序言
数据落地之前,如果出现持久化存储引擎实例重启,或者服务当机重启,如何进行故障恢复(Crash Recovery)呢?数据写操作增删改,这些操作状态数据,是如何保证事务中原子性和持久性的呢? 这些问题数据大拿们提出了Algorithms for Recovery and Isolation Exploiting Semantics ,基于语义的恢复与隔离算法,现代数据库的基础理论;当前主流关系型数据在事务实现上都受到该理论的影响,其中有两种故障恢复的方法: 预写日志(write-ahead logging (WAL) ) 和shadow-page technique;shadow-page 方法简单介绍就是每次事务操作,以page为单位,写时复制的方式,分为Current和Shadow,类似主备的形式,如果commit成功,Current中的page合并到 Shadow中; 如果abort不成功丢弃Current的page; 如果Crash了,从Shadow中的page恢复,对所有未提交事务的回滚操作; 由于shadow-page技术的实现以page为单位,page内无法并发操作,commit/回滚时会有大量垃圾回收操作;本文主要介绍WAL,以及对应持久化存储引擎的实现机制介绍。
WAL
预写日志( WAL ) 是一系列技术,用于在数据库系统中提供原子性和持久性(两个ACID属性)。在将更改写入数据库之前,更改首先记录在日志中,日志必须写入稳定存储(保证任何给定写入操作的原子性,并允许编写对某些硬件和电源故障具有鲁棒性的软件)。
这样做的目的可以通过一个例子来说明。想象一下,当运行它的机器断电时,它正在执行某些操作。重新启动时,该程序可能需要知道它正在执行的操作是成功、部分成功还是失败。如果使用预写日志,程序可以检查此日志并将意外断电时应该执行的操作与实际执行的操作进行比较。在此比较的基础上,程序可以决定撤消已开始的内容、完成已开始的内容或保持原样。
在使用 WAL 的系统中,所有修改在应用之前都会写入日志。通常redo和undo信息都存储在日志中。
注意:写不一定是顺序写,一般计算机存储 非易失性的硬件结构对顺序写的性能高于随机写的性能,比如常用的磁盘HDD/SSD; 但是最近基于NVM技术(结合磁盘和内存的特性)的存储硬件PC-RAM(Phase Change Random Access Memory), STT-RAM( Spin Transfer Torque Random Access Memory), R-RAM(Resistive Random Access Memory),结合内存中随机访问,磁盘非易失性特性,随机写和顺序写没什么差别,Implications of Non-Volatile Memory as Primary Storage for Database Management Systems 这篇论文中提到Pg如果不部署内部的buffer cache,所有写直接写到NVM对应的存储硬件中,可以去掉redo日志,但是undo日志任然需要,在系统错误时复原; 一般学术方案要领先实际工程许多,真正落地在生产环境中,还是用躺过坑的成熟方案 (顺便想到现在一些k/v存储引擎考虑上云,支持云厂商的云盘,可以认为无限容量)。硬件结构决定上层软件存储引擎的设计的优化,以下都是以常用的磁盘HDD/SSD的硬件结构来介绍存储引擎实现WAL技术。
mysql Innodb存储引擎
mysql Innodb存储引擎是通过 redo、undo 日志实现 WAL,主要用于crash 恢复和回滚,满足本地事务中的持久性和原子性,来保证数据一致性;当然innodb引擎为了提高并发读性能,undo log中加入了MVCC (多版本并发控制)相关信息; 另外,mysql server层执行器会写bin log,主要是用来恢复某个时间的点数据以及主从复制数据使用,bin log文件和存储引擎无关;分别简要介绍redo, undo, bin log 文件在mysql中的作用。
redolog
为什么需要redo log?
我们都知道,事务的四大特性里面有一个是 持久性 ,具体来说就是只要事务提交成功,那么对数据库做的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态 。那么mysql是如何保证一致性的呢?最简单的做法是在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题,主要体现在两个方面:
- 因为 Innodb是以页为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了!
- 一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差!
