用 C 从头开始编写 SQLite 克隆;
注:用chatGPT翻译+人工稍微整理下,耗时一个多小时整理完成,使用这个简单的db from scratch试下效果, 代码简单;现在高中甚至初中生有在学这个。
原文地址: https://cstack.github.io/db_tutorial/
数据库如何工作?
- 数据以什么格式保存?(在内存和磁盘上)
- 它什么时候从内存移动到磁盘?
- 为什么一张表只能有一个主键?
- 回滚事务如何进行?
- 索引是如何格式化的?
- 全表扫描何时以及如何发生?
- 准备好的语句以什么格式保存?
简而言之,数据库是如何工作的?
为了理解,我正在用 C 从头开始构建sqlite的克隆,并且我将记录我的过程。
“我无法创造的东西,我就不明白。What I cannot create, I do not understand” ——理查德·费曼
第一部分 - 简介和设置REPL
作为一名网页开发者,我每天都在工作中使用关系数据库,但它们对我来说就像一个黑匣子。我有一些问题:
- 数据保存在什么格式中?(在内存和磁盘上)
- 何时将数据从内存移动到磁盘?
- 为什么每个表只能有一个主键?
- 事务回滚是如何工作的?
- 索引是如何格式化的?
- 何时以及如何进行全表扫描?
- 准备好的语句保存在什么格式中?
换句话说,数据库是如何工作的呢?
为了弄清楚这些问题,我正在从零开始编写一个数据库。它的模型是基于SQLite的,因为它设计得很小,比MySQL或PostgreSQL少了一些特性,所以我更有希望能理解它。整个数据库存储在单个文件中!
Sqlite
在他们的网站上有很多关于sqlite内部的文档,而且我也有一本《SQLite数据库系统:设计与实现》的副本(看是否可以撸一遍,仅翻译,看sqlite具体版本源码了解细节)。
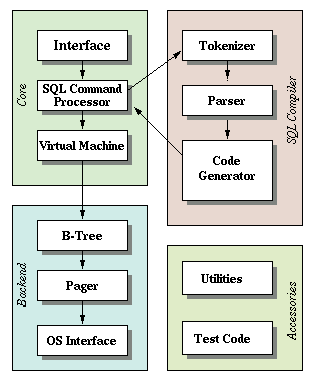
sqlite 架构 (https://www.sqlite.org/zipvfs/doc/trunk/www/howitworks.wiki)
一个查询需要通过一系列组件来检索或修改数据。前端包括:
- 分词器(tokenizer)
- 解析器(parser)
- 代码生成器(code generator)
前端的输入是一个 SQL 查询,输出是 SQLite 虚拟机的字节码(实质上是一个可以操作数据库的编译程序)。
后端包括:
- 虚拟机(virtual machine)
- B-树(B-tree)
- 页面管理器(pager)
- 操作系统接口(os interface)
虚拟机接受前端生成的字节码作为指令。然后,它可以对一个或多个表或索引执行操作,每个表或索引都存储在一个称为 B-树 的数据结构中。虚拟机实质上是针对字节码指令类型的一个大型开关语句。
每个B-树由许多节点组成,每个节点的长度为一个页面。B-树可以通过向页面管理器发出命令来从磁盘检索页面或将其保存回磁盘。
页面管理器接收读取或写入数据页面的命令。它负责在数据库文件中适当的偏移位置读取/写入数据。它还在内存中保持最近访问的页面的缓存,并确定何时需要将这些页面写回磁盘。
操作系统接口是一个根据 SQLite 编译的操作系统而不同的层。在本教程中,我不会支持多个平台。
千里之行始于足下,所以让我们从一些更简单的事情开始:创建一个简单的 REPL。
制作一个简单的 REPL
当你从命令行启动 SQLite 时,它会开始一个读取-执行-打印循环:
这段代码创建了一个简单的数据库 REPL(Read-Eval-Print Loop)。它包含了一些关键功能:
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt() { printf("db > "); }
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// Ignore trailing newline
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
这段代码创建了一个基本的交互式命令行界面,类似于 SQLite 的命令行界面。它能够读取用户输入,并检测特定的命令(如 .exit)以退出循环,否则会显示错误消息。这是一个很好的起点,接下来可以在此基础上逐步构建更多功能,实现数据库的基本交互。
让我们创建一个简单的REPL。
首先,我们需要一个无限循环的主函数,它会打印提示符,获取输入行,然后处理该输入行:
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
接下来,我们定义InputBuffer作为围绕我们需要存储以与 getline() 交互所需状态的小包装器。(稍后会详细解释)
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
接下来,print_prompt()用于向用户打印提示。我们在读取每行输入之前都会这样做。
void print_prompt() { printf("db > "); }
要读取一行输入,我们使用 getline():
ssize_t getline(char **lineptr, size_t *n, FILE *stream);
lineptr:指向我们用于指向包含读取行的缓冲区的变量的指针。如果设置为NULL,它将由getline进行分配,因此即使命令失败,用户也应该释放它。n:指向我们用于保存分配缓冲区大小的变量的指针。stream:要从中读取的输入流。我们将从标准输入读取。
返回值:读取的字节数,可能小于缓冲区的大小。
我们告诉 getline 将读取的行存储在 input_buffer->buffer 中,并将分配缓冲区的大小存储在 input_buffer->buffer_length 中。我们将返回值存储在 input_buffer->input_length 中。
buffer 最初为空,因此 getline 分配足够的内存来存储输入行,并使 buffer 指向它。
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// 忽略行尾的换行符
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
接下来,我们需要定义一个函数来释放为 InputBuffer * 实例和该结构的 buffer 元素分配的内存(getline 在 read_input 中为 input_buffer->buffer 分配内存)。
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
最后,我们解析并执行命令。目前只有一个可识别的命令:.exit,用于终止程序。否则,我们会打印错误消息并继续循环。
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
让我们试试看!
~ ./db
db > .tables
Unrecognized command '.tables'.
db > .exit
~
好了,我们有一个工作的REPL。在下一部分中,我们将开始开发我们的命令语言。与此同时,以下是本节的整个程序:
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt() { printf("db > "); }
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// 忽略行尾的换行符
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}
第二部分 - 世界上最简单的SQL编译器和虚拟机
我们正在制作一个 SQLite 的克隆版本。SQLite 的“前端”是一个 SQL 编译器,它解析字符串并输出称为字节码的内部表示形式。
这个字节码被传递给虚拟机,然后由虚拟机执行。
将任务分成两个步骤有几个优点:
- 减少了每个部分的复杂性(例如,虚拟机不需要担心语法错误)
- 允许编译常见查询一次,并缓存字节码以提高性能
有了这个想法,让我们重构我们的 main 函数,并在此过程中支持两个新关键字:
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
}
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ execute_statement(&statement);
+ printf("Executed.\n");
}
}
像 .exit 这样的非 SQL 语句被称为“元命令”。它们都以点号开头,所以我们检查它们并在一个单独的函数中处理它们。
接下来,我们添加了一个步骤,将输入行转换为我们内部的语句表示形式。这是我们 SQLite 前端的简单版本。
最后,我们将准备好的语句传递给 execute_statement。这个函数最终会成为我们的虚拟机。
两个新函数的返回值都是枚举,表示成功或失败:
typedef enum {
META_COMMAND_SUCCESS,
META_COMMAND_UNRECOGNIZED_COMMAND
} MetaCommandResult;
typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT } PrepareResult;
“Unrecognized statement”?这似乎有点像异常。我不太喜欢使用异常(而且C甚至不支持异常),所以我在尽可能的地方使用枚举结果代码。如果我的switch语句没有处理枚举的某个成员,C编译器会报错,所以我们可以更有信心地处理函数的每个结果。预计将来会添加更多的结果代码。
do_meta_command 只是现有功能的一个包装器,为更多的命令留出空间:
MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
}
我们的“准备语句”现在只包含一个具有两个可能值的枚举。随着我们允许语句中包含参数,它将包含更多数据:
typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
typedef struct {
StatementType type;
} Statement;
prepare_statement(我们的“SQL编译器”)现在不理解SQL。事实上,它只理解两个单词:
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
return PREPARE_SUCCESS;
}
if (strcmp(input_buffer->buffer, "select") == 0) {
statement->type = STATEMENT_SELECT;
return PREPARE_SUCCESS;
}
return PREPARE_UNRECOGNIZED_STATEMENT;
}
请注意,我们对“insert”使用了 strncmp,因为“insert”关键字后面会跟着数据。(例如 insert 1 cstack foo@bar.com)
最后,execute_statement 包含一些存根:
void execute_statement(Statement* statement) {
switch (statement->type) {
case (STATEMENT_INSERT):
printf("This is where we would do an insert.\n");
break;
case (STATEMENT_SELECT):
printf("This is where we would do a select.\n");
break;
}
}
请注意,它不返回任何错误代码,因为目前还没有可能出错的地方。
通过这些重构,我们现在可以识别两个新的关键字!
~ ./db
db > insert foo bar
This is where we would do an insert.
Executed.
db > delete foo
Unrecognized keyword at start of 'delete foo'.
db > select
This is where we would do a select.
Executed.
db > .tables
Unrecognized command '.tables'
db > .exit
~
我们的数据库框架正在成型……如果它能存储数据岂不是更好?在下一部分中,我们将实现 insert 和 select,创建世界上最糟糕的数据存储。在此期间,以下是此部分的整个差异:
@@ -10,6 +10,23 @@ struct InputBuffer_t {
} InputBuffer;
+typedef enum {
+ META_COMMAND_SUCCESS,
+ META_COMMAND_UNRECOGNIZED_COMMAND
+} MetaCommandResult;
+
+typedef enum { PREPARE_SUCCESS, PREPARE_UNRECOGNIZED_STATEMENT } PrepareResult;
+
+typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
+
+typedef struct {
+ StatementType type;
+} Statement;
+
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
@@ -40,17 +57,67 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
+ if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ close_input_buffer(input_buffer);
+ exit(EXIT_SUCCESS);
+ } else {
+ return META_COMMAND_UNRECOGNIZED_COMMAND;
+ }
+}
+
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ statement->type = STATEMENT_INSERT;
+ return PREPARE_SUCCESS;
+ }
+ if (strcmp(input_buffer->buffer, "select") == 0) {
+ statement->type = STATEMENT_SELECT;
+ return PREPARE_SUCCESS;
+ }
+
+ return PREPARE_UNRECOGNIZED_STATEMENT;
+}
+
+void execute_statement(Statement* statement) {
+ switch (statement->type) {
+ case (STATEMENT_INSERT):
+ printf("This is where we would do an insert.\n");
+ break;
+ case (STATEMENT_SELECT):
+ printf("This is where we would do a select.\n");
+ break;
+ }
+}
+
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- close_input_buffer(input_buffer);
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
}
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ execute_statement(&statement);
+ printf("Executed.\n");
}
}
第三部分 - 内存中、追加方式、单表数据库
我们将通过在数据库上设置许多限制来以小范围开始。暂时,它将会:
- 支持两种操作:插入一行和打印所有行
- 仅存在于内存中(不会持久化到磁盘)
- 仅支持一个硬编码的表
我们的硬编码表将存储用户信息,结构如下:
| 列名 | 类型 |
|---|---|
| id | 整数 |
| username | 可变长度文本 |
| 可变长度文本 |
这是一个简单的模式,但它使我们能够支持多种数据类型和不同大小的文本数据类型。
这部分我们需要修改 prepare_statement 函数来解析参数:
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
int args_assigned = sscanf(
input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
statement->row_to_insert.username, statement->row_to_insert.email);
if (args_assigned < 3) {
return PREPARE_SYNTAX_ERROR;
}
return PREPARE_SUCCESS;
}
我们将解析的参数存储到语句对象内的新 Row 数据结构中:
#define COLUMN_USERNAME_SIZE 32
#define COLUMN_EMAIL_SIZE 255
typedef struct {
uint32_t id;
char username[COLUMN_USERNAME_SIZE];
char email[COLUMN_EMAIL_SIZE];
} Row;
typedef struct {
StatementType type;
Row row_to_insert; // 仅在插入语句中使用
} Statement;
接下来,我们需要将这些数据复制到表示表的某个数据结构中。SQLite 使用 B 树进行快速查找、插入和删除。我们将从简单的结构开始。就像 B 树一样,它将行分组到称为页面的内存块中,但是它们不会像树那样排列,而是像数组那样排列。
我的计划如下:
- 将行存储在称为页面的内存块中
- 每个页面存储尽可能多的行
- 行被序列化为与每个页面一起的紧凑表示形式
- 页面仅在需要时分配
- 保留一个指向页面的固定大小数组
首先,我们来定义行的紧凑表示形式:
#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
const uint32_t ID_SIZE = size_of_attribute(Row, id);
const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
const uint32_t ID_OFFSET = 0;
const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
这意味着序列化行的布局将如下所示:
| 列名 | 大小(字节) | 偏移量 |
|---|---|---|
| id | 4 | 0 |
| username | 32 | 4 |
| 255 | 36 | |
| 总计 | 291 |
我们还需要编写代码,将紧凑表示形式转换为原始行数据,以及从原始行数据转换回紧凑表示形式。
void serialize_row(Row* source, void* destination) {
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
}
void deserialize_row(void* source, Row* destination) {
memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
接下来是 Table 结构,它指向行的页面并跟踪行的数量:
const uint32_t PAGE_SIZE = 4096;
#define TABLE_MAX_PAGES 100
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
uint32_t num_rows;
void* pages[TABLE_MAX_PAGES];
} Table;
我将页面大小设置为4千字节,因为它与大多数计算机体系结构的虚拟内存系统中使用的页面大小相同。这意味着数据库中的一个页面对应于操作系统中使用的一个页面。操作系统会整体地将页面移入和移出内存,而不会将其拆分。
我设置了一个最大为100个的页面分配的任意限制。当我们转换为树结构时,我们数据库的最大大小仅受文件的最大大小限制。(尽管我们仍然限制了一次在内存中保留的页面数)
行不应该跨越页面边界。由于页面可能不会相邻存在于内存中,这个假设使得读取/写入行更容易。
至于在内存中为特定行读取/写入的位置,我们可以这样计算:
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
void* page = table->pages[page_num];
if (page == NULL) {
// 仅在访问页面时分配内存
page = table->pages[page_num] = malloc(PAGE_SIZE);
}
uint32_t row_offset = row_num % ROWS_PER
_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
现在我们可以修改 execute_statement 从我们的表结构中读写数据:
ExecuteResult execute_insert(Statement* statement, Table* table) {
if (table->num_rows >= TABLE_MAX_ROWS) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
serialize_row(row_to_insert, row_slot(table, table->num_rows));
table->num_rows += 1;
return EXECUTE_SUCCESS;
}
ExecuteResult execute_select(Statement* statement, Table* table) {
Row row;
for (uint32_t i = 0; i < table->num_rows; i++) {
deserialize_row(row_slot(table, i), &row);
print_row(&row);
}
return EXECUTE_SUCCESS;
}
ExecuteResult execute_statement(Statement* statement, Table* table) {
switch (statement->type) {
case (STATEMENT_INSERT):
return execute_insert(statement, table);
case (STATEMENT_SELECT):
return execute_select(statement, table);
}
}
最后,我们需要初始化表,创建相应的内存释放函数,并处理一些其他错误情况:
Table* new_table() {
Table* table = (Table*)malloc(sizeof(Table));
table->num_rows = 0;
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
table->pages[i] = NULL;
}
return table;
}
void free_table(Table* table) {
for (int i = 0; table->pages[i]; i++) {
free(table->pages[i]);
}
free(table);
}
int main(int argc, char* argv[]) {
Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
// ...
