使用meloTTS 本文生成的音频
使用openVoice clone 自己的声音 阅读本文内容
文件直接上传在github中, 暂未走cdn, 缓存比较慢,可下载播放, 下载地址: http://github.com/weedge/paper-speaker/tree/main/multimoding/voices/open_voice_inference
openVoiceV2 tone color clone: base TTS + extra tone color + convert
Base TTS: use meloTTS , 支持TTS模型训练,以及load Pre-Trained ckpt 进行TTS, 在 VITS基础上支持多种语言;
论文地址:OpenVoice: Versatile Instant Voice Cloning
论文主作者:Zengyi Qin (同时是JetMoE的作者,站在巨人的肩膀上创新)
公开的权重:
- OpenVoice: https://huggingface.co/myshell-ai/OpenVoice
- OpenVoiceV2: https://huggingface.co/myshell-ai/OpenVoiceV2
源码:
训练: MSML dataset 和 训练过程 未公开
附操作笔记: https://github.com/weedge/doraemon-nb/blob/main/myshell_ai_OpenVoiceV2.ipynb
抽取音色:
clone音色转换:
Tips: 使用cpu转换的时间比较长,比如本文音色转换时间大概需要1个小时,如果是在线场景,像app.myshell.ai 在线转换的场景中,限制输入文本的最大长度为300,而且也会定义转换的超时时间,防止过度消耗计算资源。如果是离线场景pipeline,可以采用m/r框架来分布式处理音频文件转换。(这个是后续修改加入,音频文件未生成); 如果对于文章经常更新的场景,需要重新生成文章音频文件,这个是比较消耗资源,暂未找到一种diff方案增量更新音频。
0 摘要
我们介绍了 OpenVoice,这是一种多功能的即时语音克隆方法,只需来自参考说话者的短音频剪辑即可复制其声音并生成多种语言的语音。OpenVoice 在以下领域中代表了重大进展:
1) 灵活的语音风格控制。 OpenVoice 能够对语音风格进行精细的控制,包括情感、口音、节奏、停顿和语调,除了复制参考说话者的音色外。这些语音风格不是直接从参考说话者的风格复制和受到限制的。以往的方法缺乏在克隆后灵活操纵语音风格的能力。
2) 零样本跨语言语音克隆。 OpenVoice 实现了零样本跨语言语音克隆,适用于未包含在大规模说话者训练集中的语言。与以往的方法不同,以往的方法通常需要为所有语言提供广泛的大规模说话者多语言(MSML)数据集,而 OpenVoice 可以在没有针对该语言的任何大规模说话者训练数据的情况下将语音克隆到新语言中。OpenVoice 还具有计算效率高的特点,成本比商业可用的甚至性能较差的 API 低几十倍。为了促进该领域的进一步研究,我们已经将源代码和训练模型公开。我们还在我们的演示网站提供了定性结果。在其公开发布之前,我们内部版本的 OpenVoice 在 2023 年 5 月至 10 月之间被全球用户数千万次使用,作为 MyShell.ai 的后端服务。
1 介绍
在文本转语音(TTS)合成中,即时语音克隆(IVC)意味着 TTS 模型可以在给定短音频样本的情况下克隆任何参考说话者的声音,而无需对参考说话者进行额外的训练。它也被称为零样本 TTS。IVC 使用户能够灵活定制生成的语音,在各种实际应用中展现出巨大的价值,例如媒体内容创作、定制聊天机器人以及人与计算机或大型语言模型之间的多模式交互。
在 IVC 方面已经进行了大量的研究工作。自回归方法的例子包括 VALLE1 和 XTTS2,它们从参考音频中提取声学标记或说话者嵌入作为自回归模型的条件。然后,自回归模型按顺序生成声学标记,然后将其解码为原始音频波形。尽管这些方法可以克隆音色,但它们不允许用户灵活地操纵其他重要的风格参数,如情感、口音、节奏、停顿和语调。而且,自回归模型相对计算成本高,推理速度相对较慢。非自回归方法的例子包括 YourTTS3和最近开发的 Voicebox4,它们展示了显著更快的推理速度,但仍无法提供除音色以外的风格参数的灵活控制。现有方法的另一个共同缺点是,它们通常需要大量的 MSML 数据集才能实现跨语言语音克隆。这种组合数据要求可能会限制它们包含新语言的灵活性。此外,由于科技巨头的语音克隆研究41 大多是闭源的,因此研究界没有便捷的方式站在他们的肩膀上,推动该领域的进展。
我们介绍了 OpenVoice,这是一种灵活的即时语音克隆方法,针对该领域的以下关键问题:
-
除了克隆音色外,如何灵活控制其他重要的风格参数,如情感、口音、节奏、停顿和语调?这些特征对于生成上下文自然的语音和对话非常重要,而不是单调地叙述输入文本。先前的方法321只能克隆参考说话者的单调音色和风格,但不允许灵活操纵风格。
-
如何以简单的方式实现零样本跨语言语音克隆。我们提出了两个零样本能力方面的重要问题,这些问题并不是先前研究所解决的:
-
如何在不降低质量的情况下实现超快速的实时推理速度,这对于大规模商业生产环境至关重要。
为了解决前两个问题,OpenVoice 被设计为尽可能地解耦语音中的组件。语言、音色和其他重要的语音特征的生成被独立地分开,使得可以灵活操纵单个语音风格和语言类型。这是在不标记任何语音风格的 MSML 训练集中实现的。我们想澄清一点,本研究中的零样本跨语言任务与 VALLE-X 中的任务不同5。在 VALLE-X 中,所有语言的数据都需要包含在 MSML 训练集中,模型无法推广到 MSML 训练集之外的未见过的语言。相比之下,OpenVoice 设计为推广到完全未见过的 MSML 训练集之外的语言。第三个问题默认被解决,因为解耦的结构降低了对模型大小和计算复杂度的要求。我们不需要一个大型模型来学习所有东西。此外,我们避免了自回归或扩散组件以加快推理速度。
