
图片来源: https://aiptcomics.com/2024/04/10/transformers-7-2024-review/
摘要: 本文介绍了一种有效的方法,将基于Transformer的大型语言模型(LLMs)扩展到无限长的输入,同时受到内存和计算的限制。我们提出的方法的关键组成部分是一种新的注意力技术,称为Infini-attention。Infini-attention将一种压缩内存集成到了传统的注意力机制中,并在单个Transformer块中构建了掩码局部注意力和长期线性注意力机制。我们通过在长上下文语言建模基准、1M序列长度的口令(keypass)上下文块检索和500K长度的书籍摘要任务中使用1B和8B LLMs,展示了我们方法的有效性。我们的方法引入了最小的有界内存参数,并实现了LLMs的快速流式推理。
注:为解决大模型(LLMs)在处理超长输入序列时遇到的内存限制问题,本文作者提出了一种新型架构:Infini-Transformer,它可以在有限内存条件下,让基于Transformer的大语言模型(LLMs)高效处理无限长的输入序列。实验结果表明:Infini-Transformer在长上下文语言建模任务上超越了基线模型,内存最高可节约114倍。
感觉有种外挂存储库(类似向量数据库)嵌入到模型结构中。比如: Memorizing Transformers + code
在论文《Memorizing Transformers》中,作者提出了一种新的注意力机制,称为kNN-augmented attention layer,它结合了局部上下文的密集自注意力和对外部记忆的近似k-最近邻(kNN)搜索。这个机制的关键部分之一是使用了一个门控机制(gating mechanism)来结合局部注意力和外部记忆的注意力。
门控机制的具体实现如下:
门控分数(gating score):对于每个注意力头,模型会学习一个偏置(bias)$ bg $,这是一个可学习的参数,用于控制每个头在局部上下文和外部记忆之间的注意力分配。
门控函数(gating function):偏置$ bg $通过sigmoid函数进行处理,得到门控分数$ g = \sigma(bg) $。这个分数决定了模型在局部上下文和外部记忆之间如何分配其注意力。
注意力结果的结合:局部注意力的结果($ V_c $)和外部记忆注意力的结果($ V_m $)通过门控分数和一个元素级别的乘法操作结合起来,形成最终的注意力输出$ V_a $。这个过程可以用以下公式表示: $ g = \sigma(bg) $ $ V_a = V_m \odot g + V_c \odot (1 - g) $ 其中,$ \odot $表示元素级别的乘法,$ \sigma $是sigmoid函数。
通过这种方式,模型可以动态地在局部和长期记忆之间调整其注意力,以更好地处理长序列数据。这种门控机制使得Memorizing Transformer能够有效地利用外部记忆来提高其在各种任务上的性能,包括代码、数学论文、书籍等长文本数据集的语言建模任务。
在Memorizing Transformers基础上,结合Compressive Memory + Linear attetion机制 + 增量规则 => Infinite Context Transformers
目的:
- 通过翻译通读论文,了解Transformer相关优化模型结构论文思路,比如文中对比的 Transformer-XL + code,Compressive Transformer + code,Recurrent Memory Transformer(RMT) + code, Memorizing Transformers + code(使用基于向量检索的 KV 存储器,主要是在该论文的基础上实验),Adapting Language Models to Compress Contexts(AutoCompressors) + code;还有一篇Jeff Dean主导的模型推理工程优化论文:Efficiently scaling transformer inference可以通读下 。
- 文中通过摘要任务进行对比的Unlimiformer,熟悉论文:Unlimiformer: Long-Range Transformers with Unlimited Length Input + code : Unlimiformer通过将交叉注意力计算卸载到一个单一的k-最近邻(kNN)索引中,从而允许每个解码器层中的每个标准交叉注意力头只关注输入序列中的top-k键。这种方法可以在GPU或CPU内存中存储kNN索引,并以亚线性时间进行查询,因此可以索引实际上无限的输入序列
- Infini-Transformer论文中提到的优化技术:Compressive Memory 还可以整合到现到Sparse MoE 相关的模型结构中,比如Switch Transformers , ModuleFormer中提到的Sparse MoE中;诶~是不是做做实验,困惑度(perplexity)/loss 效果不错的话是不是可以发个论文嘞~;Google大法下了个优化蛋,后面跟着一批组合优化蛋。法力无边,ღ( ´・ᴗ・` )比心~
- 借鉴建模预训练和继续预训练实验方法,以及任务微调测试方法;借鉴在小模型上的实验方法和评估方法;低成本实现方案去复现。
- scaling到更长文本序列长度。理论上没有限制,Infini-attention以递归方式对固定数量的内存参数进行增量内存更新。
论文解读:
原论文地址: https://arxiv.org/pdf/2404.07143.pdf
论文中提到 Compressive Memory 来自:
- Sparse distributed memory (SDM)
- SDM 与原始attention的结合在GPT2模型结构中,可以看下这个视频:Attention Approximates Sparse Distributed Memory + code
- Metalearned neural memory. Advances in Neural Information Processing Systems | Learning associative inference using fast weight memory + code;
Infini-attention的优化借鉴Linear attetion机制 + 增量规则 => 更新规则(线性(Linear) + 增量(Delta)):
更新规则(Update Rule): 如果在KV 绑定已经存在于内存中,则保持关联矩阵不变,同时,仍跟踪与前一个更新规则相同的归一化项(线性)以保证数值稳定性
- Linear attention的探索:Attention必须有个Softmax吗?
