背景:
教学直播间场景多样性,按年龄段区分辅导后台角色,构成整个教学课中直播和互动的多样性,为了快速支持业务发展,导致后端服务接口过多,不易维护,统一管理。
主要分为如下场景:
- 对接辅导侧后台的场景: 辅导侧不同的辅导运营后台,比如:低幼辅导,班主任(班课),督学服务,0转化督学服务等,后续可能还有小鹿编程,大师素养课对应的辅导侧;辅导侧会分班去带学生,不同的辅导侧会有单独的课中业务服务来对接辅导后台的接口,课中理解不同的业务组织形态,代码逻辑和存放数据冗余,不方便维护;
- 业务前台对接直播接口场景:直播业务服务多样;按照课程类型分为专题课,班课,短训班,素养课,编程课等;直播服务:班主任出镜(课前,课中,课后),小班,小组,大班,自习室等;服务的多样性,导致业务接口繁琐,前期快速开发上线,针对每个直播服务业务场景单独提供接口, 带来的问题不方便统一管理维护;
- 课中互动中台互动聊天场景: 大班,小班,小组直播间场景依赖售卖和辅导侧的组织结构进行聊天,答题,鼓励,PK,发红包等互动;导致课前需要对这些组织结构按照不同直播场景+不同辅导侧数据进行提前预热处理,逻辑重复;
设计目标:
需要一个承上启下的模块来连接辅导侧支撑课中直播/回放互动场景:
- 对不同业务直播场景进行收敛,减少重复开发;
- 隔离底层业务后台辅导侧,售卖侧数据,统一接入辅导/售卖侧全量数据,以及异动,减少数据冗余;
- 隔离底层业务数据,抽象直播中台数据模型,中台面向这个数据模型进行编程,提供原子化接口;
- 当天上课课前预热数据需要在0-6点尽量全部预热完成;预热加速,预热后的数据检查;
- 复用中台数据模型已支持的直播场景能力,提供saas化服务,前台使用中台定义的dsl,根据业务场景进行组装,提高开发效率;
- 提供可配置后台,管理服务接口;
- 将读写io最小化,提高原子化接口响应时间RT
原则: 高内聚低耦合、空间换时间
数据模型:
-
一个章节会有多个直播间,比如辅导老师出镜(课前,课中,课后),最多3n+1个直播间,n为课程章节下的辅导老师数目,liveRoom
-
不同直播间,对应不同的直播间业务流程: bizType
三分屏直播间,进入教室→签到→直播/互动→离开(切直播间)
小组直播间,进入教室→课件下载→分组→签到→直播/互动→离开(切直播间)
小班直播间,进入直播间→ 课件下载→ 分班→ 直播/互动→离开(切直播间)
自习室直播间,进入直播间→ 签到→直播
-
不同直播间,对应不同的流媒体推拉流方案:streamPolicy
三分屏直播间,rtmp + 长链接
小组直播间,rtc + 长链接
小班直播间,rtc + 长链接
自习室直播间,rtmp + 长链接
-
不同组织关系对应聊天互动广播统计维度,抽象组织结构:orgPolicy, orgTree(node)
一课三分屏:/课程章节, 无班主任,全员互动;课中自动生成;