我们在此公开发布之前的 OpenVoice 内部版本已在 2023 年 5 月至 10 月期间全球用户使用了数千万次。它为 MyShell.ai 的即时语音克隆后端提供支持,并在该平台上见证了数百倍的用户增长。为了促进该领域的研究进展,我们详细解释了该技术,并公开提供了源代码和模型权重。
2 方法
技术方法 简单 实现但效果惊人。我们首先介绍 OpenVoice 背后的直觉,然后详细说明模型结构和训练过程。
2.1 直觉
难点 。很明显,同时克隆任何说话者的音色,实现对所有其他风格的灵活控制,并且用很少的工作量添加新语言可能会非常具有挑战性。这需要大量的组合数据集,其中受控参数相交,并且只在一个属性上有差异的数据对,并且有良好标记,以及一个相对较大容量的模型来拟合数据集。
简单的部分 。我们还注意到,在常规的单说话者 TTS 中,只要不需要语音克隆,就相对容易添加对其他风格参数的控制和添加新语言。例如,记录一个包含 10K 个带有标记的情感和语调的短音频样本的单说话者数据集足以训练出一个提供对情感和语调进行控制的单说话者 TTS 模型。通过在数据集中包含另一个说话者,添加新语言或口音也很简单。
OpenVoice 背后的直觉是将 IVC 任务解耦为单独的子任务,其中每个子任务比耦合任务更容易实现。音色克隆与所有其他风格参数和语言的控制完全解耦。我们提议使用基础说话者 TTS 模型来控制风格参数和语言,并使用音色转换器将参考音色体现到生成的语音中。
2.2 模型结构
我们在图1 中说明了模型结构。OpenVoice 的两个主要组件是基础说话者 TTS 模型和音色转换器。基础说话者 TTS 模型是单说话者或多说话者模型,允许对风格参数(例如情感、口音、节奏、停顿和语调)、口音和语言进行控制。由该模型生成的语音传递给音色转换器,该转换器将基础说话者的音色改变为参考说话者的音色。
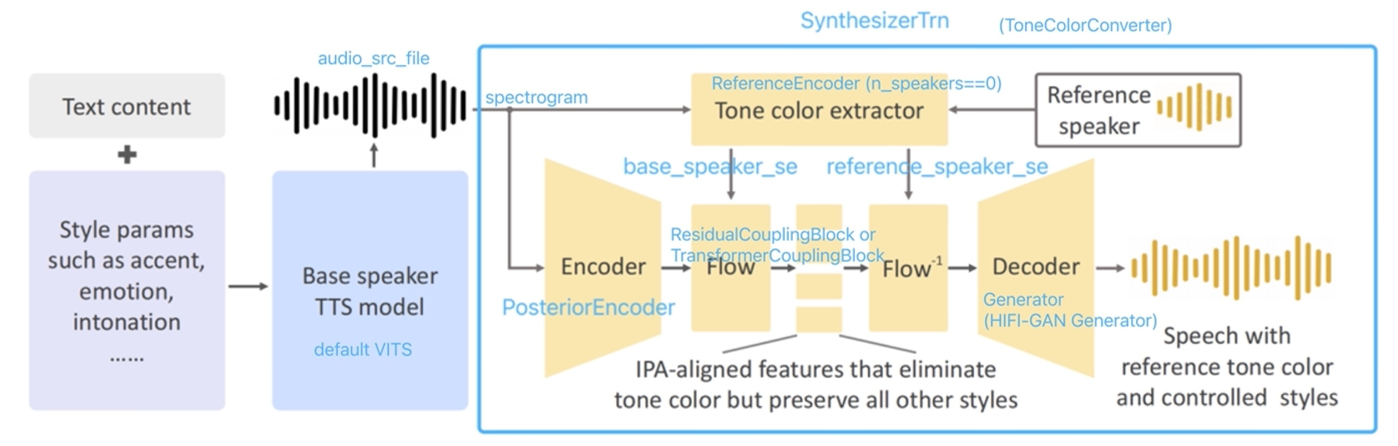
图1: OpenVoice 框架示意图。我们使用一个基础说话者模型来控制风格和语言,并使用一个转换器将参考说话者的音色体现到语音中。
基础说话者 TTS 模型。 基础说话者 TTS 模型的选择非常灵活。例如,VITS6 模型可以修改为在其文本编码器和持续预测器中接受风格和语言嵌入。其他选择,如 InstructTTS7 也可以接受风格提示。也可以使用商业可用(且价格低廉)的模型,如 Microsoft TTS,该模型接受指定情感、停顿和发音的语音合成标记语言(SSML)。甚至可以跳过基础说话者 TTS 模型,自己按照所需的风格和语言阅读文本。在我们的 OpenVoice 实现中,默认使用了 VITS6 模型,但其他选择完全可行。我们将基础模型的输出表示为 $\mathbf{X}(L_I, S_I, C_I)$,其中三个参数分别表示语言、风格和音色。类似地,来自参考说话者的语音音频表示为 $\mathbf{X}(L_O, S_O, C_O)$。
附 vits 模型结构:

音色转换器。 音色转换器是一个编码器-解码器结构,中间带有可逆正规化流8 。编码器是一个 1D 卷积神经网络,接受 $\mathbf{X}(L_I, S_I, C_I)$ 的短时傅里叶变换频谱作为输入。所有卷积都是单步长的。编码器输出的特征图表示为 $\mathbf{Y}(L_I, S_I, C_I)$。音色提取器是一个简单的 2D 卷积神经网络,操作输入语音的梅尔频谱图,并输出一个单一的特征向量,编码了音色信息。我们将其应用于 $\mathbf{X}(L_I, S_I, C_I)$ 以获得向量 $\mathbf{v}(C_I)$,然后将其应用于 $\mathbf{X}(L_O, S_O, C_O)$ 以获得向量 $\mathbf{v}(C_O)$。
正规化流层将 $\mathbf{Y}(L_I, S_I, C_I)$ 和 $\mathbf{v}(C_I)$ 作为输入,并输出消除音色信息但保留所有其他风格属性的特征表示 $\mathbf{Z}(L_I, S_I)$。特征 $\mathbf{Z}(L_I, S_I)$ 沿着时间维度与国际音标(IPA International Phonetic Alphabet)9 对齐。关于如何学习这样的特征表示的详细信息将在下一节中解释。然后,我们以逆方向应用正规化流层,将 $\mathbf{Z}(L_I, S_I)$ 和 $\mathbf{v}(C_O)$ 作为输入,并输出 $\mathbf{Y}(L_I, S_I, C_O)$。这是一个关键步骤,参考说话者的音色 $C_O$ 被体现到特征图中。然后,$\mathbf{Y}(L_I, S_I, C_O)$ 通过包含一堆转置 1D 卷积的 HiFi-Gan10 解码为原始波形 $\mathbf{X}(L_I, S_I, C_O)$。我们的 OpenVoice 实现中的整个模型都是前向传递的,没有任何自回归组件。音色转换器在概念上类似于语音转换11 12 ,但在功能、模型结构和训练目标上有所不同。音色转换器中的流层在结构上类似于基于流的 TTS 方法6 13 ,但具有不同的功能和训练目标。
替代方法和缺点。 尽管有替代方法14 15 11 可以提取 $\mathbf{Z}(L_I, S_I)$,但我们经验性地发现所提出的方法实现了最佳的音频质量。可以使用 HuBERT14 提取离散或连续的声学单元11 来消除音色信息,但我们发现这种方法也会消除输入语音的情感和口音。当输入是未见过的语言时,这种方法也存在保留语素自然发音的问题。我们还研究了另一种方法15 ,它通过仔细构建信息瓶颈仅保留语音内容,但我们观察到这种方法无法完全消除音色。
新颖性的备注。 OpenVoice 并不打算发明模型结构中的子模块。基础说话者 TTS 模型和音色转换器都从现有工作13 6 中借鉴了模型结构。OpenVoice 的贡献是 将声音风格和语言控制与音色克隆分离 的解耦框架。这非常简单,但非常有效,特别是当想要控制风格、口音或泛化到新语言时。如果要在类似于 XTTS2 的耦合框架上实现相同的控制,可能需要大量的数据和计算,而且流利地讲每种语言也相对困难。在 OpenVoice 中,只要单说话者 TTS 说得流利,克隆的语音就会流利。将声音风格和语言的生成与音色的生成分离是 OpenVoice 的核心理念。我们还在我们的选择中提供了使用音色转换器中的流层的见解,以及在我们的实验部分中选择通用音素系统(IPA: International Phonetic Alphabet)在语言泛化中的重要性。
