介绍
平常想到不浪费资源的方法,是对资源进行复用,减少资源消耗和浪费(小时候大人经常在吃饭时说的那句话);在计算机工程领域,存在大量消耗资源的场景,多路复用和池化是最常用的性能优化手段;多路复用存在系统调用,由系统内核层面去支持优化(I/O多路复用select/poll/epoll/kqueue),而池化可以应用用户使用层面来优化;池化(pool)是一种资源复用优化技术,减少资源回收处理,提高资源利用率,资源最好是固定大小,如果在复用资源过程中,资源在逐渐增大,一直复用,也会导致资源消耗过多,到了一定大小之后,通过系统释放掉;在程序启动的时候提前申请加载好资源放到池子中,运行时根据不同的调度管理资源策略从池子中获取准备好的资源,或者运行时新建资源放入池子中,用户程序中进行自定义处理操作,操作完之后将资源重新放入池子中复用,有些资源可以动态扩缩; 资源主要是程序运行时对象,当然这些操作资源实际都是分配在虚拟内存空间的内核空间和用户空间中,比如,进程(process PCB 内核态)、线程(thread TCB 内核态)、协程(coroutine 用户态协作式调度,尽量减少内核调度)为载体的工作任务(work task 在用户态分配栈空间);内存对象(heap object),长链接(tcp connect) 等;主要对这些资源对象进行池化技术进行介绍,了解池化对应场景。
工作任务池(worker pool)
程序中的工作任务是一些运行逻辑,通过进程,线程,或者协程为载体获取系统资源来运行;如果运行的资源对象特别多,这些资源对象在内存中分配空间,这就导致资源消耗过多,甚至可能导致OOM,同时处理任务完成之后,这些资源需要回收,也会消耗大量的cpu时间;所以在这些高耗进程/线程,或者协程资源的工作任务场景下(比如大量的请求任务),需要用池化技术进行复用管理,提高利用率,减少请求耗时;对此分别介绍进程池,线程池,协程池,以及开源组件服务中的实现。
进程池(process pool)
早期的操作系统是以进程作为资源分配和调度的基本单位,比如早期linux2.4以及之前的版本,进程是程序的基本执行实体;在面向线程设计的系统(如当代多数操作系统、Linux 2.6及更新的版本)中,进程本身不是基本执行单位,而是线程的容器,将资源分配和调度运行进行了分离设计;引入线程后,进程中可以有多个线程,并且共享线程资源;这里介绍进程池,一个进程中只有一个线程作为调度运行单位;在使用PHP语言进行web服务端开发的时候,常规操作用LAMP/LNMP组合,其中使用Apache/Nginx作为web服务器将请求路由到对应后端服务模块处理,然后将处理的响应结果返回;后端服务模块通过实现通用网关接口协议(CGI)应用(app)进程来处理请求, 如果仅仅是单个请求处理从路由模块转发的请求,吞吐量是很低的(一个请求一个进程的方式(fork-and-exec模式),实现简单,甚至可以用shell脚本来作为CGI进程处理,早期90年之前互联网用户不多);随着互联网的发展,fork-and-exec模式,进程创建和消除开销变大,成了诟病,FastCGI接口协议在90年代中期提出来,FastCGI服务器使用持久进程来处理一系列请求,及每个单独的 FastCGI 进程可以在其生命周期内处理许多请求,从而避免每个请求进程创建和终止的开销(另外还有SCGI,WSGI协议,都是定义通用的接口协议,将web服务器和应用服务器进行解耦,比如apache/nginx都有对应的协议模块和应用服务器php-fpm/uWSGI(python)相关接口协议进程进行交互,编写语言大多是解释性语言,进程运行时动态加载解释执行)。
php-fpm worker process pool