因此 mysql设计了redolog , 具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题了(相对而言文件更小并且是顺序IO)。
redo log基本概念
redo log包括两部分:一个是内存中的日志缓冲( redo log buffer ),另一个是磁盘上的日志文件( redo log file )。 mysql 每执行一条 DML 修改写语句,操作的数据在内存中(如果没有会load到内存中),首先会记修改操作的反操作逻辑数据记录写入undo log buffer中,然后会将修改哪个物理页面做了什么操作记录写入 redo log buffer ,后续某个时间点再一次性将多个操作记录写到 redo log file 和 undo log file。这种 先写日志,再写磁盘 的技术就是 MySQL中的 WAL。
在计算机操作系统中,用户空间( user space )下的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间(kernel space )缓冲区( OS Buffer )。因此, redo/undo log buffer 写入 redo/undo log file; 实际上是先写入 OS Buffer ,然后再通过系统调用 fsync() 将其刷到 redo/undo log file 中,过程如下:

mysql 支持三种将 redo/undo log buffer 写入 redo/undo log file 的时机,可以通过 innodb_flush_log_at_trx_commit 参数配置,各参数值含义如下:
| 参数值 | 含义 |
|---|---|
| 0(延迟写) | 事务提交时不会将 redo/undo log buffer 中日志写入到 os buffer ,而是每秒写入 os buffer 并调用 fsync() 写入到 redo/undo log file 中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。 |
| 1(实时写,实时刷) | 事务每次提交都会将 redo/undo log buffer 中的日志写入 os buffer 并调用 fsync() 刷到 redo/undo log file 中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。一般开启 |
| 2(实时写,延迟刷) | 每次提交都仅写入到 os buffer ,然后是每秒调用 fsync() 将 os buffer 中的日志写入到 redo/undo log file 。 |

redo log记录形式
前面说过, redo log 实际上记录数据页的变更,而这种变更记录是没必要全部保存,因此 redo log实现上采用了大小固定,循环写入的方式,当写到结尾时,会回到开头循环写日志。通过show variables like 'innodb_log%'; 查看参数;记录文件形式如下图:

在innodb存储引擎中,既有 redo log 需要刷盘,还有 数据页 也需要刷盘, redo log 存在的意义主要就是降低对数据页刷盘的要求 。在上图中, write pos 表示 redo log 当前记录的 LSN (逻辑序列号)位置, check point 表示数据页更改记录刷盘后对应 redo log 所处的 LSN (逻辑序列号)位置。 write pos 到 check point 之间的部分是 redo log 空着的部分,用于记录新的记录; check point 到 write pos 之间是 redo log 待落盘的数据页更改记录。当 write pos 追上 check point 时,会先推动 check point 向前移动,空出位置再记录新的日志。
启动 innodb 的时候,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。因为 redo log 记录的是数据页的物理变化,因此恢复的时候速度比逻辑日志(如 binlog )要快很多。 重启 innodb 时,首先会检查磁盘中数据页的 LSN ,如果数据页的 LSN 小于日志中的 LSN ,则会从 checkpoint 开始恢复。 还有一种情况,在宕机前正处于checkpoint 的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度,此时会出现数据页中记录的 LSN 大于日志中的 LSN,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
Mysql8.0 InnoDB存储引擎写操作,对redo log的写操作进行无锁全异步设计优化,增加;具体详细见官方文档:优化 InnoDB 重做日志
undolog