2.3 训练 training
为了训练基础说话者 TTS 模型,我们从两位英语说话者(美国口音和英国口音)、一位中文说话者和一位日语说话者收集了音频样本。总共有 30K 个句子,平均句子长度为 7 秒。英语和中文数据具有情感分类标签。我们修改了 VITS6 模型,将情感分类嵌入、语言分类嵌入和说话者 id 输入到文本编码器、持续预测器和流层中。训练遵循 VITS 作者提供的标准流程6 。训练后的模型能够通过切换不同的基础说话者来改变口音和语言,并以不同的情感朗读输入文本。我们还尝试了额外的训练数据,并确认节奏、停顿和语调可以像情感一样学习。
为了训练音色转换器,我们从 20K 个人员收集了 300K 个音频样本。大约 18 万个样本是英语,6 万个样本是中文,6 万个样本是日语。这就是我们所谓的 MSML 数据集。音色转换器的训练目标是双重的。首先,我们要求编码器-解码器产生自然声音。在训练期间,我们直接将编码器的输出馈送到解码器,并使用原始波形进行监督,使用梅尔频谱损失和 HiFi-GAN10 损失对生成的波形进行评估。我们不会在这里详细说明,因为先前的文献10 6 已经很好地解释了这一点。
其次,我们要求流层尽可能多地消除音色信息。在训练期间,对于每个音频样本,其文本被转换为国际音标(IPA)中的音素的序列9 ,每个音素由一个可学习的向量嵌入表示。向量嵌入的序列被传递到一个 Transformer16 编码器,以产生文本内容的特征表示。将这个特征表示表示为 $\mathbf{L}\in\mathbb{R}^{c\times l}$,其中 $c$ 是特征通道数,$l$ 是输入文本中的音素数。音频波形经过编码器和流层处理,产生特征表示 $\mathbf{Z}\in\mathbb{R}^{c\times t}$,其中 $t$ 是特征沿时间维度的长度。然后,我们使用动态时间规整17 18 (另一种是单调规整13 6 )将 $\mathbf{L}$ 与 $\mathbf{Z}$ 沿着时间维度对齐,产生 $\mathbf{\bar{L}}\in \mathbb{R}^{c\times t}$,并最小化 $\mathbf{\bar{L}}$ 和 $\mathbf{Z}$ 之间的 KL 散度。由于 $\mathbf{\bar{L}}$ 不包含任何音色信息,最小化目标会鼓励流层从输出 $\mathbf{Z}$ 中消除音色信息。流层被音色编码器的音色信息所条件化,这进一步帮助流层确定需要消除的信息。此外,我们没有为流层提供任何风格或语言信息来进行条件化,这防止了流层除音色外的信息。由于流层是可逆的,将它们条件化为一个新的音色信息并运行其逆过程可以将新的音色添加回特征表示中,然后将其解码为带有新音色的原始波形。
3 实验 Experiment
评估语音克隆的准确性存在几个客观上的困难。首先,不同的研究(例如 4 、3 )通常具有不同的训练和测试集。数字比较可能从本质上是不公平的。即使他们的指标如平均意见分数可以通过众包评估,测试集的多样性和难度也会显著影响结果。例如,如果测试集中许多样本都是神经语音,集中在人类语音分布的平均值上,那么大多数方法都相对容易实现良好的语音克隆结果。第二,不同的研究通常具有不同的训练集,规模和多样性会对结果产生重大影响。第三,不同的研究可能在其核心功能上有不同的关注点。OpenVoice 主要旨在音色克隆、对语音风格的灵活控制,并使跨语言语音克隆即使没有新语言的海量说话者数据也变得简单。这与以前关于语音克隆或零-shot TTS 的工作的目标不同。因此,我们主要关注分析 OpenVoice 本身的定性性能,并公开了相关研究人员自由评估的音频样本。
准确的音色克隆。 我们构建了一个参考说话者的测试集,选择了名人、游戏角色和匿名个体。测试集涵盖了广泛的语音分布,包括具有表现力的独特语音和人类语音分布中的中性样本。使用任何 4 个基础说话者和任何参考说话者,OpenVoice 都能准确克隆参考音色,并以多种语言和口音生成语音。我们邀请读者访问该网站 https://research.myshell.ai/open-voice/accurate-tone-color-cloning 获取定性结果。
对语音风格的灵活控制。 提出的框架能够灵活控制语音风格的前提是音色转换器能够仅修改音色并保留所有其他风格和语音属性。为了确认这一点,我们使用了我们的基础说话者模型和 Microsoft TTS with SSML 来生成一个包含 1K 个样本的具有多种风格(情感、口音、节奏、停顿和语调)的语音语料库作为基础语音。转换为参考音色后,我们观察到所有风格都被很好地保留。在极少数情况下,情感会略微中性化,我们发现解决这个问题的一种方法是用同一基础说话者的具有不同情感的多个句子的平均向量替换该特定句子的音色嵌入向量。这样做会给流层提供较少的情感信息,以便它们不会消除情感。由于音色转换器能够保留基础声音的所有风格,通过简单操作基础说话者 TTS 模型来控制语音风格变得非常简单。定性结果可在此网站上公开获得 https://research.myshell.ai/open-voice/flexible-voice-style-control。
轻松的跨语言语音克隆。 OpenVoice 实现了几乎零-shot 的跨语言语音克隆,而不需要使用新语言的海量说话者数据。它确实需要语言的基础说话者,可以通过现成的模型和数据集轻松实现。在我们的网站 https://research.myshell.ai/open-voice/zero-shot-cross-lingual-voice-cloning 上,我们提供了丰富的样本,展示了所提出方法的跨语言语音克隆能力。跨语言能力有两个方面:
- 当参考说话者的语言在 MSML 数据集中看不到时,模型能够准确克隆参考说话者的音色。
- 当生成语音的语言在 MSML 数据集中看不到时,模型能够克隆参考声音并以该语言说话,只要基础说话者 TTS 支持该语言。
