背景
随着前期业务迭代不断增多,会留下一些技术债务;用户不断累计增加,整体DAU,MAU,PV/UV的不断上升,为了符合根据组织结构和业务需求更加稳定健康的发展,需要对业务服务进行改造/重构;采用团队适合的语言开发,将服务进行分层,抽象底层模型,分离出不变/易变业务逻辑;业务改造和基础建设服务升级(整体系统认知的改变)
过程
整体服务分为4个阶段进行简述:
-
快速上线,需求多,迭代快,开发团队整体使用熟悉开发框架(效益:前期起步使用rd熟悉的开发脚本语言,支持需求快速迭代)
-
后面功能复用, 建设业务中台, 直播中台,互动中台的建设,中台的请求大,采用golang进行开发,(效益:整体机器资源消耗减少, 高峰期机器负载降低)
-
根据直播业务场景,抽象中台底层数据模型,(效益:减少人力,提高复用,增加整体研发效能)
-
开发语言迁移, 服务模型从多进程脚本弱类型语言切到多协程强类型语言,需要适配接口
-
需要梳理核心服务接口和非核心服务接口,
-
服务上线,迁移老接口, 需要做流量的切分,新老接口的diff , 有两种方案:
- 在业务层面加上灰度策略,通过策略配置,对不同的业务id进行异步分流,一份请求数据,2份响应数据,只返回老的响应数据,新老响应数据进行diff处理;优点:业务改造方自己把控;缺点:对业务代码有侵入,如果改造灰度策略多的话,会降低业务代码逻辑稳定性;
- 在新老服务之上加一层接口代理层,接口适配,灰度策略流量切分,新老接口diff功能 移至 接口代理层做,相当于提供一层网关服务来处理;优点: 对接口灰度进行统一管理,不会对业务代码有浸入操作;缺点:多了一层代理层,接口响应时间会有所增加,需要保证代理层的稳定性;
两种方案都可以,需要结合组织结构来考虑开发技术成本, 方案一:不需要额外的人力来支持维护代理层;方案二:需要单独的团队或者开发人员来维护代理层; 如果看整体收益的话,偏向于第二种方案,前者就是战术编程,后者就是战略编程,应该侧重战略编程。
-
课中直播是流量突发的场景,对于服务优化改造,服务压力测试必不可少:
- 接口压测,关注qps,接口响应时间,服务监控,负载等情况;
- 全链路压侧,关注tps,整体链路调用接口响应时间耗时,总响应时间耗时,各服务监控,负载等情况;并且输出测试报表;为了不污染线上数据,需要对基础存储组件 单独部署一套影子系统,服务链路上需要加上压侧标签参数;可参考:性能测试 PTS
-
保证切流过程中服务比较稳定,进行周期性引流,切流观察:
- 旁路引流diff,覆盖到业务全场景的情况,diff在可接受范围内,进行下一步 流量切流