- Efficient Attention: Attention with Linear Complexities [v10] + code + video 中的线性注意力(Linear attention)机制;并利用相关方法中的稳定训练技术;
- Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention + website 中的线性注意力(Linear attention)机制;更新规则和检索机制,主要是因为其简单性和竞争性能;
- Rethinking Attention with Performers + blog + code + video 论文中未提到,但是感觉可以加入优化;
- Landmark Attention + code : 稀疏性纳入注意力层, 了解思路;
- Delta Rule: 增量规则尝试通过首先检索现有值条目并将它们从新值中减去,然后应用关联绑定作为新的更新,稍微改进了内存更新
论文作者: Tsendsuren Munkhdalai , 也是 Metalearned neural memory 和 Learning associative inference using fast weight memory (FWM) 的作者,沿用了以前的优化(作者以前在微软发的论文),与原始attention结构结合;在压缩内存中存储键和值状态的绑定,并使用查询向量进行检索。其他两位作者是google bart(现在的gemini模型)项目负责研究主管人员。
1 引言
内存作为智能的基石,它使得针对特定上下文的高效计算成为可能。然而,Transformer(Vaswani等人,2017年)和基于Transformer的大型语言模型(LLMs)(Brown等人,2020年;Touvron等人,2023年;Anil等人,2023年;Groeneveld等人,2024年)由于注意力机制的本质,具有受限的上下文依赖内存。
Transformer中的注意力机制在内存占用和计算时间上表现出二次方复杂度。例如,对于一个批量大小为512,上下文长度为2048的500B模型,注意力键值(KV)状态有3TB的内存占用(Pope等人,2023年)。实际上,将LLMs扩展到更长的序列(例如1M个标记)对于标准Transformer架构来说是一个挑战,而且随着上下文模型变得越来越长,其服务成本也越来越高。
压缩内存(Compressive memory)系统承诺比注意力机制更可扩展和高效,特别是对于极长序列(Kanerva,1988年;Munkhdalai等人,2019年)。与随输入序列长度增长的数组不同,压缩内存主要通过改变其参数来存储和回忆信息,以实现有界的存储和计算成本。在压缩内存中,通过改变其参数来添加新信息到内存中,目标是稍后能够恢复这些信息。然而,目前的LLMs还没有看到一个有效的、实用的压缩内存技术,该技术在简单性和质量之间取得了平衡。
在这项工作中,我们介绍了一种新的方法,使得Transformer LLMs能够有效地处理无限长的输入,同时内存占用和计算资源有界。我们提出的方法的一个关键组成部分是一个新的注意力技术,称为Infini-attention(图1)。
Infini-attention将压缩内存整合到传统的注意力机制中,并在单个Transformer块中构建了掩蔽的局部注意力(Causal SDPA)和长期的线性注意力(Linear attention)机制。
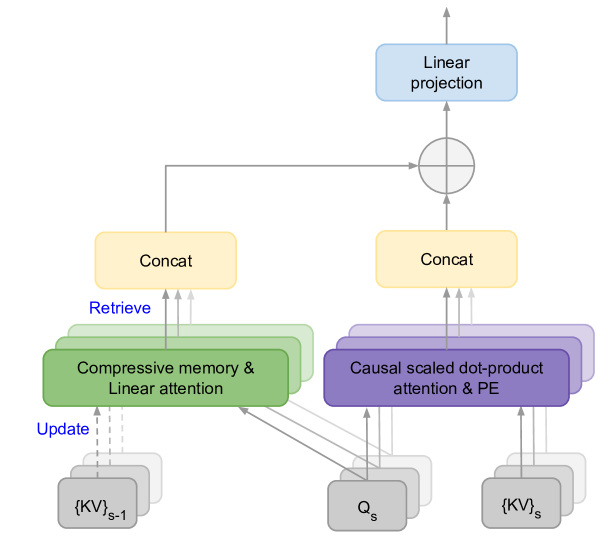
图 1:Infini-attention 具有一个额外的压缩内存,使用线性注意力处理无限长的上下文。${KV}_{s-1}$ 和 ${KV}_s$ 分别是当前和前一个输入片段的注意力键和值,而 $Q_s$ 是注意力查询。PE 表示位置嵌入。
这种对Transformer注意力层的微妙但关键的修改,使得现有的LLMs能够通过持续的预训练和微调,自然地扩展到无限长的上下文。我们的Infini-attention重用了标准注意力计算的所有键、值和查询状态,用于长期内存的巩固和检索。我们将注意力的旧KV状态存储在压缩内存中,而不是像在标准注意力机制中那样丢弃它们。然后,我们在使用注意力查询状态处理后续序列时,从内存中检索值。为了计算最终的上下文输出,Infini-attention聚合了长期内存检索到的值和局部注意力上下文。
在我们的实验中,我们展示了我们的方法在长上下文语言建模基准测试中胜过了基线模型,同时在内存大小上具有114倍的理解比率。当使用100K序列长度进行训练时,模型达到了更低的困惑度(perplexity)。一个1B LLM自然扩展到1M序列长度,并在注入Infini-attention后解决了口令(passkey)检索任务。最后,我们展示了一个8B模型在持续预训练和任务微调后,使用Infini-attention在500K长度的书籍摘要任务上达到了新的SOTA结果。
总之,我们的工作做出了以下贡献:
- 我们引入了一个实用而强大的注意力机制Infini-attention,它具有长期压缩内存和局部因果注意力,能够有效地建模长距离和短距离的上下文依赖关系。
- Infini-attention对标准的缩放点积注意力进行了最小的改变,并支持即插即用的持续预训练和长上下文适应。
- 我们的方法使Transformer LLMs能够通过流式处理极长的输入,扩展到无限长的上下文,同时保持有界的内存和计算资源。
2 方法
图2比较了我们的模型Infini-Transformer和Transformer-XL(Dai等人,2019年)。与Transformer-XL类似,Infini-Transformer在一系列片段上操作。我们在每个片段内计算标准的因果点积注意力上下文。因此,点积注意力计算在某种意义上是局部的,它涵盖了当前片段S(N是片段长度),总共N个token。

图 2:Infini-Transformer(顶部)具有完整的上下文历史,而 Transformer-XL(底部)会丢弃旧的上下文,因为它只缓存了最后一个片段的 KV 状态。
然而,局部注意力(Dai等人,2019年)在处理下一个片段时会丢弃前一个片段的注意力状态。在Infini-Transformers中,我们提出不仅不丢弃旧的KV注意力状态,而是重用它们来通过压缩内存维持整个上下文历史。因此,Infini-Transformers的每个注意力层都具有全局压缩和局部细粒度状态。我们称这种高效的注意力机制为Infini-attention,如图1所示,并在以下各节中正式描述。
2.1 Infini-attention
如图1所示,我们的Infini-attention计算局部和全局上下文状态,并结合它们输出。与多头注意力(MHA)类似,它在每个注意力层中维护H个并行的压缩内存(H是注意力头的数量),除了点积注意力外。
2.1.1 缩放点积注意力