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
case (PREPARE_SYNTAX_ERROR):
printf("Syntax error. Could not parse statement.\n");
continue;
case (PREPARE_UNRECOGNIZED_STATEMENT):
printf("Unrecognized keyword at start of '%s'.\n",
input_buffer->buffer);
continue;
}
switch (execute_statement(&statement, table)) {
case (EXECUTE_SUCCESS):
printf("Executed.\n");
break;
case (EXECUTE_TABLE_FULL):
printf("Error: Table full.\n");
break;
}
}
}
这些修改后,我们可以实际在数据库中保存数据了!
~ ./db
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 bob bob@example.com
Executed.
db > select
(1, cstack, foo@bar.com)
(2, bob, bob@example.com)
Executed.
db > insert foo bar 1
Syntax error. Could not parse statement.
db > .exit
现在是写一些测试的好时机,有几个原因:
- 我们打算大幅改变存储表的数据结构,测试可以捕捉到回归问题。
- 还有一些边缘案例我们尚未手动测试(例如,填满表)
我们将在下一部分解决这些问题。现在,这是本部分的全部修改内容。
@@ -2,6 +2,7 @@
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
+#include <stdint.h>
typedef struct {
char* buffer;
@@ -10,6 +11,105 @@ typedef struct {
} InputBuffer;
+typedef enum { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL } ExecuteResult;
+
+typedef enum {
+ META_COMMAND_SUCCESS,
+ META_COMMAND_UNRECOGNIZED_COMMAND
+} MetaCommandResult;
+
+typedef enum {
+ PREPARE_SUCCESS,
+ PREPARE_SYNTAX_ERROR,
+ PREPARE_UNRECOGNIZED_STATEMENT
+ } PrepareResult;
+
+typedef enum { STATEMENT_INSERT, STATEMENT_SELECT } StatementType;
+
+#define COLUMN_USERNAME_SIZE 32
+#define COLUMN_EMAIL_SIZE 255
+typedef struct {
+ uint32_t id;
+ char username[COLUMN_USERNAME_SIZE];
+ char email[COLUMN_EMAIL_SIZE];
+} Row;
+
+typedef struct {
+ StatementType type;
+ Row row_to_insert; //only used by insert statement
+} Statement;
+
+#define size_of_attribute(Struct, Attribute) sizeof(((Struct*)0)->Attribute)
+
+const uint32_t ID_SIZE = size_of_attribute(Row, id);
+const uint32_t USERNAME_SIZE = size_of_attribute(Row, username);
+const uint32_t EMAIL_SIZE = size_of_attribute(Row, email);
+const uint32_t ID_OFFSET = 0;
+const uint32_t USERNAME_OFFSET = ID_OFFSET + ID_SIZE;
+const uint32_t EMAIL_OFFSET = USERNAME_OFFSET + USERNAME_SIZE;
+const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
+
+const uint32_t PAGE_SIZE = 4096;
+#define TABLE_MAX_PAGES 100
+const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
+const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+
+typedef struct {
+ uint32_t num_rows;
+ void* pages[TABLE_MAX_PAGES];
+} Table;
+
+void print_row(Row* row) {
+ printf("(%d, %s, %s)\n", row->id, row->username, row->email);
+}
+
+void serialize_row(Row* source, void* destination) {
+ memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
+ memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
+ memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+}
+
+void deserialize_row(void *source, Row* destination) {
+ memcpy(&(destination->id), source + ID_OFFSET, ID_SIZE);
+ memcpy(&(destination->username), source + USERNAME_OFFSET, USERNAME_SIZE);
+ memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
+}
+
+void* row_slot(Table* table, uint32_t row_num) {
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = table->pages[page_num];
+ if (page == NULL) {
+ // Allocate memory only when we try to access page
+ page = table->pages[page_num] = malloc(PAGE_SIZE);
+ }
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+Table* new_table() {
+ Table* table = (Table*)malloc(sizeof(Table));
+ table->num_rows = 0;
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ table->pages[i] = NULL;
+ }
+ return table;
+}
+
+void free_table(Table* table) {
+ for (int i = 0; table->pages[i]; i++) {
+ free(table->pages[i]);
+ }
+ free(table);
+}
+
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
@@ -40,17 +140,105 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
+ if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ close_input_buffer(input_buffer);
+ free_table(table);
+ exit(EXIT_SUCCESS);
+ } else {
+ return META_COMMAND_UNRECOGNIZED_COMMAND;
+ }
+}
+
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ statement->type = STATEMENT_INSERT;
+ int args_assigned = sscanf(
+ input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
+ statement->row_to_insert.username, statement->row_to_insert.email
+ );
+ if (args_assigned < 3) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+ return PREPARE_SUCCESS;
+ }
+ if (strcmp(input_buffer->buffer, "select") == 0) {
+ statement->type = STATEMENT_SELECT;
+ return PREPARE_SUCCESS;
+ }
+
+ return PREPARE_UNRECOGNIZED_STATEMENT;
+}
+
+ExecuteResult execute_insert(Statement* statement, Table* table) {
+ if (table->num_rows >= TABLE_MAX_ROWS) {
+ return EXECUTE_TABLE_FULL;
+ }
+
+ Row* row_to_insert = &(statement->row_to_insert);
+
+ serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ table->num_rows += 1;
+
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_select(Statement* statement, Table* table) {
+ Row row;
+ for (uint32_t i = 0; i < table->num_rows; i++) {
+ deserialize_row(row_slot(table, i), &row);
+ print_row(&row);
+ }
+ return EXECUTE_SUCCESS;
+}
+
+ExecuteResult execute_statement(Statement* statement, Table *table) {
+ switch (statement->type) {
+ case (STATEMENT_INSERT):
+ return execute_insert(statement, table);
+ case (STATEMENT_SELECT):
+ return execute_select(statement, table);
+ }
+}
+
int main(int argc, char* argv[]) {
+ Table* table = new_table();
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
- if (strcmp(input_buffer->buffer, ".exit") == 0) {
- close_input_buffer(input_buffer);
- exit(EXIT_SUCCESS);
- } else {
- printf("Unrecognized command '%s'.\n", input_buffer->buffer);
+ if (input_buffer->buffer[0] == '.') {
+ switch (do_meta_command(input_buffer, table)) {
+ case (META_COMMAND_SUCCESS):
+ continue;
+ case (META_COMMAND_UNRECOGNIZED_COMMAND):
+ printf("Unrecognized command '%s'\n", input_buffer->buffer);
+ continue;
+ }
+ }
+
+ Statement statement;
+ switch (prepare_statement(input_buffer, &statement)) {
+ case (PREPARE_SUCCESS):
+ break;
+ case (PREPARE_SYNTAX_ERROR):
+ printf("Syntax error. Could not parse statement.\n");
+ continue;
+ case (PREPARE_UNRECOGNIZED_STATEMENT):
+ printf("Unrecognized keyword at start of '%s'.\n",
+ input_buffer->buffer);
+ continue;
+ }
+
+ switch (execute_statement(&statement, table)) {
+ case (EXECUTE_SUCCESS):
+ printf("Executed.\n");
+ break;
+ case (EXECUTE_TABLE_FULL):
+ printf("Error: Table full.\n");
+ break;
}
}
}
第四部分 - 我们的第一个测试(Bug)
我们已经能够向数据库中插入行并打印所有行了。让我们花点时间来测试我们到目前为止做得怎么样。
我将使用 rspec 来编写我的测试,因为我对它比较熟悉,而且语法相对易读。
我将定义一个简短的辅助函数来向我们的数据库程序发送一系列命令,然后对输出进行断言:
describe 'database' do
def run_script(commands)
raw_output = nil
IO.popen("./db", "r+") do |pipe|
commands.each do |command|
pipe.puts command
end
pipe.close_write
# Read entire output
raw_output = pipe.gets(nil)
end
raw_output.split("\n")
end
it 'inserts and retrieves a row' do
result = run_script([
"insert 1 user1 person1@example.com",
"select",
".exit",
])
expect(result).to match_array([
"db > Executed.",
"db > (1, user1, person1@example.com)",
"Executed.",
"db > ",
])
end
end
这个简单的测试确保我们得到了我们放入的内容。而且确实通过了:
bundle exec rspec
.
Finished in 0.00871 seconds (files took 0.09506 seconds to load)
1 example, 0 failures
现在可以测试向数据库插入大量行:
it 'prints error message when table is full' do
script = (1..1401).map do |i|
"insert #{i} user#{i} person#{i}@example.com"
end
script << ".exit"
result = run_script(script)
expect(result[-2]).to eq('db > Error: Table full.')
end
再次运行测试…
bundle exec rspec
..
Finished in 0.01553 seconds (files took 0.08156 seconds to load)
2 examples, 0 failures
太棒了,成功了!我们的数据库现在可以容纳1400行,因为我们将最大页面数设置为100,并且一页可以容纳14行。
我们可能没有正确处理存储文本字段。可以通过以下示例轻松进行测试:
it 'allows inserting strings that are the maximum length' do
long_username = "a"*32
long_email = "a"*255
script = [
"insert 1 #{long_username} #{long_email}",
"select",
".exit",
]
result = run_script(script)
expect(result).to match_array([
"db > Executed.",
"db > (1, #{long_username}, #{long_email})",
"Executed.",
"db > ",
])
end
测试失败了!
Failures:
1) database allows inserting strings that are the maximum length
Failure/Error: raw_output.split("\n")
ArgumentError:
invalid byte sequence in UTF-8
# ./spec/main_spec.rb:14:in `split'
# ./spec/main_spec.rb:14:in `run_script'
# ./spec/main_spec.rb:48:in `block (2 levels) in <top (required)>'
我们试着自己测试一下,会发现在尝试打印出行时出现了一些奇怪的字符。(我缩写了长字符串):
db > insert 1 aaaaa... aaaaa...
Executed.
db > select
(1, aaaaa...aaa\�, aaaaa...aaa\�)
Executed.
db >
发生了什么?如果您查看我们对“Row”的定义,我们为用户名准确分配了32字节,为电子邮件准确分配了255字节。但是,C字符串应该以空字符结尾,而我们没有为其分配空间。解决方法是多分配一个字节:
const uint32_t COLUMN_EMAIL_SIZE = 255;
typedef struct {
uint32_t id;
- char username[COLUMN_USERNAME_SIZE];
- char email[COLUMN_EMAIL_SIZE];
+ char username[COLUMN_USERNAME_SIZE + 1];
+ char email[COLUMN_EMAIL_SIZE + 1];
} Row;
确实解决了问题:
bundle exec rspec
...
