发现一个有趣玩法,针对rust 编译检查的问题(这个在编写代码逻辑的时候经常会遇到,逻辑是OK,但是通不过rust的安全检查),可以直接发给 chatGPT (其他通过代码库进行PT的模型,或者SFT的模型), 会给出修改意见,并且可以根据它的提示继续追问怎么解决; 如果直接通过传统的搜索引擎比如google, 也很难找出好的解决方法,而且还要去筛选,去尝试这个方法,如果不是权威网站,可能还被坑。来来回回折腾,效率太低了。像最近的AI程序员 david: introducing-devin ,其实类似思路,也是通过聊天来解决问题,只不过更加的专业,归根结底还是需要专业数据去PT/SFT底层的模型,上层应用通过pipeline对应框架去整体系统调优。(不知是否满足类似这种rust场景的解决方案pipeline,直接给它代码,帮忙修改)
PS:应该多去玩玩最先进的chat类LLM(聊天过程(prompt engineering),其实就是一种反馈机制), 找到痛点,然后形成pipeline解决方案,进而推动上层应用改造,或者演变新生事物,当然冒出idea💡需要去落地又是另外一回事了(伪需求,还是真心痛点),脱离场景耍流氓~~~
这个case error: temporary value dropped while borrowed :
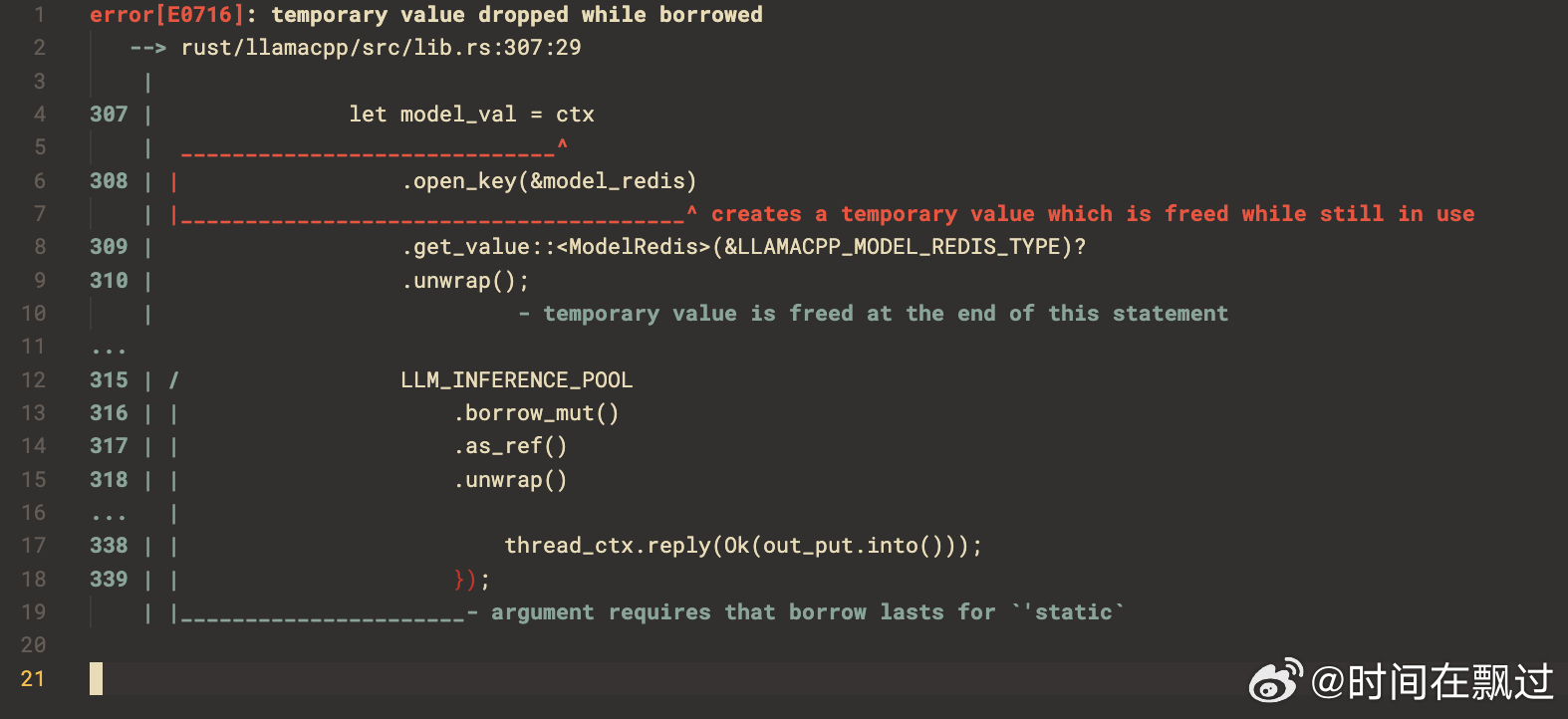
这里把错误先告知chatGPT, 待给出错误发生的原因和修改建议时,然后将错误的源码段发给chatGPT
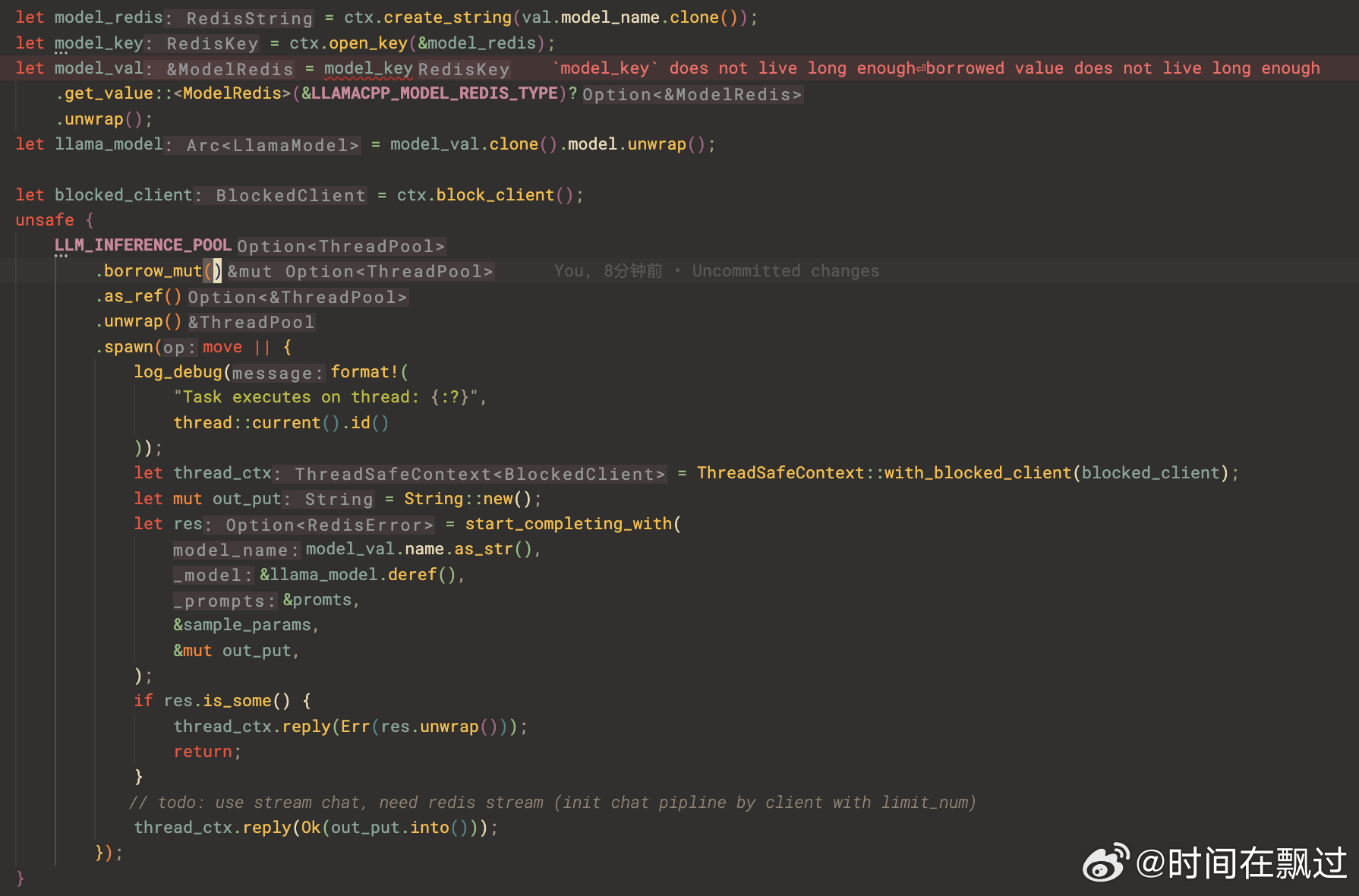
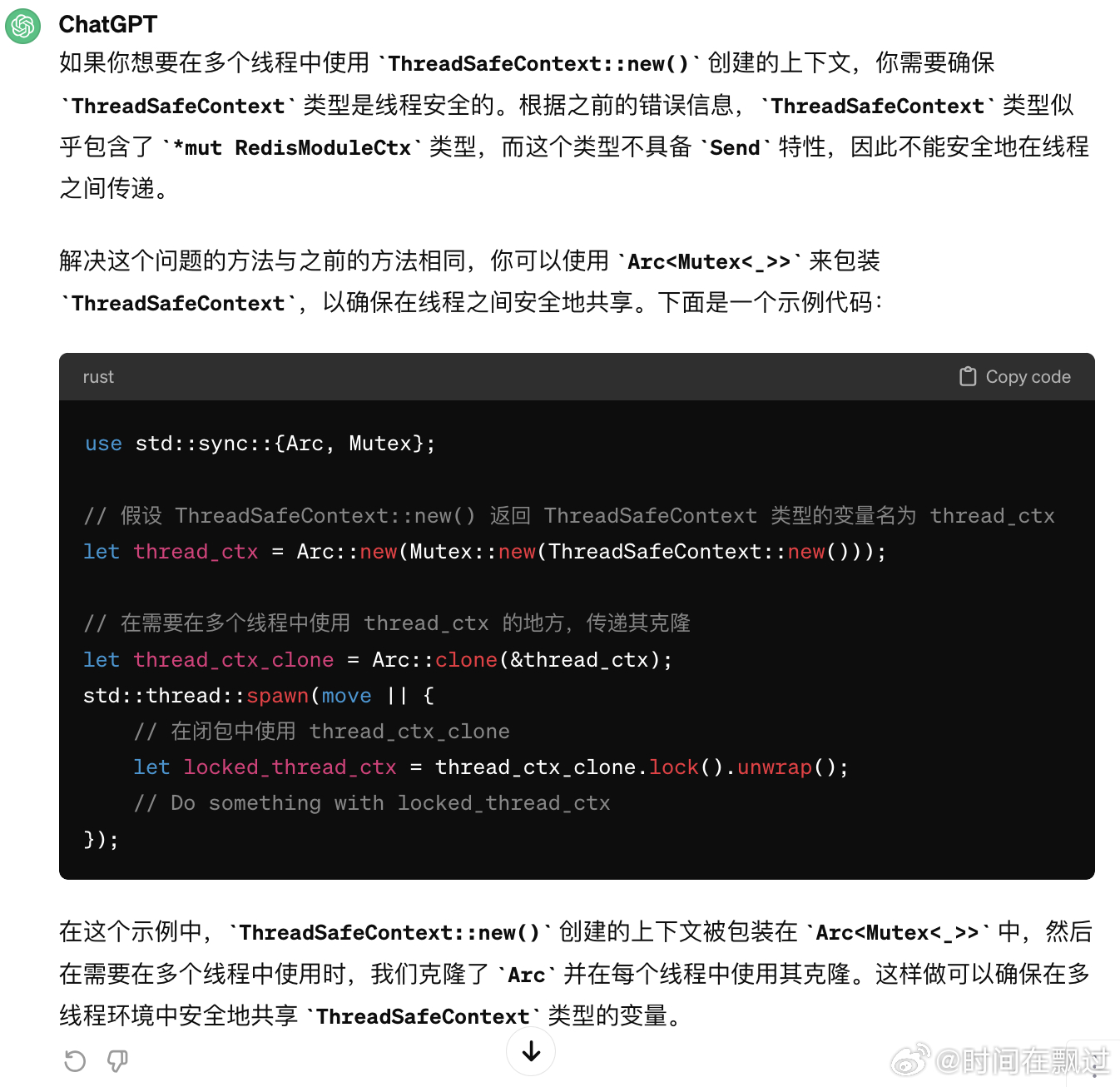
因为这里涉及多线程场景,多线程的数据竞争,rust的在编译时也会提示,常规做法是给多线程共享变量加原子引用计数Arc, 在对变量进行读写操作时,需要加互斥锁Mutex, 比如: 这里的ctx是共享的,将上下文包装在 Arc<Mutex<_>> 中,然后在需要在多个线程中使用时,我们克隆了 Arc 并在每个线程中使用其克隆,如下图chatGPT的提示。
