问题
现在吃穿住行的app大都有定位的功能;如何让手机app所在的定位寻找出附近的POI(Point of Interest)呢?至于用户手机是如何获取定位的可以自行Google/Baidu,有时间整理一下。
地图上定位一个地方,通过经度(longitude)和纬度(latitude)来标记,由WGS84规定(为GPS全球定位系统使用而建立的坐标系统);比如地球🌍作为一个球体,纬度是指所在位置的纬线到地心的直线和赤道的纬线到地心的直线的夹角,通常北纬为正,南纬为负;经度是指所在位置的经线平面和规定的本初子午线平面的夹角,以东为东经,以西为西经,通常东经为正,西经为负;
一个地点的经度一般与它于协调世界时之间的时差相应:每天有24小时,而一个圆圈有360度,因此地球每小时自转15度。因此假如一个人的地方时比协调世界UTC(Coordinated Universal Time)时早3小时的话,那么他在东经45度左右,比如北京是在东经116左右,那时区+8作为中国标准时间CST(China Standard Time)
解决方案
通过app可以获取到定位信息经维度,以及后台POI(实时/离线)录入的经纬度信息,如何获取附近POI呢?
- 直接按距离计算:定位的经纬度确定对应的地区;然后和所在地区中的所有商户POI经纬度信息进行距离计算,然后排序,找出最近几公里内的商户POI;这种方法比较暴力,遇到数据量大的时候,比较耗时;
既然数据量大,采用分而治之的办法筛选查找:
- 利用Mysql的B+tree索引进行范围筛选:直接按距离计算(经纬度建立索引)/GeoHash;
- 利用Mysql的Rtree空间索引(5.7.4+,InnoDB支持):mysql空间数据类型(Point,LineString, Polygon)来进行检索;
- 利用PostgreSQL的PostGIS模块:通过R树 或 GIST树索引来实现空间索引,PostGIS 实现了Open Geospatial Consortium所提出的基本要素类(点、线、面、多点、多线、多面等)的SQL查询;
- 利用MongoDB: 依赖MongoDB的空间搜索算法(geoNear,near),底层也是对GeoHash进行B+tree索引;命令如下:
db.runCommand({ geoNear: "places", near: [30.545162, 104.062018], num:1000 }) - 将经纬度转换成GeoHash字符串,利用字典树查找term,找到对应倒排索引中的商户信息;
- 利用Redis(3.2+) GEO命令
GEOADD GEOHASH GEOPOS GEODIST GEORADIUS GEORADIUSBYMEMBER - 谷歌的 S² 算法: 将基于希尔伯特曲线实现,算法性能要优于geohash;具体看官网介绍,具体细节还没有弄清楚,待续~
从这些解决方案中可以总结出,根据对位置经纬度信息进行转换,然后结合具体的数据结构和算法来实现,适用不同场景:
- 将经纬度信息转成一维的GeoHash字符串(表示对应位置的区块),通过ziplist,B+树,字典树trie(倒排索引中的term存储结构)来索引,提供索搜查询;
- 将经纬度信息转换成多维的点线面空间信息,通过四叉树,R树,GIST树来索引,提供索搜查询;
方案概要
以上给出的具体实施方案,篇幅有限,这里主要是讨论GeoHash编码方式来表示空间信息。具体空间信息采集可以采集高德地图的接口,或者微博的一份数据
GeoHash
geohash 是 Gustavo Niemeyer 发明的一种对地理位置进行编码的算法;它是一种分级的数据结构,把空间划分为网格。Geohash 属于空间填充曲线中的 Z 阶曲线(Z-order curve)的实际应用。
- 通过二维的经纬度所在的区块表示成一维的字符串信息,字符串的长度越长,表示的区域范围更加精确。长度为9的geohash编码的精度能达到4米左右,10位的geohash经度能达到0.6米,一般情况下能满足我们大部分的需求;
- geohash 生成的字符串代表的不是地图上的一个点,而是地图上一个矩形区域,在一定程度上能保证隐私(知道大概的位置);
- geohash编号后方便索引和缓存,具有公共前缀的geohash编码作为key/term 索引、查找附近区域的的POI信息;
原理
编码步骤
- 首先将纬度范围(-90, 90)平分成两个区间(-90, 0)、(0, 90), 如果目标纬度位于前一个区间,则编码为0,否则编码为1; 以此类推,直到精度符合要求为止;
- 经度也用同样的算法,对(-180, 180)依次细分;
- 接下来组码,将经度和纬度的编码合并,奇数位是纬度,偶数位是经度,得到二进制编码;
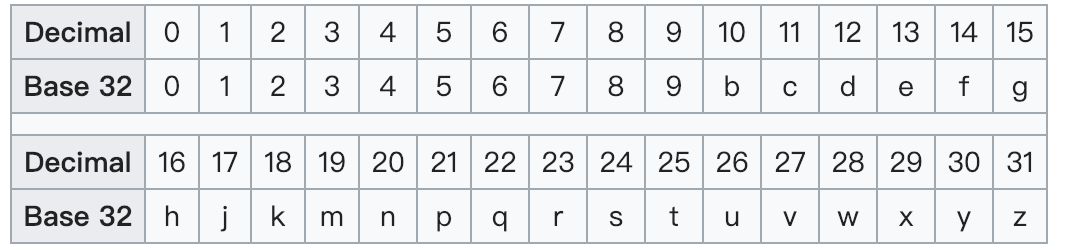
