和查询
def test_inserts_and_retrieves_row():
result = run_script([
"insert 1 user1 person1@example.com",
"select",
".exit"
])
expected_result = [
"db > Executed.",
"db > (1, user1, person1@example.com)",
"Executed.",
"db > "
]
#print(f"result: {result}")
assert result == expected_result, "Test failed"
print(f"{sys._getframe().f_code.co_name} passed")
# Run the test
test_inserts_and_retrieves_row()
# 数据库现在可以容纳1400行,因为我们将最大页面数设置为100,并且一页可以容纳14行。
# 测试表已满的情况
def test_prints_error_message_when_table_is_full():
script = [f"insert {i} user{i} person{i}@example.com" for i in range(1, 1402)]
script.append(".exit")
result = run_script(script)
expected_result = "db > Error: Table full."
assert result[-2] == expected_result, "Test failed"
print(f"{sys._getframe().f_code.co_name} passed")
# Run the test
test_prints_error_message_when_table_is_full()
# 测试允许插入最大长度的字符串。
def test_allows_inserting_strings_that_are_maximum_length():
long_username = "a" * 32
long_email = "a" * 255
script = [
f"insert 1 {long_username} {long_email}",
"select",
".exit",
]
result = run_script(script)
expected_result = [
"db > Executed.",
f"db > (1, {long_username}, {long_email})",
"Executed.",
"db > "
]
assert result == expected_result, "Test failed"
print(f"{sys._getframe().f_code.co_name} passed")
# Run the test
test_allows_inserting_strings_that_are_maximum_length()
# 测试如果字符串太长,则会打印错误消息。
def test_prints_error_message_if_strings_are_too_long():
long_username = "a" * 33
long_email = "a" * 256
script = [
f"insert 1 {long_username} {long_email}",
"select",
".exit",
]
result = run_script(script)
expected_result = [
"db > String is too long.",
"db > Executed.",
"db > "
]
assert result == expected_result, "Test failed"
print(f"{sys._getframe().f_code.co_name} passed")
# Run the test
test_prints_error_message_if_strings_are_too_long()
# 当尝试插入带有负 ID 的行时打印错误信息
def test_negative_id_error_message():
script = [
"insert -1 cstack foo@bar.com",
"select",
".exit",
]
result = run_script(script)
expected_output = [
"db > ID must be positive.",
"db > Executed.",
"db > ",
]
assert result == expected_output, f"Expected: {expected_output}, but got: {result}"
print(f"{sys._getframe().f_code.co_name} passed")
test_negative_id_error_message()
print("all tests passed.")
第五部分 - 持久化到磁盘
测试用例:
import sys,os
from util import run_script
# 测试数据库关闭后,数据是否在数据库中
def test_keeps_data_after_closing_connection(db_file):
result1 = run_script([
"insert 1 user1 person1@example.com",
".exit",
],db_file=db_file)
assert result1 == [
"db > Executed.",
"db > ",
]
result2 = run_script([
"select",
".exit",
],db_file=db_file)
#print(f"result2: {result2}")
assert result2 == [
"db > (1, user1, person1@example.com)",
"Executed.",
"db > ",
]
print(f"{sys._getframe().f_code.co_name} passed")
if len(sys.argv)<2:
print(f"need db file path")
exit(0)
db_file = sys.argv[1]
if os.path.exists(db_file):
os.remove(db_file)
test_keeps_data_after_closing_connection(db_file)
print("all tests passed.")
持久化 golang版本:
package main
import (
"bufio"
"fmt"
"io"
"os"
"strconv"
"strings"
"unsafe"
)
const (
COLUMN_USERNAME_SIZE = 32
COLUMN_EMAIL_SIZE = 255
ID_SIZE = 4
USERNAME_SIZE = COLUMN_USERNAME_SIZE + 1
EMAIL_SIZE = COLUMN_EMAIL_SIZE + 1
ID_OFFSET = 0
USERNAME_OFFSET = ID_OFFSET + ID_SIZE
EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE
ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE
PAGE_SIZE = 4096
TABLE_MAX_PAGES = 100
ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE
TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES
)
type InputBuffer struct {
buffer string
bufferLength int
inputLength int
}
type MetaCommandResult int
const (
META_COMMAND_SUCCESS MetaCommandResult = iota
META_COMMAND_UNRECOGNIZED_COMMAND
)
type PrepareResult int
const (
PREPARE_SUCCESS PrepareResult = iota
PREPARE_NEGATIVE_ID
PREPARE_STRING_TOO_LONG
PREPARE_SYNTAX_ERROR
PREPARE_UNRECOGNIZED_STATEMENT
)
type StatementType int
const (
STATEMENT_INSERT StatementType = iota
STATEMENT_SELECT
)
type Row struct {
id uint32
username [COLUMN_USERNAME_SIZE + 1]byte
email [COLUMN_EMAIL_SIZE + 1]byte
}
type Statement struct {
typ StatementType
rowToInsert Row
}
type Pager struct {
fileDescriptor *os.File
fileLength uint32
pages [TABLE_MAX_PAGES][]byte
}
type Table struct {
numRows uint32
pager *Pager
}
type ExecuteResult int
const (
EXECUTE_SUCCESS ExecuteResult = iota
EXECUTE_TABLE_FULL
)
func newInputBuffer() *InputBuffer {
buffer := ""
return &InputBuffer{
buffer: buffer,
bufferLength: 0,
inputLength: 0,
}
}
func printRow(row *Row) {
//fmt.Printf("(%d, %s, %s)\n", row.id, row.username, row.email)
fmt.Printf("(%d, %s, %s)\n", row.id, strings.TrimRight(string(row.username[:]), "\x00"), strings.TrimRight(string(row.email[:]), "\x00"))
}
func serializeRow(source *Row, destination []byte) {
copy(destination[ID_OFFSET:], (*(*[ID_SIZE]byte)(unsafe.Pointer(&source.id)))[:])
copy(destination[USERNAME_OFFSET:], source.username[:])
copy(destination[EMAIL_OFFSET:], source.email[:])
}
func deserializeRow(source []byte, destination *Row) {
destination.id = *(*uint32)(unsafe.Pointer(&source[ID_OFFSET]))
copy(destination.username[:], source[USERNAME_OFFSET:USERNAME_OFFSET+USERNAME_SIZE])
copy(destination.email[:], source[EMAIL_OFFSET:EMAIL_OFFSET+EMAIL_SIZE])
}
func getPage(pager *Pager, pageNum uint32) []byte {
if pageNum > TABLE_MAX_PAGES {
fmt.Printf("Tried to fetch page number out of bounds. %d > %d\n", pageNum, TABLE_MAX_PAGES)
os.Exit(1)
}
if pager.pages[pageNum] == nil {
page := make([]byte, PAGE_SIZE)
numPages := pager.fileLength / PAGE_SIZE
if pager.fileLength%PAGE_SIZE != 0 {
numPages++
}
if pageNum <= numPages {
_, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
_, err = pager.fileDescriptor.Read(page)
if err != nil && err != io.EOF {
fmt.Printf("Error reading file: %v\n", err)
os.Exit(1)
}
}
pager.pages[pageNum] = page
}
return pager.pages[pageNum]
}
func rowSlot(table *Table, rowNum uint32) []byte {
pageNum := rowNum / ROWS_PER_PAGE
page := getPage(table.pager, pageNum)
rowOffset := rowNum % ROWS_PER_PAGE
byteOffset := rowOffset * ROW_SIZE
return page[byteOffset : byteOffset+ROW_SIZE]
}
func pagerOpen(filename string) *Pager {
fileDescriptor, err := os.OpenFile(filename, os.O_RDWR|os.O_CREATE, 0644)
if err != nil {
fmt.Printf("Unable to open file: %v\n", err)
os.Exit(1)
}
fileLength, err := fileDescriptor.Seek(0, os.SEEK_END)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
pager := &Pager{
fileDescriptor: fileDescriptor,
fileLength: uint32(fileLength),
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
pager.pages[i] = nil
}
return pager
}
func dbOpen(filename string) *Table {
pager := pagerOpen(filename)
numRows := pager.fileLength / ROW_SIZE
table := &Table{
numRows: numRows,
pager: pager,
}
return table
}
func pagerFlush(pager *Pager, pageNum uint32, size uint32) {
if pager.pages[pageNum] == nil {
fmt.Printf("Tried to flush null page\n")
os.Exit(1)
}
offset, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
if offset != int64(pageNum*PAGE_SIZE) {
fmt.Printf("Seek offset does not match page start\n")
os.Exit(1)
}
_, err = pager.fileDescriptor.Write(pager.pages[pageNum][:size])
if err != nil {
fmt.Printf("Error writing: %v\n", err)
os.Exit(1)
}
}
func dbClose(table *Table) {
pager := table.pager
numFullPages := table.numRows / ROWS_PER_PAGE
for i := uint32(0); i < numFullPages; i++ {
if pager.pages[i] == nil {
continue
}
pagerFlush(pager, i, PAGE_SIZE)
pager.pages[i] = nil
}
numAdditionalRows := table.numRows % ROWS_PER_PAGE
if numAdditionalRows > 0 {
pageNum := numFullPages
if pager.pages[pageNum] != nil {
pagerFlush(pager, pageNum, numAdditionalRows*ROW_SIZE)
pager.pages[pageNum] = nil
}
}
err := pager.fileDescriptor.Close()
if err != nil {
fmt.Printf("Error closing db file: %v\n", err)
os.Exit(1)
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
page := pager.pages[i]
if page != nil {
pager.pages[i] = nil
}
}
os.Exit(0)
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
buffer, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
// Ignore newline character
buffer = buffer[:len(buffer)-1]
inputBuffer.inputLength = len(buffer)
inputBuffer.buffer = buffer
}
func closeInputBuffer(inputBuffer *InputBuffer) {
inputBuffer.buffer = ""
}
func doMetaCommand(inputBuffer *InputBuffer, table *Table) MetaCommandResult {
if inputBuffer.buffer == ".exit" {
closeInputBuffer(inputBuffer)
dbClose(table)
return META_COMMAND_SUCCESS
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND
}
}
func prepareInsert(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
statement.typ = STATEMENT_INSERT
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) != 4 {
return PREPARE_SYNTAX_ERROR
}
id, err := strconv.Atoi(tokens[1])
if err != nil {
return PREPARE_NEGATIVE_ID
}
if id < 0 {
return PREPARE_NEGATIVE_ID
}
if len(tokens[2]) > COLUMN_USERNAME_SIZE || len(tokens[3]) > COLUMN_EMAIL_SIZE {
return PREPARE_STRING_TOO_LONG
}
statement.rowToInsert.id = uint32(id)
copy(statement.rowToInsert.username[:], tokens[2])
copy(statement.rowToInsert.email[:], tokens[3])
return PREPARE_SUCCESS
}
func prepareStatement(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) == 0 {
return PREPARE_UNRECOGNIZED_STATEMENT
}
switch tokens[0] {
case "insert":
return prepareInsert(inputBuffer, statement)
case "select":
statement.typ = STATEMENT_SELECT
return PREPARE_SUCCESS
default:
return PREPARE_UNRECOGNIZED_STATEMENT
}
}
func executeInsert(statement *Statement, table *Table) ExecuteResult {
if table.numRows >= TABLE_MAX_ROWS {
return EXECUTE_TABLE_FULL
}
rowToInsert := &statement.rowToInsert
serializeRow(rowToInsert, rowSlot(table, table.numRows))
table.numRows++
return EXECUTE_SUCCESS
}
func executeSelect(statement *Statement, table *Table) ExecuteResult {
var row Row
for i := uint32(0); i < table.numRows; i++ {
deserializeRow(rowSlot(table, i), &row)
printRow(&row)
}
return EXECUTE_SUCCESS
}
func executeStatement(statement *Statement, table *Table) ExecuteResult {
switch statement.typ {
case STATEMENT_INSERT:
return executeInsert(statement, table)
case STATEMENT_SELECT:
return executeSelect(statement, table)
default:
return EXECUTE_SUCCESS
}
}
func main() {
if len(os.Args) < 2 {
fmt.Println("Must supply a database filename.")
os.Exit(1)
}
filename := os.Args[1]
table := dbOpen(filename)
inputBuffer := newInputBuffer()
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if inputBuffer.buffer[0] == '.' {
switch doMetaCommand(inputBuffer, table) {
case META_COMMAND_SUCCESS:
continue
case META_COMMAND_UNRECOGNIZED_COMMAND:
fmt.Printf("Unrecognized command '%s'\n", inputBuffer.buffer)
continue
}
}
var statement Statement
switch prepareStatement(inputBuffer, &statement) {
case PREPARE_SUCCESS:
break
case PREPARE_NEGATIVE_ID:
fmt.Println("ID must be positive.")
continue
case PREPARE_STRING_TOO_LONG:
fmt.Println("String is too long.")
continue
case PREPARE_SYNTAX_ERROR:
fmt.Println("Syntax error. Could not parse statement.")
continue
case PREPARE_UNRECOGNIZED_STATEMENT:
fmt.Printf("Unrecognized keyword at start of '%s'.\n", inputBuffer.buffer)
continue
}
switch executeStatement(&statement, table) {
case EXECUTE_SUCCESS:
fmt.Println("Executed.")
case EXECUTE_TABLE_FULL:
fmt.Println("Error: Table full.")