php解释性语言作为后端服务模块的开发语言,支持FastCGI,并且对支持FastCGI接口协议的进程进行管理,通过SAPI(Server Application Programme Interface)模块中的FPM(FastCGI Process Manager)实现;在初始启动php-fpm时,通过主进程监听不同服务端口,不同服务端口初始对应的FastCGI工作进程池;运行时,主进程(父进程)和工作进程(子进程)通过双向信号管道(pipe)进行通信,实现主进程对工作进程的控制管理,以及工作进程通过标准输出管道(stdout pipe)和标准错误管道(stderr pipe),将结果和错误返回给主进程;主进程和工作进程通过共享内存的方式(内部记分板结构scoreboard),实现工作进程运行时的监控(工作进程状态), 主进程会定时轮训检查工作进程数目,根据进程池管理策略来处理是否扩缩容,检查工作进程处理请求是否超时,整体流程如下图:
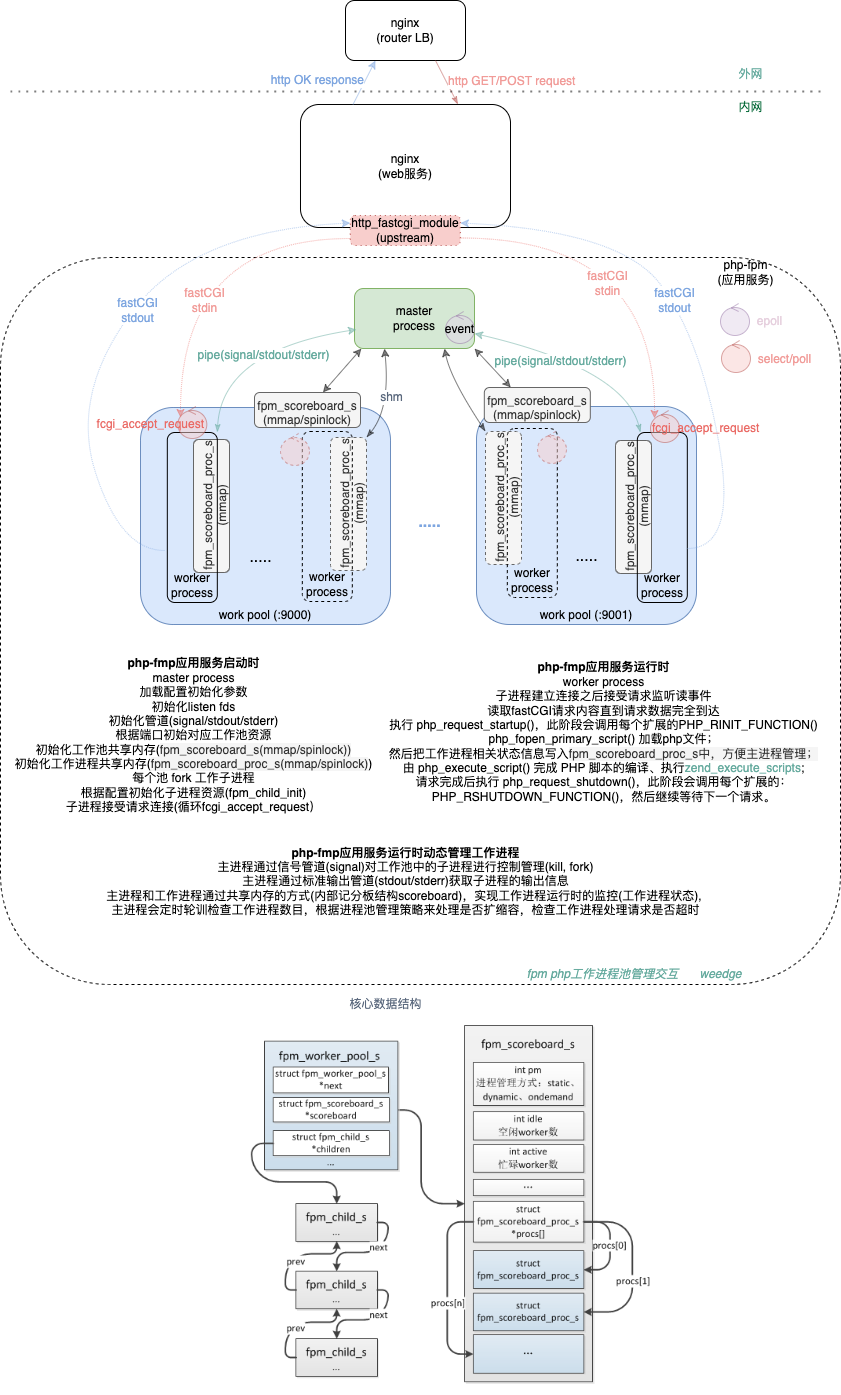
具体代码见php-fpm;php语言是线程安全的,使用 TSRM 机制分配和使用变量时会有额外的损耗,所以一般不需要多线程的 PHP 环境;而且工作进程处理请求时加载php脚本解析成opcode, 然后通过ZendVM解释器调用opcode对应的机器指令,最终完成php脚本的运行,由于每次处理请求都需要解析成opcode,会有性能损耗,所以引入opcache来缓存解析后的opcode;php-fpm的运行机制是采用多进程方式来处理请求,每个woker进程处理请求时所占内存大小在10M+,可以通过ps aux | grep php | grep -v grep | grep -v master | awk '{sum+=$6; cn+=1} END {print sum/cn}'获取worker进程消耗内存平均值,所以fpm引入工作进程池来防止过度消耗内存,而且可以服用工作进程来处理请求,内存资源紧的场景池中开启动态扩缩worker进程,反之采用静态方式池中一次初始pm.max_children 这么多worker进程,减少扩缩管理开销。
php多进程(进程单个线程)编程相对多线程(进程多个线程)编程要简单些,多线程需要考虑共享所在进程资源同步的问题,处于安全隔离考虑,进程多线程中如果某个线程出错,整个进程就挂了,而多进程资源相互隔离,如果一个进程挂了,不影响其他进程处理任务;而且解释语言相对c/c++编译成机器码执行语言开发效率要高很多,运行时加载,无需重启服务(当然c/c++编译型语言也支持动态库加载至内存提供相关接口调用,进行热加载而无需重启服务,但是不可能每次新开发一个功能都以*.so动态库的形式提供吧,所以需求更新迭代快的场景,像游戏领域的服务器,网关服务器,甚至大数据任务算子,大多都是通过引入解释型脚本语言(lua/js/perl/python/php)编写业务逻辑,进行热加载);
但是多进程毕竟比多线程要消耗更多的系统资源;而且如果存在多进程单线程的cpu切换,是从一个进程到另一个进程,而单进程多线程的cpu切换则只在一个进程内,每个进程/线程都有自己的上下文堆栈保存,进程间的cpu切换消耗更大一些;多线程上下文的切换涉及程序计数器、堆栈指针和程序状态字等一系列的寄存器置换、程序堆栈重置甚至是 CPU 高速缓存、TLB 快表的汰换;进程间的上线文切换还涉及整个进程地址空间。
线程池(thread pool)
