
执行详尽的精确 k 最近邻 (kNN) 搜索,也称为暴力搜索(brute-force search),成本高昂,并且它不能很好地扩展到更大的数据集。在向量搜索期间,暴力搜索需要计算每个查询向量和数据库向量之间的距离。对于常用的欧几里德和余弦距离,计算任务等同于大型矩阵乘法。
虽然 GPU 在执行矩阵乘法方面效率很高,但随着数据量的增加,计算成本变得令人望而却步。然而,许多应用程序不需要精确的结果,而是可以为了更快的搜索而牺牲一些准确性。当不需要精确的结果时,近似最近邻 (ANN) 方法通常可以减少搜索期间必须执行的距离计算的数量。
本文主要介绍了 IVF-Flat,这是 NVIDIA RAPIDS RAFT 中的一种方法。IVF-Flat 方法使用原始(即Flat)向量的倒排索引 (IVF)。此算法提供了简单的调整手段,以减少整体搜索空间并在准确性和速度之间进行权衡。
为了帮助了解如何使用 IVF-Flat,我们讨论了该算法的工作原理,并演示了Python和C++ APIs我们介绍了索引构建的设置参数,并提供了如何配置 GPU 加速的 IVF-Flat搜索的技巧。这些步骤也可以在示例中遵循Python notebook和C++ project.最后,我们演示了 GPU 加速的向量搜索比 CPU 搜索快一个数量级。
IVF-Flat 算法
IVF 方法通过将数据集向量分组为簇(cluster)并将搜索限制在每个查询的一些最近簇来加速向量搜索(图 1)。
在 IVF-Flat 算法中,只搜索几个簇(而不是整个数据集)是实际的近似值。使用此近似值,可能会错过分配给未搜索的簇的一些近邻,但它极大地缩短了搜索时间。
 图 1.分为簇的数据集(左),且搜索仅限于查询附近的簇(右)
图 1.分为簇的数据集(左),且搜索仅限于查询附近的簇(右)
在搜索数据集之前,必须构建索引,这是一种存储高效搜索所需信息的结构。对于 IVF-Flat,索引存储簇的描述:其中心坐标和属于簇的向量列表。此列表是倒排列表,也称为倒排文件,这就是 IVF 的首字母缩写词。
在讨论倒排文件后,我们将在以下部分演示如何构建索引并解释如何执行搜索。
IVF 含义
为完整起见,以下是一些历史语境。倒排文件(或倒排索引)来自信息检索字段。
以几个简单的文本文档为例。如果要搜索包含给定单词的文档, forward index会存储每个文档的单词列表。必须明确阅读每个文档才能找到相关的文档。
相比之下,倒排索引包含了可以搜索的所有单词的字典,并且对于每个单词,都有一个该单词所在的文档索引列表。这就是所谓的倒排列表(倒排文件),可以将搜索限制在选定的列表中。
如今,文本数据通常表示为向量嵌入(embedding)。IVF-Flat 方法定义了簇中心,这些中心类似于前面示例中的词典。对于每个簇中心,都有属于该簇的向量索引列表,并且搜索速度加快,因为只需检查选定的簇。
索引构建
索引构建主要是对数据集进行聚类运算。ivf_flat可以使用以下代码示例在 Python 中创建索引:
from pylibraft.neighbors import ivf_flat
build_params = ivf_flat.IndexParams(
n_lists=1024,
metric="sqeuclidean"
)
index = ivf_flat.build(build_params, dataset)
在 C++中,有以下语法:
#include <raft/neighbors/ivf_flat.cuh>
using namespace raft::neighbors;
raft::device_resources dev_resources;
ivf_flat::index_params index_params;
index_params.n_lists = 1024;
index_params.metric = raft::distance::DistanceType::L2Expanded;
auto index = ivf_flat::build(dev_resources, index_params,
raft::make_const_mdspan(dataset.view()));
创建索引的最重要超参数是n_lists其中会指明要使用的簇数量。还可以指定距离计算指标。
搜索
构建索引后,搜索很简单。在 Python 中,以下调用返回两个数组:相邻数组的索引及其与查询向量的距离:
distances, indices = ivf_flat.search(ivf_flat.SearchParams(n_probes=50), index, queries, k=10)
C++中的等效调用需要预先分配输出数组:
int topk = 10;
auto neighbors = raft::make_device_matrix<int64_t, int64_t>(dev_resources, n_queries, topk);
auto distances = raft::make_device_matrix<float, int64_t>(dev_resources, n_queries, topk);