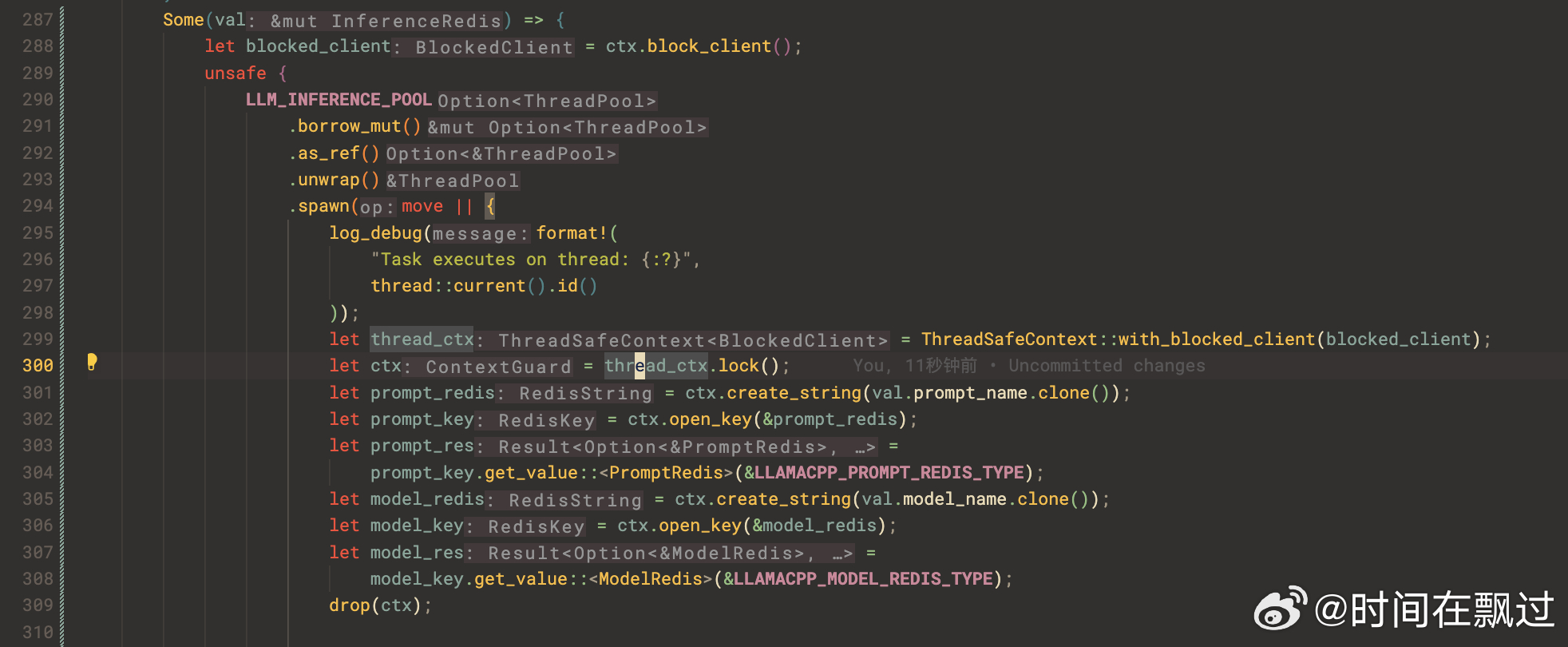
当然也有特例,这个是按照正常逻辑来解,但是也有特殊例子,比如自己封装的私有库,这个时候就需要引导LLM 网络往提示的私有路径去推理,需要私有的数据去continue PT 或者 SFT,(或者用RAG知识库的方式)。 比如:这里的ctx提供了一个线程安全的ThreadSafeContext, 对操作的互斥区域上锁,unlock的时候调用drop函数
// let thread_ctx = ThreadSafeContext::new();
let thread_ctx = ThreadSafeContext::with_blocked_client(blocked_client);
let ctx = thread_ctx.lock();
....
drop(ctx);
最终通过rust编译安全检查。而且边学边做,提高效率,而且学到了,下次遇到相同情况,直接把聊天记录找出来(或者形成一片解决该问题方案md文档),咦~~ 这里可以把聊天记录chunk建好向量索引,通过RAG pipeline来增强检索,完美学习复利闭环。
总结下: 现在大部分基于LLM的上层应用都是通过在某个场景下经历过的痛点,将这些需求整理,变成自动化的pipeline,形成应用,进而提高该场景下的工作效能,至于成本计算干了才知道。
整体聊天记录:(没有单开聊天会话,有些其他记录)
https://chat.openai.com/share/b498f8ef-97de-4db8-936b-654abc25df2b
哈哈,作为一个挨踢工程师,以前总考察基本技能是否使用google解决代码问题 和 stackoverflow 解决回答问题数作为一个指标来衡量一个合格的工程师;那现在还应该加个选项,是否会高效使用先进的LLM工具(主要是chat类)。以后就缺合理的实现方案设计了,细节问题可交个类似david程序员去帮忙解决了,但是前提条件是会问关键问题,和清晰的逻辑思路。