低成本快速推理。 由于 OpenVoice 是一个前向结构,没有任何自回归组件,它具有非常高的推理速度。我们的实验表明,略微优化的 OpenVoice 版本(包括基础说话者模型和音色转换器)能够在单个 A10G GPU 上实现 $12\times$ 的实时性能,这意味着生成一秒语音只需 85ms。通过详细的 GPU 使用分析,我们估计上限约为 $40\times$ 的实时性能,但我们将这一改进留作将来的工作。
IPA 的重要性。 我们发现将 IPA 用作音素词典对于音色转换器执行跨语言语音克隆至关重要。正如我们在第2.3节中详细说明的那样,在训练音色转换器时,首先将文本转换为 IPA 中的一系列音素,然后每个音素由一个可学习的向量嵌入表示。嵌入序列通过变压器层编码,并与流层的输出计算损失,旨在消除音色信息。IPA 本身是一个跨语言统一的音素词典,这使得流层能够产生语言中性的表示。即使我们向音色转换器输入具有看不见语言的语音,它仍能顺利处理音频。我们还尝试过其他类型的音素词典,但生成的音色转换器往往会在未知语言中发音不准确。虽然输入音频是正确的,但输出音频很可能有问题,听起来不像是母语人士。
4 讨论
OpenVoice 展示了出色的实例语音克隆能力,并在语音风格和语言方面比以前的方法更加灵活。该方法背后的直觉是,只要我们不要求模型具有克隆参考说话者音色的能力,训练基础说话者 TTS 模型来控制语音风格和语言相对容易。因此,我们建议将音色克隆与其余语音风格和语言分离,我们认为这是 OpenVoice 的基本设计原则。为了促进未来的研究,我们公开了源代码和模型权重。
附:模型结构-配置和模块
Config:
{
"_version_": "v2",
"data": {
"sampling_rate": 22050,
"filter_length": 1024,
"hop_length": 256,
"win_length": 1024,
"n_speakers": 0
},
"model": {
"zero_g": true,
"inter_channels": 192,
"hidden_channels": 192,
"filter_channels": 768,
"n_heads": 2,
"n_layers": 6,
"kernel_size": 3,
"p_dropout": 0.1,
"resblock": "1",
"resblock_kernel_sizes": [
3,
7,
11
],
"resblock_dilation_sizes": [
[
1,
3,
5
],
[
1,
3,
5
],
[
1,
3,
5
]
],
"upsample_rates": [
8,
8,
2,
2
],
"upsample_initial_channel": 512,
"upsample_kernel_sizes": [
16,
16,
4,
4
],
"gin_channels": 256
}
}
整体推理过程 和 音色转换过程如图代码所示:

Reference encoder: ReferenceEncoder (当模型配置为n_speakers==0的时候使用)
(ref_enc): ReferenceEncoder(
(convs): ModuleList(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): Conv2d(32, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(2): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(4): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(5): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
(gru): GRU(1152, 128, batch_first=True)
(proj): Linear(in_features=128, out_features=256, bias=True)
(layernorm): LayerNorm((513,), eps=1e-05, elementwise_affine=True)
)
forward:
def forward(self, inputs, mask=None):
N = inputs.size(0)
out = inputs.view(N, 1, -1, self.spec_channels) # [N, 1, Ty, n_freqs]
if self.layernorm is not None:
out = self.layernorm(out)
for conv in self.convs:
out = conv(out)
# out = wn(out)
out = F.relu(out) # [N, 128, Ty//2^K, n_mels//2^K]
out = out.transpose(1, 2) # [N, Ty//2^K, 128, n_mels//2^K]
T = out.size(1)
N = out.size(0)
out = out.contiguous().view(N, T, -1) # [N, Ty//2^K, 128*n_mels//2^K]
self.gru.flatten_parameters()
memory, out = self.gru(out) # out --- [1, N, 128]
return self.proj(out.squeeze(0))
encoder: PosteriorEncoder
(enc_q): PosteriorEncoder(
(pre): Conv1d(513, 192, kernel_size=(1,), stride=(1,))
(enc): WN(
(in_layers): ModuleList(
(0-15): 16 x Conv1d(192, 384, kernel_size=(5,), stride=(1,), padding=(2,))
)
(res_skip_layers): ModuleList(
(0-14): 15 x Conv1d(192, 384, kernel_size=(1,), stride=(1,))