小英小数小语文小组直播间,/课程章节/辅导老师/{队/小组}, 辅导老师: 低幼辅导,班主任(班课),督学服务,0转化督学服务等, 队/小组由课中学生选组自动生成;低幼辅导,班主任,督学服务,0转化督学服务提供数据;
班主任小班直播间,/课程章节/辅导老师/小班,辅导老师: 低幼辅导,班主任(班课),小班由辅导侧课前排灌班生成;低幼辅导,班主任服务提供数据;
短训班,/课程章节/督学LPC/微信群,微信群有督学老师课前排灌班生产,督学服务提供数据;
0转化服务,/课程章节/督学LPC , 0转化督学服务提供数据;
lessonPolicy: (bizType,streamPolicy,orgPolicy)
原则:
- 直播中台解耦业务属性,支持抽象业务场景,作为底层直播能力输出;
- 可复用,直播功能,性能,稳定性的复用;比如三分屏,班课,小组,伪直播等不同维度业务属性解耦前置到预热阶段;
- 可扩展,直播数据模型属性如有新增,不会影响原有属性;
数据量:
1天最高峰2w节课,总报名学生数量600w+, 在线学生100w+ , 课中进入上课页面qps 120w+
处理数据量:按一个课程章节来计算,最大的报名学生数目3w+ 实际测试用60w+ 的报名学生,预热大概45多分钟
3w 的报名学生, 小组直播间,班主任出镜,一个班主任最多带500学生,预热大概 1分钟30多秒
策略数据: 一个章节对应一个策略,一个策略可以给多个章节使用,
policy (id,conf,desc,name)
lessonPolicy (keyId,keyType,bizType,partition,policyId)
直播间数量: 3n+1 (n是班主任数目,出镜场景) 最多181个直播间 180*8*5(id,roomId,virturalRoomId,rootId,bizId,roomType,teacherUid,startTime,endTime,status) = 7.2KB
组织节点数量:3w/6=5000个小组节点,5000/6 = 800多个队节点,60个辅导老师节点,总共6000个组织节点, 6000*8*7(id, nodeId,parentId,rootId,virturalNodeId,sourceId,path) =328KB
用户数量: 3w+ 每个班主任最多带500个学生, 3w/500 = 60 个班主任,最多 181 个直播间, 180*500 + 3w =12w条直播间用户数据, 按直播间维度协程任务分批处理; 12w*8*4(id,uid,nodeId,roomId) =3.7MB
一天大概总共 2w * 4M = 78GB数据可能需要课前预热 (以一天最大2w节课程章节,每个章节报名人数3w计算, 报名学生2w*3w =6亿)
依赖中间件基础服务
redis (stored k/v存储) 前期是哨兵模式架构, 后期采用proxy模式架构