ivf_flat::search_params search_params;
search_params.n_probes = 50;
ivf_flat::search(dev_resources,
search_params,
index,
raft::make_const_mdspan(queries.view()),
neighbors.view(),
distances.view());
在这里,可以搜索k=10每个查询的近邻。参数 n_probes 会告知每个查询要搜索(或探测)的簇数量,并确定搜索的准确性。
仅通过测试 n_probes 对于每个查询的簇,可以省略分配给簇的一些近邻,簇的中心距离查询点更远。搜索质量通常以*召回率,*这是实际最近 k 近邻在所有返回近邻中的百分比。
在内部,搜索分两个步骤执行(图 2):
- 粗略搜索选择 n_probes 每个查询的附近簇。
- 精细搜索将查询向量与选定簇中的所有数据集向量进行比较。

图 2.两步搜索:通过比较查询与簇中心来选择附近的簇(左),并比较选定簇中的所有向量与相应的查询(右)
粗略搜索
粗略搜索使用簇中心和查询向量之间的精确 kNN 搜索完成。选择最近的簇中心,n_probes 个簇粗略搜索相对便宜,因为簇数量远小于数据集大小(例如,1 亿个向量的簇数量为 1 万个)。
精细搜索
对于 IVF-Flat,精细搜索也是精确搜索。但每个查询都有自己的一组要搜索(要探测)的簇,并且计算查询向量与被探测簇中所有向量之间的距离。
对于小批量,在查询点周围搜索的区域不会重叠。因此,问题结构变为批量矩阵向量乘法 (GEMV) 运算。此运算受内存带宽限制,GPU 显存的大带宽大大加速了此步骤。
选中每个探测簇的 top-k 近邻,结果是n_probes * k 个近邻候选。
调整索引构建参数
在前面的部分中,概述了索引构建和搜索。下面详细介绍了如何设置索引构建的参数。
索引构建包含两个阶段:
- 训练或计算簇(构建):平衡的分层 k-means 算法会对训练数据进行聚类。
- 将数据集向量添加到索引(扩展):将数据集向量分配给其簇,并将其添加到相应簇的向量列表中。
簇数量
参数 n_list 对训练和搜索期间的整体性能有着深远的影响:它定义了索引数据所划分的簇数量。设置n_lists=sqrt (n_samples)是一个很好的起点(n_samples是数据集中的向量数)。
为确保高效利用 GPU 资源,簇的平均大小(即n_samples/n_lists)应在至少 1K 个向量的范围内,以保持单个流多处理器 (SM) 的繁忙状态。
使用自动数据子采样构建索引
K-means 聚类是计算密集型的。为加速索引构建,对数据集进行子采样。使用参数kmeans_trainset_fraction=0.1这意味着将十分之一的数据集用于训练簇中心。
build_params = ivf_flat.IndexParams(
n_lists=1024,
metric="sqeuclidean",
kmeans_trainset_fraction=0.1,
kmeans_n_iters=20
)
在训练期间,参数 kmeans_n_iters 将直接传递给 k-means 算法。将其设置为适用于大多数数据集的合理默认值 20.但是,此参数只是聚类算法的建议。在幕后,它通常在“平衡”阶段执行更多迭代,以确保簇具有相似的大小。
使用用于聚类的特定训练数据构建索引
在前面的示例中,只需调用ivf_flat.build执行聚类并将整个数据集添加到索引中。或者,可以调用ivf_flat.build无需将向量添加到索引中即可训练向量(通过设置add_data_on_build=False).这允许精确控制用于训练索引的向量。随后,ivf_flat.extend可用于向索引中添加向量。
如下 Python 代码示例所示:
n_train = 10000
train_set = dataset[cp.random.choice(dataset.shape[0], n_train, replace=False),:]
build_params = ivf_flat.IndexParams(
n_lists=1024,
metric="sqeuclidean",
kmeans_trainset_fraction=1,
kmeans_n_iters=20,
add_data_on_build=False
)
index = ivf_flat.build(build_params, train_set)
ivf_flat.extend(index, dataset, cp.arange(dataset.shape[0], dtype=cp.int64))
数据集向量只需调用ivf_flat.extend。在内部,如果需要减少内存消耗,则对数据进行批量处理。相应的 C++代码如下所示:
index_params.add_data_on_build = false;
// Sub sample the dataset to create trainset.
// ...