数据库事务四大特性中有一个是 原子性 ,具体来说就是 原子性是指对数据库的一系列操作,要么全部成功,要么全部失败,不可能出现部分成功的情况。实际上, 原子性 底层就是通过 undo log 实现的。 undo log 主要记录了数据的逻辑变化,比如一条 INSERT 语句,对应一条 DELETE 的 undo log ,对于每个 UPDATE 语句,对应一条相反的 UPDATE 的undo log ,这样在发生错误时,就能回滚到事务之前的数据状态。同时, undo log 也是 MVCC (多版本并发控制)实现的关键;通过 show variables like '%undo%'; 查看参数。
binlog
binlog 用于记录数据库执行的写入性操作(不包括查询)信息,以二进制的形式保存在磁盘中。 binlog 是 mysql的逻辑日志,并且由 Server 层进行记录,使用任何存储引擎的 mysql 数据库都会记录 binlog 日志(log_bin 打开的情况下)。
- 逻辑日志: 可以简单理解为记录的就是sql语句 。
- 物理日志: mysql 数据最终是保存在数据页中的,物理日志记录的就是数据页变更 。
binlog 是通过追加的方式进行写入的,可以通过 max_binlog_size 参数设置每个 binlog文件的大小,当文件大小达到给定值之后,会生成新的文件来保存日志。binlog相关参数通过show variables like "%binlog%"; 查看;通过show variables like "%log_bin%";查看binlog是否开启,以及binlog日志目录,8.0版本默认时开启。
binlog使用场景
在实际应用中, binlog 的主要使用场景有两个,分别是 主从复制 和 数据恢复 。
- 主从复制 :在 Master 端开启 binlog ,然后将 binlog 发送到各个 Slave 端, Slave 端重放 binlog 从而达到主从数据一致。
- 数据恢复 :通过使用 mysqlbinlog 工具来恢复数据。
binlog刷盘时机
对于 InnoDB 存储引擎而言,只有在事务提交时才会记录 biglog ,此时记录还在内存中,那么 biglog是什么时候刷到磁盘中的呢? mysql 通过 sync_binlog 参数控制 biglog 的刷盘时机,取值范围是 0-N:
- 0:不去强制要求,由系统自行判断何时写入磁盘;
- 1:每次 commit 的时候都要将 binlog 写入磁盘;一般开启
- N:每N个事务,才会将 binlog 写入磁盘。
从上面可以看出, sync_binlog 最安全的是设置是 1 ,这也是 MySQL 5.7.7之后版本的默认值。但是设置一个大一些的值可以提升数据库性能,因此实际情况下也可以将值适当调大,牺牲一定的一致性来获取更好的性能。
binlog日志格式
binlog 日志有三种格式,分别为 STATMENT 、 ROW 和 MIXED 。在 MySQL 5.7.7 之前,默认的格式是 STATEMENT , MySQL 5.7.7 之后,默认值是 ROW 。日志格式通过 binlog-format 指定; show variables like "%binlog_format%";查看
-
STATMENT : 基于 SQL 语句的复制( statement-based replication, SBR ),每一条会修改数据的sql语句会记录到 binlog 中 。
- 优点: 不需要记录每一行的变化,减少了 binlog 日志量,节约了 IO , 从而提高了性能;
- 缺点: 在某些情况下会导致主从数据不一致,比如执行本地时间操作;
SELECT NOW(),SYSDATE(),SLEEP(3),NOW(),SYSDATE();。
-
ROW : 基于行的复制( row-based replication, RBR ),不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了 。
- 优点: 不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题 ;
- 缺点: 会产生大量的日志,尤其是 alter table 的时候会让日志暴涨;
-
MIXED : 基于 STATMENT 和 ROW 两种模式的混合复制( mixed-based replication, MBR ),一般的复制使用 STATEMENT 模式保存 binlog ,对于 STATEMENT 模式无法复制的操作使用 ROW 模式保存 binlog;
binlog日志主要是用来主从同步复制数据以及数据恢复,是mysql server层执行器进行操作(主)写入和(从)读入(relaylog);
数据可以按天按周进行备份,顺序写入,没有大小限制(文件大小有限,但是整体没有限制,多个文件binlog.**可以通过binlog.index定位);
redo log与binlog区别