多头缩放点积注意力(Vaswani等人,2017年),特别是其自注意力变体(Munkhdalai等人,2016年;Cheng等人,2016年),已成为LLMs的主要构建块。MHA的强大能力可以模拟上下文依赖的动态计算,并且其时间掩蔽的便利性在自回归生成模型中得到了广泛利用。
在普通 MHA 中,一个单独的注意力头(head)从输入序列段(input segments)$X \in {\rm I!R}^{N \times d_{model}}$ 计算其注意力上下文 $A_{dot} \in {\rm I!R}^{N \times d_{value}}$,具体过程如下。首先,它计算注意力的查询(query)、键(key)和值(value)状态: $$ K = XW_K, \text{ } V = XW_V \text{ 且 } Q = XW_Q. $$ 这里,$W_K \in {\rm I!R}^{d_{model} \times d_{key}}$、$W_V \in {\rm I!R}^{d_{model} \times d_{value}}$ 和 $W_Q \in {\rm I!R}^{d_{model} \times d_{key}}$ 是可训练的投影矩阵。然后,注意力上下文被计算为所有其他值的加权平均值:
$$ A_{dot} = \text{softmax}\left(\frac{Q K^T}{\sqrt{d_{model}}}\right) V. $$ 对于 MHA,我们并行地为每个序列元素计算 $H$ 个注意力上下文向量,沿着第二个维度将它们连接起来,最后将连接的向量投影到模型空间以获得注意力输出。
2.1.2 压缩式内存(Compressive Memory)
在无限注意力(Infini-attention)中,与为压缩式内存计算新的内存条目不同,我们重复使用点积注意力计算中的查询(query)、键(key)和值(value)状态($Q$、$K$ 和 $V$)。点积注意力和压缩内存之间的状态共享和重用不仅实现了高效的即插即用长上下文适应,还加快了训练和推理速度。与之前的工作(Munkhdalai等人,2019年)类似,我们的目标是在压缩内存中存储键和值状态的绑定,并使用查询向量进行检索。
尽管文献中提出了不同形式的压缩内存(Hopfield,1982年;Kanerva,1988年;Schlag等人,2019年;Munkhdalai等人,2019年),为了简单和计算效率,我们在这项工作中用关联矩阵(Schlag等人,2020年)参数化内存。这种方法进一步允许我们将内存更新和检索过程视为线性注意力机制(Shen等人,2018年),并利用相关方法中的稳定训练技术。特别是,我们采用了Katharopoulos等人(2020年)的更新规则和检索机制,主要是因为其简单性和竞争性能。
内存检索(Memory retrieval)。 在无限注意力中,我们通过使用查询 $Q \in {\rm I!R}^{N \times d_{key}}$ 从内存 $M_{s-1} \in {\rm I!R}^{d_{key} \times d_{value}}$ 中检索新的内容 $A_{mem} \in {\rm I!R}^{N \times d_{value}}$,计算如下: $$ A_{mem} = \frac{\sigma({Q}) M_{s-1}} {{\sigma(Q)} z_{s-1}}. $$ 这里,$\sigma$ 和 $z_{s-1} \in {\rm I!R}^{d_{key}}$ 分别是非线性激活函数和归一化项。由于非线性和规范化方法的选择对训练稳定性至关重要,因此我们遵循Katharopoulos等人(2020年)记录所有键的总和作为归一化项$z_{s-1}$,并使用逐元素ELU + 1作为激活函数(Clevert等人,2015年)。
内存更新(Memory update)。 一旦检索完成,我们使用新的 KV 条目更新内存和归一化项,并获得下一个状态,如下所示: $$ M_{s} \leftarrow M_{s-1} + \sigma(K)^T V \text{ 和 } z_{s} \leftarrow z_{s-1} + \sum_{t=1}^N \sigma(K_t). $$ 新的内存状态 $M_{s}$ 和 $z_{s}$ 然后传递给下一个段 $S+1$,在每个注意力层中形成了一个递归。式中的右侧项 $\sigma(K)^T V $ 被称为关联绑定算子。
受到增量规则(Delta Rule)的成功启发,我们还将其纳入了我们的无限注意力中。增量规则尝试通过首先检索现有值条目并将它们从新值中减去,然后应用关联绑定作为新的更新,稍微改进了内存更新。 $$ M_{s} \leftarrow M_{s-1} + \sigma(K)^T (V - \frac{\sigma({K}) M_{s-1}} {{\sigma(K)} z_{s-1}}). $$ 更新规则(线性(Linear) + 增量(Delta)):如果在 KV 绑定已经存在于内存中,则保持关联矩阵不变,同时,仍跟踪与前一个更新规则相同的归一化项(线性)以保证数值稳定性。
长期上下文注入(Long-term context injection)。 我们通过一个学习得到的门控标量 $\beta$ 聚合了局部注意力状态 $A_{dot}$ 和内存检索的内容 $A_{mem}$: $$ A = \textit{sigmoid} (\beta) \odot A_{mem} + (1 - \textit{sigmoid}(\beta)) \odot A_{dot}. $$ 这仅增加了每个头部的单个标量值作为训练参数,同时允许在模型中学习长期和局部信息流之间的可学习权衡。与标准 MHA 类似,对于多头的无限注意力,我们并行计算 $H$ 个上下文状态,并将它们连接和投影以获得最终的注意力输出 $O \in {\rm I!R}^{N \times d_{model}}$: $$ O = [A^1; \dotso A^H] W_O $$
其中 $W_O \in {\rm I!R}^{H \times d_{value} \times d_{model}}$ 是可训练权重。
2.2 内存和有效上下文窗口(Memory and Effective Context Window)
| Model | Memory (cache) footprint | Context length | Memory update | Memory retrieval |
|---|---|---|---|---|
| Transformer-XL | $(d_{key} + d_{value}) \times H \times N \times l$ | $N \times l$ | Discarded(丢弃) | Dot-product attention |
| Compressive Transformer | $d_{model} \times (c + N) \times l$ | $(c \times r + N) \times l$ | Discarded(丢弃) | Dot-product attention |