Finished in 0.0188 seconds (files took 0.08516 seconds to load)
3 examples, 0 failures
我们不应该允许插入长度超过列大小的用户名或电子邮件。对此的规范如下:
it 'prints error message if strings are too long' do
long_username = "a"*33
long_email = "a"*256
script = [
"insert 1 #{long_username} #{long_email}",
"select",
".exit",
]
result = run_script(script)
expect(result).to match_array([
"db > String is too long.",
"db > Executed.",
"db > ",
])
end
为了做到这一点,我们需要升级我们的解析器。提醒一下,我们目前正在使用scanf():
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
statement->type = STATEMENT_INSERT;
int args_assigned = sscanf(
input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
statement->row_to_insert.username, statement->row_to_insert.email);
if (args_assigned < 3) {
return PREPARE_SYNTAX_ERROR;
}
return PREPARE_SUCCESS;
}
但是scanf存在一些缺点。如果它读取的字符串大于其读入的缓冲区,它将导致缓冲区溢出,并开始向意外位置写入。我们希望在将其复制到Row结构之前检查每个字符串的长度。为了做到这一点,我们需要通过空格对输入进行划分。
我将使用strtok()来完成这个过程。如果您亲眼目睹它的运行,可能更容易理解:
+PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
+ statement->type = STATEMENT_INSERT;
+
+ char* keyword = strtok(input_buffer->buffer, " ");
+ char* id_string = strtok(NULL, " ");
+ char* username = strtok(NULL, " ");
+ char* email = strtok(NULL, " ");
+
+ if (id_string == NULL || username == NULL || email == NULL) {
+ return PREPARE_SYNTAX_ERROR;
+ }
+
+ int id = atoi(id_string);
+ if (strlen(username) > COLUMN_USERNAME_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+ if (strlen(email) > COLUMN_EMAIL_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+
+ statement->row_to_insert.id = id;
+ strcpy(statement->row_to_insert.username, username);
+ strcpy(statement->row_to_insert.email, email);
+
+ return PREPARE_SUCCESS;
+}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ return prepare_insert(input_buffer, statement);
}
对输入缓冲区连续调用strtok函数,通过插入空字符来将其分成子字符串(在我们的情况下是空格作为分隔符)。它返回子字符串的起始指针。
我们可以对每个文本值调用strlen()来查看其是否太长。
我们可以像处理其他错误代码一样处理错误:
enum PrepareResult_t {
PREPARE_SUCCESS,
+ PREPARE_STRING_TOO_LONG,
PREPARE_SYNTAX_ERROR,
PREPARE_UNRECOGNIZED_STATEMENT
};
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_STRING_TOO_LONG):
+ printf("String is too long.\n");
+ continue;
case (PREPARE_SYNTAX_ERROR):
printf("Syntax error. Could not parse statement.\n");
continue;
这样我们的测试就通过了:
bundle exec rspec
....
Finished in 0.02284 seconds (files took 0.116 seconds to load)
4 examples, 0 failures
在这里,我们也可以处理一个额外的错误情况:
it 'prints an error message if id is negative' do
script = [
"insert -1 cstack foo@bar.com",
"select",
".exit",
]
result = run_script(script)
expect(result).to match_array([
"db > ID must be positive.",
"db > Executed.",
"db > ",
])
end
enum PrepareResult_t {
PREPARE_SUCCESS,
+ PREPARE_NEGATIVE_ID,
PREPARE_STRING_TOO_LONG,
PREPARE_SYNTAX_ERROR,
PREPARE_UNRECOGNIZED_STATEMENT
@@ -148,9 +147,6 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
}
int id = atoi(id_string);
+ if (id < 0) {
+ return PREPARE_NEGATIVE_ID;
+ }
if (strlen(username) > COLUMN_USERNAME_SIZE) {
return PREPARE_STRING_TOO_LONG;
}
@@ -230,9 +226,6 @@ int main(int argc, char* argv[]) {
switch (prepare_statement(input_buffer, &statement)) {
case (PREPARE_SUCCESS):
break;
+ case (PREPARE_NEGATIVE_ID):
+ printf("ID must be positive.\n");
+ continue;
case (PREPARE_STRING_TOO_LONG):
printf("String is too long.\n");
continue;
好了,现在测试足够了。接下来是一个非常重要的特性:持久性!我们将把数据库保存到文件中,然后再读取出来。
接下来会很棒。
这是本部分的完整差异:
@@ -22,6 +22,8 @@
enum PrepareResult_t {
PREPARE_SUCCESS,
+ PREPARE_NEGATIVE_ID,
+ PREPARE_STRING_TOO_LONG,
PREPARE_SYNTAX_ERROR,
PREPARE_UNRECOGNIZED_STATEMENT
};
@@ -34,8 +36,8 @@
#define COLUMN_EMAIL_SIZE 255
typedef struct {
uint32_t id;
- char username[COLUMN_USERNAME_SIZE];
- char email[COLUMN_EMAIL_SIZE];
+ char username[COLUMN_USERNAME_SIZE + 1];
+ char email[COLUMN_EMAIL_SIZE + 1];
} Row;
@@ -150,18 +152,40 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
}
}
-PrepareResult prepare_statement(InputBuffer* input_buffer,
- Statement* statement) {
- if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
statement->type = STATEMENT_INSERT;
- int args_assigned = sscanf(
- input_buffer->buffer, "insert %d %s %s", &(statement->row_to_insert.id),
- statement->row_to_insert.username, statement->row_to_insert.email
- );
- if (args_assigned < 3) {
+
+ char* keyword = strtok(input_buffer->buffer, " ");
+ char* id_string = strtok(NULL, " ");
+ char* username = strtok(NULL, " ");
+ char* email = strtok(NULL, " ");
+
+ if (id_string == NULL || username == NULL || email == NULL) {
return PREPARE_SYNTAX_ERROR;
}
+
+ int id = atoi(id_string);
+ if (id < 0) {
+ return PREPARE_NEGATIVE_ID;
+ }
+ if (strlen(username) > COLUMN_USERNAME_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+ if (strlen(email) > COLUMN_EMAIL_SIZE) {
+ return PREPARE_STRING_TOO_LONG;
+ }
+
+ statement->row_to_insert.id = id;
+ strcpy(statement->row_to_insert.username, username);
+ strcpy(statement->row_to_insert.email, email);
+
+ return PREPARE_SUCCESS;
+
+}
+PrepareResult prepare_statement(InputBuffer* input_buffer,
+ Statement* statement) {
+ if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
+ return prepare_insert(input_buffer, statement);
}
并且我们增加了测试:
+describe 'database' do
+ def run_script(commands)
+ raw_output = nil
+ IO.popen("./db", "r+") do |pipe|
+ commands.each do |command|
+ pipe.puts command
+ end
+
+ pipe.close_write
+
+ # Read entire output
+ raw_output = pipe.gets(nil)
+ end
+ raw_output.split("\n")
+ end
+
+ it 'inserts and retrieves a row' do
+ result = run_script([
+ "insert 1 user1 person1@example.com",
+ "select",
+ ".exit",
+ ])
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > (1, user1, person1@example.com)",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
+ it 'prints error message when table is full' do
+ script = (1..1401).map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".exit"
+ result = run_script(script)
+ expect(result[-2]).to eq('db > Error: Table full.')
+ end
+
+ it 'allows inserting strings that are the maximum length' do
+ long_username = "a"*32
+ long_email = "a"*255
+ script = [
+ "insert 1 #{long_username} #{long_email}",
+ "select",
+ ".exit",
+ ]
+ result = run_script(script)
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > (1, #{long_username}, #{long_email})",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
+ it 'prints error message if strings are too long' do
+ long_username = "a"*33
+ long_email = "a"*256
+ script = [
+ "insert 1 #{long_username} #{long_email}",
+ "select",
+ ".exit",
+ ]
+ result = run_script(script)
+ expect(result).to match_array([
+ "db > String is too long.",
+ "db > Executed.",
+ "db > ",
+ ])
+ end
+
+ it 'prints an error message if id is negative' do
+ script = [
+ "insert -1 cstack foo@bar.com",
+ "select",
+ ".exit",
+ ]
+ result = run_script(script)
+ expect(result).to match_array([
+ "db > ID must be positive.",
+ "db > Executed.",
+ "db > ",
+ ])
+ end
+end
第五部分 - 持久化到磁盘
“世界上没有什么可以取代坚持。Nothing in the world can take the place of persistence.” - 卡尔文·柯立芝
我们的数据库允许你插入记录并将其读取回来,但前提是只要你保持程序运行。如果你关闭程序然后重新启动,所有记录都会消失。下面是我们想要的行为规范:
it 'keeps data after closing connection' do
result1 = run_script([
"insert 1 user1 person1@example.com",
".exit",
])
expect(result1).to match_array([
"db > Executed.",
"db > ",
])
result2 = run_script([
"select",
".exit",
])
expect(result2).to match_array([
"db > (1, user1, person1@example.com)",
"Executed.",
"db > ",
])
end
和 SQLite 一样,我们将通过将整个数据库保存到文件来保留记录。
我们已经通过将行序列化为页面大小的内存块来为此做好了准备。要添加持久性,我们可以简单地将这些内存块写入文件,并在下次启动程序时将其读入内存。
为了简化操作,我们将创建一个名为“Pager”的抽象层。我们向Pager请求第x页,Pager会返回一个内存块。它首先查看其缓存。如果缓存未命中,它将从磁盘中复制数据到内存中(通过读取数据库文件)。
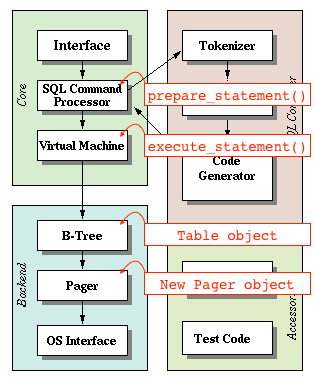
Pager访问页缓存和文件。Table对象通过Pager发送页面请求:
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];gfvccddddddd
+} Pager;
+
typedef struct {
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
uint32_t num_rows;
} Table;
我将new_table()重命名为db_open(),因为它现在具有打开数据库连接的效果。通过打开连接,我指的是:
- 打开数据库文件
- 初始化页管理器数据结构
- 初始化表数据结构
-Table* new_table() {
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+ table->pager = pager;
+ table->num_rows = num_rows;
return table;
}
db_open() 调用了 pager_open() 方法,该方法打开数据库文件并跟踪其大小。它还将页面缓存初始化为全部为 NULL。
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ pager->pages[i] = NULL;
+ }
+
+ return pager;
+}
根据新的抽象,我们将获取页面的逻辑移到单独的方法中:
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void* page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void* page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
get_page() 方法包含处理缓存未命中的逻辑。我们假设页面按顺序保存在数据库文件中:第0页位于偏移量0处,第1页位于偏移量4096处,第2页位于偏移量8192处,依此类推。如果请求的页面超出文件范围,我们知道它应该是空白的,因此我们只需分配一些内存并返回它。稍后将缓存刷新到磁盘时,页面将被添加到文件中。
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
暂时,我们会等到用户关闭数据库连接之后再将缓存刷新到磁盘上。当用户退出时,我们将调用一个名为 db_close() 的新方法,其中:
- 将页缓存刷新到磁盘上
- 关闭数据库文件
- 释放 Pager 和 Table 数据结构的内存
void db_close(Table* table) {
Pager* pager = table->pager;
uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
for (uint32_t i = 0; i < num_full_pages; i++) {
if (pager->pages[i] == NULL) {
continue;
}
pager_flush(pager, i, PAGE_SIZE);
free(pager->pages[i]);
pager->pages[i] = NULL;
}
// There may be a partial page to write to the end of the file
// This should not be needed after we switch to a B-tree
uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
if (num_additional_rows > 0) {
uint32_t page_num = num_full_pages;
if (pager->pages[page_num] != NULL) {
pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
free(pager->pages[page_num]);
pager->pages[page_num] = NULL;
}
}
int result = close(pager->file_descriptor);
if (result == -1) {
printf("Error closing db file.\n");
exit(EXIT_FAILURE);
}
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
void* page = pager->pages[i];
if (page) {
free(page);
pager->pages[i] = NULL;
}
}
free(pager);
free(table);
}
-MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
在我们当前的设计中,文件的长度编码了数据库中的行数,因此我们需要在文件末尾写入一个部分页面。这就是为什么 pager_flush() 需要接收页面编号和大小两个参数。这并不是最佳的设计,但在我们开始实现 B 树时,这个设计会很快消失。
void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page\n");
exit(EXIT_FAILURE);
}
off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
if (offset == -1) {
printf("Error seeking: %d\n", errno);
exit(EXIT_FAILURE);
}
ssize_t bytes_written =
write(pager->file_descriptor, pager->pages[page_num], size);
if (bytes_written == -1) {
printf("Error writing: %d\n", errno);
exit(EXIT_FAILURE);
}
}
最后,我们需要将文件名作为命令行参数传递。不要忘记还要将额外的参数添加到 do_meta_command 中:
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
- switch (do_meta_command(input_buffer)) {
+ switch (do_meta_command(input_buffer, table)) {
有了这些更改,我们可以关闭然后重新打开数据库,我们的记录依然存在!