(15): Conv1d(192, 192, kernel_size=(1,), stride=(1,))
)
(drop): Dropout(p=0, inplace=False)
(cond_layer): Conv1d(256, 6144, kernel_size=(1,), stride=(1,))
)
(proj): Conv1d(192, 384, kernel_size=(1,), stride=(1,))
)
forward:
def forward(self, x, x_lengths, g=None, tau=1.0):
x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
x.dtype
)
x = self.pre(x) * x_mask
x = self.enc(x, x_mask, g=g)
stats = self.proj(x) * x_mask
m, logs = torch.split(stats, self.out_channels, dim=1)
z = (m + torch.randn_like(m) * tau * torch.exp(logs)) * x_mask
return z, m, logs, x_mask
flow: ResidualCouplingBlock
(flow): ResidualCouplingBlock(
(flows): ModuleList(
(0): ResidualCouplingLayer(
(pre): Conv1d(96, 192, kernel_size=(1,), stride=(1,))
(enc): WN(
(in_layers): ModuleList(
(0-3): 4 x Conv1d(192, 384, kernel_size=(5,), stride=(1,), padding=(2,))
)
(res_skip_layers): ModuleList(
(0-2): 3 x Conv1d(192, 384, kernel_size=(1,), stride=(1,))
(3): Conv1d(192, 192, kernel_size=(1,), stride=(1,))
)
(drop): Dropout(p=0, inplace=False)
(cond_layer): Conv1d(256, 1536, kernel_size=(1,), stride=(1,))
)
(post): Conv1d(192, 96, kernel_size=(1,), stride=(1,))
)
(1): Flip()
(2): ResidualCouplingLayer(
(pre): Conv1d(96, 192, kernel_size=(1,), stride=(1,))
(enc): WN(
(in_layers): ModuleList(
(0-3): 4 x Conv1d(192, 384, kernel_size=(5,), stride=(1,), padding=(2,))
)
(res_skip_layers): ModuleList(
(0-2): 3 x Conv1d(192, 384, kernel_size=(1,), stride=(1,))
(3): Conv1d(192, 192, kernel_size=(1,), stride=(1,))
)
(drop): Dropout(p=0, inplace=False)
(cond_layer): Conv1d(256, 1536, kernel_size=(1,), stride=(1,))
)
(post): Conv1d(192, 96, kernel_size=(1,), stride=(1,))
)
(3): Flip()
(4): ResidualCouplingLayer(
(pre): Conv1d(96, 192, kernel_size=(1,), stride=(1,))
(enc): WN(
(in_layers): ModuleList(
(0-3): 4 x Conv1d(192, 384, kernel_size=(5,), stride=(1,), padding=(2,))
)
(res_skip_layers): ModuleList(
(0-2): 3 x Conv1d(192, 384, kernel_size=(1,), stride=(1,))
(3): Conv1d(192, 192, kernel_size=(1,), stride=(1,))
)
(drop): Dropout(p=0, inplace=False)
(cond_layer): Conv1d(256, 1536, kernel_size=(1,), stride=(1,))
)
(post): Conv1d(192, 96, kernel_size=(1,), stride=(1,))
)
(5): Flip()
(6): ResidualCouplingLayer(
(pre): Conv1d(96, 192, kernel_size=(1,), stride=(1,))
(enc): WN(
(in_layers): ModuleList(
(0-3): 4 x Conv1d(192, 384, kernel_size=(5,), stride=(1,), padding=(2,))
)
(res_skip_layers): ModuleList(
(0-2): 3 x Conv1d(192, 384, kernel_size=(1,), stride=(1,))
(3): Conv1d(192, 192, kernel_size=(1,), stride=(1,))
)
(drop): Dropout(p=0, inplace=False)
(cond_layer): Conv1d(256, 1536, kernel_size=(1,), stride=(1,))
)
(post): Conv1d(192, 96, kernel_size=(1,), stride=(1,))
)
(7): Flip()
)
)