}
}
}
运行:
go run golang/5.go test.db
db > select
Executed.
db > insert 1 ab cd
Executed.
db > select
(1, ab, cd)
Executed.
db > .exit
go run golang/5.go test.db
db > select
(1, ab, cd)
Executed.
db > .exit
第六部分 - 游标抽象
golang实现
package main
import (
"bufio"
"fmt"
"io"
"os"
"strconv"
"strings"
"unsafe"
)
const (
COLUMN_USERNAME_SIZE = 32
COLUMN_EMAIL_SIZE = 255
ID_SIZE = 4
USERNAME_SIZE = COLUMN_USERNAME_SIZE + 1
EMAIL_SIZE = COLUMN_EMAIL_SIZE + 1
ID_OFFSET = 0
USERNAME_OFFSET = ID_OFFSET + ID_SIZE
EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE
ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE
PAGE_SIZE = 4096
TABLE_MAX_PAGES = 100
ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE
TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES
)
type InputBuffer struct {
buffer string
bufferLength int
inputLength int
}
type MetaCommandResult int
const (
META_COMMAND_SUCCESS MetaCommandResult = iota
META_COMMAND_UNRECOGNIZED_COMMAND
)
type PrepareResult int
const (
PREPARE_SUCCESS PrepareResult = iota
PREPARE_NEGATIVE_ID
PREPARE_STRING_TOO_LONG
PREPARE_SYNTAX_ERROR
PREPARE_UNRECOGNIZED_STATEMENT
)
type StatementType int
const (
STATEMENT_INSERT StatementType = iota
STATEMENT_SELECT
)
type Row struct {
id uint32
username [COLUMN_USERNAME_SIZE + 1]byte
email [COLUMN_EMAIL_SIZE + 1]byte
}
type Statement struct {
typ StatementType
rowToInsert Row
}
type Pager struct {
fileDescriptor *os.File
fileLength uint32
pages [TABLE_MAX_PAGES][]byte
}
type Table struct {
numRows uint32
pager *Pager
}
type Cursor struct {
table *Table
rowNum uint32
endOfTable bool // 表示最后一个元素之后的位置
}
type ExecuteResult int
const (
EXECUTE_SUCCESS ExecuteResult = iota
EXECUTE_TABLE_FULL
)
func newInputBuffer() *InputBuffer {
buffer := ""
return &InputBuffer{
buffer: buffer,
bufferLength: 0,
inputLength: 0,
}
}
func printRow(row *Row) {
//fmt.Printf("(%d, %s, %s)\n", row.id, row.username, row.email)
fmt.Printf("(%d, %s, %s)\n", row.id, strings.TrimRight(string(row.username[:]), "\x00"), strings.TrimRight(string(row.email[:]), "\x00"))
}
func serializeRow(source *Row, destination []byte) {
copy(destination[ID_OFFSET:], (*(*[ID_SIZE]byte)(unsafe.Pointer(&source.id)))[:])
copy(destination[USERNAME_OFFSET:], source.username[:])
copy(destination[EMAIL_OFFSET:], source.email[:])
}
func deserializeRow(source []byte, destination *Row) {
destination.id = *(*uint32)(unsafe.Pointer(&source[ID_OFFSET]))
copy(destination.username[:], source[USERNAME_OFFSET:USERNAME_OFFSET+USERNAME_SIZE])
copy(destination.email[:], source[EMAIL_OFFSET:EMAIL_OFFSET+EMAIL_SIZE])
}
func getPage(pager *Pager, pageNum uint32) []byte {
if pageNum > TABLE_MAX_PAGES {
fmt.Printf("Tried to fetch page number out of bounds. %d > %d\n", pageNum, TABLE_MAX_PAGES)
os.Exit(1)
}
if pager.pages[pageNum] == nil {
page := make([]byte, PAGE_SIZE)
numPages := pager.fileLength / PAGE_SIZE
if pager.fileLength%PAGE_SIZE != 0 {
numPages++
}
if pageNum <= numPages {
_, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
_, err = pager.fileDescriptor.Read(page)
if err != nil && err != io.EOF {
fmt.Printf("Error reading file: %v\n", err)
os.Exit(1)
}
}
pager.pages[pageNum] = page
}
return pager.pages[pageNum]
}
func tableStart(table *Table) *Cursor {
cursor := &Cursor{
table: table,
rowNum: 0,
endOfTable: (table.numRows == 0),
}
return cursor
}
func tableEnd(table *Table) *Cursor {
cursor := &Cursor{
table: table,
rowNum: table.numRows,
endOfTable: true,
}
return cursor
}
func cursorValue(cursor *Cursor) []byte {
rowNum := cursor.rowNum
pageNum := rowNum / ROWS_PER_PAGE
page := getPage(cursor.table.pager, pageNum)
rowOffset := rowNum % ROWS_PER_PAGE
byteOffset := rowOffset * ROW_SIZE
return page[byteOffset : byteOffset+ROW_SIZE]
}
func cursorAdvance(cursor *Cursor) {
cursor.rowNum += 1
if cursor.rowNum >= cursor.table.numRows {
cursor.endOfTable = true
}
}
func pagerOpen(filename string) *Pager {
fileDescriptor, err := os.OpenFile(filename, os.O_RDWR|os.O_CREATE, 0644)
if err != nil {
fmt.Printf("Unable to open file: %v\n", err)
os.Exit(1)
}
fileLength, err := fileDescriptor.Seek(0, os.SEEK_END)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
pager := &Pager{
fileDescriptor: fileDescriptor,
fileLength: uint32(fileLength),
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
pager.pages[i] = nil
}
return pager
}
func dbOpen(filename string) *Table {
pager := pagerOpen(filename)
numRows := pager.fileLength / ROW_SIZE
table := &Table{
numRows: numRows,
pager: pager,
}
return table
}
func pagerFlush(pager *Pager, pageNum uint32, size uint32) {
if pager.pages[pageNum] == nil {
fmt.Printf("Tried to flush null page\n")
os.Exit(1)
}
offset, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
if offset != int64(pageNum*PAGE_SIZE) {
fmt.Printf("Seek offset does not match page start\n")
os.Exit(1)
}
_, err = pager.fileDescriptor.Write(pager.pages[pageNum][:size])
if err != nil {
fmt.Printf("Error writing: %v\n", err)
os.Exit(1)
}
}
func dbClose(table *Table) {
pager := table.pager
numFullPages := table.numRows / ROWS_PER_PAGE
for i := uint32(0); i < numFullPages; i++ {
if pager.pages[i] == nil {
continue
}
pagerFlush(pager, i, PAGE_SIZE)
pager.pages[i] = nil
}
numAdditionalRows := table.numRows % ROWS_PER_PAGE
if numAdditionalRows > 0 {
pageNum := numFullPages
if pager.pages[pageNum] != nil {
pagerFlush(pager, pageNum, numAdditionalRows*ROW_SIZE)
pager.pages[pageNum] = nil
}
}
err := pager.fileDescriptor.Close()
if err != nil {
fmt.Printf("Error closing db file: %v\n", err)
os.Exit(1)
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
page := pager.pages[i]
if page != nil {
pager.pages[i] = nil
}
}
os.Exit(0)
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
buffer, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
// Ignore newline character
buffer = buffer[:len(buffer)-1]
inputBuffer.inputLength = len(buffer)
inputBuffer.buffer = buffer
}
func closeInputBuffer(inputBuffer *InputBuffer) {
inputBuffer.buffer = ""
}
func doMetaCommand(inputBuffer *InputBuffer, table *Table) MetaCommandResult {
if inputBuffer.buffer == ".exit" {
closeInputBuffer(inputBuffer)
dbClose(table)
return META_COMMAND_SUCCESS
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND
}
}
func prepareInsert(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
statement.typ = STATEMENT_INSERT
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) != 4 {
return PREPARE_SYNTAX_ERROR
}
id, err := strconv.Atoi(tokens[1])
if err != nil {
return PREPARE_NEGATIVE_ID
}
if id < 0 {
return PREPARE_NEGATIVE_ID
}
if len(tokens[2]) > COLUMN_USERNAME_SIZE || len(tokens[3]) > COLUMN_EMAIL_SIZE {
return PREPARE_STRING_TOO_LONG
}
statement.rowToInsert.id = uint32(id)
copy(statement.rowToInsert.username[:], tokens[2])
copy(statement.rowToInsert.email[:], tokens[3])
return PREPARE_SUCCESS
}
func prepareStatement(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) == 0 {
return PREPARE_UNRECOGNIZED_STATEMENT
}
switch tokens[0] {
case "insert":
return prepareInsert(inputBuffer, statement)
case "select":
statement.typ = STATEMENT_SELECT
return PREPARE_SUCCESS
default:
return PREPARE_UNRECOGNIZED_STATEMENT
}
}
func executeInsert(statement *Statement, table *Table) ExecuteResult {
if table.numRows >= TABLE_MAX_ROWS {
return EXECUTE_TABLE_FULL
}
rowToInsert := &statement.rowToInsert
cursor := tableEnd(table)
serializeRow(rowToInsert, cursorValue(cursor))
table.numRows++
return EXECUTE_SUCCESS
}
func executeSelect(statement *Statement, table *Table) ExecuteResult {
cursor := tableStart(table)
var row Row
for cursor.endOfTable == false {
deserializeRow(cursorValue(cursor), &row)
printRow(&row)
cursorAdvance(cursor)
}
return EXECUTE_SUCCESS
}
func executeStatement(statement *Statement, table *Table) ExecuteResult {
switch statement.typ {
case STATEMENT_INSERT:
return executeInsert(statement, table)
case STATEMENT_SELECT:
return executeSelect(statement, table)
default:
return EXECUTE_SUCCESS
}
}
func main() {
if len(os.Args) < 2 {
fmt.Println("Must supply a database filename.")
os.Exit(1)
}
filename := os.Args[1]
table := dbOpen(filename)
inputBuffer := newInputBuffer()
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if inputBuffer.buffer[0] == '.' {
switch doMetaCommand(inputBuffer, table) {
case META_COMMAND_SUCCESS:
continue
case META_COMMAND_UNRECOGNIZED_COMMAND:
fmt.Printf("Unrecognized command '%s'\n", inputBuffer.buffer)
continue
}
}
var statement Statement
switch prepareStatement(inputBuffer, &statement) {
case PREPARE_SUCCESS:
break
case PREPARE_NEGATIVE_ID:
fmt.Println("ID must be positive.")
continue
case PREPARE_STRING_TOO_LONG:
fmt.Println("String is too long.")
continue
case PREPARE_SYNTAX_ERROR:
fmt.Println("Syntax error. Could not parse statement.")
continue
case PREPARE_UNRECOGNIZED_STATEMENT:
fmt.Printf("Unrecognized keyword at start of '%s'.\n", inputBuffer.buffer)
continue
}
switch executeStatement(&statement, table) {
case EXECUTE_SUCCESS:
fmt.Println("Executed.")
case EXECUTE_TABLE_FULL:
fmt.Println("Error: Table full.")