// Run k-means clustering using the training set
auto index = ivf_flat::build(dev_resources, index_params,
raft::make_const_mdspan(trainset.view()));
// Fill the index with the dataset vectors
index = ivf_flat::extend(dev_resources,
raft::make_const_mdspan(dataset.view()),
std::optional<raft::device_vector_view<const int64_t, int64_t>>(),
index);
向索引中添加新向量
可以通过调用ivf_flat.extend.默认情况下,增加向量列表的成本将通过在增加列表大小时分配额外空间来抵消。C++API 用户可以通过设置以下参数来更改此行为:
index_params.conservative_memory_allocation = true;
如果聚类数量较大且预计不会经常添加向量,则此操作会非常有用。
默认情况下,当向数据集添加向量时,簇中心不会发生变化。adaptive_centers,如果希望簇中心随新数据移动,则可以在索引构建期间启用标志。
调整搜索参数
以下是设置搜索参数的方法:高效使用 GPU 资源并增加 n_probes。
GPU 资源
在搜索过程中,需要创建内部工作空间内存。建议使用池化分配器来减少内存分配。
构建 RAFT资源对象非常耗时。资源对象应该复用, 通过资源handle传递给搜索函数 。在 Python 中,可以通过以下方式配置设备资源和内存池:
from pylibraft.common import DeviceResources
import rmm
mr = rmm.mr.PoolMemoryResource(
rmm.mr.CudaMemoryResource(),
initial_pool_size=2**30
)
rmm.mr.set_current_device_resource(mr)
handle = DeviceResources()
search_params = ivf_flat.SearchParams(n_probes=50)
distances, indices = ivf_flat.search(search_params, index, queries, k=10, handle=handle)
handle.sync()
C++API 的用户必须始终传递显式 device_resources handle,并且应在单独调用之间重复使用此handle进行搜索。可以通过以下方式设置池分配器:
raft::device_resources dev_resources;
raft::resource::set_workspace_to_pool_resource(
dev_resources, 2 * 1024 * 1024 * 1024ull);
ivf_flat::search(dev_resources, ...);
C++ 用户可以为临时工作空间数组指定一个单独的分配器,这在前面的示例中已经使用过。全局分配器(用于创建输入/输出数组)可以使用 rmm::mr::set_current_device_resource。
探针数量
比率n_probes/n_lists表明数据集的哪一部分与每个查询进行比较。距离计算的数量减少到n_probes/n_clusters暴力搜索计算量的一小部分。搜索质量以及计算时间会随着n_probes 的增加而增加,正确的值取决于数据集。
在图 3 和图 4 中,可以分别观察吞吐量(每秒查询次数)和搜索精度(召回率)如何取决于探测器数量。这里,从DEEP1B 数据集搜索 100M 个向量,并使用 H100 GPU 进行搜索。
吞吐量与探针的数量成反比。数据集被分为 10 万个簇;每个查询仅搜索 100 个最接近的簇可实现 96% 的召回率,而搜索 1000 个簇(数据集的 1%)可实现 99.8% 的准确率。

图 3.搜索吞吐量(每秒查询次数)作为n_probes搜索参数

图 4.精度(召回)作为n_probes搜索参数
通常会将这些图形组合到单个 QPS 与召回图中(图 5)。当想要紧凑地权衡准确性和搜索吞吐量时,这很有用。在比较不同的 ANN 方法时,这也很有用。
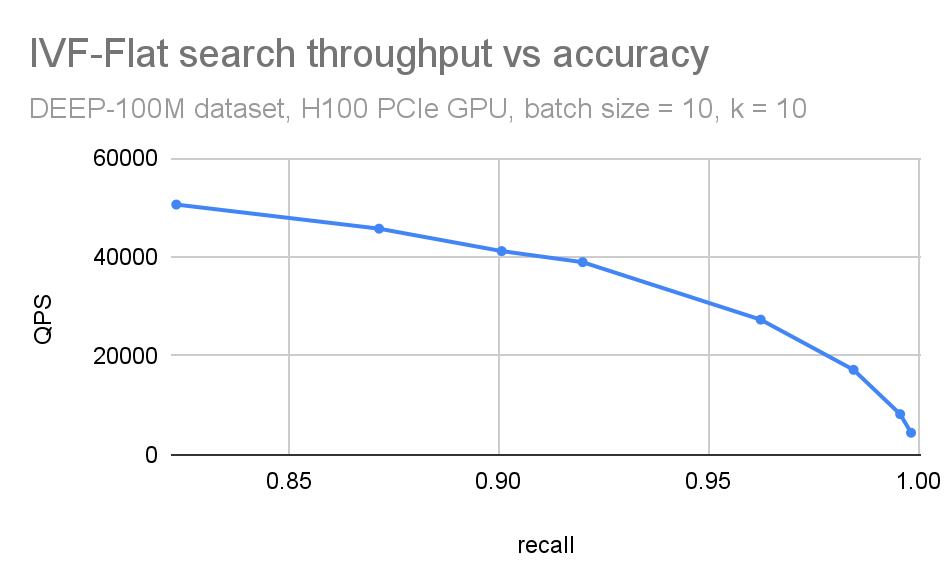 图 5.组合 QPS 召回图