不同于redo log, 虽然两者都可以用来恢复数据,但是在mysql中innodb存储引擎的wal机制下生成的redolog有大小限制, redo log 实际上记录数据页的变更,而这种变更记录是没必要全部保存,因此 redo log实现上采用了大小固定,循环写入的方式,当写到结尾时,会回到开头循环写日志;而binlog主要是用来数据恢复,如果备份时间长,用户在某段时间有误操作,需要回滚操作,就可以同binlog来恢复到某个时间点的日志状态;对于redo log是做不到的;而且binlog 不是存储引擎特有的,所以可以在不同的存储引擎公用来恢复数据场景;区别如下:
| redo log | binlog | |
|---|---|---|
| 文件大小 | redo log 的大小是固定的。 | binlog 可通过配置参数 max_binlog_size 设置每个 binlog 文件的大小。 |
| 实现方式 | redo log 是 InnoDB 引擎层实现的,并不是所有引擎都有。 | binlog 是 Server 层实现的,MySQL 3.23.14 中引入的,所有引擎都可以使用 binlog 日志,服务器运行期间生成的服务器全局状态更改的跟踪日志 |
| 记录方式 | redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。 | binlog通过追加的方式记录,当文件大小大于给定值后,后续的日志会记录到新的文件上 |
| 适用场景 | redo log 适用于崩溃恢复(crash-safe),重启恢复的时候,通过check point和write pos 来恢复数据 | binlog 适用于主从复制和数据恢复,某个时间点的操作记录归档,可以按时间点进行恢复;以及主从之间的复制重放, 实现高可用的基础,以及订阅binlog进行不同分布式存储数据的同步 |
由 binlog 和 redo log 的区别可知:因为mysql 早期自带的MyISAM存储引擎设计用 binlog 日志只用于归档,进行数据恢复,只依靠 binlog 是没有 crash-safe 能力的。innodb存储引擎引入mysql之后,引入redo/undo log文件来支持事务持久性和原子性来保证写入数据的一致性;但只有 redo log 也不行,因为 redo log 是 InnoDB 特有的,循环写入,无法还原不在这个redo log中的记录,比如从服务启动或者记录数据落后很多(除非是shared storage架构机制的云厂商数据库,像Aurora,PolarDB);因此需要 binlog 和 redo log二者同时记录,才能保证当数据库发生误删或者宕机重启时,数据不会丢失。
两阶段提交
为了保证写入两份日志redo log, binlog 最终恢复数据是一致的,采用两阶段提交(2pc)的机制(XA,内部/全局事务 innodb提供一样的操作),mysql server 执行器 在调用innodb存储引擎接口进行写操作的时候,起到一个事务协调者的作用,通过TC_LOG(Transaction Coordinator Log)基类定义了事务日志需要实现的接口: open, prepare, commit, rollback, close;实现这些接口的类:TC_LOG_DUMMY(disable the logging), TC_LOG_MMAP(mmap logging), MYSQL_BIN_LOG(binlog);主要是是查看MYSQL_BIN_LOG类中prepare 和 commit 的实现;prepare 和 commit最终会调用存储引擎初始化时指向的handlerton对象对应函数;(这种接口隔离的常用设计,将调用方和实现方进行解耦,根据参数配置来绑定实现方,运行时动态调用)
mysql是以plugin的方式管理存储引擎,replication(主从副本同步)插件和其他插件(通过SHOW PLUGINS;查看);具体的插件代码在plugin文件中,简单的插件示例rewrite_example
mysqld 启动时通过配置初始的存储引擎(默认innodb),调用init_server_components 调用innodb存储引擎的接口进行初始化ha_handler, 在innodb_init中进行初始化, 比如刷盘操作 innobase_hton->flush_logs = innobase_flush_logs; 然后在sql/handler中定义的相关接口调用, 比如ha_flush_logs。
安装replication插件时会注册插件中相应的方法加入observer 列表中,运行触发的时候以AOP的方式RUN_HOOK 扫描observer列表Observer_info->observer调用对应插件函数;replication插件需要实现以下replication文件中相关结构体的方法(接口) 才能加载:
struct Trans_observer /* Observes and extends transaction execution */
struct Server_state_observer /* Observer server state */