}
}
}
使用原来章节的测试用例
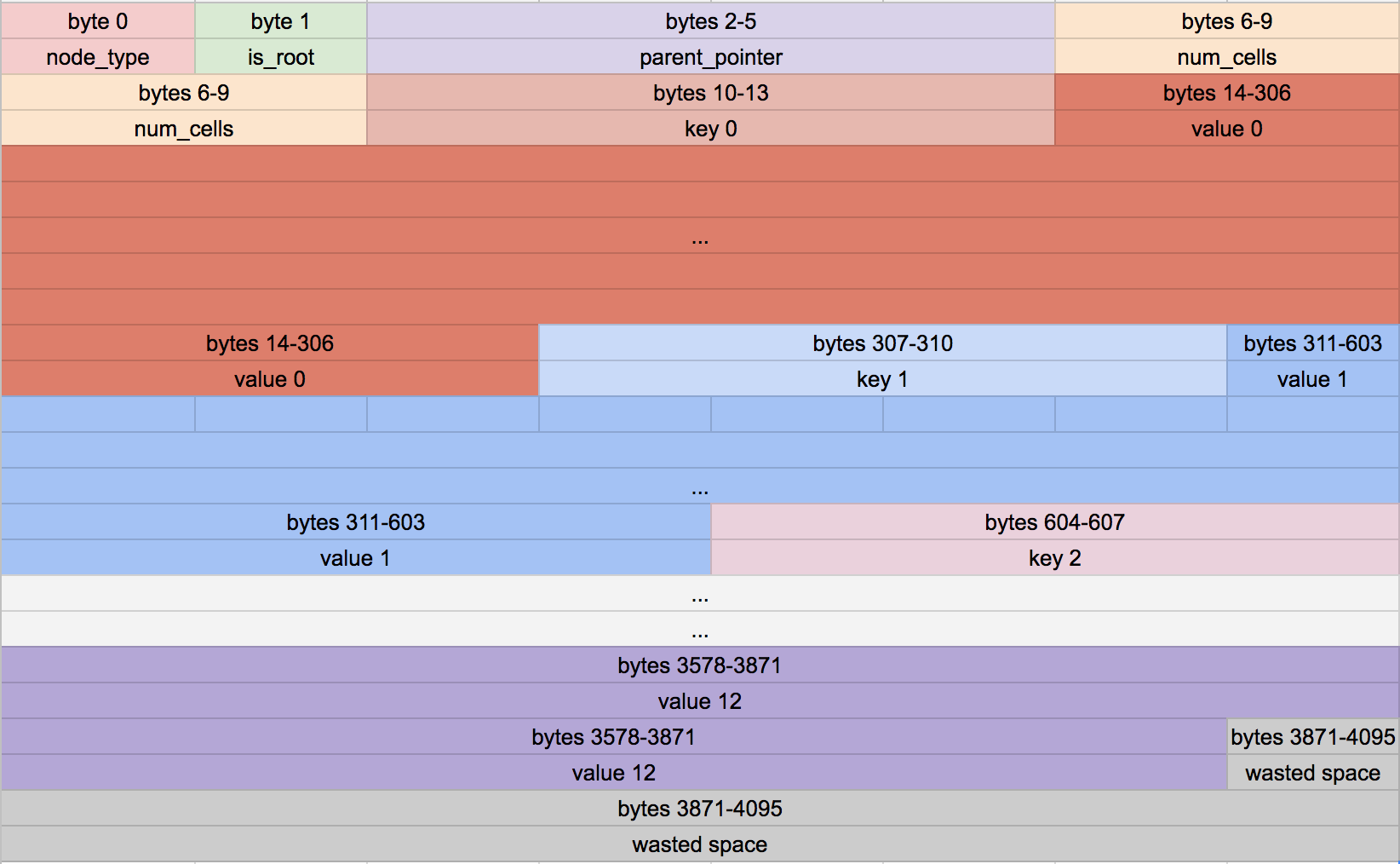
第八部分 - B-Tree叶节点格式
python 测试用例:
import sys,os
from util import run_script
# 测试btree结构
def test_one_node_btree_structure(db_file=""):
script = [
"insert 3 user3 person3@example.com",
"insert 1 user1 person1@example.com",
"insert 2 user2 person2@example.com",
".btree",
".exit"
]
result = run_script(script,db_file=db_file)
expected_result = [
"db > Executed.",
"db > Executed.",
"db > Executed.",
"db > Tree:",
"leaf (size 3)",
" - 0 : 3",
" - 1 : 1",
" - 2 : 2",
"db > "
]
print(f"result: {result}")
assert result == expected_result
print(f"{sys._getframe().f_code.co_name} passed")
# 测试打印常量
def test_print_constants(db_file=""):
script = [
".constants",
".exit",
]
result = run_script(script,db_file=db_file)
expected_result = [
"db > Constants:",
"ROW_SIZE: 293",
"COMMON_NODE_HEADER_SIZE: 6",
"LEAF_NODE_HEADER_SIZE: 10",
"LEAF_NODE_CELL_SIZE: 297",
"LEAF_NODE_SPACE_FOR_CELLS: 4086",
"LEAF_NODE_MAX_CELLS: 13",
"db > ",
]
assert result == expected_result
print(f"{sys._getframe().f_code.co_name} passed")
if len(sys.argv)<2:
print(f"need db file path")
exit(0)
db_file = sys.argv[1]
if os.path.exists(db_file):
os.remove(db_file)
test_one_node_btree_structure(db_file)
test_print_constants(db_file)
print("all tests passed.")
golang实现 (无序方式存储键)
package main
import (
"bufio"
"fmt"
"io"
"os"
"strconv"
"strings"
"unsafe"
)
const (
COLUMN_USERNAME_SIZE = 32
COLUMN_EMAIL_SIZE = 255
ID_SIZE = 4
USERNAME_SIZE = COLUMN_USERNAME_SIZE + 1
EMAIL_SIZE = COLUMN_EMAIL_SIZE + 1
ID_OFFSET = 0
USERNAME_OFFSET = ID_OFFSET + ID_SIZE
EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE
ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE
PAGE_SIZE = 4096
TABLE_MAX_PAGES = 100
)
type NodeType uint8
const (
NODE_INTERNAL NodeType = iota
NODE_LEAF
)
// Common Node Header Layout
const (
NODE_TYPE_SIZE = 1
NODE_TYPE_OFFSET = 0
IS_ROOT_SIZE = 1
IS_ROOT_OFFSET = NODE_TYPE_OFFSET + NODE_TYPE_SIZE
PARENT_POINTER_SIZE = 4
PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE
COMMON_NODE_HEADER_SIZE = NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE
)
// Leaf Node Header Layout
const (
LEAF_NODE_NUM_CELLS_SIZE = 4
LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE
LEAF_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE
)
// Leaf Node Body Layout
const (
LEAF_NODE_KEY_SIZE = 4
LEAF_NODE_KEY_OFFSET = 0
LEAF_NODE_VALUE_SIZE = ROW_SIZE
LEAF_NODE_VALUE_OFFSET = LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE
LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE
LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE
LEAF_NODE_MAX_CELLS = LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE
)
type InputBuffer struct {
buffer string
bufferLength int
inputLength int
}
type MetaCommandResult int
const (
META_COMMAND_SUCCESS MetaCommandResult = iota
META_COMMAND_UNRECOGNIZED_COMMAND
)
type PrepareResult int
const (
PREPARE_SUCCESS PrepareResult = iota
PREPARE_NEGATIVE_ID
PREPARE_STRING_TOO_LONG
PREPARE_SYNTAX_ERROR
PREPARE_UNRECOGNIZED_STATEMENT
)
type StatementType int
const (
STATEMENT_INSERT StatementType = iota
STATEMENT_SELECT
)
type Row struct {
id uint32
username [COLUMN_USERNAME_SIZE + 1]byte
email [COLUMN_EMAIL_SIZE + 1]byte
}
type Statement struct {
typ StatementType
rowToInsert Row
}
type Pager struct {
fileDescriptor *os.File
fileLength uint32
numPages uint32
pages [TABLE_MAX_PAGES][]byte
}
type Table struct {
rootPageNum uint32
pager *Pager
}
type Cursor struct {
table *Table
pageNum uint32
cellNum uint32
endOfTable bool // 表示最后一个元素之后的位置
}
type ExecuteResult int
const (
EXECUTE_SUCCESS ExecuteResult = iota
EXECUTE_TABLE_FULL
)
func newInputBuffer() *InputBuffer {
buffer := ""
return &InputBuffer{
buffer: buffer,
bufferLength: 0,
inputLength: 0,
}
}
func leafNodeNumCells(node []byte) *uint32 {
return (*uint32)(unsafe.Pointer(&node[LEAF_NODE_NUM_CELLS_OFFSET]))
}
func leafNodeCell(node []byte, cellNum uint32) []byte {
offset := LEAF_NODE_HEADER_SIZE + cellNum*LEAF_NODE_CELL_SIZE
return node[offset : offset+LEAF_NODE_CELL_SIZE]
}
func leafNodeKey(node []byte, cellNum uint32) *uint32 {
offset := LEAF_NODE_HEADER_SIZE + cellNum*LEAF_NODE_CELL_SIZE
return (*uint32)(unsafe.Pointer(&node[offset]))
}
func leafNodeValue(node []byte, cellNum uint32) []byte {
offset := LEAF_NODE_HEADER_SIZE + cellNum*LEAF_NODE_CELL_SIZE + LEAF_NODE_KEY_SIZE
return node[offset : offset+LEAF_NODE_VALUE_SIZE]
}
func printConstants() {
fmt.Printf("ROW_SIZE: %d\n", ROW_SIZE)
fmt.Printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE)
fmt.Printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE)
fmt.Printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE)
fmt.Printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS)
fmt.Printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS)
}
func printLeafNode(node []byte) {
numCells := *leafNodeNumCells(node)
fmt.Printf("leaf (size %d)\n", numCells)
for i := uint32(0); i < numCells; i++ {
key := *leafNodeKey(node, i)
fmt.Printf(" - %d : %d\n", i, key)
}
}
func printRow(row *Row) {
//fmt.Printf("(%d, %s, %s)\n", row.id, row.username, row.email)
fmt.Printf("(%d, %s, %s)\n", row.id, strings.TrimRight(string(row.username[:]), "\x00"), strings.TrimRight(string(row.email[:]), "\x00"))
}
func serializeRow(source *Row, destination []byte) {
copy(destination[ID_OFFSET:], (*(*[ID_SIZE]byte)(unsafe.Pointer(&source.id)))[:])
copy(destination[USERNAME_OFFSET:], source.username[:])
copy(destination[EMAIL_OFFSET:], source.email[:])
}
func deserializeRow(source []byte, destination *Row) {
destination.id = *(*uint32)(unsafe.Pointer(&source[ID_OFFSET]))
copy(destination.username[:], source[USERNAME_OFFSET:USERNAME_OFFSET+USERNAME_SIZE])
copy(destination.email[:], source[EMAIL_OFFSET:EMAIL_OFFSET+EMAIL_SIZE])
}
func initializeLeafNode(node []byte) {
*leafNodeNumCells(node) = 0
}
func getPage(pager *Pager, pageNum uint32) []byte {
if pageNum > TABLE_MAX_PAGES {
fmt.Printf("Tried to fetch page number out of bounds. %d > %d\n", pageNum, TABLE_MAX_PAGES)
os.Exit(1)
}
if pager.pages[pageNum] == nil {
page := make([]byte, PAGE_SIZE)
numPages := pager.fileLength / PAGE_SIZE
if pager.fileLength%PAGE_SIZE != 0 {
numPages++
}
if pageNum <= numPages {
_, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
_, err = pager.fileDescriptor.Read(page)
if err != nil && err != io.EOF {
fmt.Printf("Error reading file: %v\n", err)
os.Exit(1)
}
}
pager.pages[pageNum] = page
if pageNum >= pager.numPages {
pager.numPages = pageNum + 1
}
}
return pager.pages[pageNum]
}
func tableStart(table *Table) *Cursor {
cursor := &Cursor{
table: table,
pageNum: table.rootPageNum,
cellNum: 0,
endOfTable: false,
}
rootNode := getPage(table.pager, table.rootPageNum)
numCells := *leafNodeNumCells(rootNode)
cursor.endOfTable = (numCells == 0)
return cursor
}
func tableEnd(table *Table) *Cursor {
cursor := &Cursor{
table: table,
endOfTable: true,
pageNum: table.rootPageNum,
}
rootNode := getPage(table.pager, table.rootPageNum)
numCells := *leafNodeNumCells(rootNode)
cursor.cellNum = numCells
return cursor
}
func cursorValue(cursor *Cursor) []byte {
pageNum := cursor.pageNum
page := getPage(cursor.table.pager, pageNum)
return leafNodeValue(page, cursor.cellNum)
}
func cursorAdvance(cursor *Cursor) {
pageNum := cursor.pageNum
node := getPage(cursor.table.pager, pageNum)
cursor.cellNum += 1
if cursor.cellNum >= *leafNodeNumCells(node) {
cursor.endOfTable = true
}
}
func pagerOpen(filename string) *Pager {
fileDescriptor, err := os.OpenFile(filename, os.O_RDWR|os.O_CREATE, 0644)
if err != nil {
fmt.Printf("Unable to open file: %v\n", err)
os.Exit(1)
}
fileLength, err := fileDescriptor.Seek(0, os.SEEK_END)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
pager := &Pager{
fileDescriptor: fileDescriptor,
fileLength: uint32(fileLength),
numPages: uint32(fileLength / PAGE_SIZE),
}
if fileLength%PAGE_SIZE != 0 {
fmt.Printf("Db file is not a whole number of pages. Corrupt file.\n")
os.Exit(1)
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
pager.pages[i] = nil
}
return pager
}
func dbOpen(filename string) *Table {
pager := pagerOpen(filename)
table := &Table{
rootPageNum: 0,
pager: pager,
}
if pager.numPages == 0 {
// New database file. Initialize page 0 as leaf node.