线程是操作系统调度运行的最小单元,随着计算机cpu核数的增加,多线程技术可以充分利用多个cpu核进行并行处理,提高吞吐;对于在单cpu单核的计算机上,使用多线程技术,也可以把进程中负责I/O处理、人机交互而常被阻塞的部分,与密集计算的部分分开来执行,编写专门的workhorse线程执行密集计算,虽然多任务比不上多核,但因为具备多线程的能力,从而提高了程序的执行效率。而多线程的频繁建立和销毁,以及多线程上下文的切换,会导致整体执行的延迟,对于高性能的服务组件,针对io密集型场景,引入线程池来进行优化;而业务场景,为了提高业务的接口吞吐量,也引入了线程池进行优化;
nginx thread pool
nginx是多工作进程(cpu核数)+事件模型(如果是IO密集型 worker进程数在1.5-2倍cpu核数),通过工作进程单线程的事件模型(比喻成grandmaster😄)能够很快处理用户的请求(epoll事件机制),但是为了解决重阻塞型IO密集型的工作任务问题,nginx 1.7.12引入了thread pool 线程池技术,主要是针对linux系统,解决不支持异步IO的场景(FreeBSD系统的异步IO支持使用内存做为文件缓存);
比如产生磁盘io的系统调用read(),sendfile(),aio_write()(Linux上的在编写一些临时文件,在nginx1.9.13加入commit 348f705)这些阻塞操作场景,工作进程处理这些操作的时候,将其放入线程池中来处理,常见的直播/点播回放场景中,会有拉流操作,从最近CDN服务节点上获取视频流进行播放;像视频流文件,或者其他大文件,这些请求资源是没法放入系统内存页面缓存中,导致事件模型被文件操作卡住,没法正常的响应链接,引入 thread pool 来缓解这个问题;流程如下:
工作进程中的主线程决定要发起文件系统操作时,将会建立一个特殊的任务,并将该任务丢到任务队列中;而线程池中的空闲线程会不断的执行该队列的文件任务,而后将执行好的结果返回,主线程监听到通知事件就绪调用回调函数处理结果,继续后续操作。经过这个优化,主线程不会再被阻塞在系统调用上(多分出了通知事件,不影响读写事件),如图:
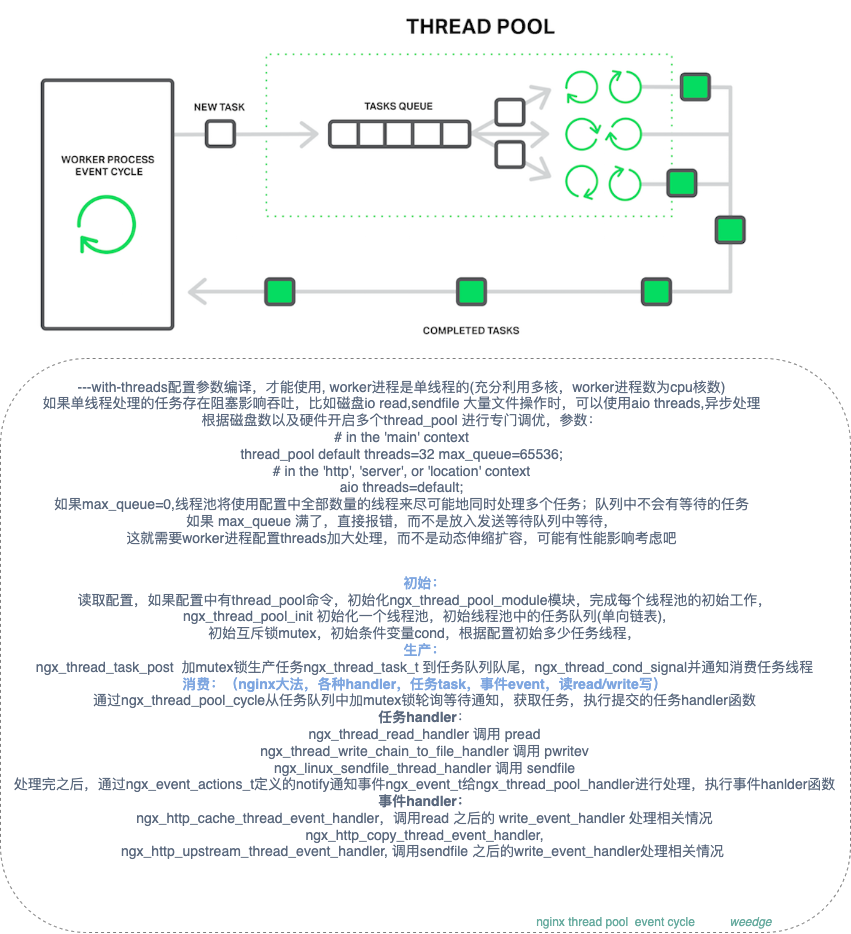
thread pool整体实现代码见thread pool commit 305fc02 , epoll notify mechanism, kqueue notify mechanism;最近有个commit 83e92a2 解决http2 等待 sendfile 完成 请求hang住的情况,就是利用线程池的异步方式(aio)来处理的(ps: nginx 作者也)。
redis thread pool
redis处理命令核心逻辑是单进程单线程模式,redis关注的是网络IO,以及内存操作,如果是单进程多线程处理必然会有同一个内存结构会有多个线程处理,加锁处理,线程等待以及多线程上下文切换开销的问题,执行效率不如单线程高效;网络IO事件直接通过IO多路复用事件模型(AE)来解决, 而且逻辑简单可维护;
- 为了提高处理性能,Redis v4.0 将磁盘io和内存释放free工作采用几个线程异步处理bio(3个);
fsync内存异步持久落盘操作和close异步关闭文件操作;
由于内存中大ke同步删除会耗时高从而阻塞核心逻辑,所以将这些内存释放采用lazyfree机制优化异步化处理,包括两类:一类是主动释放unlink flushall async ;一类是被动释放, 分为4种场景,按需求场景进行打开优化(默认是关闭的):
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
slave-lazy-flush no
lazyfree-lazy-eviction:针对redis内存使用达到maxmeory,并设置有淘汰策略时;在被动淘汰键时,是否采用lazy free机制; 具体流程见redis 近似lru算法;