struct Binlog_transmit_observer /* Observe and extends the binlog dumping thread. */
struct Binlog_relay_IO_observer /* Observes and extends the service of slave IO thread. */
struct Binlog_storage_observer /* Observe binlog logging storage */
这里会有各种日志的刷新机制,可以通过show variables like '%innodb%flush%'; show variables like 'sync_binlog';获取对应的参数,可以去官网Server Option, System Variable, and Status Variable Reference 查找对应的详情进行配置优化;
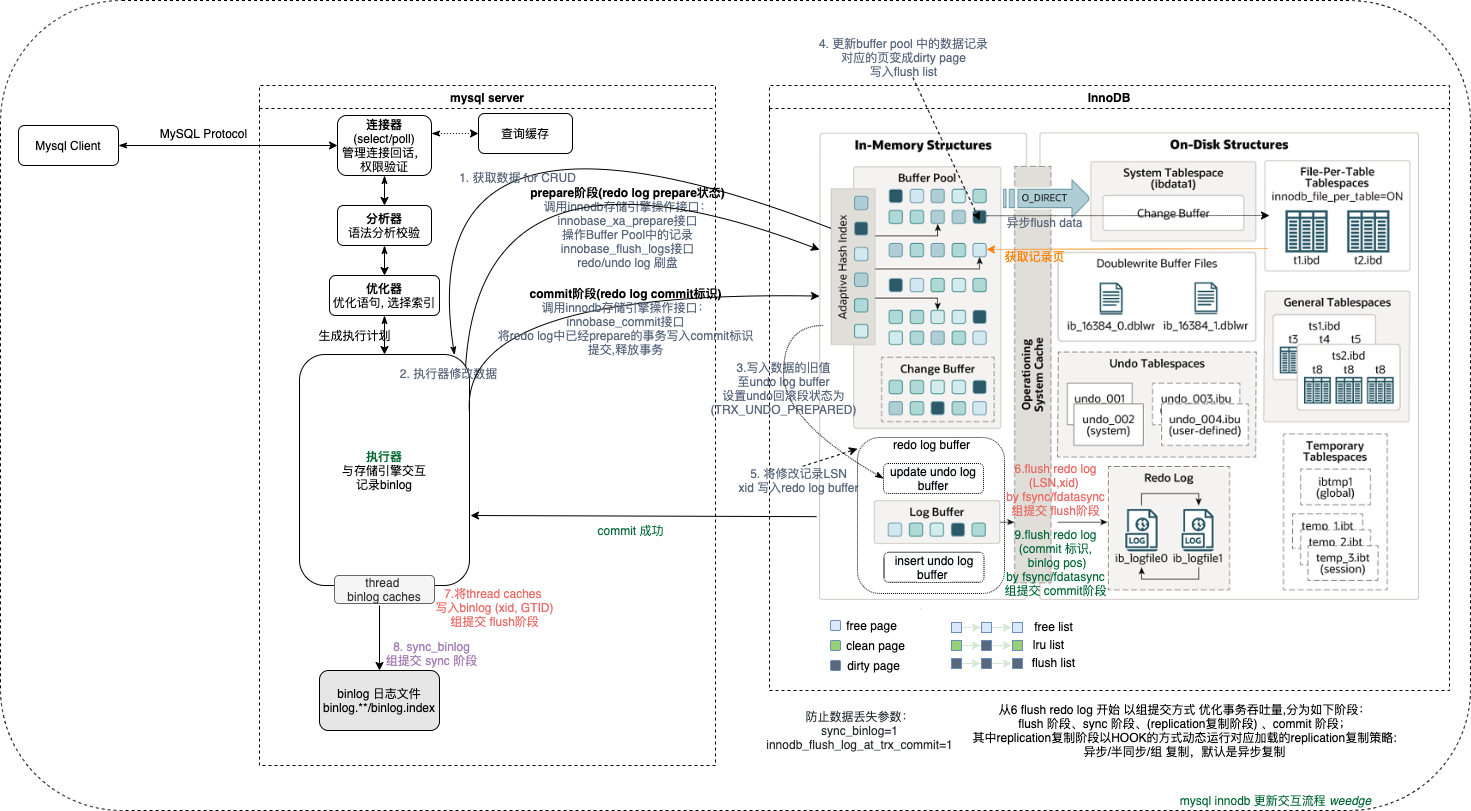
当开启binlog时, MySQL默认使用该隐式XA模式,开启自动提交事务autocommit。事务的提交流程相对比较复杂,执行简单的update操作,简述如下:
0. 执行器数据获取修改:
- 执行器调用innodb存储引擎接口获取满足条件的数据,通过树索引查找/全表查找, 如果数据在buffer pool中查找到,返回数据;否则从磁盘表空间文件中读取数据page到buffer pool clean page中,返回数据;无数据,流程终止返回;
- 执行器修改找到的数据,将修改的数据 调用innodb存储引擎接口写入新数据,进行两阶段提交;
事务的提交过程入口点位于 ha_commit_trans函数,以mysql binlog 为事务2pc协调者为例,事务提交的过程如下:
1. mysql bin log 事务2pc协调者 处理 准备prepare阶段:(tc_log->prepare)
MYSQL_BIN_LOG::prepare(THD *thd, bool all) 设置 thd->durability_property = HA_IGNORE_DURABILITY; 用于在存储引擎准备阶段不刷新事务日志redo/undo log 到磁盘日志文件中;
调用流程:ha_prepare_low → innobase_xa_prepare → trx_prepare_for_mysql → static void trx_prepare(trx_t *trx) → trx_prepare_low → trx_undo_set_state_at_prepare
-
执行器调用innodb存储引擎接口进行修改操作,首先写入数据的旧值至undo log buffer中,更新InnoDB的undo回滚段,将其设置为Prepare状态(
TRX_UNDO_PREPARED)写入mlog中,返回 redo log 的LSN, -
更新buffer pool中的数据(如果插入需要从free(free list)变成clean page(lru list),free list 不够时需要从flush ist或者lru list淘汰一定的page变成free page 加入free list); 修改的clean page(lru list)变成 dirty page(lru list)(更新的数据页在缓存中,还未刷盘);dirty page写入flush list; 为了提高写性能异步线程刷盘(刷盘时机可以在commit之后;MySQL 5.7引入了page cleaner线程)
Tips: 在flush list上的页面一定在lru List上,但是反之则不成立。一个数据页可能会在不同的时刻被修改多次,在数据页上记录了最老(也就是第一次)的一次修改的LSN,即oldest_modification。不同数据页有不同的oldest_modification,flush list中的节点按照oldest_modification排序,链表尾是最小的,也就是最早被修改的数据页,当需要从flush list中淘汰页面时候,从链表尾部开始淘汰。加入flush list,需要使用flush_list_mutex保护,所以能保证flush list中节点的顺序。
-
同时将数据页的修改记录LSN写入redo log buffer中,准备提交事务,此时 redo log 处于 prepare 状态,如果thd->durability_property = HA_IGNORE_DURABILITY, 将
LSN写入redo log 磁盘文件中;原子化操作trx_t事务状态为 PREPARED (用于事务隔离操作); 将gtid_desc写入undolog 表空间中;然后告知执行器执行完成了,随时可以提交事务。
Tips: 这里会出现redo log file写满的情况,buffer 写入会hang住,MySQL就会停下手头的任务,先把脏页刷到磁盘里,才能继续干活,会导致MySQL的服务器的tps有明显的波动; 默认开启了innodb_adaptive_flushing 算法进行优化,在redo log file还没有满的时候,会根据redo log file生成的速度和刷新频率来将redo log file中的脏页刷入磁盘表空间文件中;