rootNode := getPage(pager, 0)
initializeLeafNode(rootNode)
}
return table
}
func pagerFlush(pager *Pager, pageNum uint32) {
if pager.pages[pageNum] == nil {
fmt.Printf("Tried to flush null page\n")
os.Exit(1)
}
offset, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
if offset != int64(pageNum*PAGE_SIZE) {
fmt.Printf("Seek offset does not match page start\n")
os.Exit(1)
}
_, err = pager.fileDescriptor.Write(pager.pages[pageNum][:PAGE_SIZE])
if err != nil {
fmt.Printf("Error writing: %v\n", err)
os.Exit(1)
}
}
func dbClose(table *Table) {
pager := table.pager
for i := uint32(0); i < pager.numPages; i++ {
if pager.pages[i] == nil {
continue
}
pagerFlush(pager, i)
pager.pages[i] = nil
}
err := pager.fileDescriptor.Close()
if err != nil {
fmt.Printf("Error closing db file: %v\n", err)
os.Exit(1)
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
page := pager.pages[i]
if page != nil {
pager.pages[i] = nil
}
}
os.Exit(0)
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
buffer, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
// Ignore newline character
buffer = buffer[:len(buffer)-1]
inputBuffer.inputLength = len(buffer)
inputBuffer.buffer = buffer
}
func closeInputBuffer(inputBuffer *InputBuffer) {
inputBuffer.buffer = ""
}
func doMetaCommand(inputBuffer *InputBuffer, table *Table) MetaCommandResult {
if inputBuffer.buffer == ".exit" {
closeInputBuffer(inputBuffer)
dbClose(table)
return META_COMMAND_SUCCESS
} else if inputBuffer.buffer == ".btree" {
fmt.Printf(("Tree:\n"))
printLeafNode(getPage(table.pager, 0))
return META_COMMAND_SUCCESS
} else if inputBuffer.buffer == ".constants" {
fmt.Printf(("Constants:\n"))
printConstants()
return META_COMMAND_SUCCESS
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND
}
}
func prepareInsert(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
statement.typ = STATEMENT_INSERT
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) != 4 {
return PREPARE_SYNTAX_ERROR
}
id, err := strconv.Atoi(tokens[1])
if err != nil {
return PREPARE_NEGATIVE_ID
}
if id < 0 {
return PREPARE_NEGATIVE_ID
}
if len(tokens[2]) > COLUMN_USERNAME_SIZE || len(tokens[3]) > COLUMN_EMAIL_SIZE {
return PREPARE_STRING_TOO_LONG
}
statement.rowToInsert.id = uint32(id)
copy(statement.rowToInsert.username[:], tokens[2])
copy(statement.rowToInsert.email[:], tokens[3])
return PREPARE_SUCCESS
}
func prepareStatement(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) == 0 {
return PREPARE_UNRECOGNIZED_STATEMENT
}
switch tokens[0] {
case "insert":
return prepareInsert(inputBuffer, statement)
case "select":
statement.typ = STATEMENT_SELECT
return PREPARE_SUCCESS
default:
return PREPARE_UNRECOGNIZED_STATEMENT
}
}
func leafNodeInsert(cursor *Cursor, key uint32, value *Row) {
node := getPage(cursor.table.pager, cursor.pageNum)
numCells := *leafNodeNumCells(node)
if numCells >= LEAF_NODE_MAX_CELLS {
// Node full
fmt.Println("Need to implement splitting a leaf node.")
os.Exit(1)
}
if cursor.cellNum < numCells {
// Make room for new cell
for i := numCells; i > cursor.cellNum; i-- {
copy(leafNodeCell(node, i), leafNodeCell(node, i-1))
}
}
*leafNodeNumCells(node) += 1
*leafNodeKey(node, cursor.cellNum) = key
serializeRow(value, leafNodeValue(node, cursor.cellNum))
}
func executeInsert(statement *Statement, table *Table) ExecuteResult {
node := getPage(table.pager, table.rootPageNum)
if *leafNodeNumCells(node) >= LEAF_NODE_MAX_CELLS {
return EXECUTE_TABLE_FULL
}
rowToInsert := &statement.rowToInsert
cursor := tableEnd(table)
leafNodeInsert(cursor, rowToInsert.id, rowToInsert)
return EXECUTE_SUCCESS
}
func executeSelect(statement *Statement, table *Table) ExecuteResult {
cursor := tableStart(table)
var row Row
for cursor.endOfTable == false {
deserializeRow(cursorValue(cursor), &row)
printRow(&row)
cursorAdvance(cursor)
}
return EXECUTE_SUCCESS
}
func executeStatement(statement *Statement, table *Table) ExecuteResult {
switch statement.typ {
case STATEMENT_INSERT:
return executeInsert(statement, table)
case STATEMENT_SELECT:
return executeSelect(statement, table)
default:
return EXECUTE_SUCCESS
}
}
func main() {
if len(os.Args) < 2 {
fmt.Println("Must supply a database filename.")
os.Exit(1)
}
filename := os.Args[1]
table := dbOpen(filename)
inputBuffer := newInputBuffer()
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if inputBuffer.buffer[0] == '.' {
switch doMetaCommand(inputBuffer, table) {
case META_COMMAND_SUCCESS:
continue
case META_COMMAND_UNRECOGNIZED_COMMAND:
fmt.Printf("Unrecognized command '%s'\n", inputBuffer.buffer)
continue
}
}
var statement Statement
switch prepareStatement(inputBuffer, &statement) {
case PREPARE_SUCCESS:
break
case PREPARE_NEGATIVE_ID:
fmt.Println("ID must be positive.")
continue
case PREPARE_STRING_TOO_LONG:
fmt.Println("String is too long.")
continue
case PREPARE_SYNTAX_ERROR:
fmt.Println("Syntax error. Could not parse statement.")
continue
case PREPARE_UNRECOGNIZED_STATEMENT:
fmt.Printf("Unrecognized keyword at start of '%s'.\n", inputBuffer.buffer)
continue
}
switch executeStatement(&statement, table) {
case EXECUTE_SUCCESS:
fmt.Println("Executed.")
case EXECUTE_TABLE_FULL:
fmt.Println("Error: Table full.")
}
}
}
第九部分 - 二分搜索和重复键
golang实现
package main
import (
"bufio"
"fmt"
"io"
"os"
"strconv"
"strings"
"unsafe"
)
const (
COLUMN_USERNAME_SIZE = 32
COLUMN_EMAIL_SIZE = 255
ID_SIZE = 4
USERNAME_SIZE = COLUMN_USERNAME_SIZE + 1
EMAIL_SIZE = COLUMN_EMAIL_SIZE + 1
ID_OFFSET = 0
USERNAME_OFFSET = ID_OFFSET + ID_SIZE
EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE
ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE
PAGE_SIZE = 4096
TABLE_MAX_PAGES = 100
)
type NodeType uint8
const (
NODE_INTERNAL NodeType = iota
NODE_LEAF
)
// Common Node Header Layout
const (
NODE_TYPE_SIZE = 1
NODE_TYPE_OFFSET = 0
IS_ROOT_SIZE = 1
IS_ROOT_OFFSET = NODE_TYPE_OFFSET + NODE_TYPE_SIZE
PARENT_POINTER_SIZE = 4
PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE
COMMON_NODE_HEADER_SIZE = NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE
)
// Leaf Node Header Layout
const (
LEAF_NODE_NUM_CELLS_SIZE = 4
LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE
LEAF_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE
)
// Leaf Node Body Layout
const (
LEAF_NODE_KEY_SIZE = 4
LEAF_NODE_KEY_OFFSET = 0
LEAF_NODE_VALUE_SIZE = ROW_SIZE
LEAF_NODE_VALUE_OFFSET = LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE
LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE
LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE
LEAF_NODE_MAX_CELLS = LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE
)
type InputBuffer struct {
buffer string
bufferLength int
inputLength int
}
type MetaCommandResult int
const (
META_COMMAND_SUCCESS MetaCommandResult = iota
META_COMMAND_UNRECOGNIZED_COMMAND
)
type PrepareResult int
const (
PREPARE_SUCCESS PrepareResult = iota
PREPARE_NEGATIVE_ID
PREPARE_STRING_TOO_LONG
PREPARE_SYNTAX_ERROR
PREPARE_UNRECOGNIZED_STATEMENT
)
type StatementType int
const (
STATEMENT_INSERT StatementType = iota
STATEMENT_SELECT
)
type Row struct {
id uint32
username [COLUMN_USERNAME_SIZE + 1]byte
email [COLUMN_EMAIL_SIZE + 1]byte
}
type Statement struct {
typ StatementType
rowToInsert Row
}
type Pager struct {
fileDescriptor *os.File
fileLength uint32
numPages uint32
pages [TABLE_MAX_PAGES][]byte
}
type Table struct {
rootPageNum uint32
pager *Pager
}
type Cursor struct {
table *Table
pageNum uint32
cellNum uint32
endOfTable bool // 表示最后一个元素之后的位置
}
type ExecuteResult int
const (
EXECUTE_SUCCESS ExecuteResult = iota
EXECUTE_TABLE_FULL
EXECUTE_DUPLICATE_KEY
)
func newInputBuffer() *InputBuffer {
buffer := ""
return &InputBuffer{
buffer: buffer,
bufferLength: 0,
inputLength: 0,
}
}
func leafNodeNumCells(node []byte) *uint32 {
return (*uint32)(unsafe.Pointer(&node[LEAF_NODE_NUM_CELLS_OFFSET]))
}
func leafNodeCell(node []byte, cellNum uint32) []byte {
offset := LEAF_NODE_HEADER_SIZE + cellNum*LEAF_NODE_CELL_SIZE
return node[offset : offset+LEAF_NODE_CELL_SIZE]
}
func leafNodeKey(node []byte, cellNum uint32) *uint32 {
offset := LEAF_NODE_HEADER_SIZE + cellNum*LEAF_NODE_CELL_SIZE
return (*uint32)(unsafe.Pointer(&node[offset]))
}
func leafNodeValue(node []byte, cellNum uint32) []byte {
offset := LEAF_NODE_HEADER_SIZE + cellNum*LEAF_NODE_CELL_SIZE + LEAF_NODE_KEY_SIZE
return node[offset : offset+LEAF_NODE_VALUE_SIZE]
}
func printConstants() {
fmt.Printf("ROW_SIZE: %d\n", ROW_SIZE)
fmt.Printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE)
fmt.Printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE)
fmt.Printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE)
fmt.Printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS)
fmt.Printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS)
}
func printLeafNode(node []byte) {
numCells := *leafNodeNumCells(node)
fmt.Printf("leaf (size %d)\n", numCells)
for i := uint32(0); i < numCells; i++ {
key := *leafNodeKey(node, i)
fmt.Printf(" - %d : %d\n", i, key)
}
}
func printRow(row *Row) {
//fmt.Printf("(%d, %s, %s)\n", row.id, row.username, row.email)
fmt.Printf("(%d, %s, %s)\n", row.id, strings.TrimRight(string(row.username[:]), "\x00"), strings.TrimRight(string(row.email[:]), "\x00"))
}
func serializeRow(source *Row, destination []byte) {
copy(destination[ID_OFFSET:], (*(*[ID_SIZE]byte)(unsafe.Pointer(&source.id)))[:])
copy(destination[USERNAME_OFFSET:], source.username[:])
copy(destination[EMAIL_OFFSET:], source.email[:])
}
func deserializeRow(source []byte, destination *Row) {
destination.id = *(*uint32)(unsafe.Pointer(&source[ID_OFFSET]))
copy(destination.username[:], source[USERNAME_OFFSET:USERNAME_OFFSET+USERNAME_SIZE])
copy(destination.email[:], source[EMAIL_OFFSET:EMAIL_OFFSET+EMAIL_SIZE])
}
func getNodeType(node []byte) NodeType {
return NodeType(node[NODE_TYPE_OFFSET])
}
func setNodeType(node []byte, nodeType NodeType) {
node[NODE_TYPE_OFFSET] = byte(nodeType)
}
func initializeLeafNode(node []byte) {
setNodeType(node, NODE_LEAF)
*leafNodeNumCells(node) = 0
}
func getPage(pager *Pager, pageNum uint32) []byte {
if pageNum > TABLE_MAX_PAGES {
fmt.Printf("Tried to fetch page number out of bounds. %d > %d\n", pageNum, TABLE_MAX_PAGES)
os.Exit(1)
}
if pager.pages[pageNum] == nil {
// Cache miss. Allocate memory and load from file.