lazyfree-lazy-expire:针对设置有TTL的键,达到过期后,被redis清理删除时是否采用lazy free机制;可开启
lazyfree-lazy-server-del:针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作,比如rename操作,如果key存在会先删除这个key/value, 如果是大key场景会阻塞;可开启
slave-lazy-flush:针对slave进行全量数据同步,slave在加载master的RDB文件前,会运行flushall来清理自己的数据场景,开启可减少全量同步耗时,从而减少主库因输出缓冲区爆涨引起的内存使用增长;可开启
还有一个配置 lazyfree-lazy-user-del no, 针对老用户/代码使用del主动删除是否异步处理,开启和unlink一样;
- 为了提高处理IO能力,Redis v6.0 正式在网络模型中实现 I/O 多线程,流程如下:
客户端和主线程建立连接,主线程将请求封装成client结构放入LIFO读入队列(clients_pending_read),主线程然后把LIFO读入队列中的client数据RR均匀分配给主线程和I/O多线程的本地队列(io_threads_list[id]);
主线程和I/O多线程解析命令,写入查询缓存区(querybuf);
主线程忙轮训等待I/O多线程全部解析处理完之后,遍历LIFO读入队列(clients_pending_read)中的client, 处理执行命令核心逻辑(processCommand),注意这里并不是I/O多线程来处理;主线程处理完命令后,将响应数据写入client写出缓存区(buf/reply),然后把client放入LIFO 写出队列(clients_pending_write),同样主线程然后把LIFO写出队列(clients_pending_write)中的client数据RR均匀分配给主线程和I/O多线程的本地队列(io_threads_list[id]);
主线程和I/O多线程回写响应数据给客户端;
主线程忙轮训等待I/O多线程全部回写响应数据给客户端 处理完之后,最后在遍历LIFO写出队列(clients_pending_write),检查是否还有 client 的写出缓冲区(buf/reply)中有残留数据,如果有,为 client 注册一个命令回复器 sendReplyToClient,等待client可写之后在事件循环中继续回写残余的响应数据。
处理流程和以前的单线程reactor模式差不多,主要区别是对读写IO优化(异步多线程处理); 读入请求命令读取解析和写出响应数据给客户端,增加了I/O多线程来处理,以前的主线程处理的核心逻辑没有变,增加了和I/O多线程交互的读写LIFO队列(clients_pending_read / clients_pending_write),有点像扇入扇出模式;尽量保持 less is more 原则;
而且redis v6.0为了高性能,网络IO多线程场景,和nginx一样也对多核CPU NUMA架构进行了亲和性处理(见setcpuaffinity.c中逻辑,commit 1a0deab2),充分利用CPU本地缓存,并行处理;另外redis v6.0还有一些性能优化骚操作,无锁化处理,看代码时会发现用到了mutex lock,通过 pthread_mutex_lock 给 io_threads_mutex[i] (0<=i<128) 上锁,其实目的是主线程用来通知I/O线程使用的,最终还是通过io_threads_pending[i] 原子化操作(atomic_load_explicit)获取判读是否等待;每个处理I/O线程都有自己的本地队列io_threads_list[i] 用于处理封装的client结构,I/O线程之间互不干涉;而且主线程和I/O子线程处理本地队列 io_threads_list[i] 以及io_threads_op 通过控制主线程和 I/O 线程交错访问来规避共享数据竞争(data race)问题。