- 最后使用base32(0-9、b-z,去掉a,i,l,o,比较常用)或者base36编码(base36的版本对大小写敏感,用了36个字符,“23456789bBCdDFgGhHjJKlLMnNPqQrRtTVWX”);这里采用base32方式进行操作,首先将组合好的二进制码转成对应的十进制(二进制每5位表示一个base32字符);十进制对应base32编码表如下:
例如:将坐标 (39.97696,116.3764874)(latitude, longitude)编码成长度为12的字符串(base32编码) wx4g2jwf8tqx
精度表:
| length | latitude bits | longitude bits | latitude error | longitude error | km error |
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2500 |
| 2 | 5 | 5 | ±2.8 | ±5.6 | ±630 |
| 3 | 7 | 8 | ±0.70 | ±0.70 | ±78 |
| 4 | 10 | 10 | ±0.087 | ±0.18 | ±20 |
| 5 | 12 | 13 | ±0.022 | ±0.022 | ±2.4 |
| 6 | 15 | 15 | ±0.0027 | ±0.0055 | ±0.61 |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 |
| 8 | 20 | 20 | ±0.00008 | ±0.00017 | ±0.019 |
| 9 | 22 | 23 | ±0.00002 | ±0.000021 | ±0.00478 |
| 10 | 25 | 25 | ±0.00000268 | ±0.00000536 | ±0.0005971 |
| 11 | 27 | 28 | ±0.00000067 | ±0.00000067 | ±0.0001492 |
| 12 | 30 | 30 | ±0.00000008 | ±0.00000017 | ±0.0000186 |
geohash编码长度对应区域大小:
| length | width | height |
|---|---|---|
| 1 | 5000km | 5000km |
| 2 | 1250km | 625km |
| 3 | 156km | 156km |
| 4 | 39.1km | 19.5km |
| 5 | 4.89km | 4.89km |
| 6 | 1.22km | 0.61km |
| 7 | 153m | 153m |
| 8 | 38.2m | 19.1m |
| 9 | 4.77m | 4.77m |
| 10 | 1.19m | 0.596m |
| 11 | 149mm | 149mm |
| 12 | 37.2mm | 18.6mm |
解码步骤
解码操作为编码操作的逆向过程,这里就省略(后续补上)
获取相邻区域
为啥要获取相邻区域呢???
根据编码算法定义不难看出,如果需要寻找附近多少米的POI,根据精度只要前缀匹配规定长度的字符串(可以把经常访问的前缀匹配的字符串表示的区域POI信息缓存起来),比如坐标 (39.97696,116.3764874)对应成长度为12的字符串wx4g2jwf8tqx,想找附近500m的POI,长度为6的geohash编码能表示矩形区域在0.744平方千米左右(区域大小和geohash编码长度对应关系见上表),那么查询的时候就可缩小范围,找出那些前缀为wx4g2j的POI,与wx4g2jwf8tqx公共前缀匹配的长度越大,离得距离也就越近;
但是这种前缀匹配的方式存在一个临近边界问题,就是在区域的边界地方,在这个区域的相邻区域的公共前缀不同(长度按照区域大小选出),按照公共前缀匹配的方法会少筛选出一部分附近的POI;
解决的办法是将相邻的8块区域也算进来,扩大寻找范围,计算这些区域中的POI和所在位置的距离, 然后按距离排序筛选;
待续 (Geohash vs S²)
-
Geohash 有12级,从5000km 到 3.7cm。中间每一级的变化比较大。有时候可能选择上一级会大很多,选择下一级又会小一些。比如选择字符串长度为4,它对应的区域宽度是39.1km,需求可能是50km,那么选择字符串长度为5,对应的区域宽度就变成了156km,瞬间又大了3倍了。这种情况选择多长的 Geohash 字符串就比较难选。选择不好,每次判断可能就还需要取出周围的8个格子再次进行判断。Geohash 需要 12 bytes 存储。
-
S² 有30级,从 0.7cm² 到 85,000,000km² 。中间每一级的变化都比较平缓,接近于4次方的曲线。所以选择精度不会出现 Geohash 选择困难的问题。S2 的存储只需要一个 uint64 即可存下。S²算法待续
抛出问题
- 运动的个体(个体也可以当做POI),如何获取附近实时运动的POI呢? 实时计算方案呢?(像多人约会涉猎app)