page := make([]byte, PAGE_SIZE)
numPages := pager.fileLength / PAGE_SIZE
// We might save a partial page at the end of the file
if pager.fileLength%PAGE_SIZE != 0 {
numPages++
}
if pageNum <= numPages {
_, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
_, err = pager.fileDescriptor.Read(page)
if err != nil && err != io.EOF {
fmt.Printf("Error reading file: %v\n", err)
os.Exit(1)
}
}
pager.pages[pageNum] = page
if pageNum >= pager.numPages {
pager.numPages = pageNum + 1
}
}
return pager.pages[pageNum]
}
func tableStart(table *Table) *Cursor {
cursor := &Cursor{
table: table,
pageNum: table.rootPageNum,
cellNum: 0,
endOfTable: false,
}
rootNode := getPage(table.pager, table.rootPageNum)
numCells := *leafNodeNumCells(rootNode)
cursor.endOfTable = (numCells == 0)
return cursor
}
func leafNodeFind(table *Table, pageNum, key uint32) *Cursor {
node := getPage(table.pager, pageNum)
numCells := *leafNodeNumCells(node)
cursor := &Cursor{table: table, pageNum: pageNum}
// Binary search
minIndex := uint32(0)
onePastMaxIndex := numCells
for onePastMaxIndex != minIndex {
index := (minIndex + onePastMaxIndex) / 2
keyAtIndex := *leafNodeKey(node, index)
if key == keyAtIndex {
cursor.cellNum = index
return cursor
}
if key < keyAtIndex {
onePastMaxIndex = index
} else {
minIndex = index + 1
}
}
cursor.cellNum = minIndex
return cursor
}
func tableFind(table *Table, key uint32) *Cursor {
rootPageNum := table.rootPageNum
rootNode := getPage(table.pager, rootPageNum)
nodeType := getNodeType(rootNode)
if nodeType == NODE_LEAF {
return leafNodeFind(table, rootPageNum, key)
} else {
fmt.Println("Need to implement searching an internal node")
os.Exit(1)
}
return nil
}
func cursorValue(cursor *Cursor) []byte {
pageNum := cursor.pageNum
page := getPage(cursor.table.pager, pageNum)
return leafNodeValue(page, cursor.cellNum)
}
func cursorAdvance(cursor *Cursor) {
pageNum := cursor.pageNum
node := getPage(cursor.table.pager, pageNum)
cursor.cellNum += 1
if cursor.cellNum >= *leafNodeNumCells(node) {
cursor.endOfTable = true
}
}
func pagerOpen(filename string) *Pager {
fileDescriptor, err := os.OpenFile(filename, os.O_RDWR|os.O_CREATE, 0644)
if err != nil {
fmt.Printf("Unable to open file: %v\n", err)
os.Exit(1)
}
fileLength, err := fileDescriptor.Seek(0, os.SEEK_END)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
pager := &Pager{
fileDescriptor: fileDescriptor,
fileLength: uint32(fileLength),
numPages: uint32(fileLength / PAGE_SIZE),
}
if fileLength%PAGE_SIZE != 0 {
fmt.Printf("Db file is not a whole number of pages. Corrupt file.\n")
os.Exit(1)
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
pager.pages[i] = nil
}
return pager
}
func dbOpen(filename string) *Table {
pager := pagerOpen(filename)
table := &Table{
rootPageNum: 0,
pager: pager,
}
if pager.numPages == 0 {
// New database file. Initialize page 0 as leaf node.
rootNode := getPage(pager, 0)
initializeLeafNode(rootNode)
}
return table
}
func pagerFlush(pager *Pager, pageNum uint32) {
if pager.pages[pageNum] == nil {
fmt.Printf("Tried to flush null page\n")
os.Exit(1)
}
offset, err := pager.fileDescriptor.Seek(int64(pageNum*PAGE_SIZE), os.SEEK_SET)
if err != nil {
fmt.Printf("Error seeking: %v\n", err)
os.Exit(1)
}
if offset != int64(pageNum*PAGE_SIZE) {
fmt.Printf("Seek offset does not match page start\n")
os.Exit(1)
}
_, err = pager.fileDescriptor.Write(pager.pages[pageNum][:PAGE_SIZE])
if err != nil {
fmt.Printf("Error writing: %v\n", err)
os.Exit(1)
}
}
func dbClose(table *Table) {
pager := table.pager
for i := uint32(0); i < pager.numPages; i++ {
if pager.pages[i] == nil {
continue
}
pagerFlush(pager, i)
pager.pages[i] = nil
}
err := pager.fileDescriptor.Close()
if err != nil {
fmt.Printf("Error closing db file: %v\n", err)
os.Exit(1)
}
for i := 0; i < TABLE_MAX_PAGES; i++ {
page := pager.pages[i]
if page != nil {
pager.pages[i] = nil
}
}
os.Exit(0)
}
func printPrompt() {
fmt.Print("db > ")
}
func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
// chatGPT init error, need to debug
//reader := bufio.NewReader(os.Stdin)
buffer, err := reader.ReadString('\n')
if err != nil {
fmt.Println("Error reading input: ", err.Error())
os.Exit(1)
}
// Ignore newline character
buffer = buffer[:len(buffer)-1]
inputBuffer.inputLength = len(buffer)
inputBuffer.buffer = buffer
}
func closeInputBuffer(inputBuffer *InputBuffer) {
inputBuffer.buffer = ""
}
func doMetaCommand(inputBuffer *InputBuffer, table *Table) MetaCommandResult {
if inputBuffer.buffer == ".exit" {
closeInputBuffer(inputBuffer)
dbClose(table)
return META_COMMAND_SUCCESS
} else if inputBuffer.buffer == ".btree" {
fmt.Printf(("Tree:\n"))
printLeafNode(getPage(table.pager, 0))
return META_COMMAND_SUCCESS
} else if inputBuffer.buffer == ".constants" {
fmt.Printf(("Constants:\n"))
printConstants()
return META_COMMAND_SUCCESS
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND
}
}
func prepareInsert(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
statement.typ = STATEMENT_INSERT
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) != 4 {
return PREPARE_SYNTAX_ERROR
}
id, err := strconv.Atoi(tokens[1])
if err != nil {
return PREPARE_NEGATIVE_ID
}
if id < 0 {
return PREPARE_NEGATIVE_ID
}
if len(tokens[2]) > COLUMN_USERNAME_SIZE || len(tokens[3]) > COLUMN_EMAIL_SIZE {
return PREPARE_STRING_TOO_LONG
}
statement.rowToInsert.id = uint32(id)
copy(statement.rowToInsert.username[:], tokens[2])
copy(statement.rowToInsert.email[:], tokens[3])
return PREPARE_SUCCESS
}
func prepareStatement(inputBuffer *InputBuffer, statement *Statement) PrepareResult {
tokens := strings.Fields(inputBuffer.buffer)
if len(tokens) == 0 {
return PREPARE_UNRECOGNIZED_STATEMENT
}
switch tokens[0] {
case "insert":
return prepareInsert(inputBuffer, statement)
case "select":
statement.typ = STATEMENT_SELECT
return PREPARE_SUCCESS
default:
return PREPARE_UNRECOGNIZED_STATEMENT
}
}
func leafNodeInsert(cursor *Cursor, key uint32, value *Row) {
node := getPage(cursor.table.pager, cursor.pageNum)
numCells := *leafNodeNumCells(node)
if numCells >= LEAF_NODE_MAX_CELLS {
// Node full
fmt.Println("Need to implement splitting a leaf node.")
os.Exit(1)
}
if cursor.cellNum < numCells {
// Make room for new cell
for i := numCells; i > cursor.cellNum; i-- {
copy(leafNodeCell(node, i), leafNodeCell(node, i-1))
}
}
*leafNodeNumCells(node) += 1
*leafNodeKey(node, cursor.cellNum) = key
serializeRow(value, leafNodeValue(node, cursor.cellNum))
}
func executeInsert(statement *Statement, table *Table) ExecuteResult {
node := getPage(table.pager, table.rootPageNum)
numCells := *leafNodeNumCells(node)
if numCells >= LEAF_NODE_MAX_CELLS {
return EXECUTE_TABLE_FULL
}
rowToInsert := &statement.rowToInsert
keyToInsert := rowToInsert.id
cursor := tableFind(table, keyToInsert)
if cursor.cellNum < numCells {
keyAtIndex := *leafNodeKey(node, cursor.cellNum)
if keyAtIndex == keyToInsert {
return EXECUTE_DUPLICATE_KEY
}
}
leafNodeInsert(cursor, rowToInsert.id, rowToInsert)
return EXECUTE_SUCCESS
}
func executeSelect(statement *Statement, table *Table) ExecuteResult {
cursor := tableStart(table)
var row Row
for cursor.endOfTable == false {
deserializeRow(cursorValue(cursor), &row)
printRow(&row)
cursorAdvance(cursor)
}
return EXECUTE_SUCCESS
}
func executeStatement(statement *Statement, table *Table) ExecuteResult {
switch statement.typ {
case STATEMENT_INSERT:
return executeInsert(statement, table)
case STATEMENT_SELECT:
return executeSelect(statement, table)
default:
return EXECUTE_SUCCESS
}
}
func main() {
if len(os.Args) < 2 {
fmt.Println("Must supply a database filename.")
os.Exit(1)
}
filename := os.Args[1]
table := dbOpen(filename)
inputBuffer := newInputBuffer()
reader := bufio.NewReader(os.Stdin)
for {
printPrompt()
readInput(reader, inputBuffer)
if inputBuffer.buffer[0] == '.' {
switch doMetaCommand(inputBuffer, table) {
case META_COMMAND_SUCCESS:
continue
case META_COMMAND_UNRECOGNIZED_COMMAND:
fmt.Printf("Unrecognized command '%s'\n", inputBuffer.buffer)
continue
}
}
var statement Statement
switch prepareStatement(inputBuffer, &statement) {
case PREPARE_SUCCESS:
break
case PREPARE_NEGATIVE_ID:
fmt.Println("ID must be positive.")
continue
case PREPARE_STRING_TOO_LONG:
fmt.Println("String is too long.")
continue
case PREPARE_SYNTAX_ERROR:
fmt.Println("Syntax error. Could not parse statement.")
continue
case PREPARE_UNRECOGNIZED_STATEMENT:
fmt.Printf("Unrecognized keyword at start of '%s'.\n", inputBuffer.buffer)
continue
}
switch executeStatement(&statement, table) {
case EXECUTE_SUCCESS:
fmt.Println("Executed.")
case EXECUTE_TABLE_FULL:
fmt.Println("Error: Table full.")
case EXECUTE_DUPLICATE_KEY:
fmt.Println("Error: Duplicate key.")
}
}
}
第十部分 - 分裂叶子节点
测试:
import sys,os
from util import run_script
# 测试btree有序结构
def test_btree_order_structure(db_file=""):
script = [
"insert 3 user3 person3@example.com",
"insert 1 user1 person1@example.com",
"insert 2 user2 person2@example.com",
".btree",
".exit"
]
result = run_script(script,db_file=db_file)
expected_result = [
"db > Executed.",
"db > Executed.",
"db > Executed.",
"db > Tree:",
"- leaf (size 3)",
" - 1",
" - 2",
" - 3",
"db > "
]
print(f"result: {result}")
assert result == expected_result
print(f"{sys._getframe().f_code.co_name} passed")
# 测试打印3个叶子节点的btree
def test_print_structure_of_3_leaf_node_btree(db_file=""):
script = [f"insert {i} user{i} person{i}@example.com" for i in range(1, 15)]
script.append(".btree")
script.append("insert 15 user15 person15@example.com")
script.append(".exit")
result = run_script(script,db_file=db_file,is_remove=True)
expected_result = [
"db > Tree:",
"- internal (size 1)",
" - leaf (size 7)",
" - 1",
" - 2",
" - 3",
" - 4",
" - 5",
" - 6",
" - 7",
" - key 7",
" - leaf (size 7)",
" - 8",
" - 9",
" - 10",
" - 11",
" - 12",
" - 13",
" - 14",
"db > Need to implement searching an internal node",
]
print(f"result: {result}")
assert result[14:] == expected_result
print(f"{sys._getframe().f_code.co_name} passed")
if len(sys.argv)<2:
print(f"need db file path")
exit(0)
db_file = sys.argv[1]
if os.path.exists(db_file):
print(f"{db_file} exists, remove it first")
os.remove(db_file)
test_btree_order_structure(db_file)
test_print_structure_of_3_leaf_node_btree(db_file)
print("all tests passed.")