DB(mysql ) 主从架构,未使用proxy数据库中间件
MQ(NMQ, RocketMQ) 消息队列
前期用的NMQ 消息以push的方式发送的消费方,通过groupKey来保证有序,以及消息积压报警,无限重试,消费方来保证幂等
RMQ是为了兼容NMQ , 对rocketMQ进行来封装, 消息生成侧提供proxy, 兼容nmqproxy;消费侧rocketMQ是pull长轮训方式,为了兼容NMQ的push方式,提供pusher模块;数据存放用rocketMQ的broker
rocketMQ : https://github.com/apache/rocketmq/tree/master/docs/cn
kafka : https://kafka.apachecn.org/intro.html 长链接心跳打点数据 → kafka → 计算引擎
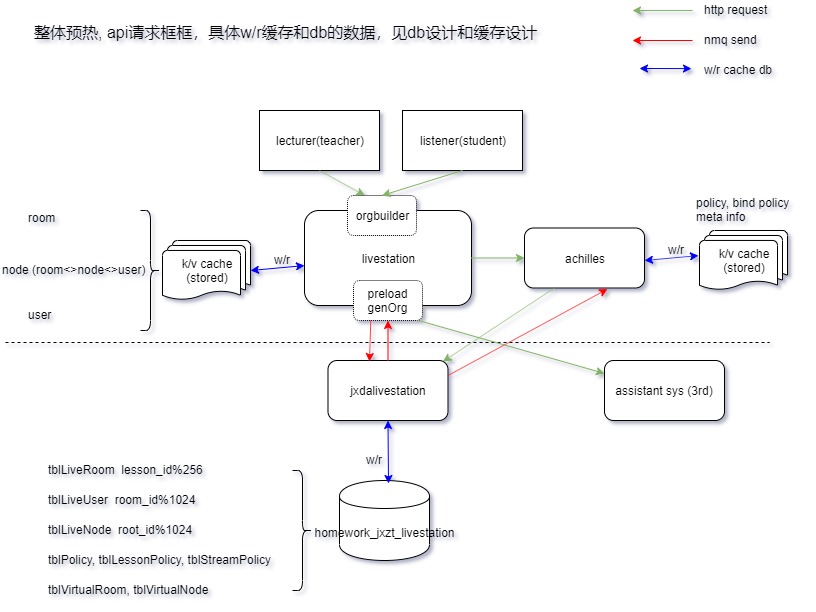
流程
数据对接方
预热模块接入辅导侧三方数据:
- 班主任侧(小班,辅导老师:班主任)
- 督学服务侧(微信服务,辅导老师:督学)
- 0转化督学服务侧(拉新转化,辅导老师:0转化督学)
- 低幼服务侧(小班,辅导老师:班主任)
场景(直播间维度)
- 一个章节里一个主直播间一个组织树 (非出境)
- 一个章节里多个主直播间一个组织树 (出境)
- 一个章节里多个主直播间对应多个从直播间多个组织树 (旁听+出境)
- 多个章节情况都转化成一个章节下的直播间情况 (共享)
- 跟课场景:一个章节可能给不同的辅导侧在使用,辅导平台的数据源不同,一个组织树对应多个业务组织,一个直播间主讲推流,多个辅导侧后台拉流监控
流程
定义规范辅导侧数据接入 → 上课课程章节绑定对应策略(如不满足,新增支持)→ 分发任务前置预热 → 生成中台理解的属性 (liveRoom,lessonPolicy,orgTree 等) →直播中台面向这些属性编程,提供原子化读写接口
策略规则平台policy:
用于不同的业务直播间类型绑定组织策略,开发提供给运营产品团队使用
- 推拉流策略(rtc(udp),rtmp(tcp)+CDN 延迟较高,价格低; 学生,老师小组直播间互动场景用的rtc, 一课(三分屏)直播间用的rtmp; 辅导跟课后台,监控后台用的rtmp);
- 直播间策略(班主任课前/课中/课后出镜直播间,主讲直播间);
- 互动组织策略(基于组织树,学生,班主任,老师 通过长链接的聊天广播模式);
- 预热策略(极简,简单,全部预热);
- 预热时间计算预热时长(根据直播间数,组织节点数,用户数,计算预热时长);用于分层时间轮来监控预热任务超时报警
- 缓存设计中直播间的学生集合和在线学生集合 zset 分片策略(根据课程报名人数和商品库存数调权相加获取);
