背景
用户业务数据增长过快,比如文章评论系统,feed流系统,订单系统;数据的存放模型需要从主从的单机单库 演变成 分布式集群数据库; 分库分表的数据查询需用到全局唯一标识的id来查询业务,比如莫个feed的评论数据、推送消息、购物订单、活动优惠劵等等都需要进行唯一ID标识;以便分布式存储(mysql,nosql,newsql)索引(b+tree, LSMtree,inverted index)快速查询;至于数据一致性通过约定规范协议保证(强:类Paxos算法/raft算法,弱: mq) 。
特征
根据不同的需求场景进行总体归纳全局id生成服务的特征:
- 全局唯一:最基本要求,不能出现重复的id;
- 趋势递增:业务中如果大量使用mysql innodb来存放数据,而innodb使用聚集索引(cluster index),使用b+tree来存放索引数据,所以在主键的选择存放上应该尽量使用整数型有序的主键,来保证数据的写入性能(顺序io)
- 单调递增:IM增量消息,排序序列号
- 可解码:比如统计分析id的生成情况,尽量是服务分布均匀,需要查看业务id(appID),生成时间(time ms), 以及id服务节点号(nodeID)
- 信息安全:生成id的规律不能过于简单,比如单调递增,信息详情展示页会有规律的爬取,这样直接可以估算出一些指标数据(天订单量,天feed产生流量等);所以需要id无规律生成(可以内部获取有规律的id后,进行加盐编码处理)
这些特征有些是互斥的,不能同时满足,需要根据业务场景具体分析(可能有些场景特征还未考虑到,后续加入),选择对应特征方案来满足。
id生成服务的评价指标:(由于在分布式系统中,id生成服务依赖度非常高,需要高可用和高性能)
- 平均响应时间和所有请求中的千分之999的最低相应时间(TP999)尽可能的低;
- SLA(可用性)5个9(全年低于5分钟的不可用时间)
- QPS(每秒请求量)尽可能的高
方案
uuid
标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,无序,不适合用来做为数据库(B+Tree)中的主键。
snowflake
twitter中的feed数据从mysql迁移至Cassandra中存放,cassandra没有顺序id生成机制,提出的一种解决方案;不依赖其他组件服务,直接程序算法实现;
- 41位的时间序列(精确到毫秒,41位的长度可以使用69年)
- 10位的机器标识(10位的长度最多支持部署1024个节点),根据业务服务类型和部署还可进行细分,比如idc,机器,业务id(appid)
- 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
- 最高位是符号位,始终为0
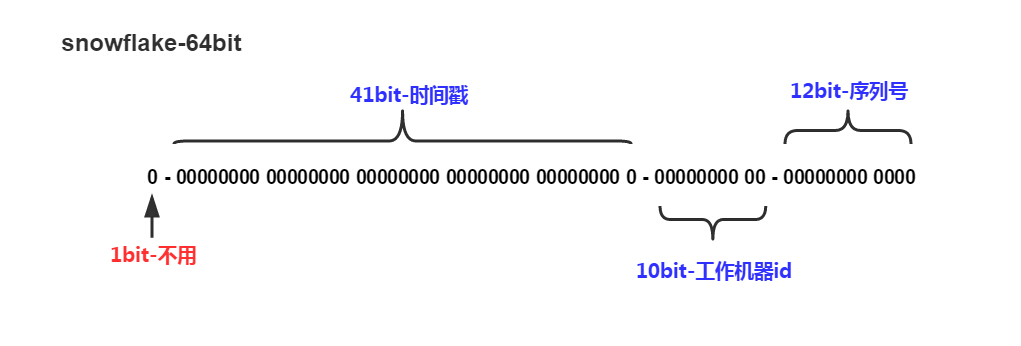
64位bigint类型ID, 最大2^63-1 19位10进制数
- 缺点: 多机部署时,必须保证时间是同步的,否则如果存在时间回溯,出现重复id。
- 解决方案:可以加上多台机器时间同步检测恢复机制NTP网络时间协议,可以尽量避免
redis生成id:
利用redis的单线程机制,以及原子递增操作INCR和INCRBY来实现;多台部署:采用按起始值分N台机器数间隔递增(等差数列),格式:时间戳+单日增长号;(单点故障,由于等差值N机器数是事先定义好的,水平扩容不方便,不便于运维)
mysql生成id(64位):
利用mysql的auto_increment自助机制 + replace into table操作(table定义两个字段,一个是64位的主键自增字段,一个是属性唯一字段) +InnoDB/MyISAM引擎 来实现,多台主从部署:采用按起始值分N台机器数间隔递增(等差数列),需要设置mysql自增参数:set auto_increment_increment=N.
- 存在问题:
主跪了,切从,主从数据同步存在延时的话,id会出现重复的情况,以及每次生成id,都要访问一次数据库replace操作,性能会降低很多; - 解决方案:
通过“号段”segment批量获取的方式,从mysql中获取ID,然后扩大倍数M,设定范围[ID*M,(ID+1)*M],然后从内存中的这个范围里生成一个自增序列号,如果到了范围的最大值,则阻塞其他请求,由最早的线程去db获取id,设定范围,或者在号码到达最大范围的10~75%的时候提前去db获取id,这样就不会阻塞的情况;然后继续以述过程。这个方案有个小缺陷就是服务重启,以往内存中的id范围段就会浪费掉,但是64位还是挺多的,性能提高了,浪费点也就无所谓啦~ 当然如果你是处女座,最求极致可以旁路监控记录已经分配出去的id,启动的时候在捞回来放入内存中继续分配生成id)。
这个方案比较常用,稳定,依赖mysql,需要与dba配合操作,和redis生成id一样不便于水平扩展,运维维护,改进方案类似于美团的Leaf-segment设计,采用元数据(tag,max_id,step,desc,create_time,update_time)管理,对业务tag进行分库扩容,减低运维维护成本
总结
- 性能上当然snowflake性能最好,全局唯一,趋势递增,可解码,不依赖其他组件,唯一缺陷是时间不同步的问题,如果回退的时间比较大,服务可能就跪了,解决方案:服务启动时就进行校验时间是否与启动的服务节点一致,依赖于zk或者etcd来记录监控各个genId service服务节点的时间信息,验证相同则ok,否则启动失败,报警。应用场景feed流
- 稳定上mysql生成id方案比较好,全局唯一,单个mysql实例可以保证单调递增,扩容多实例变成趋势递增(proxy wrr负载均衡w=1),性能和主从同步延迟导致id重复问题,这些问题可以通过内存中的ID范围段segment来计算生成自增序列id解决。应用场景订单号,消息id
参考阅读
- 分布式架构系统生成全局唯一序列号的一个思路
- 美团点评id生成器系统-Leaf (HA,性能,便于扩容,通过管理元数据(tag,max_id,step,desc,create_time,update_time),对业务tag进行分库扩容;通过zk来同步每个启动的Leaf节点时间,新的服务启动是通过时间校验机制来规避时间戳不同步,回拨问题上的监控)
- golang分布式id生成服务
- raft