diff golang/9.go golang/10.go
62a63,84
> /*
> * Leaf Node Split
> */
> const LEAF_NODE_RIGHT_SPLIT_COUNT = (LEAF_NODE_MAX_CELLS + 1) / 2
> const LEAF_NODE_LEFT_SPLIT_COUNT = LEAF_NODE_MAX_CELLS + 1 - LEAF_NODE_RIGHT_SPLIT_COUNT
>
> /*
> * Internal Node Header Layout
> */
> const INTERNAL_NODE_NUM_KEYS_SIZE = 4
> const INTERNAL_NODE_NUM_KEYS_OFFSET = COMMON_NODE_HEADER_SIZE
> const INTERNAL_NODE_RIGHT_CHILD_SIZE = 4
> const INTERNAL_NODE_RIGHT_CHILD_OFFSET = INTERNAL_NODE_NUM_KEYS_OFFSET + INTERNAL_NODE_NUM_KEYS_SIZE
> const INTERNAL_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE + INTERNAL_NODE_NUM_KEYS_SIZE + INTERNAL_NODE_RIGHT_CHILD_SIZE
>
> /*
> * Internal Node Body Layout
> */
> const INTERNAL_NODE_KEY_SIZE = 4
> const INTERNAL_NODE_CHILD_SIZE = 4
> const INTERNAL_NODE_CELL_SIZE = INTERNAL_NODE_CHILD_SIZE + INTERNAL_NODE_KEY_SIZE
>
168,173c190,192
< func printLeafNode(node []byte) {
< numCells := *leafNodeNumCells(node)
< fmt.Printf("leaf (size %d)\n", numCells)
< for i := uint32(0); i < numCells; i++ {
< key := *leafNodeKey(node, i)
< fmt.Printf(" - %d : %d\n", i, key)
---
> func indent(level uint32) {
> for i := uint32(0); i < level; i++ {
> fmt.Print(" ")
199a219,239
> }
>
> func isNodeRoot(node []byte) bool {
> value := node[IS_ROOT_OFFSET]
> return value != 0
> }
>
> func setNodeRoot(node []byte, isRoot bool) {
> if isRoot {
> node[IS_ROOT_OFFSET] = 1
> } else {
> node[IS_ROOT_OFFSET] = 0
> }
> }
>
> func internalNodeNumKeys(node []byte) *uint32 {
> return (*uint32)(unsafe.Pointer(&node[INTERNAL_NODE_NUM_KEYS_OFFSET]))
> }
>
> func internalNodeRightChild(node []byte) *uint32 {
> return (*uint32)(unsafe.Pointer(&node[INTERNAL_NODE_RIGHT_CHILD_OFFSET]))
201a242,246
> func internalNodeCell(node []byte, cellNum uint32) *uint32 {
> offset := INTERNAL_NODE_HEADER_SIZE + cellNum*INTERNAL_NODE_CELL_SIZE
> return (*uint32)(unsafe.Pointer(&node[offset]))
> }
>
203a249
> setNodeRoot(node, false)
206a253,258
> func initializeInternalNode(node []byte) {
> setNodeType(node, NODE_INTERNAL)
> setNodeRoot(node, false)
> *internalNodeNumKeys(node) = 0
> }
>
243a296,341
> }
>
> func internalNodeChild(node []byte, childNum uint32) *uint32 {
> numKeys := *internalNodeNumKeys(node)
> if childNum > numKeys {
> fmt.Printf("Tried to access childNum %d > numKeys %d\n", childNum, numKeys)
> os.Exit(1)
> }
> if childNum == numKeys {
> return internalNodeRightChild(node)
> }
> return internalNodeCell(node, childNum)
> }
>
> func internalNodeKey(node []byte, keyNum uint32) *uint32 {
> offset := INTERNAL_NODE_HEADER_SIZE + keyNum*INTERNAL_NODE_CELL_SIZE + INTERNAL_NODE_CHILD_SIZE
> return (*uint32)(unsafe.Pointer(&node[offset]))
> }
>
> func printTree(pager *Pager, pageNum, indentationLevel uint32) {
> node := getPage(pager, pageNum)
> numKeys, child := uint32(0), uint32(0)
>
> switch getNodeType(node) {
> case NODE_LEAF:
> numKeys = *leafNodeNumCells(node)
> indent(indentationLevel)
> fmt.Printf("- leaf (size %d)\n", numKeys)
> for i := uint32(0); i < numKeys; i++ {
> indent(indentationLevel + 1)
> fmt.Printf("- %d\n", *leafNodeKey(node, i))
> }
> case NODE_INTERNAL:
> numKeys = *internalNodeNumKeys(node)
> indent(indentationLevel)
> fmt.Printf("- internal (size %d)\n", numKeys)
> for i := uint32(0); i < numKeys; i++ {
> child = *internalNodeChild(node, i)
> printTree(pager, child, indentationLevel+1)
>
> indent(indentationLevel + 1)
> fmt.Printf("- key %d\n", *internalNodeKey(node, i))
> }
> child = *internalNodeRightChild(node)
> printTree(pager, child, indentationLevel+1)
> }
358a457
> setNodeRoot(rootNode, true)
445c544
< printLeafNode(getPage(table.pager, 0))
---
> printTree(table.pager, 0, 0)
499a599,616
> }
>
> func getNodeMaxKey(node []byte) uint32 {
> switch getNodeType(node) {
> case NODE_INTERNAL:
> numKeys := *internalNodeNumKeys(node)
> return *internalNodeKey(node, numKeys-1)
> case NODE_LEAF:
> numCells := *leafNodeNumCells(node)
> return *leafNodeKey(node, numCells-1)
> default:
> // Handle other node types if needed
> return 0 // or appropriate default value
> }
> }
>
> func getUnusedPageNum(pager *Pager) uint32 {
> return pager.numPages
501a619,683
> func createNewRoot(table *Table, rightChildPageNum uint32) {
> root := getPage(table.pager, table.rootPageNum)
> //rightChild := getPage(table.pager, rightChildPageNum)
> leftChildPageNum := getUnusedPageNum(table.pager)
> leftChild := getPage(table.pager, leftChildPageNum)
>
> // Left child gets data copied from the old root
> copy(leftChild, root[:])
> setNodeRoot(leftChild, false)
>
> // Root becomes a new internal node with one key and two children
> initializeInternalNode(root)
> setNodeRoot(root, true)
> *internalNodeNumKeys(root) = 1
> *internalNodeChild(root, 0) = leftChildPageNum
>
> leftChildMaxKey := getNodeMaxKey(leftChild)
> *internalNodeKey(root, 0) = leftChildMaxKey
> *internalNodeRightChild(root) = rightChildPageNum
> }
>
> // 创建一个新节点并将一半单元格移动过去。
> // 在两个节点中的一个中插入新值。
> // 更新父节点或创建一个新的父节点。
> func leafNodeSplitAndInsert(cursor *Cursor, key uint32, value *Row) {
> oldNode := getPage(cursor.table.pager, cursor.pageNum)
> newPageNum := getUnusedPageNum(cursor.table.pager)
> newNode := getPage(cursor.table.pager, newPageNum)
> initializeLeafNode(newNode)
>
> /*
> 所有现有键以及新键应该均匀分布
> 在旧(左)和新(右)节点之间。
> 从右侧开始,将每个键移动到正确的位置。
> */
> for i := LEAF_NODE_MAX_CELLS; i >= 0; i-- {
> var destinationNode []byte
> if i >= LEAF_NODE_LEFT_SPLIT_COUNT {
> destinationNode = newNode
> } else {
> destinationNode = oldNode
> }
> indexWithinNode := i % LEAF_NODE_LEFT_SPLIT_COUNT
> destination := leafNodeCell(destinationNode, uint32(indexWithinNode))
>
> if i == int(cursor.cellNum) {
> serializeRow(value, destination)
> } else if i > int(cursor.cellNum) {
> copy(destination, leafNodeCell(oldNode, uint32(i-1))[:LEAF_NODE_CELL_SIZE])
> } else {
> copy(destination, leafNodeCell(oldNode, uint32(i))[:LEAF_NODE_CELL_SIZE])
> }
> }
>
> /* 在两个叶子节点上更新单元格计数 */
> *leafNodeNumCells(oldNode) = LEAF_NODE_LEFT_SPLIT_COUNT
> *leafNodeNumCells(newNode) = LEAF_NODE_RIGHT_SPLIT_COUNT
> if isNodeRoot(oldNode) {
> createNewRoot(cursor.table, newPageNum)
> } else {
> fmt.Println("Need to implement updating parent after split")
> os.Exit(1)
> }
> }
>
507,509c689,690
< // Node full
< fmt.Println("Need to implement splitting a leaf node.")
< os.Exit(1)
---
> leafNodeSplitAndInsert(cursor, key, value)
> return
527,529d707
< if numCells >= LEAF_NODE_MAX_CELLS {
< return EXECUTE_TABLE_FULL
< }
第十一部分 - 递归搜索 B 树
测试:
import sys,os
from util import run_script
# 测试打印3个叶子节点的btree
def test_print_structure_of_3_leaf_node_btree(db_file=""):
script = [f"insert {i} user{i} person{i}@example.com" for i in range(1, 15)]
script.append(".btree")
script.append("insert 15 user15 person15@example.com")
script.append(".exit")
result = run_script(script,db_file=db_file)
expected_result = [
"db > Tree:",
"- internal (size 1)",
" - leaf (size 7)",
" - 1",
" - 2",
" - 3",
" - 4",
" - 5",
" - 6",
" - 7",
" - key 7",
" - leaf (size 7)",
" - 8",
" - 9",
" - 10",
" - 11",
" - 12",
" - 13",
" - 14",
"db > Executed.",
"db > ",
]
print(f"result: {result}")
assert result[14:] == expected_result
print(f"{sys._getframe().f_code.co_name} passed")
# 数据库现在可以容纳1400行,因为我们将最大页面数设置为100,并且一页可以容纳14行。
# 测试表已满的情况
def test_prints_error_message_when_table_is_full(db_file=""):
script = [f"insert {i} user{i} person{i}@example.com" for i in range(1, 1402)]
script.append(".exit")
result = run_script(script,db_file=db_file,is_remove=True)
expected_result = [
"db > Executed.",
"db > Need to implement updating parent after split",
]
print(f"result: {result}")
assert result[-2:] == expected_result, "Test failed"
print(f"{sys._getframe().f_code.co_name} passed")
if len(sys.argv)<2:
print(f"need db file path")
exit(0)
db_file = sys.argv[1]
if os.path.exists(db_file):
print(f"{db_file} exists, remove it first")
os.remove(db_file)
test_print_structure_of_3_leaf_node_btree(db_file)
test_prints_error_message_when_table_is_full(db_file)
print("all tests passed.")
diff golang/10.go golang/11.go
383a384,391
>
> func internalNodeFind(table *Table, pageNum, key uint32) *Cursor {
> node := getPage(table.pager, pageNum)
> numKeys := *internalNodeNumKeys(node)
>
> // Binary search to find index of child to search
> minIndex := uint32(0)
> maxIndex := numKeys // there is one more child than key
384a393,416
> for minIndex != maxIndex {
> index := (minIndex + maxIndex) / 2
> keyToRight := *internalNodeKey(node, index)
> if keyToRight >= key {
> maxIndex = index
> } else {
> minIndex = index + 1
> }
> }
>
> childNum := *internalNodeChild(node, minIndex)
> child := getPage(table.pager, childNum)
>
> switch getNodeType(child) {
> case NODE_LEAF:
> return leafNodeFind(table, childNum, key)
> case NODE_INTERNAL:
> return internalNodeFind(table, childNum, key)
> default:
> // Handle other node types if needed
> return nil
> }
> }
>
393,394c425
< fmt.Println("Need to implement searching an internal node")
< os.Exit(1)
---
> return internalNodeFind(table, rootPageNum, key)
第十二部分 - 扫描多层 B 树
测试:
import sys,os
from util import run_script
def test_prints_all_rows_in_multi_level_tree(db_file=""):
script = []
for i in range(1, 16):
script.append(f"insert {i} user{i} person{i}@example.com")
script.append("select")
script.append(".exit")
result = run_script(script,db_file=db_file)
expected_output = [
"db > (1, user1, person1@example.com)",
"(2, user2, person2@example.com)",
"(3, user3, person3@example.com)",
"(4, user4, person4@example.com)",
"(5, user5, person5@example.com)",
"(6, user6, person6@example.com)",
"(7, user7, person7@example.com)",
"(8, user8, person8@example.com)",
"(9, user9, person9@example.com)",
"(10, user10, person10@example.com)",
"(11, user11, person11@example.com)",
"(12, user12, person12@example.com)",
"(13, user13, person13@example.com)",
"(14, user14, person14@example.com)",
"(15, user15, person15@example.com)",
"Executed.", "db > ",
]
print(f"result: {result}")
assert result[15:] == expected_output
print(f"{sys._getframe().f_code.co_name} passed")
# 测试打印常量
def test_print_constants(db_file=""):
script = [
".constants",
".exit",
]
result = run_script(script,db_file=db_file)
expected_result = [
"db > Constants:",
"ROW_SIZE: 293",
"COMMON_NODE_HEADER_SIZE: 6",
"LEAF_NODE_HEADER_SIZE: 14",
"LEAF_NODE_CELL_SIZE: 297",
"LEAF_NODE_SPACE_FOR_CELLS: 4082",
"LEAF_NODE_MAX_CELLS: 13",
"db > ",
]
assert result == expected_result
print(f"{sys._getframe().f_code.co_name} passed")
if len(sys.argv)<2:
print(f"need db file path")
exit(0)
db_file = sys.argv[1]
if os.path.exists(db_file):
print(f"{db_file} exists, remove it first")
os.remove(db_file)
test_prints_all_rows_in_multi_level_tree(db_file=db_file)
test_print_constants(db_file=db_file)
print("all tests passed.")