- 数据源定义(辅导侧数据:低幼,0转化督学,督学,班主任等,售卖侧数据);
- 异动数据通知定义 (学生更换班主任/小班,老师更换,课程章节上课时间更改,课程章节重开)
组织数据生成引擎core:
-
缓存设计:
策略缓存/本地缓存,组织树缓存,直播间缓存,学生缓存,预热任务缓存
-
数据库数据设计:
业务策略表,组织节点表,直播间表,学生表
-
直播中台组织引擎课中数据接口设计:
直接从缓存中取,交互的数据通过write-behind 模式写入
获取组织树节点信息,节点原始节点信息,子节点信息,学生所在直播间节点,选组/位置
获取业务课程章节业务id的直播间信息
-
直播中台组织引擎回放数据接口设计:
接口数据缓存,cache-aside 模式读取,课后回放数据都是读的场景
-
消息队列topic 消息体设计 :异步落库,为了同步db, 同步db逻辑幂等,降低db的写压力
直播间,组织节点,学生数据
内部优化设计:(原则:尽量减少读写io, 达到最优解)
- 异步缓冲buffer数据批量发送队列入库,减少网络io,降低db的写压力
- 课中老师的课件信令记录,zset存缓存,学生高并发场景获取直播间信令记录,通过本地缓存来减少对zset 大key数据读取压力
- 任务池化,并发批量处理任务,提高吞吐相应速度
- 临时对象池化,高并发吞吐减少gc
配置平台conf-dashboard:
- 预热流程 DSL pipeline 配置,
- 依赖缓存和数据配置 ,
- 业务配置,
- 预热报警通知配置,
预热数据监控平台monitor-dashboard:
- 提供手动触发预热和预热数据检查;
- 查看预热好的直播间,组织树,学生所在直播间的组织节点信息,以及课中直播间开始结束时间,直播间状态,学生在线状态,聊天状态(禁言/可聊天), 分组信息,到课时间
开发工具
-
线上/线下预热通知群
-
预热报警通知群
-
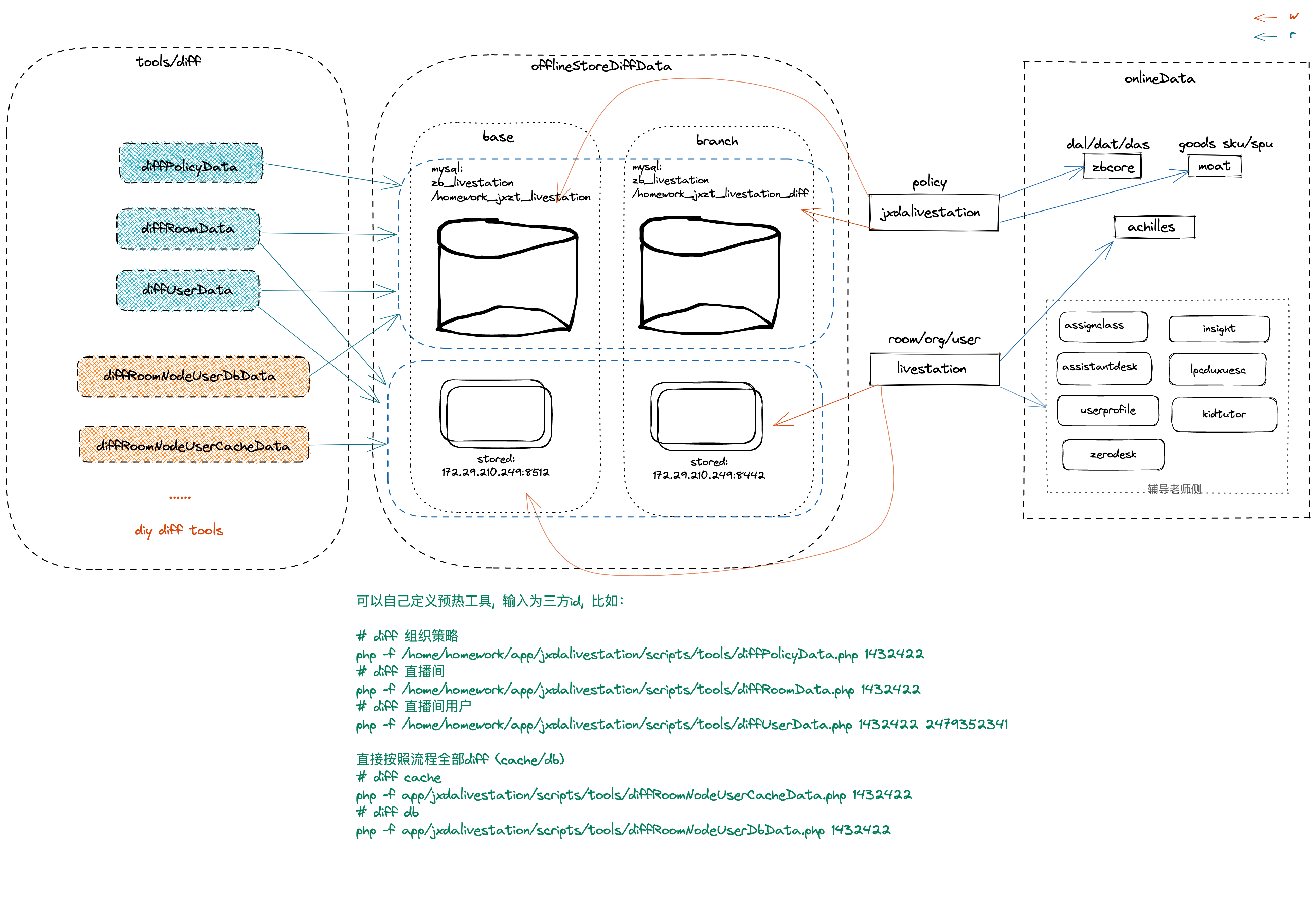
预热回归diff检查工具
容错处理
-
分布式任务处理,如果一个机器挂了不影响任务处理,failover机制
-
任务执行失败会右报警机制,可以手动处理重新预热,还有自动轮训检查预热是否成功机制,如果预热失败,会在下个轮训周期出发预热, 轮训周期可调,默认是10分钟
技术难点和收益
组织引擎:
-
业务数据源梳理,设计通用的模型,通过策略配置将不属于课中直播中台的业务属性进行隔离,
比如售卖平台和辅导侧运营平台 售卖的课程产品,分班排管班策略,以及课程中每一节大纲章节业务属性,都通过课前预热的时候进行解耦,生成课中理解的内聚模型,直播间,组织树;主讲,辅导老师和学生在直播间上课,通过组织树进行互动;课中学生老师进入教室获取课前绑定的策略,初始化直播间和组织树属性。这样能够服用已有沉淀下来的稳定功能;而且在支持新业务直播场景下,节省开发人力,加速产品迭代,将业务属性隔离,也有助于服务稳定运行