~ ./db mydb.db
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 voltorb volty@example.com
Executed.
db > .exit
~
~ ./db mydb.db
db > select
(1, cstack, foo@bar.com)
(2, voltorb, volty@example.com)
Executed.
db > .exit
~
为了更有趣,让我们查看一下 mydb.db,看看我们的数据是如何存储的。我会使用 vim 作为十六进制编辑器来查看文件的内存布局:
vim mydb.db
:%!xxd
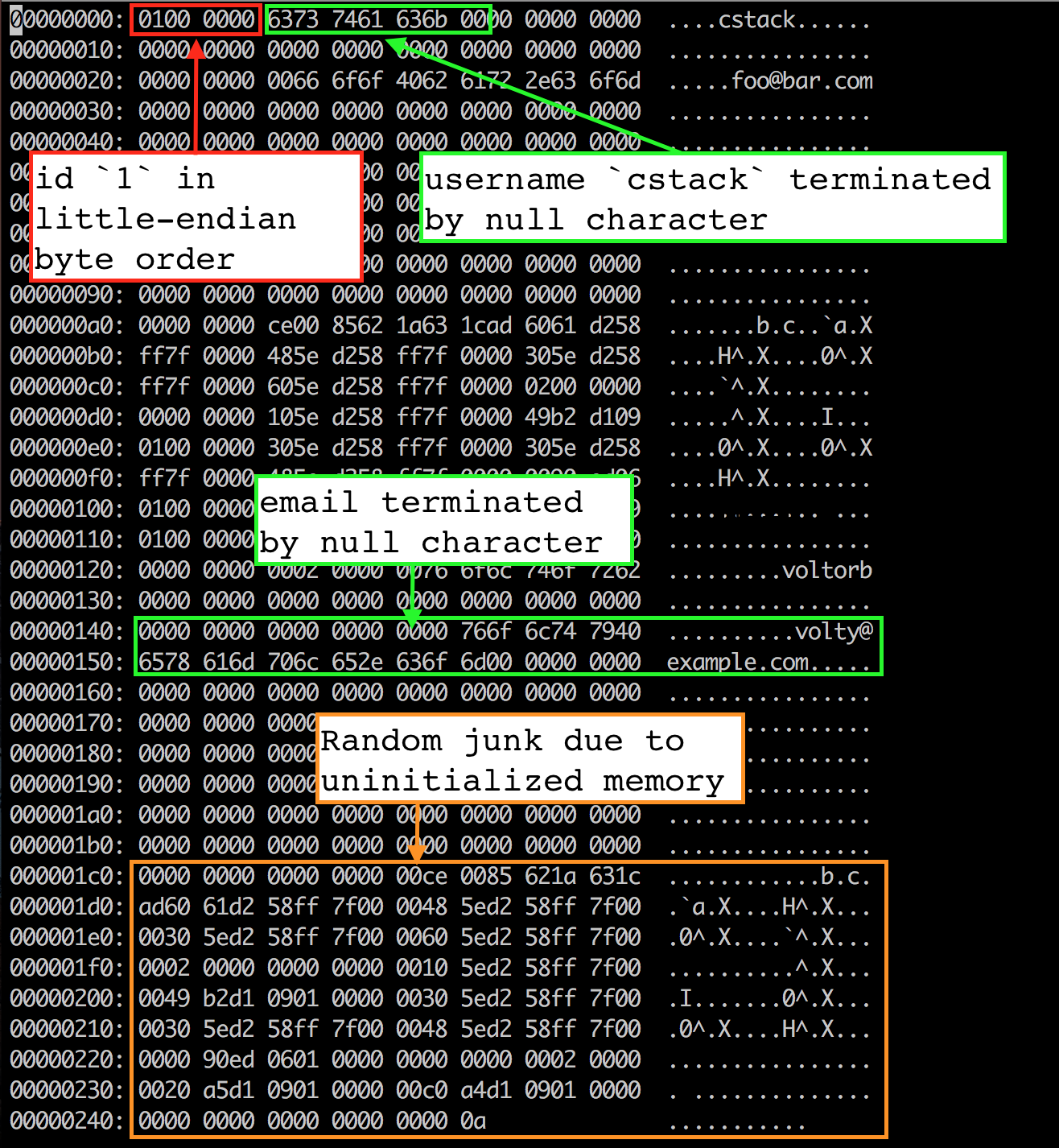
前四个字节是第一行的 ID(4 个字节因为我们存储了一个 uint32_t)。它以小端字节序存储,因此最低有效字节排在前面(01),后面是高位字节(00 00 00)。我们使用 memcpy() 将字节从 Row 结构体复制到页面缓存,这意味着结构体在内存中按照小端字节序排列。这是我编译程序时所用机器的特性。如果我们想在我的机器上写一个数据库文件,然后在大端序的机器上读取它,我们就需要更改我们的 serialize_row() 和 deserialize_row() 方法,始终以相同的顺序存储和读取字节。
接下来的 33 个字节以空字符结尾存储了用户名。显然,“cstack” 的 ASCII 十六进制是 63 73 74 61 63 6b,后跟一个空字符(00)。其余的 33 个字节未被使用。
接下来的 256 个字节以同样的方式存储了邮箱。在终止空字符后面,我们可以看到一些随机的垃圾值。这很可能是由于我们 Row 结构体中未初始化的内存。我们将整个 256 字节的邮箱缓冲区复制到文件中,包括字符串结束后的任何字节。当我们分配该结构体时,内存中存在的任何值都会保留下来。但由于我们使用了终止空字符,它对行为没有影响。
注意:如果我们想确保所有字节都被初始化,可以在 serialize_row 中将 username 和 email 字段的复制改为 strncpy,如下所示:
void serialize_row(Row* source, void* destination) {
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
- memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
- memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+ strncpy(destination + USERNAME_OFFSET, source->username, USERNAME_SIZE);
+ strncpy(destination + EMAIL_OFFSET, source->email, EMAIL_SIZE);
}
结论
好了!我们实现了持久性。这不是最理想的。例如,如果你在没有输入 .exit 的情况下终止程序,你会丢失更改。此外,我们将所有页面写回磁盘,即使这些页面自从从磁盘读取以来没有发生变化。这些是我们可以稍后解决的问题。
下次我们将介绍游标,这应该会更容易地实现 B 树。
在那之前!
完整的变更
+#include <errno.h>
+#include <fcntl.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
+#include <unistd.h>
struct InputBuffer_t {
char* buffer;
@@ -62,9 +65,16 @@ const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
uint32_t num_rows;
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
} Table;
@@ -84,32 +94,81 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
+
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void *page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
-Table* new_table() {
- Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
- table->pages[i] = NULL;
+ pager->pages[i] = NULL;
}
- return table;
+
+ return pager;
}
-void free_table(Table* table) {
- for (int i = 0; table->pages[i]; i++) {
- free(table->pages[i]);
- }
- free(table);
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
+ Table* table = malloc(sizeof(Table));
+ table->pager = pager;
+ table->num_rows = num_rows;
+
+ return table;
}
InputBuffer* new_input_buffer() {
@@ -142,10 +201,76 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE,
+ SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written = write(
+ pager->file_descriptor, pager->pages[page_num], size
+ );
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
+
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // There may be a partial page to write to the end of the file
+ // This should not be needed after we switch to a B-tree
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+
+ free(pager);
+ free(table);
+}
+
MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
- free_table(table);
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
@@ -182,6 +308,7 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
return PREPARE_SUCCESS;
}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
@@ -227,7 +354,14 @@ ExecuteResult execute_statement(Statement* statement, Table *table) {
}
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
以及我们测试的变更:
describe 'database' do
+ before do
+ `rm -rf test.db`
+ end
+
def run_script(commands)
raw_output = nil
- IO.popen("./db", "r+") do |pipe|
+ IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
pipe.puts command
end
@@ -28,6 +32,27 @@ describe 'database' do
])
end
+ it 'keeps data after closing connection' do
+ result1 = run_script([
+ "insert 1 user1 person1@example.com",
+ ".exit",
+ ])
+ expect(result1).to match_array([
+ "db > Executed.",
+ "db > ",
+ ])
+
+ result2 = run_script([
+ "select",
+ ".exit",
+ ])
+ expect(result2).to match_array([
+ "db > (1, user1, person1@example.com)",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
it 'prints error message when table is full' do
script = (1..1401).map do |i|
"insert #{i} user#{i} person#{i}@example.com"
第六部分 - 游标抽象
这部分应该比上一部分要短。我们只是进行一些重构,以便更容易开始B-Tree的实现。
我们将添加一个Cursor对象,代表表中的位置。您可能想要使用游标进行的操作包括:
- 在表的开头创建游标
- 在表的末尾创建游标
- 访问游标指向的行
- 将游标推进到下一行
这些是我们现在要实现的行为。稍后,我们还想:
- 删除游标指向的行
- 修改游标指向的行
- 在表中搜索给定ID,并创建指向该ID行的游标
话不多说,这是Cursor类型:
typedef struct {
Table* table;
uint32_t row_num;
bool end_of_table; // 表示最后一个元素之后的位置
} Cursor;
在我们当前的表数据结构中,唯一需要用于在表中标识位置的是行号。
游标还具有对其所属表的引用(因此我们的游标函数可以只将游标作为参数)。
最后,它有一个名为end_of_table的布尔值。这样我们就可以表示表末尾的位置(这是我们可能要插入行的位置)。
table_start()和table_end()创建新的游标:
Cursor* table_start(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
cursor->row_num = 0;
cursor->end_of_table = (table->num_rows == 0);
return cursor;
}
Cursor* table_end(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
cursor->row_num = table->num_rows;
cursor->end_of_table = true;
return cursor;
}
我们的row_slot()函数将变为cursor_value(),它返回指向游标描述位置的指针:
void* cursor_value(Cursor* cursor) {
uint32_t row_num = cursor->row_num;
uint32_t page_num = row_num / ROWS_PER_PAGE;
void* page = get_page(cursor->table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
在我们当前的表结构中推进游标就是简单地递增行号。在B-Tree中会更复杂一些。
void cursor_advance(Cursor* cursor) {
cursor->row_num += 1;
if (cursor->row_num >= cursor->table->num_rows) {
cursor->end_of_table = true;
}
}
最后,我们可以更改我们的“虚拟机”方法,以使用游标抽象。在插入行时,我们在表的末尾打开一个游标,写入该游标位置,然后关闭游标。
Row* row_to_insert = &(statement->row_to_insert);
Cursor* cursor = table_end(table);
serialize_row(row_to_insert, cursor_value(cursor));
table->num_rows += 1;
free(cursor);
return EXECUTE_SUCCESS;
在选择表中的所有行时,我们在表的开头打开一个游标,打印行,然后将游标推进到下一行。重复直到达到表的末尾。
ExecuteResult execute_select(Statement* statement, Table* table) {
Cursor* cursor = table_start(table);
Row row;
while (!(cursor->end_of_table)) {
deserialize_row(cursor_value(cursor), &row);
print_row(&row);
cursor_advance(cursor);
}
free(cursor);
return EXECUTE_SUCCESS;
}
好了,就是这样!就像我说的,这是一个更短的重构,应该有助于我们将表数据结构重写为B-Tree。execute_select()和execute_insert()可以完全通过游标与表进行交互,而不假设表的存储方式。
以下是本部分的完整差异:
@@ -78,6 +78,13 @@ struct {
} Table;
+typedef struct {
+ Table* table;
+ uint32_t row_num;
+ bool end_of_table; // Indicates a position one past the last element
+} Cursor;
+
void print_row(Row* row) {
printf("(%d, %s, %s)\n", row->id, row->username, row->email);
}
@@ -126,12 +133,38 @@ void* get_page(Pager* pager, uint32_t page_num) {
return pager->pages[page_num];
}
-void* row_slot(Table* table, uint32_t row_num) {
- uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = get_page(table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+Cursor* table_start(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = 0;
+ cursor->end_of_table = (table->num_rows == 0);
+
+ return cursor;
+}
+
+Cursor* table_end(Table* table) {
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->row_num = table->num_rows;
+ cursor->end_of_table = true;
+
+ return cursor;
+}
+
+void* cursor_value(Cursor* cursor) {
+ uint32_t row_num = cursor->row_num;
+ uint32_t page_num = row_num / ROWS_PER_PAGE;
+ void *page = get_page(cursor->table->pager, page_num);
+ uint32_t row_offset = row_num % ROWS_PER_PAGE;
+ uint32_t byte_offset = row_offset * ROW_SIZE;
+ return page + byte_offset;
+}
+
+void cursor_advance(Cursor* cursor) {
+ cursor->row_num += 1;
+ if (cursor->row_num >= cursor->table->num_rows) {
+ cursor->end_of_table = true;
+ }
}
Pager* pager_open(const char* filename) {
@@ -327,19 +360,28 @@ ExecuteResult execute_insert(Statement* statement, Table* table) {
}
Row* row_to_insert = &(statement->row_to_insert);
+ Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, row_slot(table, table->num_rows));
+ serialize_row(row_to_insert, cursor_value(cursor));
table->num_rows += 1;
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
ExecuteResult execute_select(Statement* statement, Table* table) {
+ Cursor* cursor = table_start(table);
+
Row row;
- for (uint32_t i = 0; i < table->num_rows; i++) {
- deserialize_row(row_slot(table, i), &row);
+ while (!(cursor->end_of_table)) {
+ deserialize_row(cursor_value(cursor), &row);
print_row(&row);
+ cursor_advance(cursor);
}
+
+ free(cursor);
+
return EXECUTE_SUCCESS;
}
第七部分 - B-Tree简介
B-Tree是SQLite用于表示表和索引的数据结构,因此它是一个非常核心的概念。本文仅介绍数据结构,所以不包含任何代码。
为什么树是数据库中的好数据结构呢?