forward:
def forward(self, x, x_mask, g=None, reverse=False):
if not reverse:
for flow in self.flows:
x, _ = flow(x, x_mask, g=g, reverse=reverse)
else:
for flow in reversed(self.flows):
x = flow(x, x_mask, g=g, reverse=reverse)
return x
decoder: Generator (HIFI-GAN Generator)
(dec): Generator(
(conv_pre): Conv1d(192, 512, kernel_size=(7,), stride=(1,), padding=(3,))
(ups): ModuleList(
(0): ConvTranspose1d(512, 256, kernel_size=(16,), stride=(8,), padding=(4,))
(1): ConvTranspose1d(256, 128, kernel_size=(16,), stride=(8,), padding=(4,))
(2): ConvTranspose1d(128, 64, kernel_size=(4,), stride=(2,), padding=(1,))
(3): ConvTranspose1d(64, 32, kernel_size=(4,), stride=(2,), padding=(1,))
)
(resblocks): ModuleList(
(0): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
(1): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(3,), dilation=(3,))
(2): Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(5,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(256, 256, kernel_size=(3,), stride=(1,), padding=(1,))
)
)
(1): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(3,))
(1): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(9,), dilation=(3,))
(2): Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(15,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(256, 256, kernel_size=(7,), stride=(1,), padding=(3,))
)
)
(2): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(5,))
(1): Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(15,), dilation=(3,))
(2): Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(25,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(256, 256, kernel_size=(11,), stride=(1,), padding=(5,))
)
)
(3): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
(1): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(3,), dilation=(3,))
(2): Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(5,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(128, 128, kernel_size=(3,), stride=(1,), padding=(1,))
)
)
(4): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(3,))
(1): Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(9,), dilation=(3,))
(2): Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(15,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(128, 128, kernel_size=(7,), stride=(1,), padding=(3,))
)
)
(5): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(5,))
(1): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(15,), dilation=(3,))
(2): Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(25,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(128, 128, kernel_size=(11,), stride=(1,), padding=(5,))
)
)
(6): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(1): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(3,), dilation=(3,))