| Memorizing Transformers | $(d_{key} + d_{value}) \times H \times N \times S$ | $N \times S$ | None | kNN + dot-product attention |
| RMT | $d_{model} \times p \times l \times 2$ | $N \times S$ | Discarded(丢弃) | Soft-prompt input |
| AutoCompressors | $d_{model} \times p \times (m + 1) \times l$ | $N \times S$ | Discarded(丢弃) | Soft-prompt input |
| Infini-Transformers | $d_{key} \times (d_{value} + 1) \times H \times l$ | $N \times S$ | Incremental(增量) | Linear attention |
表1: 列出了以前具有段级内存的 Transformer 模型及其上下文-内存占用(footprint)和有效上下文长度,这些长度是根据模型参数和输入段长度定义的。对于每个模型,内存大小和有效上下文长度的定义如下:$N$:输入段长度,$S$:段的数量,$l$:层数,$H$:注意力头的数量,$c$:压缩式 Transformer 内存大小,$r$:压缩比率,$p$:软提示摘要向量(soft-prompt summary vectors)的数量,$m$:摘要向量积累步骤数。
我们的 Infini-Transformer 能够以有限的内存占用实现无界上下文窗口。为了说明这一点,表1 列出了先前具有段级内存的模型及其上下文-内存占用和有效上下文长度,这些长度是根据模型参数和输入段长度定义的。Infini-Transformer 对于每个头部在单个层中存储压缩的上下文的内存复杂度为 $d_{key} \times d_{value} + d_{key}$,而对于其他模型,复杂度随着序列维度增长而增加 - 内存复杂度要么依赖于缓存大小(如 Transformer-XL~(Dai等,2019年)、Compressive Transformer~(Rae等,2019年)和Memorizing Transformers~(Wu等,2022年)),要么依赖于软提示大小(如 RTM~(Bulatov等,2022年) 和 AutoCompressors~(Ge等,2023年))。
Transformer-XL 在计算注意力时,除了当前状态外,还会对上一段缓存的 KV 状态进行注意力计算。由于这是在每一层都进行的操作,因此 Transformer-XL 将上下文窗口从 $N$ 扩展到 $N \times l$ 个标记,而额外的内存占用为 $(d_{key} + d_{value}) \times H \times N \times l$。Compressive Transformer 在 Transformer-XL 的基础上增加了第二个缓存,并存储过去段激活的压缩表示。因此,它将 Transformer-XL 的上下文窗口扩展了 $c \times r \times l$,但仍具有较大的上下文-内存复杂度。Memorizing Transformers 选择将整个 KV 状态作为输入序列的上下文存储。由于在这种情况下存储变得成本过高,因此它们将上下文计算限制为仅在单个层中进行。通过利用快速 kNN 检索器,Memorizing Transformers 构建一个覆盖整个序列历史的上下文窗口,长度为 $N \times S$,但存储成本增加了。我们的实验表明,在 Memorizing Transformers 的基础上,Infini-Transformer LM 可以实现超过 100 倍的压缩率,同时进一步改善了困惑度(perplexity)得分。
RMT 和 AutoCompressors 允许潜在的无限上下文长度,因为它们将输入压缩成摘要向量,然后将它们作为额外的软提示输入传递给后续的段落。然而,在实践中,这些技术的成功程度高度依赖于软提示向量的大小。换句话说,为了使 AutoCompressors (Chevalier 等,2023年) 实现更好的性能,需要增加软提示(摘要)向量的数量,而这样做会导致内存和计算复杂度迅速增长,从而降低效率。也观察到在 AutoCompressors (Chevalier 等,2023年) 中需要一个高效的压缩目标来训练这种提示压缩技术 (Ge 等,2023年)。
3 实验
我们在涉及极长输入序列的基准数据集上评估了我们的 Infini-Transformer 模型:
长上下文语言建模、100万长度口令(passkey)块检索和50万长度书籍摘要任务。
对于长上下文语言建模基准,我们从头开始训练我们的模型;
而对于口令(passkey)块和书籍摘要任务,我们持续预训练现有的 LLMs,以突出我们方法的插拔式长上下文适应能力。
基准数据集: PG19 和 Arxiv-math
继续预训数据集:PG19 和 Arxiv-math + 长度超过 4K token的 C4 文本
微调数据:
- passkey检索任务数据 将一个随机数字隐藏在一段长文本中,并要求在模型输出中找回该数字(脚本生成即可)
- 书籍摘要任务 BookSum 数据集: https://huggingface.co/datasets/kmfoda/booksum
3.1 长上下文语言建模
我们在 PG19(Rae 等,2019年)和 Arxiv-math(Wu 等,2022年)基准数据集上训练和评估了小型的 Infini-Transformer 模型。我们的设置与 Memorizing Transformers(Wu 等,2022年)非常相似。具体来说,我们所有的模型都有 12 层,每层有 8 个注意力头,每个头的维度为 128,以及隐藏层为 4096 的 FFNs。
我们将 Infini-attention 的段长度 $N$ 设置为 2048,对于所有的注意力层输入序列长度设置为 32768 进行训练。这样可以让 Infini-attention 在关于其压缩内存状态的 16 个步骤上展开。对于 RMT 基线,我们进行了几次运行,摘要提示长度为 50、100 和 150,序列长度分别为 4096、8196 和 32768。当在长度为 8196 的序列上训练时,RMT 使用 100 个摘要向量时达到了最佳结果。
| Model | Memory size (comp.) | XL cache | Segment length | PG19 | Arxiv-math |
|---|---|---|---|---|---|