- 搜索特定值快速(对数时间)
- 插入/删除已找到的值很快(重新平衡的大致常数时间)
- 遍历一系列值很快(不像哈希映射)
B-Tree与二叉树不同(“B”可能代表发明者的名字,但也可能代表“平衡”)。这是一个示例B-Tree:
与二叉树不同,B-Tree中的每个节点可以有超过2个孩子。每个节点最多可以有m个孩子,其中m称为树的“阶”。为了保持树基本平衡,我们还说节点必须至少有m/2个孩子(向上取整)。
例外情况:
- 叶节点没有孩子
- 根节点可以少于m个孩子,但必须至少有2个
- 如果根节点是叶节点(唯一的节点),则仍然没有孩子
上面的图片展示了SQLite用于存储索引的B-Tree。为了存储表,SQLite使用了一种称为B+树的变体。
| B-Tree | B+ Tree | |
|---|---|---|
| 发音 | “Bee Tree” | “Bee Plus Tree” |
| 用于存储 | 索引 | 表 |
| 内部节点存储键 | 是 | 是 |
| 内部节点存储值 | 是 | 否 |
| 每个节点的孩子数 | 较少 | 较多 |
| 内部节点与叶节点 | 相同结构 | 不同结构 |
在我们开始实现索引之前,我将专门讨论B+树,但我会简称为B-Tree或btree。
具有孩子的节点称为“内部”节点。内部节点和叶节点的结构不同:
| 对于一个阶为m的树… | 内部节点 | 叶节点 |
|---|---|---|
| 存储 | 键和指向子节点的指针 | 键和值 |
| 键的数量 | 最多m-1 | 尽可能多的键 |
| 指针的数量 | 键的数量 + 1 | 没有 |
| 值的数量 | 没有 | 键的数量 |
| 键的作用 | 用于路由 | 与值配对 |
| 存储值? | 否 | 是 |
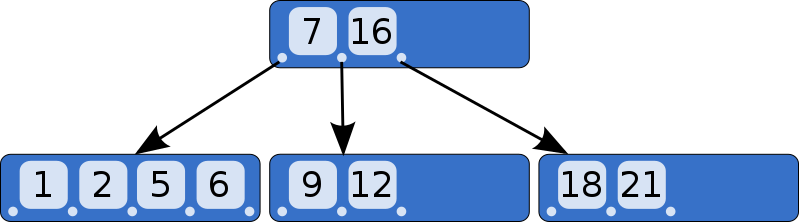
让我们通过示例来看看当向B-Tree插入元素时,B-Tree是如何增长的。为了保持简单,树将是阶为3的。这意味着:
- 每个内部节点最多有3个孩子
- 每个内部节点最多有2个键
- 每个内部节点至少有2个孩子
- 每个内部节点至少有1个键
空的B-Tree只有一个节点:根节点。根节点开始作为一个带有零个键/值对的叶节点:
如果我们插入一对键/值,它们将按排序顺序存储在叶节点中。
假设叶节点的容量为两个键/值对。当我们插入另一个时,我们必须分裂叶节点并将一半的键/值对放入每个节点。这两个节点都成为新的内部节点的子节点,这个内部节点现在将成为根节点。
内部节点有1个键和2个指向子节点的指针。如果我们要查找小于或等于5的键,我们查找左侧子节点。如果我们要查找大于5的键,我们查找右侧子节点。
现在让我们插入键“2”。首先,我们查找如果它存在时它会在哪个叶节点,然后我们到达左侧叶节点。节点已满,所以我们分裂叶节点并在父节点中创建新条目。
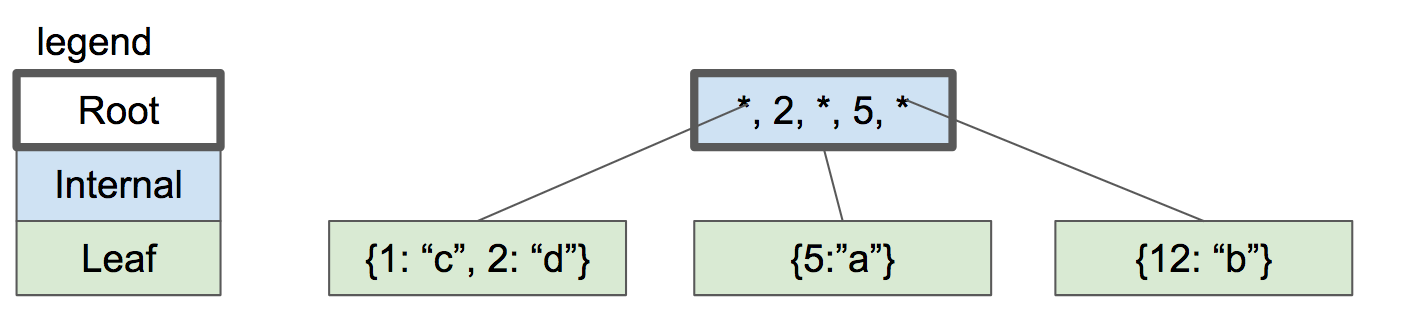
让我们继续添加键。18和21。我们到达必须再次分裂的点,但在父节点中没有足够的空间来放置另一个键/指针对。
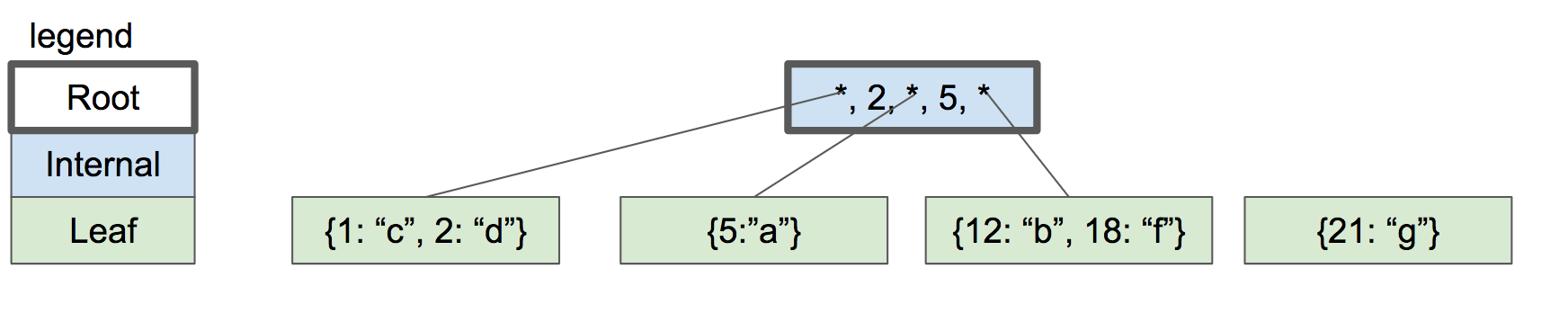
解决方案是将根节点分裂为两个内部节点,
然后创建新的根节点作为它们的父节点。
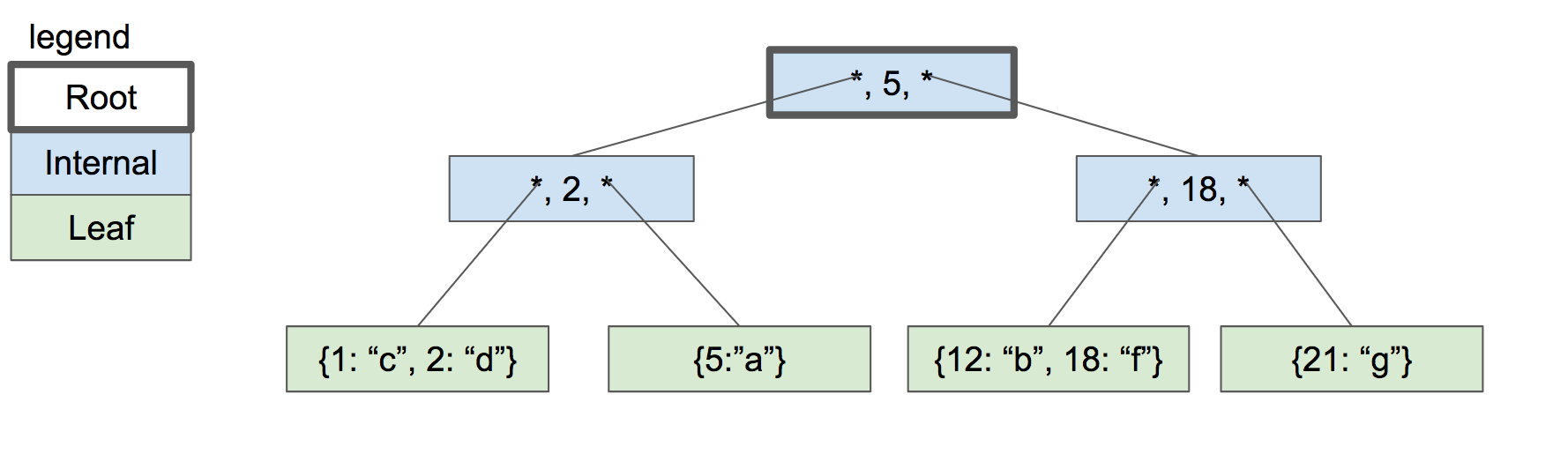
树的深度仅在我们分裂根节点时增加。每个叶节点具有相同的深度和接近相同数量的键/值对,因此树保持平衡并快速搜索。
在我们实现这种数据结构之前,每个节点将对应一个页面。根节点将存在于页面0中。子指针将简单地是包含子节点的页面号。
下次,我们开始实现btree!