diff golang/11.go golang/12.go
49c49,51
< LEAF_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE
---
> LEAF_NODE_NEXT_LEAF_SIZE = 4
> LEAF_NODE_NEXT_LEAF_OFFSET = LEAF_NODE_NUM_CELLS_OFFSET + LEAF_NODE_NUM_CELLS_SIZE
> LEAF_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE + LEAF_NODE_NEXT_LEAF_SIZE
178a181,184
> }
>
> func leafNodeNextLeaf(node []byte) *uint32 {
> return (*uint32)(unsafe.Pointer(&node[LEAF_NODE_NEXT_LEAF_OFFSET]))
250a257
> *leafNodeNextLeaf(node) = 0 // 0 表示无兄弟节点
341,349d347
< }
< }
<
< func tableStart(table *Table) *Cursor {
< cursor := &Cursor{
< table: table,
< pageNum: table.rootPageNum,
< cellNum: 0,
< endOfTable: false,
351,356d348
<
< rootNode := getPage(table.pager, table.rootPageNum)
< numCells := *leafNodeNumCells(rootNode)
< cursor.endOfTable = (numCells == 0)
<
< return cursor
441c433,441
< cursor.endOfTable = true
---
> /* 前进到下一个叶子节点 */
> nextPageNum := *leafNodeNextLeaf(node)
> if nextPageNum == 0 {
> /* 这是最右边的叶子节点 */
> cursor.endOfTable = true
> } else {
> cursor.pageNum = nextPageNum
> cursor.cellNum = 0
> }
678a679,680
> *leafNodeNextLeaf(newNode) = *leafNodeNextLeaf(oldNode)
> *leafNodeNextLeaf(oldNode) = newPageNum
696c698,699
< serializeRow(value, destination)
---
> serializeRow(value, leafNodeValue(destinationNode, uint32(indexWithinNode)))
> *leafNodeKey(destinationNode, uint32(indexWithinNode)) = key
754a758,766
> func tableStart(table *Table) *Cursor {
> cursor := tableFind(table, 0)
> node := getPage(table.pager, cursor.pageNum)
> numCells := *leafNodeNumCells(node)
> cursor.endOfTable = numCells == 0
>
> return cursor
> }
>
第十三部分 - 分裂叶子节点后更新父节点
测试:
import sys,os
from util import run_script
# 数据库现在可以容纳1400行,因为我们将最大页面数设置为100,并且一页可以容纳14行。
# 测试表已满的情况
def test_prints_error_message_when_table_is_full(db_file=""):
script = [f"insert {i} user{i} person{i}@example.com" for i in range(1, 1402)]
script.append(".exit")
result = run_script(script,db_file=db_file,is_remove=True)
expected_result = [
"db > Executed.",
"db > Need to implement splitting internal node",
]
print(f"result: {result}")
assert result[-2:] == expected_result, "Test failed"
print(f"{sys._getframe().f_code.co_name} passed")
# 测试4个叶子节点的B+树的结构
def test_prints_structure_of_4_leaf_node_btree(db_file=""):
script = [
"insert 18 user18 person18@example.com",
"insert 7 user7 person7@example.com",
"insert 10 user10 person10@example.com",
"insert 29 user29 person29@example.com",
"insert 23 user23 person23@example.com",
"insert 4 user4 person4@example.com",
"insert 14 user14 person14@example.com",
"insert 30 user30 person30@example.com",
"insert 15 user15 person15@example.com",
"insert 26 user26 person26@example.com",
"insert 22 user22 person22@example.com",
"insert 19 user19 person19@example.com",
"insert 2 user2 person2@example.com",
"insert 1 user1 person1@example.com",
"insert 21 user21 person21@example.com",
"insert 11 user11 person11@example.com",
"insert 6 user6 person6@example.com",
"insert 20 user20 person20@example.com",
"insert 5 user5 person5@example.com",
"insert 8 user8 person8@example.com",
"insert 9 user9 person9@example.com",
"insert 3 user3 person3@example.com",
"insert 12 user12 person12@example.com",
"insert 27 user27 person27@example.com",
"insert 17 user17 person17@example.com",
"insert 16 user16 person16@example.com",
"insert 13 user13 person13@example.com",
"insert 24 user24 person24@example.com",
"insert 25 user25 person25@example.com",
"insert 28 user28 person28@example.com",
".btree",
".exit",
]
result = run_script(script,db_file=db_file)
expected_output = [
"db > Tree:",
"- internal (size 3)",
" - leaf (size 7)",
" - 1",
" - 2",
" - 3",
" - 4",
" - 5",
" - 6",
" - 7",
" - key 7",
" - leaf (size 8)",
" - 8",
" - 9",
" - 10",
" - 11",
" - 12",
" - 13",
" - 14",
" - 15",
" - key 15",
" - leaf (size 7)",
" - 16",
" - 17",
" - 18",
" - 19",
" - 20",
" - 21",
" - 22",
" - key 22",
" - leaf (size 8)",
" - 23",
" - 24",
" - 25",
" - 26",
" - 27",
" - 28",
" - 29",
" - 30",
"db > ",
]
print(f"result: {result}")
assert result[30:] == expected_output
print(f"{sys._getframe().f_code.co_name} passed")
if len(sys.argv)<2:
print(f"need db file path")
exit(0)
db_file = sys.argv[1]
if os.path.exists(db_file):
print(f"{db_file} exists, remove it first")
os.remove(db_file)
test_prints_error_message_when_table_is_full(db_file)
test_prints_structure_of_4_leaf_node_btree(db_file)
print("all tests passed.")
diff golang/12.go golang/13.go
85a86
> const INTERNAL_NODE_MAX_CELLS = 3
184a186,189
> }
>
> func nodeParent(node []byte) *uint32 {
> return (*uint32)(unsafe.Pointer(&node[PARENT_POINTER_OFFSET]))
319a325,399
> }
>
> // 返回应包含给定键的子节点的索引。
> func internalNodeFindChild(node []byte, key uint32) uint32 {
> numKeys := *internalNodeNumKeys(node)
>
> // Binary search
> minIndex := uint32(0)
> maxIndex := numKeys // there is one more child than key
>
> for minIndex != maxIndex {
> index := (minIndex + maxIndex) / 2
> keyToRight := *internalNodeKey(node, index)
>
> if keyToRight >= key {
> maxIndex = index
> } else {
> minIndex = index + 1
> }
> }
>
> return minIndex
> }
>
> func updateInternalNodeKey(node []byte, oldKey, newKey uint32) {
> oldChildIndex := internalNodeFindChild(node, oldKey)
> *internalNodeKey(node, oldChildIndex) = newKey
> }
>
> func getNodeMaxKey(node []byte) uint32 {
> switch getNodeType(node) {
> case NODE_INTERNAL:
> return *internalNodeKey(node, *internalNodeNumKeys(node)-1)
> case NODE_LEAF:
> return *leafNodeKey(node, *leafNodeNumCells(node)-1)
> default:
> // Handle other node types if needed
> return 0 // or appropriate default value
> }
> }
>
> func internalNodeInsert(table *Table, parentPageNum, childPageNum uint32) {
> parent := getPage(table.pager, parentPageNum)
> child := getPage(table.pager, childPageNum)
> childMaxKey := getNodeMaxKey(child)
> index := internalNodeFindChild(parent, childMaxKey)
>
> originalNumKeys := *internalNodeNumKeys(parent)
> *internalNodeNumKeys(parent) = originalNumKeys + 1
>
> if originalNumKeys >= INTERNAL_NODE_MAX_CELLS {
> fmt.Println("Need to implement splitting internal node")
> os.Exit(1)
> }
>
> rightChildPageNum := *internalNodeRightChild(parent)
> rightChild := getPage(table.pager, rightChildPageNum)
>
> if childMaxKey > getNodeMaxKey(rightChild) {
> // Replace right child
> *internalNodeChild(parent, originalNumKeys) = rightChildPageNum
> *internalNodeKey(parent, originalNumKeys) = getNodeMaxKey(rightChild)
> *internalNodeRightChild(parent) = childPageNum
> } else {
> // Make space for the new cell
> for i := originalNumKeys; i > index; i-- {
> //destination := internalNodeCell(parent, i)
> //source := internalNodeCell(parent, i-1)
> // c: memcpy(destination, source, INTERNAL_NODE_CELL_SIZE);
> //copy(destination, source)
> *internalNodeCell(parent, i) = *internalNodeCell(parent, i-1)
> }
> *internalNodeChild(parent, index) = childPageNum
> *internalNodeKey(parent, index) = childMaxKey
> }
632,645d711
< func getNodeMaxKey(node []byte) uint32 {
< switch getNodeType(node) {
< case NODE_INTERNAL:
< numKeys := *internalNodeNumKeys(node)
< return *internalNodeKey(node, numKeys-1)
< case NODE_LEAF:
< numCells := *leafNodeNumCells(node)
< return *leafNodeKey(node, numCells-1)
< default:
< // Handle other node types if needed
< return 0 // or appropriate default value
< }
< }
<
652c718
< //rightChild := getPage(table.pager, rightChildPageNum)
---
> rightChild := getPage(table.pager, rightChildPageNum)
668a735,736
> *nodeParent(leftChild) = table.rootPageNum
> *nodeParent(rightChild) = table.rootPageNum
675a744
> oldMax := getNodeMaxKey(oldNode)
678a748
> *nodeParent(newNode) = *nodeParent(oldNode)
713,714c783,788
< fmt.Println("Need to implement updating parent after split")
< os.Exit(1)
---
> parentPageNum := *nodeParent(oldNode)
> newMax := getNodeMaxKey(oldNode)
> parent := getPage(cursor.table.pager, parentPageNum)
>
> updateInternalNodeKey(parent, oldMax, newMax)
> internalNodeInsert(cursor.table, parentPageNum, newPageNum)
第十四部分 - 拆分内部节点
测试:
import sys,os
from util import run_script
# 测试7个叶子节点的B+树的结构
def test_prints_structure_of_7_leaf_node_btree(db_file=""):
script = [
"insert 58 user58 person58@example.com",
"insert 56 user56 person56@example.com",
"insert 8 user8 person8@example.com",
"insert 54 user54 person54@example.com",
"insert 77 user77 person77@example.com",
"insert 7 user7 person7@example.com",
"insert 25 user25 person25@example.com",
"insert 71 user71 person71@example.com",
"insert 13 user13 person13@example.com",
"insert 22 user22 person22@example.com",
"insert 53 user53 person53@example.com",
"insert 51 user51 person51@example.com",
"insert 59 user59 person59@example.com",
"insert 32 user32 person32@example.com",
"insert 36 user36 person36@example.com",
"insert 79 user79 person79@example.com",
"insert 10 user10 person10@example.com",
"insert 33 user33 person33@example.com",
"insert 20 user20 person20@example.com",
"insert 4 user4 person4@example.com",
"insert 35 user35 person35@example.com",
"insert 76 user76 person76@example.com",
"insert 49 user49 person49@example.com",
"insert 24 user24 person24@example.com",
"insert 70 user70 person70@example.com",
"insert 48 user48 person48@example.com",
"insert 39 user39 person39@example.com",
"insert 15 user15 person15@example.com",
"insert 47 user47 person47@example.com",
"insert 30 user30 person30@example.com",
"insert 86 user86 person86@example.com",
"insert 31 user31 person31@example.com",
"insert 68 user68 person68@example.com",
"insert 37 user37 person37@example.com",
"insert 66 user66 person66@example.com",
"insert 63 user63 person63@example.com",
"insert 40 user40 person40@example.com",
"insert 78 user78 person78@example.com",
"insert 19 user19 person19@example.com",
"insert 46 user46 person46@example.com",
"insert 14 user14 person14@example.com",
"insert 81 user81 person81@example.com",
"insert 72 user72 person72@example.com",
"insert 6 user6 person6@example.com",
"insert 50 user50 person50@example.com",
"insert 85 user85 person85@example.com",
"insert 67 user67 person67@example.com",
"insert 2 user2 person2@example.com",
"insert 55 user55 person55@example.com",
"insert 69 user69 person69@example.com",
"insert 5 user5 person5@example.com",
"insert 65 user65 person65@example.com",
"insert 52 user52 person52@example.com",
"insert 1 user1 person1@example.com",
"insert 29 user29 person29@example.com",
"insert 9 user9 person9@example.com",
"insert 43 user43 person43@example.com",
"insert 75 user75 person75@example.com",
"insert 21 user21 person21@example.com",
"insert 82 user82 person82@example.com",
"insert 12 user12 person12@example.com",
"insert 18 user18 person18@example.com",
"insert 60 user60 person60@example.com",
"insert 44 user44 person44@example.com",
".btree",
".exit",
]
result = run_script(script,db_file=db_file)
expected_output = [
"db > Tree:",
"- internal (size 1)",
" - internal (size 2)",
" - leaf (size 7)",
" - 1",
" - 2",
" - 4",
" - 5",
" - 6",
" - 7",
" - 8",
" - key 8",
" - leaf (size 11)",
" - 9",
" - 10",
" - 12",
" - 13",
" - 14",
" - 15",
" - 18",
" - 19",
" - 20",
" - 21",
" - 22",
" - key 22",
" - leaf (size 8)",
" - 24",
" - 25",
" - 29",
" - 30",
" - 31",
" - 32",
" - 33",
" - 35",
" - key 35",
" - internal (size 3)",
" - leaf (size 12)",
" - 36",
" - 37",
" - 39",
" - 40",
" - 43",
" - 44",
" - 46",
" - 47",
" - 48",
" - 49",
" - 50",
" - 51",
" - key 51",
" - leaf (size 11)",
" - 52",
" - 53",
" - 54",
" - 55",
" - 56",
" - 58",
" - 59",
" - 60",
" - 63",
" - 65",
" - 66",
" - key 66",
" - leaf (size 7)",
" - 67",
" - 68",
" - 69",
" - 70",
" - 71",
" - 72",
" - 75",
" - key 75",
" - leaf (size 8)",
" - 76",
" - 77",
" - 78",
" - 79",
" - 81",
" - 82",
" - 85",
" - 86",
"db > ",
]
#print(f"result: {result}")
print(f"result[64:]: {result[64:]}")
assert result[64:] == expected_output
print(f"{sys._getframe().f_code.co_name} passed")
if len(sys.argv)<2:
print(f"need db file path")
exit(0)
db_file = sys.argv[1]
if os.path.exists(db_file):
print(f"{db_file} exists, remove it first")
os.remove(db_file)
test_prints_structure_of_7_leaf_node_btree(db_file)
print("all tests passed.")