| Transformer-XL | 50M (3.7x) | 2048 | 2048 | 11.88 | 2.42 |
| Memorizing Transformers | 183M (1x) | 2048 | 2048 | 11.37 | 2.26 |
| RMT | 2.5M (73x) | None | 2048 | 13.27 | 2.55 |
| Infini-Transformer (Linear) | 1.6M (114x) | None | 2048 | 9.65 | 2.24 |
| Infini-Transformer (Linear + Delta) | 1.6M (114x) | None | 2048 | 9.67 | 2.23 |
表2:长上下文语言建模结果以平均单词级困惑度进行比较。Comp. 表示压缩比。Infini-Transformer 模型优于内存变压器(Memorizing Transformers),其存储器长度为 65K,并实现了114倍的压缩比。
语言建模实验的主要结果总结在表2中。 Infini-Transformer 在保持比 Memorizing Transformers(Wu 等,2022年)模型参数少 114 倍的情况下,优于 Transformer-XL(Dai 等,2019年)和 Memorizing Transformers 的基准模型,后者使用基于向量检索的 KV 存储器,在其第9层具有长度为 65K 的存储器。
100K长度训练。 我们进一步将训练序列长度从32K增加到100K,并在 Arxiv-math 数据集上对模型进行了训练。100K的训练进一步将困惑度分数降低到 2.21 和 2.20 分别对于 $Linear$ 和 $Linear + Delta$ 模型。
门控分数可视化(Gating score visualization)。 图3 展示了每一层中所有注意力头的压缩内存的门控分数 $\textit{sigmoid}(\beta)$。在训练后,Infini-attention 中出现了两种类型的头:门控分数接近 0 或 1 的专用头和分数接近 0.5 的混合头。专用头通过局部注意力计算处理上下文信息或从压缩内存中检索,而混合头将当前上下文信息和长期内存内容合并到一个输出中。有趣的是,每一层至少有一个短程头,允许输入信号向前传播直至输出层。我们还观察到在正向计算过程中长期和短期内容的检索交错进行。

图3:图中显示了训练后,在Infini-attention中出现了两种类型的注意力头:具有接近0或1的门控分数(gating score)的专用头和接近0.5的混合头。专用头通过局部注意力机制处理上下文信息或从压缩内存中检索,而混合头将当前上下文信息和长期(long-term)内存内容聚合到单个输出中。
3.2 LLM 持续预训练
我们对现有 LLM 进行了轻量级的持续预训练,以适应长上下文。预训练数据包括 PG19 和 Arxiv-math 语料库以及长度超过 4K token的 C4 文本(Raffel等人,2020)。我们的实验中,段长度 $N$ 设定为 2K。
1M 口令(passkey)检索基准测试。我们将一个 10 亿参数的 LLM 中的普通 MHA 替换为 Infini-attention,并继续对长度为 4K 的输入进行预训练。模型在进行 1M 口令(passkey)检索任务 fine-tune 之前,以批量大小为 64 进行了 30K 步的训练。
passkey检索任务将一个随机数字隐藏在一段长文本中,并要求在模型输出中找回该数字。干扰文本(distraction text)的长度通过多次重复文本块来变化, 样本实例见附录B。之前的研究(Chen等人,2023a)表明,当使用相同长度为32K的输入进行微调时,8B LLaMA模型可以解决长达32K的任务,采用位置插值。我们进一步挑战,并仅在长度为5K的输入上进行微调,以测试1M长度范围的任务。
表3 表明从 32K 到 1M 不同长度的测试子集的token级准确率。对于每个测试子集,我们控制了口令(passkey)的位置,使其位于输入序列的开始、中间或结尾附近。我们报告了 zero-shot 准确率(accuracy)和 fine-tuning 准确率(accuracy)。Infini-Transformers 在使用长度为 5K 的输入进行 400 步 fine-tune 后,可以解决长达 1M 的任务。
| Zero-shot | |||||
|---|---|---|---|---|---|
| 32K | 128K | 256K | 512K | 1M | |
| Infini-Transformer (Linear) | 14/13/98 | 11/14/100 | 6/3/100 | 6/7/99 | 8/6/98 |
| Infini-Transformer (Linear + Delta) | 13/11/99 | 6/9/99 | 7/5/99 | 6/8/97 | 7/6/97 |
| FT (400 steps) | |||||
| Infini-Transformer (Linear) | 100/100/100 | 100/100/100 | 100/100/100 | 97/99/100 | 96/94/100 |
| Infini-Transformer (Linear + Delta) | 100/100/100 | 100/100/99 | 100/100/99 | 100/100/100 | 100/100/100 |
表3:当在长度为5K的输入上进行微调时,Infini-Transformers解决了带有长达1M的上下文长度的口令(passkey)任务。在长度为32K到1M的长输入中隐藏的口令在token级别上的检索准确率,这些passkey位于不同部分(开始/中间/结束)。
500K 长度的书籍摘要(BookSum)。我们进一步扩展了我们的方法,通过对 8K 输入长度进行 30K 步持续预训练,连续预训练了一个 80 亿参数的 LLM 模型。然后我们在书籍摘要任务 BookSum(Kryscinski等人,2021)上进行了微调,该任务的目标是生成整本书的摘要。
我们将输入长度设置为 32K 进行微调,并将其增加到 500K 以进行评估。我们使用生成温度temperature为 0.5 和 $top_{p} = 0.95$,并将解码步骤数量设置为 1024,以生成每本书的摘要。
表4 将我们的模型与专门用于摘要任务的编码器-解码器模型(Lewis等人,2019;Xiao等人,2021)及其基于检索的长上下文扩展(Bertsch等人,2024)进行了比较。我们的模型在 BookSum 上超越了先前的最佳结果,并通过处理整本书的文本实现了 BookSum 上的新 SOTA。
| Model | Rouge-1 | Rouge-2 | Rouge-L | Overall |
|---|---|---|---|---|