-
组织树在分布式缓存和数据库中的设计;
如何在k/v存储中表示一颗组织树,以及在db数据库表中表示一颗组织树和学生,老师之间的关系;
数据库需要考虑每天的数据容量,以及未来3年的数据容量(按一天2w节课,一节课3w+报名,估算78GB数据量);
为了方便课后问题排查,缓存数据过期时间7天(可调整),课中接口是直接和缓存交互,改变的数据状态通过Write behind模式异步刷盘写入db中,后台的接口数据通过Cache aside 课前预读提前加载至缓存中(延迟双删)。
-
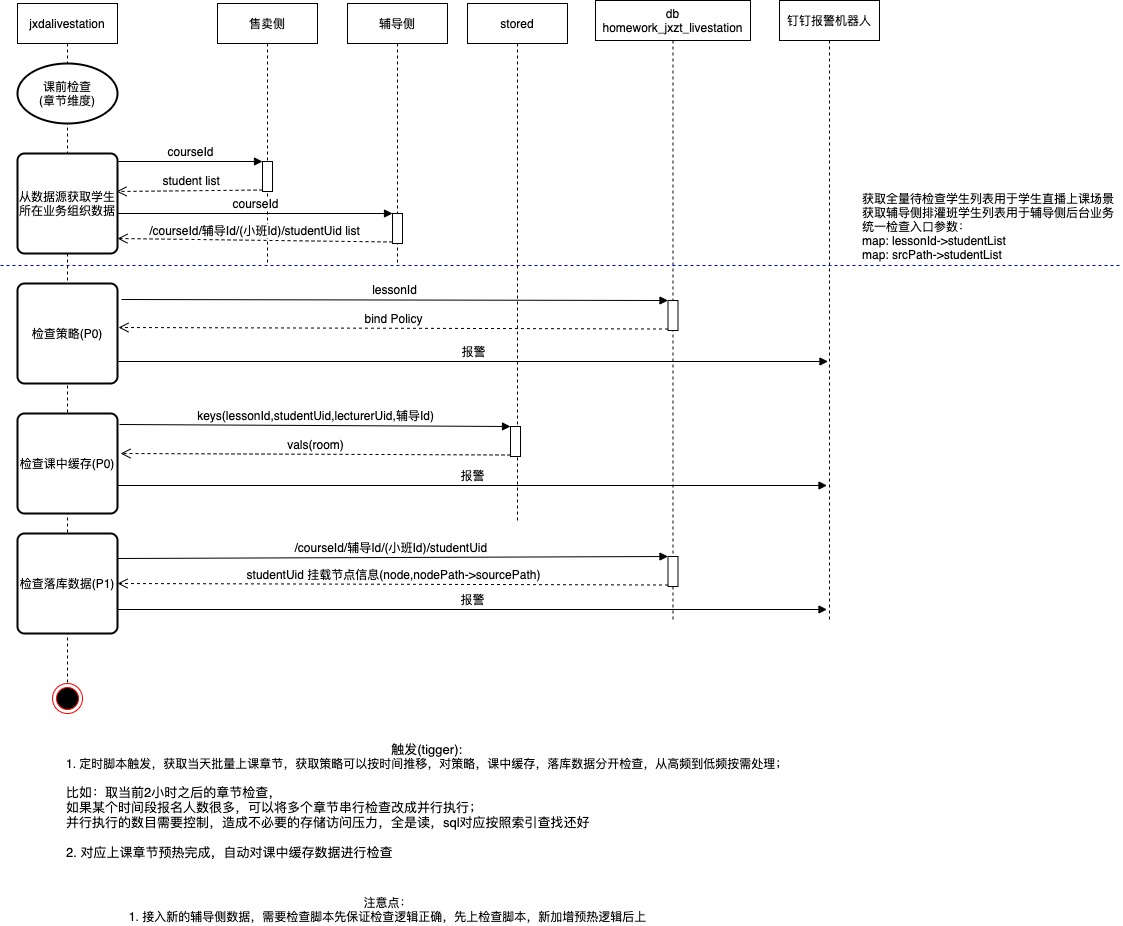
半夜0点~6点这段时间需要保证当天预热数据的高效性,准确性,以及可视化监控报警:
1. 预热框架的设计 ,业务数据和课中直播组织模型 策略绑定平台,生产预热任务,负载均衡分发至预热worker节点,记录预热,任务监控(预热和检查),预热失败的容错,failover,报警;
将业务属性和直播属性通过策略进行绑定,生成任务发送给消息队列,通过消息队列pusher到 预热模块, 利用内部的nmq工具属性,进行任务的负载均衡发布到每台worker协程来预热,考虑到可能会同时发多个相同的任务在不同的worker上执行,需要加锁;预热记录在预热记录表中,进行监控;
每个预热worker会统计本机处理的章节,直播间,组织节点/树,学生数目,预热完之后,通过丁丁通知预热结果,也会同时触发数据检查流程;
为了支持不同的预热场景,加入了极速预热,快速预热策略,满足新建一个课直接上课的场景(这些场景在内部老师的测试课会使用到), 秒级内完成;
2. 预热数据检查
检查预热数据的完整性,通过和数据源的对比,检查绑定的策略属性是否是好的;缓存和db中的直播间,组织数据,以及学生所在组织树,老师所在的直播间等数据的检查
批量数据检查不能影响线上的稳定性,主要是读取线上缓存和db中的数据,也会像预热那样分发到集群机器上去并行处理;如果是业务高峰期进行检查,需要对检查流量进行限流,
限流方案:对单机进行限流,对整体检查集群进行限流,都是以当前运行的检查任务数进行计数限流控制(redis hincr);每个检查worker进程会统计当前正在运行的任务数,如果到了单机最大任务数,新的检查请求会直接返回检查容量已超限制错误,pusher会重试到另外一台机器上,
3. 预热数据监控
课前 预热任务和检查任务的监控;
课前 业务数据和课中直播组织模型 绑定策略, 老师直播间,组织树,学生等数据,在缓存,db中的监控;
课中 直播间状态,所在组织树下的学生数据状态的监控;
- 需要考虑课前,课中的异动场景,比如
课前,辅导侧给分好班的学生重新分班,需要订阅辅导测的异动,如果是同一时间批量修改,课中直播中台预热好的组织树需要考虑 并发异动修改学生所在的节点;