2. mysql binlog 事务2pc协调者 处理 提交commit阶段:(tc_log->commit)
调用流程:TC_LOG::enum_result MYSQL_BIN_LOG::commit(THD *thd, bool all) →int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit) , 如果没有开启log_bin,没有bin log文件,直接跳至commit阶段;
组提交 (流程见代码中介绍 ordered_commit ):组提交第一眼看着有点懵逼,可以结合这片文章 [图解MySQL]MySQL组提交(group commit) 了解;主要是为了提升事务吞吐量设计的方案(原则:尽量减少磁盘IO, 利用持久盘的特性顺序写);如同木桶效应一样,redo log 和 binlog 两者其中有一个没有组提交,都会降低事务吞吐量,所以最好的方式redo log 和 binlog 两者都组队提交; mysql设计者将组提交从flush阶段开始优化,将其分为几个阶段: flush 阶段、sync 阶段、(replication复制阶段) 、commit 阶段;其中replication复制阶段以HOOK的方式动态运行对于的replication复制策略,默认是异步复制。
binlog_order_commits参数控制innodb commit顺序和binlog写入顺序是否一致,默认启用保证顺序一致,方便备份和快速恢复;和binlog组提交配合使用,这个参数来自官网的介绍:
当在复制源服务器上启用此变量时(这是默认设置),发送给存储引擎的事务提交指令在单个leader线程上被序列化,因此事务总是按照写入binlog的相同顺序提交。禁用此变量允许使用多个线程发出事务提交指令。与binlog组提交结合使用,这可以防止单个事务的提交率成为吞吐量的瓶颈,因此可能会产生性能改进。
Flush阶段:
调用流程:TC_LOG::enum_result MYSQL_BIN_LOG::commit(THD *thd, bool all) →int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit) → int MYSQL_BIN_LOG::process_flush_stage_queue ;
RUN_HOOK 去获取加载的插件,rpl handler Binlog_storage_delegate::after_flush FOREACH_OBSERVER宏 遍历observer列表Observer_info->observer调用对应replication插件函数
最终调用os_file_fsync_posix flush redolog to disk ; 根据不同的操作系统来调用,unix操作系统调用fsync/fdatasync函数刷盘, fsync会确保OS cache中的数据直到写磁盘操作结束才会返回,并且写入元数据,而fdatasync不会; 如果想不走OS cache直接写磁盘,对打开/创建的文件句柄加上O_DIRECT属性,一般用于写系统表空间数据落盘;
此时process_flush_stage_queue处理会形成一组队列,由组leader(一个组中最早开始的事务)依次为别的线程写binlog文件 在准备写binlog前,会先调用ha_flush_logs -> innobase_flush_logs接口,将存储的日志写到最新的LSN;然后再写binlog到文件; 这样做的目的是为了提升组提交的效率。
- 执行器 调用innodb存储引擎innobase_flush_logs->log_flush_low->redo_space_flush->os_file_flush->os_file_fsync_posix 接口 将 redo/undo log buffer中的数据写入redo/undo log file 磁盘中;
- 执行器 调用 MYSQL_BIN_LOG::flush_thread_caches 将 thread caches binlog缓冲数据 写入 bin log(xid,GTID)中(还未刷盘),通过
show variables like '%binlog_cache%';查看缓冲大小; 并且设置好事务的写入位置m_trans_end_pos,当事务提交commit阶段的时候,直接获取位置提交;
Sync_binlog阶段: std::pair<bool, bool> MYSQL_BIN_LOG::sync_binlog_file(bool force)
RUN_HOOK 去获取加载的插件,rpl handler Binlog_storage_delegate::after_sync FOREACH_OBSERVER宏遍历observer列表Observer_info->observer调用对应replication插件函数;
