想象一下,当您尝试将 100 美元从账户 A 转账到账户 B,并且两个账户都在同一家银行时。启动传输后,您刷新屏幕。然而,当您刷新屏幕时,您的总余额就会下降——那 100 美元似乎凭空消失了。您看到帐户 A 少了 100 美元。然而,B账户并没有多出100美元。然后,您刷新屏幕几次,可以看到帐户 B 获得了 100 美元。
您在事务期间遇到的这个问题称为读取偏差。当您在不幸运的时间(写入交易期间和之后)读取交易时,就会发生异常。
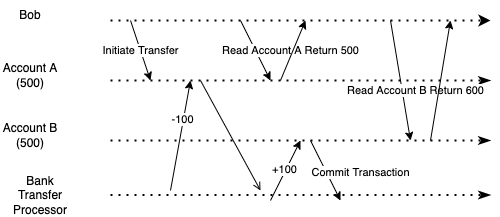
这可能会带来不好的用户体验,但如果转账交易成功后刷新页面,这不会造成任何问题。
然而,在进行数据库备份或分析查询时,读取偏差会成为一个问题。
在数据库备份中,我们需要制作数据库的副本。备份过程中可能会有写请求进来,如果出现读倾斜不一致的情况,可能会导致备份结果不一致。部分数据为旧版本,部分数据为新版本。通过这样的操作,这种不一致的问题可能会永久存在。
我们需要在分析查询中扫描大型数据库并定期检查数据损坏。读取偏差可能会导致搜索和检查不一致 - 通常可能会产生不一致的结果并引发有关数据损坏的错误警报。
解决读取偏差
读取倾斜的问题是读事务在旧数据库版本中读取一次,在新数据库版本中读取另一次。
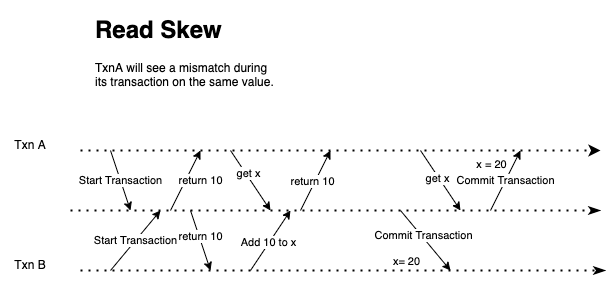
这里重要的一点是读取事务需要一致 - 它不需要是最新版本。从事务开始到结束需要保持一致,所以我们需要保持数据版本相同。
例如,如果 Bob 正在以数据版本 1 运行读事务,则在整个事务中,Bob 应该只能读取数据库数据版本 1。如果在事务处理过程中,发生新的写事务,这将导致更新数据库中的数据。Bob 将不会在他的交易中看到该新版本。
因此,我们可以使事务从数据库的一致快照中读取——事务将从事务开始时其他事务在数据库中提交的所有数据中看到。
此功能称为快照隔离,许多关系数据库都提供此功能,例如 PostgreSQL 和 MySQL。
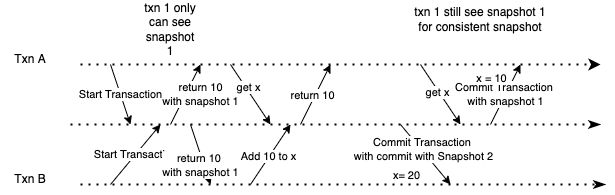
实施快照隔离
我们需要在数据库中保留各种快照版本来实现快照隔离。每次事务开始时,数据库都会将最新提交的快照版本赋予该事务。然后,数据库将跟踪每个事务及其相应的快照版本,以保持读取的一致性。
每个事务都有一个transactionId,并且transactionId是从数据库中检索的。因此,transactionId总是在增加。数据库跟踪每个transactionId写入数据库的使用createdAt和deletedAt值。transactionId提交事务后,数据库使用事务中的 对该操作创建了一个标记。数据库进一步制作新交易的快照,并用最新的 transactionId 标记该快照。当有新的事务从数据库读取时,数据库会检索该事务之前最新提交的事务,有以下几个规则:
- 即使提交了后续事务,也不会显示当前尚未提交到数据库的任何 transactionId。
- 任何中止的交易也不会显示。
- 数据库不会显示任何晚于
transactionId(大于)当前的事务transactionId。 - 数据库将向读取数据库的其他传入事务显示任何其他事务。
让我们看看 Bob 的场景中会发生什么:
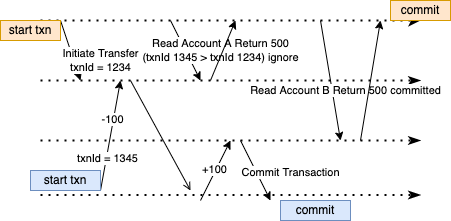
- 当 Bob 发起转账交易时,它会启动一个后台进程,将 100 美元从账户 A 转账到账户 B。该交易将首先调用数据库或辅助服务来获取增量,然后发起交易 - 假设交易是
transactionId1234 。 - 后续的读取事务将需要通过获取增量