THREADED I/O 核心操作变量如下:
/* ==========================================================================
* Threaded I/O
* ========================================================================== */
#define IO_THREADS_MAX_NUM 128
#define IO_THREADS_OP_READ 0
#define IO_THREADS_OP_WRITE 1
pthread_t io_threads[IO_THREADS_MAX_NUM];
pthread_mutex_t io_threads_mutex[IO_THREADS_MAX_NUM];
redisAtomic unsigned long io_threads_pending[IO_THREADS_MAX_NUM];
int io_threads_op; /* IO_THREADS_OP_WRITE or IO_THREADS_OP_READ. */
/* This is the list of clients each thread will serve when threaded I/O is
* used. We spawn io_threads_num-1 threads, since one is the main thread
* itself. */
list *io_threads_list[IO_THREADS_MAX_NUM];
以上通过引入多线程来改善redis中I/O处理性能,这些优化都可以根据需求场景进行配置,也有具体说明 见: redis.conf (LAZY FREEING, THREADED I/O);功能按需配置,可配置功能说明 配置文档原则 (开源软件配置文件一般都会有详细说明可了解);
java thread pool
java多线程编程,也有相关的线程池(ThreadPoolExecutor,子类ScheduledThreadPoolExecutor - 利用延迟工作队列(最小堆)实现定时任务线程池)提供使用;使用ThreadPoolExecutor可以满足两种场景:
- 并行执行子任务,提高响应速度。这种情况下,应该使用同步队列,没有什么任务应该被缓存下来,而是应该立即执行;
- 并行执行大批次任务,提升吞吐量。这种情况下,应该使用有界队列,使用队列去缓冲大批量的任务,队列容量必须声明,防止任务无限制堆积;

ThreadPoolExecutor具体的使用介绍可以参考美团的这片文章:Java线程池实现原理及其在美团业务中的实践,引用 ThreadPoolExecutor 运行流程如上图;文中有有实际的案例和参数配置解决方案,可以借鉴;在使用java线程池对接口吞吐量进行优化时,如果参数使用不当,线程池最大线程数过小,可能导致接口服务降级;消费线程过小任务队列过长,积压任务,可能导致请求超时的情况;针对这些场景,提出解决方案:增加线程池监控,通过配置中心,手动来调整java线程池参数, 进行动态配置化管理,这个思路其实也是服务基础稳定性的常用思路,做好监控报警,配置化及时人工响应。(美团的复盘机制值得学习)