diff golang/13.go golang/14.go
6a7
> "math"
85a87,88
>
> /* 为了测试,保持较小 */
86a90,91
>
> const INVALID_PAGE_NUM = math.MaxUint32
268a274,277
> /*
> 由于根页码是0,因此在初始化内部节点时,如果不将其右子节点初始化为无效的页码,可能会导致右子节点为0,这将使该节点成为根节点的父节点。
> */
> *internalNodeRightChild(node) = INVALID_PAGE_NUM
317c326,331
< return internalNodeRightChild(node)
---
> rightChild := internalNodeRightChild(node)
> if *rightChild == INVALID_PAGE_NUM {
> fmt.Printf("Tried to access right child of node, but was invalid page\n")
> os.Exit(1)
> }
> return rightChild
319c333,338
< return internalNodeCell(node, childNum)
---
> child := internalNodeCell(node, childNum)
> if *child == INVALID_PAGE_NUM {
> fmt.Printf("Tried to access child %d of node, but was invalid page\n", childNum)
> os.Exit(1)
> }
> return child
354,358c373,374
< func getNodeMaxKey(node []byte) uint32 {
< switch getNodeType(node) {
< case NODE_INTERNAL:
< return *internalNodeKey(node, *internalNodeNumKeys(node)-1)
< case NODE_LEAF:
---
> func getNodeMaxKey(pager *Pager, node []byte) uint32 {
> if getNodeType(node) == NODE_LEAF {
360,362c376,407
< default:
< // Handle other node types if needed
< return 0 // or appropriate default value
---
> }
> rightChild := getPage(pager, *internalNodeRightChild(node))
> return getNodeMaxKey(pager, rightChild)
> }
>
> // 处理根节点的拆分。
> // 将旧根复制到新页,成为左子节点。
> // 重新初始化根页以包含新根节点。
> // 新根节点指向两个子节点。
> func createNewRoot(table *Table, rightChildPageNum uint32) {
> root := getPage(table.pager, table.rootPageNum)
> rightChild := getPage(table.pager, rightChildPageNum)
> leftChildPageNum := getUnusedPageNum(table.pager)
> leftChild := getPage(table.pager, leftChildPageNum)
>
> if getNodeType(root) == NODE_INTERNAL {
> initializeInternalNode(rightChild)
> initializeInternalNode(leftChild)
> }
>
> // Left child has data copied from the old root
> copy(leftChild, root)
> setNodeRoot(leftChild, false)
>
> if getNodeType(leftChild) == NODE_INTERNAL {
> var child []byte
> for i := uint32(0); i < *internalNodeNumKeys(leftChild); i++ {
> child = getPage(table.pager, *internalNodeChild(leftChild, i))
> *nodeParent(child) = leftChildPageNum
> }
> child = getPage(table.pager, *internalNodeRightChild(leftChild))
> *nodeParent(child) = leftChildPageNum
363a409,420
>
> // Root becomes a new internal node with one key and two children
> initializeInternalNode(root)
> setNodeRoot(root, true)
> *internalNodeNumKeys(root) = 1
> *internalNodeChild(root, 0) = leftChildPageNum
> leftChildMaxKey := getNodeMaxKey(table.pager, leftChild)
>
> *internalNodeKey(root, 0) = leftChildMaxKey
> *internalNodeRightChild(root) = rightChildPageNum
> *nodeParent(leftChild) = table.rootPageNum
> *nodeParent(rightChild) = table.rootPageNum
365a423
> // 向父节点添加一个新的子节点/键对,对应于子节点
369c427
< childMaxKey := getNodeMaxKey(child)
---
> childMaxKey := getNodeMaxKey(table.pager, child)
373,374d430
< *internalNodeNumKeys(parent) = originalNumKeys + 1
<
376,377c432,433
< fmt.Println("Need to implement splitting internal node")
< os.Exit(1)
---
> internalNodeSplitAndInsert(table, parentPageNum, childPageNum)
> return
380a437,442
> // 具有右子节点为INVALID_PAGE_NUM的内部节点为空
> if rightChildPageNum == INVALID_PAGE_NUM {
> *internalNodeRightChild(parent) = childPageNum
> return
> }
>
381a444,450
> /*
> 如果我们已经达到节点的最大单元格数,就不能在分裂之前递增。
> 在没有插入新的键/子节点对的情况下递增,并立即调用
> `internal_node_split_and_insert` 会导致在 `(max_cells + 1)`
> 处创建一个新的键,其值未初始化。
> */
> *internalNodeNumKeys(parent) = originalNumKeys + 1
383c452
< if childMaxKey > getNodeMaxKey(rightChild) {
---
> if childMaxKey > getNodeMaxKey(table.pager, rightChild) {
386c455
< *internalNodeKey(parent, originalNumKeys) = getNodeMaxKey(rightChild)
---
> *internalNodeKey(parent, originalNumKeys) = getNodeMaxKey(table.pager, rightChild)
391,392c460,461
< //destination := internalNodeCell(parent, i)
< //source := internalNodeCell(parent, i-1)
---
> destination := internalNodeCell(parent, i)
> source := internalNodeCell(parent, i-1)
394,395c463,464
< //copy(destination, source)
< *internalNodeCell(parent, i) = *internalNodeCell(parent, i-1)
---
> copy((*(*[INTERNAL_NODE_CELL_SIZE]byte)(unsafe.Pointer(destination)))[:], (*(*[INTERNAL_NODE_CELL_SIZE]byte)(unsafe.Pointer(source)))[:])
> //*internalNodeCell(parent, i) = *internalNodeCell(parent, i-1)
400a470,473
> func internalNodeSplitAndInsert(table *Table, parentPageNum, childPageNum uint32) {
> oldPageNum := parentPageNum
> oldNode := getPage(table.pager, parentPageNum)
> oldMax := getNodeMaxKey(table.pager, oldNode)
401a475,543
> child := getPage(table.pager, childPageNum)
> childMax := getNodeMaxKey(table.pager, child)
>
> newPageNum := getUnusedPageNum(table.pager)
>
> // Flag to indicate if we are splitting the root node
> // 这个简短的注释是chatGPT总结后加上的...
> splittingRoot := isNodeRoot(oldNode)
>
> var parent, newNode []byte
> if splittingRoot {
> createNewRoot(table, newPageNum)
> parent = getPage(table.pager, table.rootPageNum)
> // If splitting root, update oldNode to point to the left child of the new root
> oldPageNum = *internalNodeChild(parent, 0)
> oldNode = getPage(table.pager, oldPageNum)
> } else {
> parent = getPage(table.pager, *nodeParent(oldNode))
> newNode = getPage(table.pager, newPageNum)
> initializeInternalNode(newNode)
> }
>
> oldNumKeys := internalNodeNumKeys(oldNode)
>
> curPageNum := *internalNodeRightChild(oldNode)
> cur := getPage(table.pager, curPageNum)
>
> // Move the right child into the new node and set the right child of old node to INVALID_PAGE_NUM
> internalNodeInsert(table, newPageNum, curPageNum)
> *nodeParent(cur) = newPageNum
> *internalNodeRightChild(oldNode) = INVALID_PAGE_NUM
>
> // Move keys and child nodes to the new node until the middle key
> for i := INTERNAL_NODE_MAX_CELLS - 1; i > INTERNAL_NODE_MAX_CELLS/2; i-- {
> curPageNum = *internalNodeChild(oldNode, uint32(i))
> cur = getPage(table.pager, curPageNum)
>
> internalNodeInsert(table, newPageNum, curPageNum)
> *nodeParent(cur) = newPageNum
>
> (*oldNumKeys)--
> }
>
> // Set the right child of old node to the highest key before the middle key and decrement the number of keys
> *internalNodeRightChild(oldNode) = *internalNodeChild(oldNode, *oldNumKeys-1)
> (*oldNumKeys)--
>
> // Determine which of the split nodes should contain the child to be inserted
> maxAfterSplit := getNodeMaxKey(table.pager, oldNode)
> destinationPageNum := newPageNum
>
> if childMax < maxAfterSplit {
> destinationPageNum = oldPageNum
> }
>
> // Insert the child node into the appropriate split node
> internalNodeInsert(table, destinationPageNum, childPageNum)
> *nodeParent(child) = destinationPageNum
>
> // Update the parent node's key to reflect the new highest key in the old node
> updateInternalNodeKey(parent, oldMax, getNodeMaxKey(table.pager, oldNode))
>
> // If not splitting the root, insert the new node into its parent
> if !splittingRoot {
> internalNodeInsert(table, *nodeParent(oldNode), newPageNum)
> *nodeParent(newNode) = *nodeParent(oldNode)
> }
> }
>
419,421c561,564
< for i := uint32(0); i < numKeys; i++ {
< child = *internalNodeChild(node, i)
< printTree(pager, child, indentationLevel+1)
---
> if numKeys > 0 {
> for i := uint32(0); i < numKeys; i++ {
> child = *internalNodeChild(node, i)
> printTree(pager, child, indentationLevel+1)
423,424c566,570
< indent(indentationLevel + 1)
< fmt.Printf("- key %d\n", *internalNodeKey(node, i))
---
> indent(indentationLevel + 1)
> fmt.Printf("- key %d\n", *internalNodeKey(node, i))
> }
> child = *internalNodeRightChild(node)
> printTree(pager, child, indentationLevel+1)
426,427d571
< child = *internalNodeRightChild(node)
< printTree(pager, child, indentationLevel+1)
629c773
< func readInput(reader *bufio.Reader, inputBuffer *InputBuffer) {
---
> func readInput(reader *bufio.Reader, table *Table, inputBuffer *InputBuffer) {
633a778,781
> dbClose(table)
> if err == io.EOF {
> os.Exit(0)
> }
716,738d863
< func createNewRoot(table *Table, rightChildPageNum uint32) {
< root := getPage(table.pager, table.rootPageNum)
< rightChild := getPage(table.pager, rightChildPageNum)
< leftChildPageNum := getUnusedPageNum(table.pager)
< leftChild := getPage(table.pager, leftChildPageNum)
<
< // Left child gets data copied from the old root
< copy(leftChild, root[:])
< setNodeRoot(leftChild, false)
<
< // Root becomes a new internal node with one key and two children
< initializeInternalNode(root)
< setNodeRoot(root, true)
< *internalNodeNumKeys(root) = 1
< *internalNodeChild(root, 0) = leftChildPageNum
<
< leftChildMaxKey := getNodeMaxKey(leftChild)
< *internalNodeKey(root, 0) = leftChildMaxKey
< *internalNodeRightChild(root) = rightChildPageNum
< *nodeParent(leftChild) = table.rootPageNum
< *nodeParent(rightChild) = table.rootPageNum
< }
<
744c869
< oldMax := getNodeMaxKey(oldNode)
---
> oldMax := getNodeMaxKey(cursor.table.pager, oldNode)
784c909
< newMax := getNodeMaxKey(oldNode)
---
> newMax := getNodeMaxKey(cursor.table.pager, oldNode)
843a969
> i := 0
847a974
> i++
848a976
> fmt.Printf("total_rows: %d\n", i)
876c1004,1007
< readInput(reader, inputBuffer)
---
> readInput(reader, table, inputBuffer)
> if inputBuffer.inputLength == 0 {
> continue
> }