(2): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(5,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
)
)
(7): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(64, 64, kernel_size=(7,), stride=(1,), padding=(3,))
(1): Conv1d(64, 64, kernel_size=(7,), stride=(1,), padding=(9,), dilation=(3,))
(2): Conv1d(64, 64, kernel_size=(7,), stride=(1,), padding=(15,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(64, 64, kernel_size=(7,), stride=(1,), padding=(3,))
)
)
(8): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(64, 64, kernel_size=(11,), stride=(1,), padding=(5,))
(1): Conv1d(64, 64, kernel_size=(11,), stride=(1,), padding=(15,), dilation=(3,))
(2): Conv1d(64, 64, kernel_size=(11,), stride=(1,), padding=(25,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(64, 64, kernel_size=(11,), stride=(1,), padding=(5,))
)
)
(9): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(32, 32, kernel_size=(3,), stride=(1,), padding=(1,))
(1): Conv1d(32, 32, kernel_size=(3,), stride=(1,), padding=(3,), dilation=(3,))
(2): Conv1d(32, 32, kernel_size=(3,), stride=(1,), padding=(5,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(32, 32, kernel_size=(3,), stride=(1,), padding=(1,))
)
)
(10): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(32, 32, kernel_size=(7,), stride=(1,), padding=(3,))
(1): Conv1d(32, 32, kernel_size=(7,), stride=(1,), padding=(9,), dilation=(3,))
(2): Conv1d(32, 32, kernel_size=(7,), stride=(1,), padding=(15,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(32, 32, kernel_size=(7,), stride=(1,), padding=(3,))
)
)
(11): ResBlock1(
(convs1): ModuleList(
(0): Conv1d(32, 32, kernel_size=(11,), stride=(1,), padding=(5,))
(1): Conv1d(32, 32, kernel_size=(11,), stride=(1,), padding=(15,), dilation=(3,))
(2): Conv1d(32, 32, kernel_size=(11,), stride=(1,), padding=(25,), dilation=(5,))
)
(convs2): ModuleList(
(0-2): 3 x Conv1d(32, 32, kernel_size=(11,), stride=(1,), padding=(5,))
)
)
)
(conv_post): Conv1d(32, 1, kernel_size=(7,), stride=(1,), padding=(3,), bias=False)
(cond): Conv1d(256, 512, kernel_size=(1,), stride=(1,))
)
forward:
def forward(self, x, g=None):
x = self.conv_pre(x)
if g is not None:
x = x + self.cond(g)
for i in range(self.num_upsamples):
x = F.leaky_relu(x, modules.LRELU_SLOPE)
x = self.ups[i](x)
xs = None
for j in range(self.num_kernels):
if xs is None:
xs = self.resblocks[i * self.num_kernels + j](x)
else:
xs += self.resblocks[i * self.num_kernels + j](x)
x = xs / self.num_kernels
x = F.leaky_relu(x)
x = self.conv_post(x)
x = torch.tanh(x)
return x
HIFI-GAN generator 结构

-
C. Wang, S. Chen, Y. Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023. ↩︎