| BART | 36.4 | 7.6 | 15.3 | 16.2 |
| BART + Unlimiformer | 36.8 | 8.3 | 15.7 | 16.9 |
| PRIMERA | 38.6 | 7.2 | 15.6 | 16.3 |
| PRIMERA + Unlimiformer | 37.9 | 8.2 | 16.3 | 17.2 |
| Infini-Transformers (Linear) | 37.9 | 8.7 | 17.6 | 18.0 |
| Infini-Transformers (Linear + Delta) | 40.0 | 8.8 | 17.9 | 18.5 |
表4:500K长度的书籍摘要(BookSum)结果。BART、PRIMERA 和 Unlimiformer 的结果来自 (Bertsch等 2024)。
我们还在图4 中绘制了 BookSum 数据验证集上的整体 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)评估分数。有一个清晰的趋势显示,随着提供给书籍的输入文本越来越多,我们的 Infini-Transformers 在摘要性能指标上有所提升。

图 4:Infini-Transformer 使用更多的书籍文本作为输入获得更好的 Rouge 总体分数。
4 相关工作
压缩内存(Compressive memory)。 受生物神经元可塑性的启发(Munkhdalai等人,2017;Miconi等人,2018),压缩内存方法将参数化函数视为内存来存储和检索信息(Hinton等人,1987;Schmidhuber,1992;Ba和Hinton,2016;Munkhdalai和Yu,2019)。与Transformer KV 内存数组(Vaswani等人,2017;Wu等人,2022)不同,后者随着输入序列长度增长,压缩内存系统保持恒定数量的内存参数以提高计算效率。这些参数通过更新规则进行修改以存储信息,然后通过内存读取机制检索信息(Graves等人,2014;Sukhbaatar等人,2015;Munkhdalai等人,2017)。
压缩的输入表示可以视为过去序列片段的摘要(Rae等人,2019;Chevalier等人,2023)。沿着这个方向,更近期的工作已经利用Transformer LLM 本身来压缩输入序列,以实现高效的长上下文建模(Bulatov等人,2022;Chevalier等人,2023;Ge等人,2023;Mu等人,2024)。然而,先前的段级压缩方法,包括压缩Transformer(Rae等人,2019),仍会丢弃旧段的内存条目,以释放空间给新段,从而将上下文窗口限制为最近的段。这与我们的Infini-attention相反,后者以递归方式对固定数量的内存参数进行增量内存更新。
长上下文持续预训练(Long-context continual pre-training)。 有一系列工作在扩展点乘注意力层的基础上继续对LLM 进行训练,以处理长上下文(Xiong等人,2023;Fu等人,2024)。这些注意力扩展包括将稀疏性纳入注意力层(Chen等人,2023;Ratner等人,2022;Mohtashami等人,2024),以及操纵位置编码(Chen等人,2023;Peng等人,2023)。虽然基于位置编码的方法,如位置插值技术(Chen等人,2023),可以是数据高效的,因为它们只调整了注意力层中的位置偏差,但它们在推理方面仍然昂贵。
注意机制也容易出现注意力聚焦(attention sink)问题(Xiao等人,2023)和迷失在中间(lost-in-the-middle)问题(Liu等人,2024)。因此,它们在上下文长度超出训练中观察到的长度时往往会遇到困难。提出的Infini-attention通过启用固定的本地注意力窗口,以段级流式计算长序列,解决了这些问题。Infini-Transformers在训练32K甚至5K长度序列时,成功地推广到了100万长度的输入范围。
高效的注意力(Efficient attention)。 高效的注意力技术试图通过近似或系统级优化来改善点乘注意力的效率。不同形式的高效注意力近似已经探索了多个方向,包括基于稀疏性的(Child等人,2019;Beltagy等人,2020;Sukhbaatar等人,2021;Ding等人,2023)和线性注意力近似(Shen和Tao,2018;Katharopoulos和Fleuret,2020;Schlag等人,2021)。在这些方法中,线性注意力变种与关联内存矩阵(Schlag等人,2020;Schlag等人,2021)和元学习神经内存(Munkhdalai和Yu,2019)密切相关,其中KV 绑定(Smolensky,1990)存储在快速权重(Hinton等人,1987;Schmidhuber,1992;Ba和Hinton,2016)中,这些权重根据新的上下文信息进行修改。最近,通过利用特定硬件架构来使精确的注意力计算更加高效,提出了系统级优化技术(Dao等人,2022;Liu等人,2023)。
5 结论
有效的内存系统不仅对于理解LLM中的长上下文至关重要,而且对于推理、规划、持续适应新知识甚至学习如何学习也是至关重要的。本文介绍了将压缩内存模块紧密集成到普通点乘注意力层中;这对注意力层的微妙但关键修改使LLM能够在有界的内存和计算资源下处理无限长的上下文。我们展示了我们的方法可以自然地扩展到百万长度的输入序列范围,同时在长上下文语言建模基准测试和书籍摘要任务上胜过了基线。我们还展示了我们方法的有希望的长度泛化能力。fine-tune在长度为5K的序列上的1B模型解决了1M长度的问题(准确率)。
References
-
R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
-
J. Ba, G. E. Hinton, V. Mnih, J. Z. Leibo, and C. Ionescu. Using fast weights to attend to the recent past. Advances in neural information processing systems, 29, 2016.
-
D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
-
I. Beltagy, M. E. Peters, and A. Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
-
A. Bertsch, U. Alon, G. Neubig, and M. Gormley. Unlimiformer: Longrange transformers with unlimited length input. Advances in Neural Information Processing Systems, 36, 2024.
-