图 5.组合 QPS 召回图
如果 n_lists=n_probes 这就像精确(暴力)搜索:将所有数据集向量与所有查询向量进行比较。在这种情况下,预计召回率等于 1 (除了小的舍入误差)。
当 n_probes 接近 n_lists 时,IVF-Flat 由于算法所做的额外工作(粗略加精细搜索),速度比暴力慢。在实践中,搜索大约 0.1-1%的列表足以处理许多数据集。但这取决于输入的聚类效果。
On the Surprising Behavior of Distance Metrics in High Dimensional Space论文中提到,如果数据集没有结构(例如,统一随机数),聚类会变得困难。在这种情况下,IVF 方法的效果不佳。
(注:IVF-Flat算法依赖输入的数据集,以及聚类效果)
性能
RAFT 库可快速实施 IVF-Flat 算法。索引 1 亿个向量可在一分钟内完成(图 6)。这比使用 CPU 快 14 倍。

图 6.不同数据集和簇大小的索引构建时间
我们在 NVIDIA H100 SXM GPU (使用 RAFT 23.10 进行 GPU 测试)和 Intel Xeon Platinum 8480CL CPU 上执行了FAISS 1.7.4 的测量。
实现这种加速有两个主要因素:
- GPU 的高计算吞吐量:RAFT 利用 Tensor Core 在索引构建期间加速 k-means 聚类。
- 改进的算法:RAFT 使用平衡的分层 k-means 聚类,即使数据集的向量数量达到数亿,也能高效地进行聚类。
还可以观察到,构建索引的时间随向量数量线性增加,随聚类数量线性增加。
GPU 的高内存吞吐量有助于搜索索引。RAFT 的 IVF-Flat 索引使用优化的内存布局。向量交错以进行向量化内存访问,以确保在遍历每个探测簇中的数据集向量时实现高带宽利用率。
精细搜索过程中的另一个重要步骤是过滤掉前 k 个候选项。最新top-k算法on GPU论文 Parallel Top-K Algorithms on GPU: A Comprehensive Study and New Methods。将优化的 block-select-k 内核融合到距离计算内核中。如图 7 所示,与 CPU 实现的性能相比,这可以将 RAFT IVF-Flat 的速度提高 20 倍以上(回顾值=0.95)。
(注:top-k 这篇论文期待一下;和Efficient Top-K Query Processing on Massively Parallel Hardware 对比学习下~)

图 7.不同召回率(准确性)的搜索吞吐量
在此基准测试中,我们使用了 FAISS IVF-Flat 的 CPU 实现。FAISS 还提供了此算法的 GPU 实现。如果使用 FAISS,则只需对代码进行细微更改即可从 GPU 加速中受益。与 Meta 合作,将 RAFT 的性能改进引入 FAISS,因此很快也可以通过 FAISS 使用 RAFT。
(注: 相关PR见Reference, IVF-Flat 已集成)
总结
在大型数据库中执行向量搜索时,务必要注意精确搜索的高昂成本,因为这会导致不适合在线服务的低延迟。
RAPIDS RAFT 库提供了高效的算法,通过将搜索集中到数据集中最相关的部分,以提高向量搜索的延迟和吞吐量。本文讨论了 RAFT IVF-Flat 算法的工作原理,以及如何设置索引构建和搜索的参数。最后,提供基准测试,以强调 GPU 在 IVF – Flat 搜索中的卓越性能。可以使用基准测试工具。
Reference
-
https://developer.nvidia.com/blog/accelerated-vector-search-approximating-with-rapids-raft-ivf-flat/
-
https://github.com/rapidsai/raft/blob/branch-23.12/docs/source/vector_search_tutorial.md
-
On the Surprising Behavior of Distance Metrics in High Dimensional Space
-
Parallel Top-K Algorithms on GPU: A Comprehensive Study and New Methods
-
https://www.kdnuggets.com/2018/05/wtf-tensor.html , https://en.wikipedia.org/wiki/Tensor