最终调用 int my_sync(File fd, myf my_flags) Sync binlog data in file to disk
如果sync_binlog计数超过配置值,则进行一次文件fsync,n>1 开启组提交,参数sync_binlog的含义不是指的这么多个事务之后做一次fsync,而是多个事务一组之后做一次fsync,binlog_group_commit_sync_delay,binlog_group_commit_sync_no_delay_count 这些参数见官网文档;
- 开始生成这个时间点的逻辑操作日志格式,通过
sync_binlogflush策略异步将thead caches中的数据批量写入到磁盘binlog文件binlog.**/binlog.index中; 通过show binlog events;来查看binlog文件相关的信息,也可以对单个文件查看;
Async/Semisync/Group 异步/半同步/组复制阶段: (写操作都在主上)
异步复制:主库在记录完binlog,执行完自己的事务之后就会直接返回,mysql主从模式默认是异步复制;异步复制流程如下图:
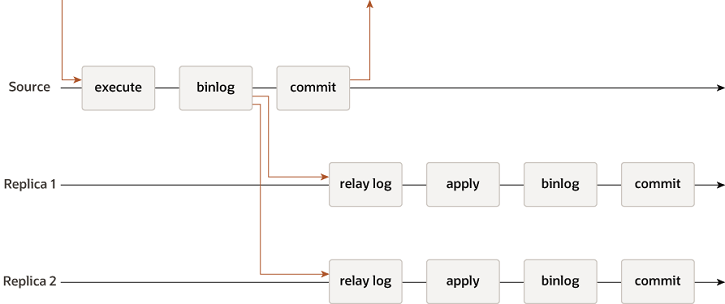
半同步复制:主的事务需要等一台从同步binlog日志提交到Relay Log中(sync_relay=1),返回ack,主库提交事务;半同步流程如下图:
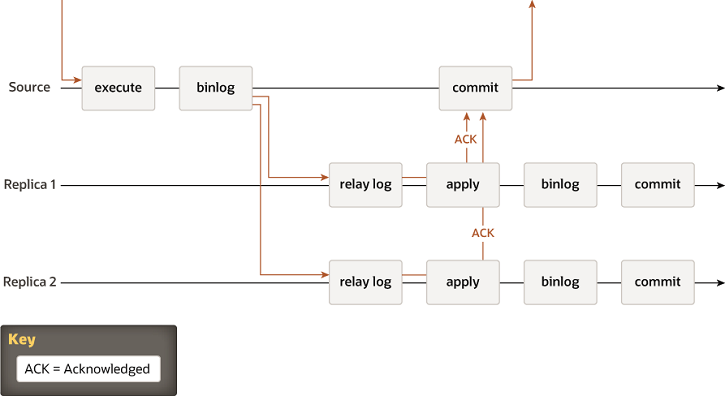
从MySQL5.5开始 以插件的形式支持半同步复制;如果需要支持,主从都需要安装半同步插件库;对应的代码在plugin/semisync文件夹中。
主 install plugin rpl_semi_sync_master soname 'semisync_master.so';
从 install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
并且打开半同步复制,set global rpl_semi_sync_master_enabled=1;
其中通过参数rpl_semi_sync_master_wait_point来决定什么时候提交事务:
- after_sync 主库先不提交事务,等待某一个从库返回了结果之后,再提交事务,在返回结构通知客户端。这样一来,如果从库在没有任何返回的情况下宕机了,master这边也无法提交事务。主从仍然是一致的,mysql5.7之后默认值。
- after_commit 主库先提交事务,等待从库返回结果再通知客户端。
组复制:基于原生复制及 paxos 协议,提供一致数据安全保证,一种可用于实现容错系统的技术;具体详情见官方文档:MySQL8.0 Group Replication;组复制流程如下图:
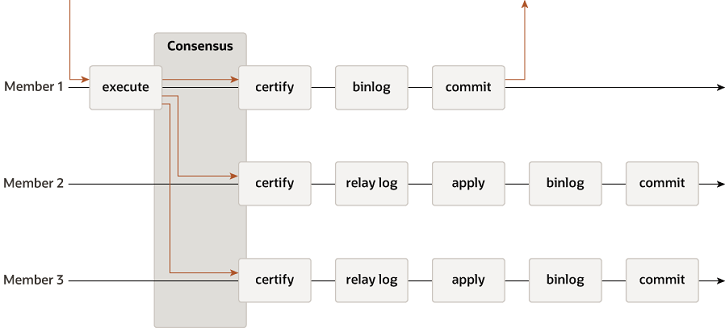
MySQL 5.7.17版本中引入MySQL 组复制,同样也是以插件的形式支持; 对应的代码在plugin/group_replication文件夹中。一组副本机器安装插件都是INSTALL PLUGIN group_replication SONAME 'group_replication.so';
- 如果开启的主从复制(默认异步)1:n,主库会等待从库I/O线程建立连接之后,创建binlog dump线程,通知slave有数据更新,当I/O线程请求日志内容时,会将此时的binlog名称和当前更新的位置pos同时传给slave的I/O线程, 把binlog event发送给从库I/O线程,从库I/O线程获取到binlog event之后将其写入到自己的Relay Log中,然后从库启动SQL线程,将Relay中的数据进行重放,完成从库的数据更新;为了保证不重复更新,binlog/relaylog 中记录了GTID(mysql5.6加入), 全局唯一, 如果relaylog中已有GTID, 则执行GTID自动跳过,意味着在源上提交的事务只能在副本上应用一次,这有助于保证一致性;
另外如果主从复制过程突然中断了,或者主从切换了,重启之后发现SQL线程实际执行到位置和数据库记录的不一致;mysql5.6之后将复制的进度放在系统的mysql.slave_relay_log_infoinnodb表里,并且把更新进度、SQL线程执行用户事务绑定成一个事务执行。即使宕机了,可以通过MySQL内建的崩溃恢复机制来使实际执行的位置和数据库保存的进度恢复到一致。
Commit阶段:
调用流程:int MYSQL_BIN_LOG::finish_commit(THD *thd) -> ha_commit_low -> innobase_commit -> void trx_commit(trx_t *trx)