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
-
A. Bulatov, Y. Kuratov, and M. Burtsev. Recurrent memory transformer. Advances in Neural Information Processing Systems, 35:11079–11091, 2022.
-
S. Chen, S. Wong, L. Chen, and Y. Tian. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023a.
-
Y. Chen, S. Qian, H. Tang, X. Lai, Z. Liu, S. Han, and J. Jia. Longlora: Efficient fine-tuning of long-context large language models. arXiv preprint arXiv:2309.12307, 2023b.
-
J. Cheng, L. Dong, and M. Lapata. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733, 2016.
-
A. Chevalier, A. Wettig, A. Ajith, and D. Chen. Adapting language models to compress contexts. arXiv preprint arXiv:2305.14788, 2023.
-
R. Child, S. Gray, A. Radford, and I. Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
-
D. Clevert, T. Unterthiner, and S. Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289, 2015.
-
Z. Dai, Z. Yang, Y. Yang, J. Carbonell, Q. V. Le, and R. Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
-
T. Dao, D. Fu, S. Ermon, A. Rudra, and C. R´e. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
-
J. Ding, S. Ma, L. Dong, X. Zhang, S. Huang, W. Wang, N. Zheng, and F. Wei. Longnet: Scaling transformers to 1,000,000,000 tokens. arXiv preprint arXiv:2307.02486, 2023.
-
Y. Fu, R. Panda, X. Niu, X. Yue, H. Hajishirzi, Y. Kim, and H. Peng. Data engineering for scaling language models to 128k context. arXiv preprint arXiv:2402.10171, 2024.
-
T. Ge, J. Hu, X. Wang, S.-Q. Chen, and F. Wei. In-context autoencoder for context compression in a large language model. arXiv preprint arXiv:2307.06945, 2023.
-
A. Graves, G. Wayne, and I. Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014.
-
D. Groeneveld, I. Beltagy, P. Walsh, A. Bhagia, R. Kinney, O. Tafjord, A. H. Jha, H. Ivison, I. Magnusson, Y. Wang, et al. Olmo: Accelerating the science of language models. arXiv preprint arXiv:2402.00838, 2024.
-
D. O. Hebb. The organization of behavior: A neuropsychological theory. Psychology press, 2005.
-
G. E. Hinton and D. C. Plaut. Using fast weights to deblur old memories. In Proceedings of the ninth annual conference of the Cognitive Science Society, pp. 177–186, 1987.
-
J. J. Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554–2558, 1982.
-
P. Kanerva. Sparse distributed memory. MIT press, 1988.
-
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pp. 5156–5165. PMLR, 2020.
-
A. Kazemnejad, I. Padhi, K. Natesan Ramamurthy, P. Das, and S. Reddy. The impact of positional encoding on length generalization in transformers. Advances in Neural Information Processing Systems, 36, 2024.
-
W. Kry´sci´nski, N. Rajani, D. Agarwal, C. Xiong, and D. Radev. Booksum: A collection of datasets for long-form narrative summarization. arXiv preprint arXiv:2105.08209, 2021.
-
M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
-
H. Liu, M. Zaharia, and P. Abbeel. Ring attention with blockwise transformers for near-infinite context. arXiv preprint arXiv:2310.01889, 2023.