thread pool 小结
引入线程池其实本质上还是对多线程的有效管理,充分利用多核进行并行处理,减少线程间的上下文切换开销(上下文切换时间在~1000 到 ~1500 纳秒,(平均)每核心每纳秒 12 条指令,上下文切换可能会花费大约 12k 到大约 18k 条指令的延迟);以上实现的线程池本质上都是通过多线程异步优化IO任务,通过线程池来管理线程,通过参数进行调优,充分利用多核cpu硬件资源,并行处理,吞吐最大化(ps: redis和nginx的源码值得一撸)。 但是用户应用层使用线程池需要对线程数目进行调整,那可否从用户应用层面来封装一层进行调度管理呢? 答案是有的,像GO语言,现在的内部运行时runtime 通过G-P-M调度模型来有效管理,Go 语言的调度模型通过使用与 CPU 数量相等的线程减少线程频繁切换的内存开销(如果是在容器环境中,可以通过uber-go/automaxprocs 运行时自动适配分配给容器cpu核数),同时在每一个线程上执行额外开销更低的 Goroutine 协程来降低操作系统和硬件的负载,用户应用层面不需要考虑多线程编程的细节,重点关注Goroutine 协程的使用优化,了解G-P-M模型,运行时调度机制。(享受一波语言,工具福利时,注意系统阻塞调用时的线程泄露,以及异步阻塞时的协程泄漏, race检查,性能测试,pprof/trace分析,逃逸分析,GC等)
协程池(coroutine pool)
协程是运行在用户态的轻量线程,可以认为是用户应用层面的线程, 比线程分配的虚拟内存栈空间要小;创建一个线程所占虚拟内存栈空间大小,在linux下通过pmap +pid 查看stack大小, 在macOS下通过vmmap -interleaved+pid 查看stack大小,大小由ulimit -s 控制,线程栈空间一般在8M~10M左右,如果使用不当会栈溢出;而协程分配空间是由实现协程语言来决定,像GO实现的goroutine协程初始创建栈空间大小是2k(go 1.4+ 采用连续堆栈策略,以前是分段栈策略),最大限制的默认值在64位系统上是1GB(不同的架构最大数会不同);编译期间插入检查,调用时如果满足了扩容条件(根据被调用函数栈帧的大小来判断是否需要扩容,通过 stackguard0 来判断是否要进行栈增长),扩容两倍空间,如果协程所使用的栈空间小于1/4时,缩容成一半空间;(具体细节见:栈空间管理 推送场景: 聊一聊goroutine stack)
尽管goroutine协程比线程分配栈空间小,但是 大量的 goroutine 还是很耗资源的,而且大量的 goroutine 对于调度和垃圾回收的耗时还是会有影响的,因此,goroutine 并不是越多越好,所以使用协程池来优化;
GO中管理协程池的开发方案还是比较多的,大都是和线程池任务工作模型差不多,任务队列用的是GO中的runtime/channel, 池化管理用的是GO中的sync.Pool, 比如fasthttp workerpool 针对自身场景的多个连接通道池化复用 -> panjf2000/ants 通用化了多个任务通道池化复用 -> bytedance/gopool 任务tasker和工作worker池化复用;相对线程池thread pool的实现要简单些,因为底层GO runtime的调度器以及sync库已经做了大部分的优化(无锁或最小化锁粒度)。Pool:性能提升大杀器 中介绍了GO中sync.Pool的实现,以及协程池的三方开源方案实现;