- 为了保证服务稳定性,不出现p0,p1,p2事故,流量切换的周期一般比较长,按覆盖到的业务场景和整体服务监控情况而定,按1%、2%、10%、20%,40%,80%放量;查看客户端是否有异常以及用户的反馈工单,切流放量阶段diff还是正常进行,返回是否有问题,存放数据是否一致;没有问题,进入下一步 线上观察
- 线上观察一段时间,会以月为单位,观察阶段主要服务流量是新改造的服务,如果发现有异动,还可以切回原来的服务;如果观察阶段没有问题,可以下掉原来的服务了;
-
服务改造过程中,会有新的业务需求进来,如果是大的需求,开发周期比较长的项目,如果是紧急项目,只能在原有服务上进行开发,后续在迁移至新系统中;对于非紧急需求,可以暂缓压压,可以等新服务上线稳定之后,在使用新服务框架开发,上线部署,主要看需求中是否需要修改老接口,还是直接提供新接口就可以满足;
-
-
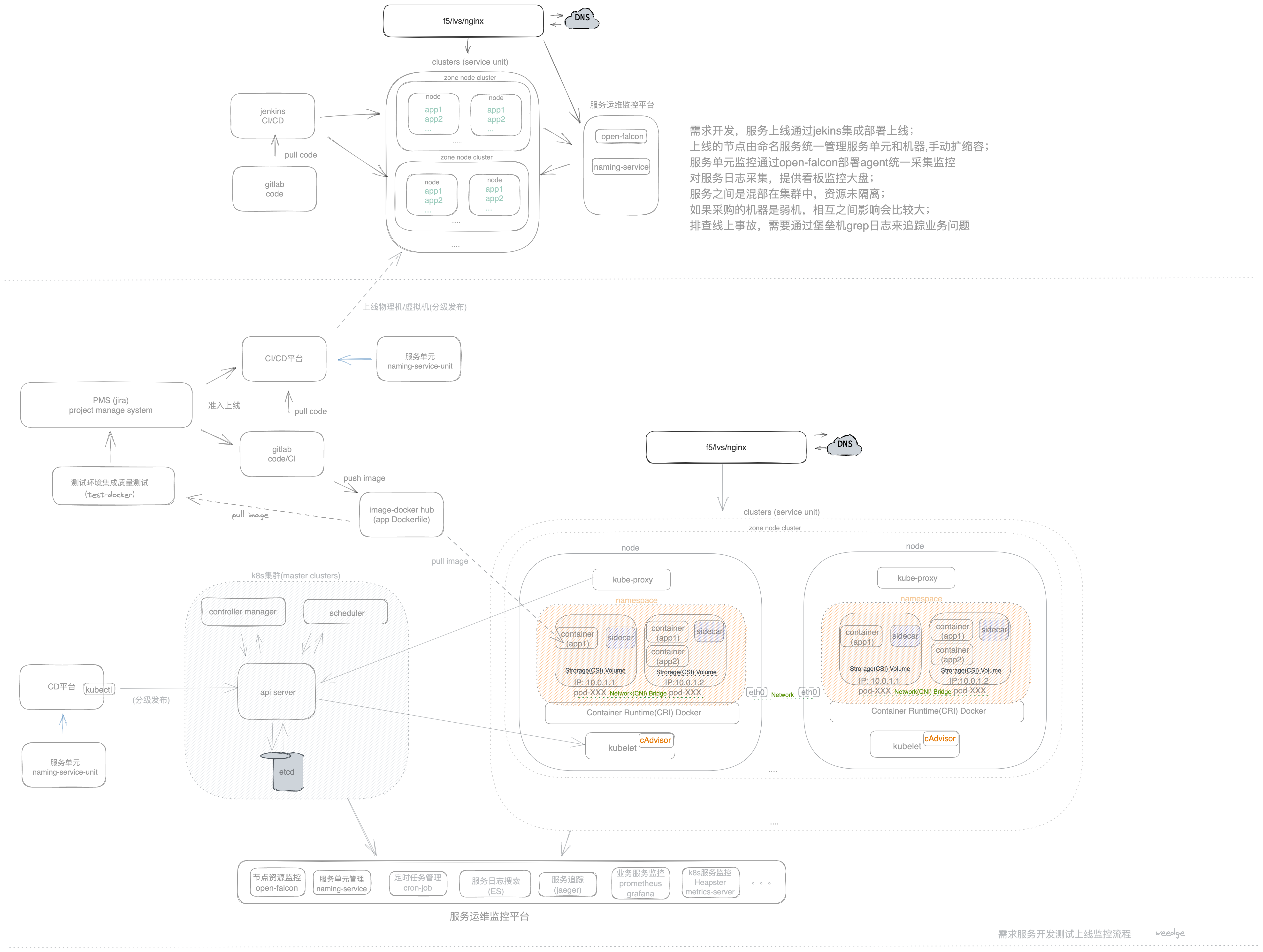
容器化改造,上云(效益:整体测试,线上环节保持一致,节约开发测试时间;线上服务治理通过K8S+Istio,进行网格化治理, 以前部署在物理机或者虚拟机上,混部的情况,资源分配和隔离不合理,迁移后,可以充分合理利用宿主物理机/虚拟机资源,隔离,弹性扩缩容,部署上线前提条件是需要保证K8S可用性)
- 对不同语言服务进行容器化改造,有不同业务部门推进(主要是项目构建打包成镜像,docker的话需要编写Dockerfile),基础的资源管理由devops提供CI(gitlab ci)/CD平台整合上线(可以部署物理机/虚拟机/部署(kubectl/istioctl)容器上云)
- 在迁移至容器云(Kubernetes 集群中的应用)的过程中,会涉及到一部分服务容器化部署上线,一部分还是部署在物理机/虚拟机上,服务之间相互访问,容器云->容器云,容器云->物理机/虚拟机, 物理机/虚拟机->容器云,需要业务梳理出服务之间的调用关系,然后对3种服务调用情况进行改造,其中可以使用sidecar模式进行流量输入输出
- 通过K8S来编排服务,会出现服务治理的问题,需要可视化,监控,追查定位问题等相关平台来整合,对应的规范和开源工具整合进来,log: 采集日志,存储日志(热/冷),查找日志;metric: 监控数据采集,监控指标,监控看板/大盘;trace: 服务请求访问链路追踪,服务调用响应时间,整体响应时间;以及k8s本身调度节点中pod资源监控
- 部署至容器云后的整体测试,接口压侧,整体链路压侧
- 上线后的切流方案
整体流程
总结
随着业务的发展,服务不断迭代改造,涉及到业务层面抽象改造,以及基础平台服务的升级;最终目的都是为了满足日益增长的需求,缩短需求发布到上线的周期,复用,减少迭代对服务整体稳定性的影响。