-
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024.
-
T. Miconi, K. Stanley, and J. Clune. Differentiable plasticity: training plastic neural networks with backpropagation. In International Conference on Machine Learning, pp. 3559–3568. PMLR, 2018.
-
A. Mohtashami and M. Jaggi. Random-access infinite context length for transformers. Advances in Neural Information Processing Systems, 36, 2024.
-
J. Mu, X. Li, and N. Goodman. Learning to compress prompts with gist tokens. Advances in Neural Information Processing Systems, 36, 2024.
-
T. Munkhdalai and H. Yu. Meta networks. In International conference on machine learning, pp. 2554–2563. PMLR, 2017a.
-
T. Munkhdalai and H. Yu. Neural semantic encoders. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 1, pp. 397. NIH Public Access, 2017b.
-
T. Munkhdalai, J. P. Lalor, and H. Yu. Citation analysis with neural attention models. In Proceedings of the Seventh International Workshop on Health Text Mining and Information Analysis, pp. 69–77, 2016.
-
T. Munkhdalai, A. Sordoni, T. Wang, and A. Trischler. Metalearned neural memory. Advances in Neural Information Processing Systems, 32, 2019.
-
B. Peng, J. Quesnelle, H. Fan, and E. Shippole. Yarn: Efficient context window extension of large language models. arXiv preprint arXiv:2309.00071, 2023.
-
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean. Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems, 5, 2023.
-
O. Press, N. A Smith, and M. Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409, 2021.
-
J. W Rae, A. Potapenko, S. M Jayakumar, and T. P Lillicrap. Compressive transformers for long-range sequence modelling. arXiv preprint arXiv:1911.05507, 2019.
-
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
-
N. Ratner, Y. Levine, Y. Belinkov, O. Ram, O. Abend, E. Karpas, A. Shashua, K. Leyton-Brown, and Y. Shoham. Parallel context windows improve in-context learning of large language models. arXiv preprint arXiv:2212.10947, 2022.
-
I. Schlag, P. Smolensky, R. Fernandez, N. Jojic, J. Schmidhuber, and J. Gao. Enhancing the transformer with explicit relational encoding for math problem solving. arXiv preprint arXiv:1910.06611, 2019.
-
I. Schlag, T. Munkhdalai, and J. Schmidhuber. Learning associative inference using fast weight memory. arXiv preprint arXiv:2011.07831, 2020.
-
I. Schlag, K. Irie, and J. Schmidhuber. Linear transformers are secretly fast weight programmers. In International Conference on Machine Learning, pp. 9355–9366. PMLR, 2021.
-
J. Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks. Neural Computation, 4(1):131–139, 1992.
-
N. Shazeer and M. Stern. Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning, pp. 4596–4604. PMLR, 2018.
-
Z. Shen, M. Zhang, H. Zhao, S. Yi, and H. Li. Efficient attention: Attention with linear complexities. arXiv preprint arXiv:1812.01243, 2018.
-
P. Smolensky. Tensor product variable binding and the representation of symbolic structures in connectionist systems. Artificial intelligence, 46(1-2):159–216, 1990.
-
S. Sukhbaatar, J. Weston, R. Fergus, et al. End-to-end memory networks. Advances in neural information processing systems, 28, 2015.
-
S. Sukhbaatar, D. Ju, S. Poff, S. Roller, A. Szlam, J. Weston, and A. Fan. Not all memories are created equal: Learning to forget by expiring. In International Conference on Machine Learning, pp. 9902–9912. PMLR, 2021.
-
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
-
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
-
Y. Wu, M. N Rabe, D. Hutchins, and C. Szegedy. Memorizing transformers. arXiv preprint arXiv:2203.08913, 2022.
-
G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023.
-
W. Xiao, I. Beltagy, G. Carenini, and A. Cohan. Primera: Pyramidbased masked sentence pre-training for multi-document summarization. arXiv preprint arXiv:2110.08499, 2021.
-
W. Xiong, J. Liu, I. Molybog, H. Zhang, P. Bhargava, R. Hou, L. Martin, R. Rungta, K. Sankararaman, B. Oguz, et al. Effective long-context scaling of foundation models. arXiv preprint arXiv:2309.16039, 2023.
附录
A 额外的训练细节
对于长上下文语言建模任务,我们将学习率设置为0.01,通过对0.003、0.005、0.01和0.03的值进行小范围搜索。我们使用Adafactor优化器(Shazeer和Stern,2018),其中包括线性预热1000步,然后是余弦衰减(cosine decay)。我们在每个段之后应用梯度检查点以节省内存。批量大小设置为64。对于LLM实验,我们在持续预训练和任务微调期间将学习率设置为0.0001。
B 口令(passkey)检索任务
下面是口令(passkey)任务的输入格式。
There is an important info hidden inside a lot of irrelevant text. Find it and memorize them. I
will quiz you about the important information there. The grass is green. The sky is blue. The sun
is yellow. Here we go. There and back again. (repeat x times) The pass key is 9054. Remember
it. 9054 is the pass key. The grass is green. The sky is blue. The sun is yellow. Here we go.
There and ack again. (repeat y times) What is the pass key? The pass key is
在许多无关文本中隐藏了重要信息。找到它并记住它们。我将在那里询问你关于重要信息。草是绿色的。天空是蓝色的。太阳是黄色的。我们开始吧。再来一次。 (重复 x 次) 口令是 9054。记住它。9054 就是口令。草是绿色的。天空是蓝色的。太阳是黄色的。我们开始吧。再来一次。 (重复 y 次) 口令是什么?口令是