这里介绍一个实现的 workerpool 通过channel 存放任务,多个 Worker 共享同一个任务 Channel,通过多个协程来消费池中的任务执行,协程根据提交的任务数动态扩缩协程;任务可以定义输入,输出,超时时间;通过channel 返回是否超时; 可用于批量任务并发执行场景,适用于大量批量耗时相对比较高的任务;在实际工作中,比如组织引擎中树中组织节点的生成,有些任务超时了,使用方可以重新放入队列中,或者出错报警等操作。 执行流程如下:
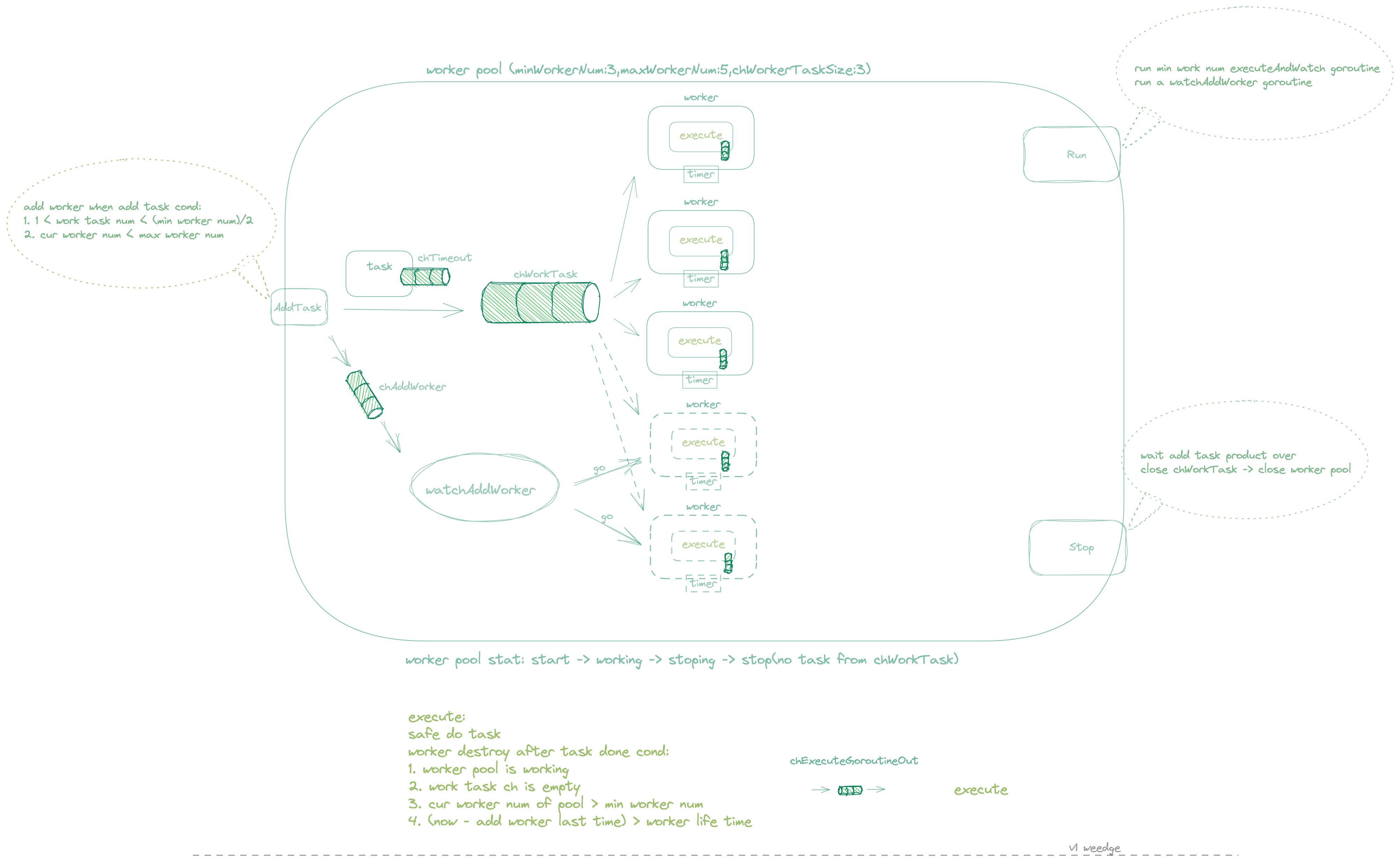
还有协程池的实现方式,主要是为了应对突发流量(场景:处理大量连接请求),如下几个:
- gammazero/workerpool 实现用到3个队列,一个用于提交任务的任务队列(buffer channel length 1,发送任务非阻塞)、一个等待队列(buf[] interface{} head,tail,为了应对突发流量设置的buff,无限制)、 一个工作队列(block channel,用阻塞chan是为了让消费的worker先启动);未使用sync.Pool;通过dispatch协程来管理工作协程, 定时(idleTimeout)检查工作队列是否有任务(idle), 以及有工作协程(workerCount>1),发送空任务(nil) 结束工作协程;这个检查是否有空闲工作协程机制比较简单,每到定时时间操作一次,回收频率可以调整,idleTimeout默认2秒;通过发送暂停任务 (Context/stopSignal) 来暂停worker工作以及整个workerpool,还有提交等待执行完成的任务,通过Pacer提交限速任务,使用方也可以提交超时任务;使用goroutine+channel+sync+context整体实现workerpool就300行左右,这个和ThreadPoolExecutor有些类似,流程如下:
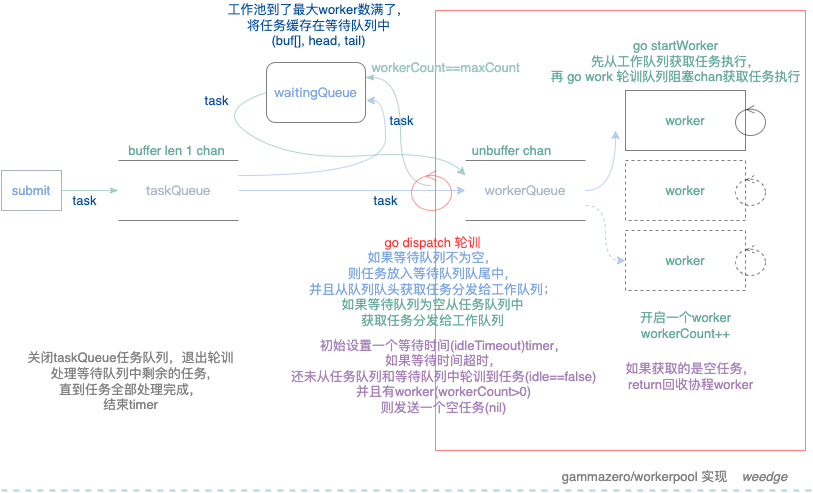
-
fasthttp workerpool 针对自身场景的多个连接通道池化复用; ->
-
panjf2000/ants 通用化了多个任务通道池化复用(一次任务G用完生命周期还可以复用(按空闲时间长短回收), 可用worker放入自定义的池中(stack/loopQueue) , 如果工作池没有可用worker, 根据配置是否等待,等待则等有可用worker时通过条件变量(Cond)唤醒,使用自旋锁; 定时从自定义的工作池中获取空闲时间大于配置阈值的worker进行回收)
-
bytedance/gopool 任务task和工作worker池化复用(一次任务G用完生命周期可以复用,复用栈空间,尽量减少协程调度消耗) -> (尽量无锁化队列);针对优化栈扩张场景使用(RPC 服务常见问题,比如:推送场景: 聊一聊goroutine stack)
Tips: 1有等待全部任务结束;2,3,4 这些协程池没有等待,因为使用场景大多是多个协程处理完任务之后无需等待结果处理,可以自己的任务中定义;1,2,3都使用了channel, 1是在消费侧启动goroutine,2,3是在生产侧启动goroutine,通过channel单向通信task;4 未使用channel来通信,直接通过FIFO单向task链表,上锁头出尾入task,在生产侧启动goroutine;
满足协程复用的前提下,在生产侧task,队列,消费侧worker 上尽量优化结构,结合调度特性。