-
CoquiAI. Xtts taking text-to-speech to the next level. Technical Blog, 2023. ↩︎
-
E. Casanova, J. Weber, C. D. Shulby, A. C. Junior, E. Gölge, and M. A. Ponti. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In International Conference on Machine Learning, pages 2709–2720. PMLR, 2022. ↩︎
-
M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, R. Moritz, M. Williamson, V. Manohar, Y. Adi, J. Mahadeokar, et al. Voicebox: Text-guided multilingual universal speech generation at scale. arXiv preprint arXiv:2306.15687, 2023. ↩︎
-
Z. Zhang, L. Zhou, C. Wang, S. Chen, Y. Wu, S. Liu, Z. Chen, Y. Liu, H. Wang, J. Li, et al. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. arXiv preprint arXiv:2303.03926, 2023. ↩︎
-
J. Kim, J. Kong, and J. Son. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In International Conference on Machine Learning, pages 5530–5540. PMLR, 2021. ↩︎
-
D. Yang, S. Liu, R. Huang, G. Lei, C. Weng, H. Meng, and D. Yu. Instructtts: Modelling expressive tts in discrete latent space with natural language style prompt. arXiv preprint arXiv:2301.13662, 2023. ↩︎
-
D. Rezende and S. Mohamed. Variational inference with normalizing flows. In International conference on machine learning, pages 1530–1538. PMLR, 2015. ↩︎
-
I. P. Association. Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet. Cambridge University Press, 1999. ↩︎
-
J. Kong, J. Kim, and J. Bae. HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33:17022–17033, 2020. ↩︎
-
B. van Niekerk, M.-A. Carbonneau, J. Zaïdi, M. Baas, H. Seuté, and H. Kamper. A comparison of discrete and soft speech units for improved voice conversion. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6562–6566. IEEE, 2022. ↩︎
-
A. Polyak, Y. Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux. Speech resynthesis from discrete disentangled self-supervised representations. arXiv preprint arXiv:2104.00355, 2021. ↩︎
-
J. Kim, S. Kim, J. Kong, and S. Yoon. Glow-tts: A generative flow for text-to-speech via monotonic alignment search. Advances in Neural Information Processing Systems, 33:8067–8077, 2020. ↩︎
-
W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021. ↩︎
-
J. Li, W. Tu, and L. Xiao. Freevc: Towards high-quality text-free one-shot voice conversion. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. ↩︎
-
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017. ↩︎
-
P. Senin. Dynamic time warping algorithm review. Information and Computer Science Department University of Hawaii at Manoa Honolulu, USA, 855(1-23):40, 2008. ↩︎
-
M. Müller. Dynamic time warping. Information retrieval for music and motion, pages 69–84, 2007. ↩︎