第八部分 - B-Tree叶节点格式
我们将表的格式从未排序的行数组更改为B-Tree。这是一个相当大的变化,需要多篇文章来实现。在本文结束时,我们将定义叶节点的布局,并支持将键/值对插入单个节点树中。但首先,让我们回顾一下切换到树结构的原因。
替代表格式
在当前格式中,每个页面仅存储行(没有元数据),因此它非常节省空间。插入也很快,因为我们只是追加到末尾。但是,只能通过扫描整个表来查找特定的行。如果我们想要删除一行,就必须通过移动其后的每一行来填充空洞。
如果我们将表存储为数组,但保持按id排序的行,则可以使用二分搜索来查找特定的id。然而,插入会很慢,因为我们必须移动很多行来腾出空间。
相反,我们选择使用树结构。树中的每个节点可以包含可变数量的行,因此我们必须在每个节点中存储一些信息来跟踪它包含的行数。此外,所有不存储任何行的内部节点的存储开销。换取一个更大的数据库文件,我们获得了快速插入、删除和查找。
| 未排序的行数组 | 排序的行数组 | 节点树 | |
|---|---|---|---|
| 页面包含 | 仅数据 | 仅数据 | 元数据、主键和数据 |
| 每页行数 | 更多 | 更多 | 更少 |
| 插入 | O(1) | O(n) | O(log(n)) |
| 删除 | O(n) | O(n) | O(log(n)) |
| 按id查找 | O(n) | O(log(n)) | O(log(n)) |
节点头格式
叶节点和内部节点具有不同的布局。让我们创建一个枚举来跟踪节点类型:
+typedef enum { NODE_INTERNAL, NODE_LEAF } NodeType;
每个节点将对应一个页面。内部节点将通过存储存储子节点的页面号来指向它们的子节点。btree会请求pager提供特定页面号,并从页面缓存中得到一个指针。页面按照页面号的顺序依次存储在数据库文件中。
节点需要在页面开头存储一些元数据。每个节点将存储其节点类型、是否为根节点以及其父节点的指针(以允许查找节点的兄弟节点)。我为每个头字段的大小和偏移定义了常量:
+/*
+ * 公共节点头布局
+ */
+const uint32_t NODE_TYPE_SIZE = sizeof(uint8_t);
+const uint32_t NODE_TYPE_OFFSET = 0;
+const uint32_t IS_ROOT_SIZE = sizeof(uint8_t);
+const uint32_t IS_ROOT_OFFSET = NODE_TYPE_SIZE;
+const uint32_t PARENT_POINTER_SIZE = sizeof(uint32_t);
+const uint32_t PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE;
+const uint8_t COMMON_NODE_HEADER_SIZE =
+ NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE;
叶节点格式
除了这些常见的头字段之外,叶节点需要存储它们包含多少个“单元”。单元是一个键/值对。
+/*
+ * 叶节点头布局
+ */
+const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_HEADER_SIZE =
+ COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
叶节点的主体是一个单元数组。每个单元都是一个键,后跟一个值(一个序列化的行)。
+/*
+ * 叶节点主体布局
+ */
+const uint32_t LEAF_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_KEY_OFFSET = 0;
+const uint32_t LEAF_NODE_VALUE_SIZE = ROW_SIZE;
+const uint32_t LEAF_NODE_VALUE_OFFSET =
+ LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE;
+const uint32_t LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE;
+const uint32_t LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_MAX_CELLS =
+ LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE;
根据这些常量,当前叶节点的布局如下:
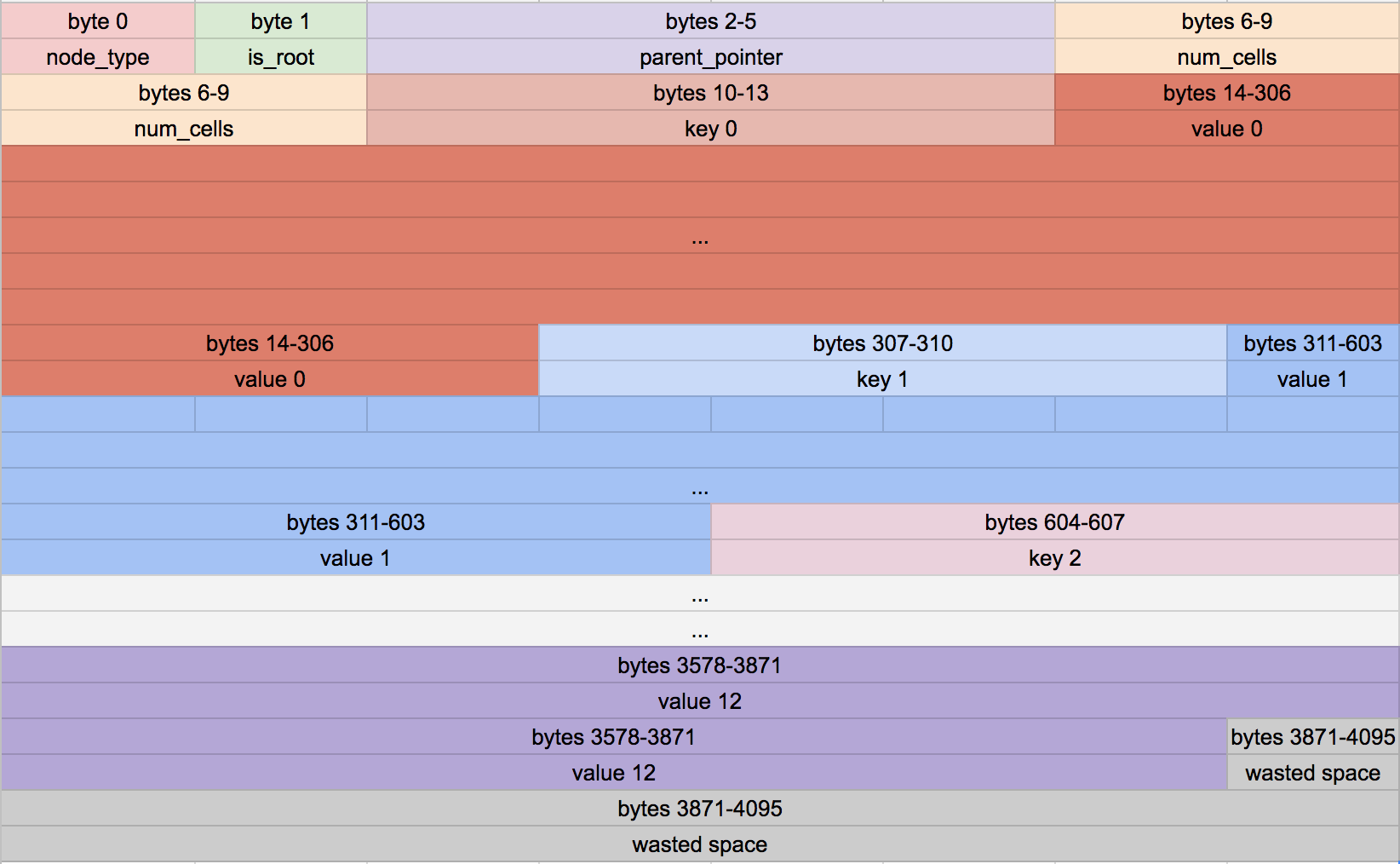
在头部每个布尔值使用一个完整的字节有些浪费空间,但这样可以更轻松地编写访问这些值的代码。
还要注意,末尾有一些空白空间。我们在头部之后存储尽可能多的单元,但剩余的空间无法容纳整个单元。我们将其留空以避免在节点之间分割单元。
访问叶节点字段
访问叶节点字段的代码都涉及使用我们刚刚定义的常量进行指针算术。
+uint32_t* leaf_node_num_cells(void* node) {
+ return node + LEAF_NODE_NUM_CELLS_OFFSET;
+}
+
+void* leaf_node_cell(void* node, uint32_t cell_num) {
+ return node + LEAF_NODE_HEADER_SIZE + cell_num * LEAF_NODE_CELL_SIZE;
+}
+
+uint32_t* leaf_node_key(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num);
+}
+
+void* leaf_node_value(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num) + LEAF_NODE_KEY_SIZE;
+}
+
+void initialize_leaf_node(void* node) { *leaf_node_num_cells(node) = 0; }
这些方法返回所需值的指针,因此可以用作getter和setter。
Pager和Table对象的更改
每个节点将占用一个完整的页面,即使它并未填满该页面。这意味着我们的pager不再需要支持读取/写入部分页面。
-void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+void pager_flush(Pager* pager, uint32_t page_num) {
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page\n");
exit(EXIT_FAILURE);
@@ -242,7 +337,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
}
ssize_t bytes_written =
- write(pager->file_descriptor, pager->pages[page_num], size);
+ write(pager->file_descriptor, pager->pages[page_num], PAGE_SIZE);
if (bytes_written == -1) {
printf("Error writing: %d\n", errno);
void db_close(Table* table) {
Pager* pager = table->pager;
- uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
- for (uint32_t i = 0; i < num_full_pages; i++) {
+ for (uint32_t i = 0; i < pager->num_pages; i++) {
if (pager->pages[i] == NULL) {
continue;
}
- pager_flush(pager, i, PAGE_SIZE);
+ pager_flush(pager, i);
free(pager->pages[i]);
pager->pages[i] = NULL;
}
- // There may be a partial page to write to the end of the file
- // This should not be needed after we switch to a B-tree
- uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
- if (num_additional_rows > 0) {
- uint32_t page_num = num_full_pages;
- if (pager->pages[page_num] != NULL) {
- pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
- free(pager->pages[page_num]);
- pager->pages[page_num] = NULL;
- }
- }
-
int result = close(pager->file_descriptor);
if (result == -1) {
printf("Error closing db file.\n");
现在,在数据库中存储页面的数量比存储行数更有意义。页面的数量应该与pager对象相关联,而不是与表相关联,因为它是数据库使用的页面数量,而不是特定表的数量。B树由其根节点页面号标识,因此表对象需要跟踪它。
const uint32_t PAGE_SIZE = 4096;
const uint32_t TABLE_MAX_PAGES = 100;
-const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
-const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
int file_descriptor;
uint32_t file_length;
+ uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
Pager* pager;
- uint32_t num_rows;
+ uint32_t root_page_num;
} Table;
@@ -127,6 +200,10 @@ void* get_page(Pager* pager, uint32_t page_num) {
}
pager->pages[page_num] = page;
+
+ if (page_num >= pager->num_pages) {
+ pager->num_pages = page_num + 1;
+ }
}
return pager->pages[page_num];
@@ -184,6 +269,12 @@ Pager* pager_open(const char* filename) {
Pager* pager = malloc(sizeof(Pager));
pager->file_descriptor = fd;
pager->file_length = file_length;
+ pager->num_pages = (file_length / PAGE_SIZE);
+
+ if (file_length % PAGE_SIZE != 0) {
+ printf("Db file is not a whole number of pages. Corrupt file.\n");
+ exit(EXIT_FAILURE);
+ }
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
pager->pages[i] = NULL;
Cursor对象的更改
游标表示表中的位置。当我们的表是一个简单的行数组时,我们可以根据行号访问行。现在它是一个树结构,我们通过节点的页面号和该节点中的单元号来标识一个位置。
typedef struct {
Table* table;
- uint32_t row_num;
+ uint32_t page_num;
+ uint32_t cell_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;
Cursor* table_start(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = 0;
- cursor->end_of_table = (table->num_rows == 0);
+ cursor->page_num = table->root_page_num;
+ cursor->cell_num = 0;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->end_of_table = (num_cells == 0);
return cursor;
}
Cursor* table_end(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = table->num_rows;
+ cursor->page_num = table->root_page_num;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->cell_num = num_cells;
cursor->end_of_table = true;
return cursor;
}
void* cursor_value(Cursor* cursor
) {
- uint32_t row_num = cursor->row_num;
- uint32_t page_num = row_num / ROWS_PER_PAGE;
+ uint32_t page_num = cursor->page_num;
void* page = get_page(cursor->table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+ return leaf_node_value(page, cursor->cell_num);
}
void cursor_advance(Cursor* cursor) {
- cursor->row_num += 1;
- if (cursor->row_num >= cursor->table->num_rows) {
+ uint32_t page_num = cursor->page_num;
+ void* node = get_page(cursor->table->pager, page_num);
+
+ cursor->cell_num += 1;
+ if (cursor->cell_num >= (*leaf_node_num_cells(node))) {
cursor->end_of_table = true;
}
}
希望这些更改能够帮助你理解和更新代码以支持B-Tree格式的数据库。
向叶节点插入数据
在本文中,我们只实现了足够实现单节点树的内容。回顾上一篇文章,树从一个空的叶节点开始:
可以添加键/值对,直到叶节点已满:
当我们首次打开数据库时,数据库文件将为空,因此我们将页面 0 初始化为空的叶节点(根节点):
Table* db_open(const char* filename) {
Pager* pager = pager_open(filename);
- uint32_t num_rows = pager->file_length / ROW_SIZE;
Table* table = malloc(sizeof(Table));
table->pager = pager;
- table->num_rows = num_rows;
+ table->root_page_num = 0;
+
+ if (pager->num_pages == 0) {
+ // 新的数据库文件。将页面 0 初始化为叶节点。
+ void* root_node = get_page(pager, 0);
+ initialize_leaf_node(root_node);
+ }
return table;
}
接下来,我们将创建一个函数,用于将键/值对插入到叶节点。它将接受一个光标作为输入,表示应将该对插入的位置。
+void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
+ void* node = get_page(cursor->table->pager, cursor->page_num);
+
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ if (num_cells >= LEAF_NODE_MAX_CELLS) {
+ // 节点已满
+ printf("Need to implement splitting a leaf node.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ if (cursor->cell_num < num_cells) {
+ // 为新单元格腾出空间
+ for (uint32_t i = num_cells; i > cursor->cell_num; i--) {
+ memcpy(leaf_node_cell(node, i), leaf_node_cell(node, i - 1),
+ LEAF_NODE_CELL_SIZE);
+ }
+ }
+
+ *(leaf_node_num_cells(node)) += 1;
+ *(leaf_node_key(node, cursor->cell_num)) = key;
+ serialize_row(value, leaf_node_value(node, cursor->cell_num));
+}
+
我们还没有实现分裂,所以如果节点已满,我们会报错。接下来,我们将单元格右移一个位置,以腾出新单元格的空间。然后,我们将新的键/值对写入到空白的位置。
由于我们假设树只有一个节点,因此 execute_insert() 函数只需要调用这个辅助方法:
ExecuteResult execute_insert(Statement* statement, Table* table) {
- if (table->num_rows >= TABLE_MAX_ROWS) {
+ void* node = get_page(table->pager, table->root_page_num);
+ if ((*leaf_node_num_cells(node) >= LEAF_NODE_MAX_CELLS)) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, cursor_value(cursor));
- table->num_rows += 1;
+ leaf_node_insert(cursor, row_to_insert->id, row_to_insert);
free(cursor);
通过这些更改,我们的数据库应该像以前一样工作!但是现在会更早地返回“表已满”错误,因为我们尚不能分裂根节点。
叶节点能够容纳多少行?
打印常量的命令
我添加了一个新的元命令,以打印一些感兴趣的常量。
+void print_constants() {
+ printf("ROW_SIZE: %d\n", ROW_SIZE);
+ printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE);
+ printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS);
+ printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS);
+}
+
@@ -294,6 +376,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".constants") == 0) {
+ printf("Constants:\n");
+ print_constants();
+ return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
我还添加了一个测试,以便在这些常量发生变化时通知我们:
+ it 'prints constants' do
+ script = [
+ ".constants",
+ ".exit",
+ ]
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Constants:",
+ "ROW_SIZE: 293",
+ "COMMON_NODE_HEADER_SIZE: 6",
+ "LEAF_NODE_HEADER_SIZE: 10",
+ "LEAF_NODE_CELL_SIZE: 297",
+ "LEAF_NODE_SPACE_FOR_CELLS: 4086",
+ "LEAF_NODE_MAX_CELLS: 13",
+ "db > ",
+ ])
+ end
所以我们的表目前可以容纳 13 行!