课中,并发场景动态扩容,比如学生进入教室之前需要选组,如果初始小组节点不够,到了阈值,发送扩容任务,通过异步动态扩容协程进行扩容;
- 课中获取缓存数据的接口优化,分布式缓存中的大key和热key的优化
大key优化 通过分片处理,直播间的在线学生集合 和 报名学生集合,对key 进行partition分片,每个partition 5000个学生, partition的值是在课前预热的时候通过报名人数和课程的库存数量进行加权和预估的值;
热key优化 通过加本地缓存,通过LRU进行evict,比如 一个老师上课时产生的信令列表(直播间维度,按时间顺序),存放在zset中,提供学生进入教室时拉取,以及数据滞后时候的拉取,如果是一个热门直播间,会同时上万个学生获取这个老师产生的信令列表,会对分布式缓存中的slot带了压力,为了解决这个问题,将以获取的信令列表数据缓存到本地的有序列表中(sortedlist -> skiplist), 这些有序列表通过直播间维度hash分桶, 本地的有序列表数据只需维护 新增的数据,而不需要整段去获取缓存,减少获取热key的网络io; 这里会打点记录每个key的hit命中/miss未命中的数据量,数据日志采集接入基础监控平台,实时查看;
-
新业务接入,对新策略的增加,以及对老策略的修改,如何保证系统稳定性
进行预热逻辑升级之后,上线之前都会在线下进行一轮未改策略的预热数据自动化diff,是拉取不同的版本,还未合入master的线上版本和修改了的版本,分布部署在两个容器中;根据不同的直播场景,从线上获取数据,预热写入线下缓存实例k/v和数据库实例表中,然后分别读取两份数据进行对比,比较为修改的策略是否有影响,有数据diff, 并报告diff的数据点,进行线下修复,再次进行自动化diff, 无diff之后,才能合并到master上线分支,上线;
建设组织引擎课前预热整体收益:
-
节约了人力,加速产品开发迭代周期;以前如果接入新的业务辅导侧数据,以及提供相关的课中接口,从开发,测试上线,大概3~4个人力,需要2~3周的时间, 改造之后,开发,测试上线,大概1-2个人,需要1周的开发时间,节约了一半的成本;
-
复用现有直播场景功能,将底层业务和直播属性进行隔离, 直播只关注直播属性,无需关注业务属性;保证直播服务的稳定性,将业务数据提供规范化接入后,可以将业务依赖进行反正,为后续saas化提供保障;
-
直播接口性能有所提高,以前是有不同的业务方去把控,现在收敛整体把控,降低资源消耗(cpu, 内存,磁盘空间,网络io),有些业务当时还是用php开发,php是多进程的方式处理业务请求逻辑,相对于go协程,占用资源更多;
-
系统更加稳定,引入自动化工具检查预热数据,监控报警机制,修改策略线下检查机制,能保障系统稳定升级,减少线上出错率;
Q&A
Q:课前预热直播间数据为什么选择先写缓存,然后在通过mq异步落db呢?