以上的workerpool 都有缓冲队列,如果服务进程重启,需要平滑停止服务,就是在收到TERM信号时,需要调用workerpool提供的Wait接口, 对于未等待的协程池,使用sync.WaitGroup来等待剩余的任务执行完成,这种任务如果是用户请求任务,一般都是短任务,处理时间不会很长,像Pod 中的 docker container销毁的时候都会等待一段时间才会回收掉;如果是长时间任务,比如cron job 取决于任务的重要程度,则需要落库存放任务状态,在任务提交之前通过任务表来记录,因为进程本地记录是不可行的,如果容器化部署在Pod中,每次部署的Node会不同;请根据需求场景选择合适的workerpool。
小结
线程作为cpu执行调度的最小单元,而进程作为资源分配最小单元,进程中有多个线程,共享其进程资源,作为线程的容器,相互隔离不同进程之间的线程,所以nginx/fpm 都是多进程(单线程)+reactor多路复用的方式处理网络IO请求; php-fpm 为了有效控制请求进程所占资源过多消耗内存的情况,引入工作进程池来防止过度消耗内存,而且可以复用工作进程来处理请求;nginx 为了优化系统调用时阻塞io,使用线程池来异步化处理处理阻塞io事件;redis 引入多线程来解决磁盘IO,释放内存空间,以及网络IO读写的性能问题,nginx和redis 引入多线程都需要编译配置,其中nginx和redis中的网络IO优化细节值得学习的;协程创建分配栈空间比线程更小,Golang中通过可增长栈空间,运行时runtime 通过G-P-M调度模型来将 goroutine 多路复用到线程,如果协程过多,也会影响调度以及GC标记清除效率,所以在消耗大量协程的场景下,引入协程池来复用,因为golang runtime调度模型以及channel机制,使用Go Concurrency Patterns 实现协程池方案很多,golang社区活跃,最好结合需求场景来分析。
references
- Introduction to Parallel Computing Tutorial
- nptl-design.pdf
- glibc pthread_create
- linux v2.6.38+ fork.c
- Linux 2.6.36 kernel map
- nginx-thread-pools-boost-performance-9x 翻译
- inside-nginx-how-we-designed-for-performance-scale
- AOSA-nginx
- Lazy Redis is better Redis
- How fast is Redis?
- Java线程池实现原理及其在美团业务中的实践
- Analysis of the Go runtime scheduler
- Golang操作系统调度原理
- Scheduling In Go : Part I - OS Scheduler Part II - Go Scheduler Part III - Concurrency gotraining
- Google I/O 2012 - Go Concurrency Patterns 「slide」
- Google I/O 2013 - Advanced Go Concurrency Patterns 「slide」
- Rethinking Classical Concurrency Patterns 「slide」
- Go Preemptive Scheduler Design Doc Go’s work-stealing scheduler
- 也谈Go的可移植性
- The Design of the Go Assembler A Manual for the Plan 9 assembler plan9 assembly 完全解析
- Pool:性能提升大杀器