树的可视化
为了帮助调试和可视化,我还添加了一个元命令来打印 b 树的表示。
+void print_leaf_node(void* node) {
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ printf("leaf (size %d)\n", num_cells);
+ for (uint32_t i = 0; i < num_cells; i++) {
+ uint32_t key = *leaf_node_key(node, i);
+ printf(" - %d : %d\n
", i, key);
+ }
+}
+
@@ -294,6 +376,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".btree") == 0) {
+ printf("Tree:\n");
+ print_leaf_node(get_page(table->pager, 0));
+ return META_COMMAND_SUCCESS;
} else if (strcmp(input_buffer->buffer, ".constants") == 0) {
printf("Constants:\n");
print_constants();
return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
还有一个测试:
+ it 'allows printing out the structure of a one-node btree' do
+ script = [3, 1, 2].map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > Executed.",
+ "db > Executed.",
+ "db > Tree:",
+ "leaf (size 3)",
+ " - 0 : 3",
+ " - 1 : 1",
+ " - 2 : 2",
+ "db > "
+ ])
+ end
哦,糟糕,我们仍然没有按顺序存储行。你会注意到 execute_insert() 在叶节点中插入的位置是由 table_end() 返回的位置。因此,行是按照插入的顺序存储的,就像以前一样。
下一步计划
这可能看起来像是一种倒退。我们的数据库现在存储的行数比以前少了,而且我们仍然按照无序的方式存储行。但就像我在开始时所说的,这是一个重大的改变,重要的是将其分解成可管理的步骤。
接下来,我们将实现按主键查找记录,并开始按顺序存储行。
完整的代码变更
@@ -62,29 +62,101 @@ const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
const uint32_t PAGE_SIZE = 4096;
#define TABLE_MAX_PAGES 100
-const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
-const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
int file_descriptor;
uint32_t file_length;
+ uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
Pager* pager;
- uint32_t num_rows;
+ uint32_t root_page_num;
} Table;
typedef struct {
Table* table;
- uint32_t row_num;
+ uint32_t page_num;
+ uint32_t cell_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;
+typedef enum { NODE_INTERNAL, NODE_LEAF } NodeType;
+
+/*
+ * Common Node Header Layout
+ */
+const uint32_t NODE_TYPE_SIZE = sizeof(uint8_t);
+const uint32_t NODE_TYPE_OFFSET = 0;
+const uint32_t IS_ROOT_SIZE = sizeof(uint8_t);
+const uint32_t IS_ROOT_OFFSET = NODE_TYPE_SIZE;
+const uint32_t PARENT_POINTER_SIZE = sizeof(uint32_t);
+const uint32_t PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE;
+const uint8_t COMMON_NODE_HEADER_SIZE =
+ NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE;
+
+/*
+ * Leaf Node Header Layout
+ */
+const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_HEADER_SIZE =
+ COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
+
+/*
+ * Leaf Node Body Layout
+ */
+const uint32_t LEAF_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_KEY_OFFSET = 0;
+const uint32_t LEAF_NODE_VALUE_SIZE = ROW_SIZE;
+const uint32_t LEAF_NODE_VALUE_OFFSET =
+ LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE;
+const uint32_t LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE;
+const uint32_t LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_MAX_CELLS =
+ LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE;
+
+uint32_t* leaf_node_num_cells(void* node) {
+ return node + LEAF_NODE_NUM_CELLS_OFFSET;
+}
+
+void* leaf_node_cell(void* node, uint32_t cell_num) {
+ return node + LEAF_NODE_HEADER_SIZE + cell_num * LEAF_NODE_CELL_SIZE;
+}
+
+uint32_t* leaf_node_key(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num);
+}
+
+void* leaf_node_value(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num) + LEAF_NODE_KEY_SIZE;
+}
+
+void print_constants() {
+ printf("ROW_SIZE: %d\n", ROW_SIZE);
+ printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE);
+ printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS);
+ printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS);
+}
+
+void print_leaf_node(void* node) {
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ printf("leaf (size %d)\n", num_cells);
+ for (uint32_t i = 0; i < num_cells; i++) {
+ uint32_t key = *leaf_node_key(node, i);
+ printf(" - %d : %d\n", i, key);
+ }
+}
+
void print_row(Row* row) {
printf("(%d, %s, %s)\n", row->id, row->username, row->email);
}
@@ -101,6 +173,8 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void initialize_leaf_node(void* node) { *leaf_node_num_cells(node) = 0; }
+
void* get_page(Pager* pager, uint32_t page_num) {
if (page_num > TABLE_MAX_PAGES) {
printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
@@ -128,6 +202,10 @@ void* get_page(Pager* pager, uint32_t page_num) {
}
pager->pages[page_num] = page;
+
+ if (page_num >= pager->num_pages) {
+ pager->num_pages = page_num + 1;
+ }
}
return pager->pages[page_num];
@@ -136,8 +214,12 @@ void* get_page(Pager* pager, uint32_t page_num) {
Cursor* table_start(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = 0;
- cursor->end_of_table = (table->num_rows == 0);
+ cursor->page_num = table->root_page_num;
+ cursor->cell_num = 0;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->end_of_table = (num_cells == 0);
return cursor;
}
@@ -145,24 +227,28 @@ Cursor* table_start(Table* table) {
Cursor* table_end(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = table->num_rows;
+ cursor->page_num = table->root_page_num;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->cell_num = num_cells;
cursor->end_of_table = true;
return cursor;
}
void* cursor_value(Cursor* cursor) {
- uint32_t row_num = cursor->row_num;
- uint32_t page_num = row_num / ROWS_PER_PAGE;
+ uint32_t page_num = cursor->page_num;
void* page = get_page(cursor->table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+ return leaf_node_value(page, cursor->cell_num);
}
void cursor_advance(Cursor* cursor) {
- cursor->row_num += 1;
- if (cursor->row_num >= cursor->table->num_rows) {
+ uint32_t page_num = cursor->page_num;
+ void* node = get_page(cursor->table->pager, page_num);
+
+ cursor->cell_num += 1;
+ if (cursor->cell_num >= (*leaf_node_num_cells(node))) {
cursor->end_of_table = true;
}
}
@@ -185,6 +271,12 @@ Pager* pager_open(const char* filename) {
Pager* pager = malloc(sizeof(Pager));
pager->file_descriptor = fd;
pager->file_length = file_length;
+ pager->num_pages = (file_length / PAGE_SIZE);
+
+ if (file_length % PAGE_SIZE != 0) {
+ printf("Db file is not a whole number of pages. Corrupt file.\n");
+ exit(EXIT_FAILURE);
+ }
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
pager->pages[i] = NULL;
@@ -194,11 +285,15 @@ Pager* pager_open(const char* filename) {
@@ -195,11 +287,16 @@ Pager* pager_open(const char* filename) {
Table* db_open(const char* filename) {
Pager* pager = pager_open(filename);
- uint32_t num_rows = pager->file_length / ROW_SIZE;
Table* table = malloc(sizeof(Table));
table->pager = pager;
- table->num_rows = num_rows;
+ table->root_page_num = 0;
+
+ if (pager->num_pages == 0) {
+ // New database file. Initialize page 0 as leaf node.
+ void* root_node = get_page(pager, 0);
+ initialize_leaf_node(root_node);
+ }
return table;
}
@@ -234,7 +331,7 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
-void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+void pager_flush(Pager* pager, uint32_t page_num) {
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page\n");
exit(EXIT_FAILURE);
@@ -242,7 +337,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
@@ -249,7 +346,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
}
ssize_t bytes_written =
- write(pager->file_descriptor, pager->pages[page_num], size);
+ write(pager->file_descriptor, pager->pages[page_num], PAGE_SIZE);
if (bytes_written == -1) {
printf("Error writing: %d\n", errno);
@@ -252,29 +347,16 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
@@ -260,29 +357,16 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
void db_close(Table* table) {
Pager* pager = table->pager;
- uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
- for (uint32_t i = 0; i < num_full_pages; i++) {
+ for (uint32_t i = 0; i < pager->num_pages; i++) {
if (pager->pages[i] == NULL) {
continue;
}
- pager_flush(pager, i, PAGE_SIZE);
+ pager_flush(pager, i);
free(pager->pages[i]);
pager->pages[i] = NULL;
}
- // There may be a partial page to write to the end of the file
- // This should not be needed after we switch to a B-tree
- uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
- if (num_additional_rows > 0) {
- uint32_t page_num = num_full_pages;
- if (pager->pages[page_num] != NULL) {
- pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
- free(pager->pages[page_num]);
- pager->pages[page_num] = NULL;
- }
- }
-
int result = close(pager->file_descriptor);
if (result == -1) {
printf("Error closing db file.\n");
@@ -305,6 +389,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".btree") == 0) {
+ printf("Tree:\n");
+ print_leaf_node(get_page(table->pager, 0));
+ return META_COMMAND_SUCCESS;
+ } else if (strcmp(input_buffer->buffer, ".constants") == 0) {
+ printf("Constants:\n");
+ print_constants();
+ return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
@@ -354,16 +446,39 @@ PrepareResult prepare_statement(InputBuffer* input_buffer,
return PREPARE_UNRECOGNIZED_STATEMENT;
}
+void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
+ void* node = get_page(cursor->table->pager, cursor->page_num);
+
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ if (num_cells >= LEAF_NODE_MAX_CELLS) {
+ // Node full
+ printf("Need to implement splitting a leaf node.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ if (cursor->cell_num < num_cells) {
+ // Make room for new cell
+ for (uint32_t i = num_cells; i > cursor->cell_num; i--) {
+ memcpy(leaf_node_cell(node, i), leaf_node_cell(node, i - 1),
+ LEAF_NODE_CELL_SIZE);
+ }
+ }
+
+ *(leaf_node_num_cells(node)) += 1;
+ *(leaf_node_key(node, cursor->cell_num)) = key;
+ serialize_row(value, leaf_node_value(node, cursor->cell_num));
+}
+
ExecuteResult execute_insert(Statement* statement, Table* table) {
- if (table->num_rows >= TABLE_MAX_ROWS) {
+ void* node = get_page(table->pager, table->root_page_num);
+ if ((*leaf_node_num_cells(node) >= LEAF_NODE_MAX_CELLS)) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, cursor_value(cursor));
- table->num_rows += 1;
+ leaf_node_insert(cursor, row_to_insert->id, row_to_insert);
free(cursor);
测试如下:
+ it 'allows printing out the structure of a one-node btree' do
+ script = [3, 1, 2].map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > Executed.",
+ "db > Executed.",
+ "db > Tree:",
+ "leaf (size 3)",
+ " - 0 : 3",
+ " - 1 : 1",
+ " - 2 : 2",
+ "db > "
+ ])
+ end
+
+ it 'prints constants' do