A: 因为预热的过程是异步多台机器单机进程并行预热,进程中通过协程并发处理流程预热,为了预热提速;
如果直接写db, 然后在更新缓存,因为mysql是主从架构,预热是写多读多场景, 写多是因为预热数据初始写入数据库,读多是因为数据入库之后,会通知接口缓存模块去请求读db接口缓存数据(接口数据为空,不会存储,都为insert操作成功之后,才通知接口缓存模块,不会出现不一致的情况);读请求可以通过多个从来分担,但是写的话都是在主上,分库分表都是在单实例上, 单机抗大量写请求会成为整体预热的瓶颈;
如果直接写入缓存,然后mq异步落db 的形式可以充分利用缓存比磁盘读写io速度快的优势,缓存的实例部署是以proxy的形式分布式部署,可以对slot分片进行读写 扩容,分散读写压力;不会成为预热的瓶颈;(以前是无中心化的形式通过业务使用方一致性hash 来访问分布式缓存slot分片, 后面改成proxy中心化的方式,统一管理方便运维,业务使用方直接通过redis协议请求,无需关心分片操作)
通过mq异步落db,mq是通过push的方式直接发给后端接口入库的,降低mq的push的并发窗口,可以减少push频率,降低后端接口的请求量,但是会消费变慢,为了加快操作,对发送给mq的数据进行buffer 处理,批量发送,通过后端接口批量写入数据库,减少网络i/o, 提高写入吞吐量;
Q: 预热过程中,如果有上线,预热中断了,怎么处理呢?
A: 在预热的时候会上报预热的启动状态, 旁路脚本每半小时会检查一次预热的启动状态,如果一直处于运行中,则报警,根据阈值判断(比如报名人数估算处预热时间,报警次数) 触发自动预热重新预热上;预热监控后台也提供了手动触发预热;
这里没有像数据库那样使用WAL机制(进程crash后,缓存中的数据没有了,可以通过WAL日志找回),业务场景可以回溯数据,按章节或者直播间重新预热
Q: 组织树的作用是什么呢?
A: 将业务组织关系进行解偶,如果接入其他业务组织关系,只需要提供原始数据,就可以服务用课中的组织关系能力,提供课中组织关系下的直播互动;课中组织树是可以动态扩展的,满足课中报名人数突增的情况;
Q: 后续会提供用户维度的组织树操作接口吗?
A: 现在是通过采集其他平台的组织数据进行一份转化生成提供给课中直播互动使用的组织树,后续提供相关的基础读写接口来初始/更改预热数据,使用方只需要在构造业务组织结构的时候调用写入缓存
Q: 现在业务数据量有多大?
A: 系统是按照最大量估算的,一天大概总共 2w * 4M = 78GB数据可能需要课前预热 (报名学生2w*3w =6亿)
Q: 是否考虑用工作流任务调度的方式处理呢?
A: 正在考虑中,现在方式是后台绑定好预热策略,把策略发到消息队列里,然后通过消息队列负载均衡推送给预热任务执行;
后面会优化成工作流任务调度的方式,将整个预热流程拆分成可单独执行的任务,然后生成一个DAG工作流,通过任务调度模块,分发到预热执行机器上执行,入度为0的任务开始启动执行