RUN_HOOK 去获取加载的插件,rpl handler Trans_delegate::after_commit FOREACH_OBSERVER宏遍历observer列表Observer_info->observer调用对应replication插件函数;
-
只有binlog写入磁盘成功之后,执行器才会调用innodb存储引擎接口,从队列中获取事务组依次进行innodb commit 提交释放事务,将redo log中已经prepare的事务提交写入commit标记,并且写入binlog位点;最后调用MYSQL_BIN_LOG::rotate 是否切换binlog文件(在切换文件期间,使用一个防止新的提交组执行刷新阶段的锁,并等待直到准备好的事务的计数器变为0,然后才创建新文件),如果切成新文件, 调用MYSQL_BIN_LOG::purge()刷盘;结束ordered_commit 组提交流程,返回提交;
Tips: Commit阶段不用刷盘,Flush阶段中的redo log刷盘已经足够保证数据库崩溃时的数据安全了; Commit阶段队列的作用是承接Sync阶段的事务,完成最后的引擎提交,使得Sync可以尽早的处理下一组事务,最大化组提交的效率。
整体更新流程:
崩溃恢复
更新流程中写入redo log的过程拆成了两个步骤prepare和commit 两个阶段;如果不使用两阶段提交,数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。在崩溃恢复中,是以 binlog 中的 xid 和 redolog 中的 xid 进行比较,xid 在 binlog 里存在则提交,不存在则回滚,以及判断redo log中是否有commit标识;崩溃恢复时具体的情况:
- binlog无记录,redolog无记录:在redolog写之前crash, 无prepare状态,无undo log 记录,恢复操作:无,无需关心;
- binlog无记录,redolog无记录:在redolog写之前crash, 无prepare状态,有undo log 记录,恢复操作:通过undo log回滚事务;
- binlog有记录,redolog有记录:redolog状态prepare, 则判断对应的事务是否存在完整的binlog,恢复操作:如果是, 则提交事务,否则, 通过undo log回滚事务;
- 如果redo log里面的事务是完整的, 也就是有了commit标识, 恢复操作:直接提交事务;
总结
对于需要持久化的数据库系统,避免不了事务在处理过程中,突然中断的情况;WAL通过预写日志的方式在事务提交之前,需要把修改重放记录和撤销详细记录写入日志文件中,以便在故障后恢复数据;事务开始后,所有对数据库的修改在发送到缓冲池之前都被记录在内存中的WAL缓冲区中;事务提交之前,必须把WAL缓冲区刷新到磁盘。mysql innodb存储引擎引入redo/undo log文件来支持事务持久性和原子性,由于mysql binlog用来归档数据记录恢复和复制,为了保证写入两份日志redo log, binlog 最终恢复数据是一致的,采用两阶段提交机制,通过源码了解了些整体WAL的实现;以及崩溃时候需要用日志进行恢复。(其他持久化存储系统的WAL实现,待续)
references
- Write-ahead_logging
- ARIES:Algorithms_for_Recovery_and_Isolation_Exploiting_Semantics
- aries.pdf
- 缓冲池管理策略
- From ARIES to MARS: Transaction Support for Next-Generation, Solid-State Drives.pdf
- Implications of Non-Volatile Memory as Primary Storage for Database Management Systems.pdf
- Scalability of write-ahead logging on multicore and multisocket hardware.pdf
- WBL.pdf
- ARIES Overview, Types of Log Records, ARIES Helper Structures
- ARIES Database Recovery (CMU Databases Systems / Fall 2019)
- mysql binary-log
- MySQL · 引擎特性 · 庖丁解InnoDB之UNDO LOG 庖丁解InnoDB之REDO LOG
- MySQL · 引擎特性 · 基于GTID复制实现的工作原理 MySQL · 源码分析 · 内部 XA 和组提交
- 日志和索引相关问题
- [图解MySQL]MySQL组提交(group commit)
- MySQL · 引擎特性 · WAL那些事儿
- 无处不在的 MySQL XA 事务
- Server Option, System Variable, and Status Variable Reference
- 凤凰架构-本地事务