transactionId并向数据库调用读取请求来执行相同的操作 - 假设是transactionId1345。 - 当传输尚未完成时,数据库不会向 Bob 显示
transactionId1234(规则 1)应用的数据。 - 如果在 1345 之后启动另一个写入事务
transactionId,因为该事务具有更大的transactionId,数据库将不会向transactionId1345 显示该事务(规则号 3)。
在删除过程中,数据库不会立即删除该字段中的值,而是会在该字段上标记一个墓碑 逻辑删除。不立即删除该值的原因之一是那些早期的交易可能仍然使用该值。因此,一旦所有事务都使用提交给其事务的值,我们就可以利用垃圾收集来异步检查和删除该值。
对分布式环境进行快照隔离
到目前为止,我们已经探索了如何解决单节点环境中的读取倾斜——我们假设数据库不分布在多个集群上。
如何在分布式环境中扩展快照隔离?
transactionId在分布式环境中很难得到一个全局的、不断增长的。出于一个原因,可能驻留在不同数据库中的每台计算机可能都有其 UUID 计数器,我们需要进行一些协调以确保因果关系。如果事务B从事务A读取值,我们要确保事务B的值大于transactionId事务A。我们如何处理复制数据库中的一致快照?
我们可以使用时钟或一天中的时间作为transactionId写入数据库吗?当天时钟不可靠,因为 NTP 同步基于不可靠的网络。因此,有些机器可能会出现时钟偏差,在时间上任意向后移动。一个节点的时间也可能与另一节点的时间不同。然而,如果我们能让时钟足够准确,它就可以作为transactionId——时钟的时间晚意味着事件产生的晚。我们如何确保时钟对于 transactionId 来说足够准确?
当检索每台机器中的时间值时,我们希望它返回一个置信区间,[Tbegin, Tlast]而不是获取单个值。置信区间表示时钟的标准偏差为正负范围Begin和Tlast。如果有两笔交易,transactionX,transactionY进来,[TbeginX, TlastX],[TbeginY, TlastY], 和TlastX < TbeginY。我们可以确保transactionX早于tranasctionY。但是,如果值重叠,我们就无法确定顺序。Google Spanner使用的是这种方法实现其快照隔离。Spanner 会故意等到超过前一个事务的置信区间而不重叠时才提交当前事务。因此,他们需要保持机器上每个时钟的置信时间间隔尽可能小,以避免延迟。Google 在每个数据中心部署原子钟或 GPS 服务器,以实现时钟同步。
为了确保每个数据库副本上的快照都是最新的,我们可以使用Quorum仲裁策略从其所有数据库集群中获取所有最新的事务快照。我们可以使用的另一个策略是确保事务始终路由到同一数据库实例以获得一致的快照结果。
概括
当由于后台发生另一个写入事务而无法从读取数据库数据中看到一致的结果时,就会发生读取偏差。一致性快照是单节点数据库读取倾斜的解决方案。
一致性快照是一种隔离级别,可保证每个事务都从数据库的一致性快照中读取数据,通常是当前启动的事务之前的最新快照。
实现快照隔离需要一个单调递增的计数器transactionId来确定返回哪个版本给事务调用。然而,在处理分布式环境时,这可能很困难,因为需要协调才能产生因果关系。解决此问题的一种解决方案是使用时钟返回置信区间来创建不断增加的transactionId.
最后,为了确保每个事务获得一致的快照,我们可以使用仲裁策略始终返回大多数节点返回的当前事务的最新快照,或者在事务调用和数据库实例上具有会话关联性。
如何确保分布式系统中的读取一致性?将如何解决创建全局的问题transactionId?