+ script = [
+ ".constants",
+ ".exit",
+ ]
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Constants:",
+ "ROW_SIZE: 293",
+ "COMMON_NODE_HEADER_SIZE: 6",
+ "LEAF_NODE_HEADER_SIZE: 10",
+ "LEAF_NODE_CELL_SIZE: 297",
+ "LEAF_NODE_SPACE_FOR_CELLS: 4086",
+ "LEAF_NODE_MAX_CELLS: 13",
+ "db > ",
+ ])
+ end
end
第九部分 - 二分搜索和重复键
上次我们指出,我们仍在以无序方式存储键。我们将修复这个问题,并检测并拒绝重复键。
现在,我们的 execute_insert() 函数总是选择在表的末尾插入。相反,我们应该在表中搜索正确的位置,然后在那里插入。如果键已经存在于该位置,则返回错误。
ExecuteResult execute_insert(Statement* statement, Table* table) {
void* node = get_page(table->pager, table->root_page_num);
- if ((*leaf_node_num_cells(node) >= LEAF_NODE_MAX_CELLS)) {
+ uint32_t num_cells = (*leaf_node_num_cells(node));
+ if (num_cells >= LEAF_NODE_MAX_CELLS) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
- Cursor* cursor = table_end(table);
+ uint32_t key_to_insert = row_to_insert->id;
+ Cursor* cursor = table_find(table, key_to_insert);
+
+ if (cursor->cell_num < num_cells) {
+ uint32_t key_at_index = *leaf_node_key(node, cursor->cell_num);
+ if (key_at_index == key_to_insert) {
+ return EXECUTE_DUPLICATE_KEY;
+ }
+ }
leaf_node_insert(cursor, row_to_insert->id, row_to_insert);
我们不再需要 table_end() 函数。
-Cursor* table_end(Table* table) {
- Cursor* cursor = malloc(sizeof(Cursor));
- cursor->table = table;
- cursor->page_num = table->root_page_num;
-
- void* root_node = get_page(table->pager, table->root_page_num);
- uint32_t num_cells = *leaf_node_num_cells(root_node);
- cursor->cell_num = num_cells;
- cursor->end_of_table = true;
-
- return cursor;
-}
我们将其替换为一个方法,该方法在树中搜索给定键的位置。
+/*
+返回给定键的位置。
+如果键不存在,则返回应插入的位置。
+*/
+Cursor* table_find(Table* table, uint32_t key) {
+ uint32_t root_page_num = table->root_page_num;
+ void* root_node = get_page(table->pager, root_page_num);
+
+ if (get_node_type(root_node) == NODE_LEAF) {
+ return leaf_node_find(table, root_page_num, key);
+ } else {
+ printf("Need to implement searching an internal node\n");
+ exit(EXIT_FAILURE);
+ }
+}
我正在为内部节点的分支提供桩代码,因为我们尚未实现内部节点。我们可以使用二分搜索来搜索叶子节点。
+Cursor* leaf_node_find(Table* table, uint32_t page_num, uint32_t key) {
+ void* node = get_page(table->pager, page_num);
+ uint32_t num_cells = *leaf_node_num_cells(node);
+
+ Cursor* cursor = malloc(sizeof(Cursor));
+ cursor->table = table;
+ cursor->page_num = page_num;
+
+ // 二分搜索
+ uint32_t min_index = 0;
+ uint32_t one_past_max_index = num_cells;
+ while (one_past_max_index != min_index) {
+ uint32_t index = (min_index + one_past_max_index) / 2;
+ uint32_t key_at_index = *leaf_node_key(node, index);
+ if (key == key_at_index) {
+ cursor->cell_num = index;
+ return cursor;
+ }
+ if (key < key_at_index) {
+ one_past_max_index = index;
+ } else {
+ min_index = index + 1;
+ }
+ }
+
+ cursor->cell_num = min_index;
+ return cursor;
+}
这将返回:
- 键的位置,
- 另一个键的位置,如果要插入新键,则需要移动该位置的键,或者
- 最后一个键之后的位置
由于我们现在正在检查节点类型,因此我们需要函数来获取并设置节点中的值。
+NodeType get_node_type(void* node) {
+ uint8_t value = *((uint8_t*)(node + NODE_TYPE_OFFSET));
+ return (NodeType)value;
+}
+
+void set_node_type(void* node, NodeType type) {
+ uint8_t value = type;
+ *((uint8_t*)(node + NODE_TYPE_OFFSET)) = value;
+}
我们首先要进行 uint8_t 强制转换,以确保将其序列化为单个字节。
我们还需要初始化节点类型。
-void initialize_leaf_node(void* node) { *leaf_node_num_cells(node) = 0; }
+void initialize_leaf_node(void* node) {
+ set_node_type(node, NODE_LEAF);
+ *leaf_node_num_cells(node) = 0;
+}
最后,我们需要创建并处理一个新的错误代码。
-enum ExecuteResult_t { EXECUTE_SUCCESS, EXECUTE_TABLE_FULL };
+enum ExecuteResult_t {
+ EXECUTE_SUCCESS,
+ EXECUTE_DUPLICATE_KEY,
+ EXECUTE_TABLE_FULL
+};
case (EXECUTE_SUCCESS):
printf("Executed.\n");
break;
+ case (EXECUTE_DUPLICATE_KEY):
+ printf("Error: Duplicate key.\n");
+ break;
case (EXECUTE_TABLE_FULL):
printf("Error: Table full.\n");
break;
通过这些更改,我们的测试可以更改为检查是否按排序顺序排列:
"db > Executed.",
"db > Tree:",
"leaf (size 3)",
- " - 0 : 3",
- " - 1 : 1",
- " - 2 : 2",
+ " - 0 : 1",
+ " - 1 : 2",
+ " - 2 : 3",
"db > "
])
end
我们还可以添加一个新的测试以检查重复键:
+ it 'prints an error message if there is a duplicate id' do
+ script = [
+ "insert 1 user1 person1@example.com",
+ "insert 1 user1 person1@example.com",
+ "select",
+ ".exit",
+ ]
+ result = run_script(script)
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > Error: Duplicate key.",
+ "db > (1, user1, person1@example.com)",
+ "Executed.",
+ "db > ",
+ ])
+ end
就是这样!接下来:实现分裂叶子节点和创建内部节点。
第十部分 - 分裂叶子节点
我们的 B-Tree 只有一个节点,看起来并不像一棵树。为了解决这个问题,我们需要一些代码来将叶子节点拆分,并创建一个内部节点作为两个叶子节点的父节点。
基本上,本文的目标是从这个状态:
变成这个状态:
首先,让我们删除对满叶子节点的错误处理:
void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
void* node = get_page(cursor->table->pager, cursor->page_num);
uint32_t num_cells = *leaf_node_num_cells(node);
if (num_cells >= LEAF_NODE_MAX_CELLS) {
// Node full
- printf("Need to implement splitting a leaf node.\n");
- exit(EXIT_FAILURE);
+ leaf_node_split_and_insert(cursor, key, value);
+ return;
}
ExecuteResult execute_insert(Statement* statement, Table* table) {
void* node = get_page(table->pager, table->root_page_num);
uint32_t num_cells = (*leaf_node_num_cells(node));
- if (num_cells >= LEAF_NODE_MAX_CELLS) {
- return EXECUTE_TABLE_FULL;
- }
Row* row_to_insert = &(statement->row_to_insert);
uint32_t key_to_insert = row_to_insert->id;
分裂算法
容易的部分已经完成。以下是来自SQLite 数据库系统:设计与实现的描述:
如果叶子节点没有空间了,我们会将驻留在那里的现有条目和要插入的新条目(正在插入的)拆分为两个相等的部分:较低和较高的部分。(上半部分的键严格大于下半部分的键。)我们分配一个新的叶子节点,并将上半部分移动到新节点。
让我们先获取旧节点,并创建新节点:
+void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
+ /*
+ 创建一个新节点并将一半单元格移动过去。
+ 在两个节点中的一个中插入新值。
+ 更新父节点或创建一个新的父节点。
+ */
+
+ void* old_node = get_page(cursor->table->pager, cursor->page_num);
+ uint32_t new_page_num = get_unused_page_num(cursor->table->pager);
+ void* new_node = get_page(cursor->table->pager, new_page_num);
+ initialize_leaf_node(new_node);
接下来,将每个单元格复制到它的新位置:
+ /*
+ 所有现有键以及新键应该均匀分布
+ 在旧(左)和新(右)节点之间。
+ 从右侧开始,将每个键移动到正确的位置。
+ */
+ for (int32_t i = LEAF_NODE_MAX_CELLS; i >= 0; i--) {
+ void* destination_node;
+ if (i >= LEAF_NODE_LEFT_SPLIT_COUNT) {
+ destination_node = new_node;
+ } else {
+ destination_node = old_node;
+ }
+ uint32_t index_within_node = i % LEAF_NODE_LEFT_SPLIT_COUNT;
+ void* destination = leaf_node_cell(destination_node, index_within_node);
+
+ if (i == cursor->cell_num) {
+ serialize_row(value, destination);
+ } else if (i > cursor->cell_num) {
+ memcpy(destination, leaf_node_cell(old_node, i - 1), LEAF_NODE_CELL_SIZE);
+ } else {
+ memcpy(destination, leaf_node_cell(old_node, i), LEAF_NODE_CELL_SIZE);
+ }
+ }
在每个节点的头部更新单元格计数:
+ /* 在两个叶子节点上更新单元格计数 */
+ *(leaf_node_num_cells(old_node)) = LEAF_NODE_LEFT_SPLIT_COUNT;
+ *(leaf_node_num_cells(new_node)) = LEAF_NODE_RIGHT_SPLIT_COUNT;
接下来,我们需要更新节点的父节点。如果原始节点是根节点,则它没有父节点。在这种情况下,创建一个新的根节点作为父节点。我会暂时创建另一支的桩代码:
+ if (is_node_root(old_node)) {
+ return create_new_root(cursor->table, new_page_num);
+ } else {
+ printf("Need to implement updating parent after split\n");
+ exit(EXIT_FAILURE);
+ }
+}
分配新页面
让我们回到并定义一些新函数和常量。当我们创建一个新的叶子节点时,我们将其放在由 get_unused_page_num() 决定的页面中:
+/*
+在我们开始回收空闲页面之前,新页面将始终
+添加到数据库文件的末尾
+*/
+uint32_t get_unused_page_num(Pager* pager) { return pager->num_pages; }
现在,我们假设在具有 N 个页面的数据库中,页面号为 0 到 N-1 被分配。因此,我们可以总是为新页面分配页面号 N。最终,在实现删除后,某些页面可能会变为空闲,它们的页面号未被使用。为了更高效,我们可以重新分配这些空闲页面。
叶子节点大小
为了保持树的平衡,我们要在两个新节点之间均匀分配单元格。如果叶子节点可以容纳 N 个单元格,那么在拆分时,我们需要在两个节点之间分配 N+1 个单元格(N 个原始单元格加一个新的单元格)。我随意地选择左节点在 N+1 为奇数时获取一个额外的单元格。
+const uint32_t LEAF_NODE_RIGHT_SPLIT_COUNT = (LEAF_NODE_MAX_CELLS + 1) / 2;
+const uint32_t LEAF_NODE_LEFT_SPLIT_COUNT =
+ (LEAF_NODE_MAX_CELLS + 1) - LEAF_NODE_RIGHT_SPLIT_COUNT;
创建一个新的根节点
这是SQLite 数据库系统解释创建新根节点的过程:
设 N 为根节点。首先分配两个节点,称为 L 和 R。将 N 的下半部分移动到 L 中,将上半部分移动到 R 中。现在 N 是空的。在 N 中添加 〈L, K,R〉,其中 K 是 L 中的最大键。页面 N 仍然是根节点。请注意,树的深度增加了一层,但新树仍然保持平衡,不违反任何 B+树属性。
在这一点上,我们已经分配了右子节点并将上半部分移动到它。我们的函数接受右子节点作为输入,并分配一个新页面来存储左子节点。
+void create_new_root(Table* table, uint32_t right_child_page_num) {
+ /*
+ 处理根节点的拆分。
+ 将旧根复制到新页面,成为左子节点。
+ 重新初始化根页以包含新根节点。
+ 新根节点指向两个子节点。
+ */
+
+ void* root = get_page(table->pager, table->root_page_num);
+ void* right_child = get_page(table->pager, right_child_page_num);
+ uint32_t left_child_page_num = get_unused_page_num(table->pager);
+ void* left_child = get_page(table->pager, left_child_page_num);
将旧根复制到左子节点,以便我们可以重用根页:
+ /* 左子节点有从旧根复制的数据 */
+ memcpy(left_child, root, PAGE_SIZE);
+ set_node_root(left_child, false);
最后,将根页初始化为一个具有两个子节点的新内部节点。
+ /* 根节点是一个新的内部节点,有一个键和两个子节点 */
+ initialize_internal_node(root);
+ set_node_root(root, true);
+ *internal_node_num_keys(root) = 1;
+ *internal_node_child(root, 0) = left_child_page_num;
+ uint32_t left_child_max_key = get_node_max_key(left_child);
+ *internal_node_key(root, 0) = left_child_max_key;
+ *internal_node_right_child(root) = right_child_page_num;
+}
内部节点格式
现在我们终于要创建一个内部节点了,我们必须定义其布局。它以通用头部开始,然后是它包含的键的数量,然后是其最右侧子节点的页号。内部节点始终比键多一个子节点指针。这个额外的子节点指针存储在头部中。
+/*
+ * 内部节点头部布局
+ */
+const uint32_t INTERNAL_NODE_NUM_KEYS_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_NUM_KEYS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t INTERNAL_NODE_RIGHT_CHILD_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_RIGHT_CHILD_OFFSET =
+ INTERNAL_NODE_NUM_KEYS_OFFSET + INTERNAL_NODE_NUM_KEYS_SIZE;
+const uint32_t INTERNAL_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE +
+ INTERNAL_NODE_NUM_KEYS_SIZE +
+ INTERNAL_NODE_RIGHT_CHILD_SIZE;
其主体是一个包含子节点和键的单元格数组。每个键应该是其左侧子节点中包含的最大键。
+/*
+ * 内部节点主体布局
+ */
+const uint32_t INTERNAL_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_CHILD_SIZE = sizeof(uint32_t);
+const uint32_t INTERNAL_NODE_CELL_SIZE =
+ INTERNAL_NODE_CHILD_SIZE + INTERNAL_NODE_KEY_SIZE;
基于这些常量,这里是内部节点布局的样子:

请注意我们的巨大分支因子。因为每个子节点/键对都非常小,所以每个内部节点可以容纳 510 个键和 511 个子节点指针。这意味着我们永远不必遍历许多层树来查找给定的键!
| # 内部节点层数 | 最大 # 叶子节点 | 所有叶子节点的大小 |
|---|---|---|
| 0 | 511^0 = 1 | 4 KB |
| 1 | 511^1 = 512 | ~2 MB |
| 2 | 511^2 = 261,121 | ~1 GB |
| 3 | 511^3 = 133,432,831 | ~550 GB |
实际上,由于头部、键和浪费空间的开销,我们不能在每个叶子节点中存储完整的 4 KB 数据。但我们可以通过仅加载磁盘上的 4 页来搜索大约 500 GB 的数据。这就是为什么 B-Tree 对于数据库是一个有用的数据结构。
这里是读取和写入内部节点的方法:
+uint32_t* internal_node_num_keys(void* node) {
+ return node + INTERNAL_NODE_NUM_KEYS_OFFSET;
+}
+
+uint32_t* internal_node_right_child(void* node) {
+ return node + INTERNAL_NODE_RIGHT_CHILD_OFFSET;
+}
+
+uint32_t* internal_node_cell(void* node, uint32_t cell_num) {
+ return node + INTERNAL_NODE_HEADER_SIZE + cell_num * INTERNAL_NODE_CELL_SIZE;
+}
+
+uint32_t* internal_node_child(void* node, uint32_t child_num) {
+ uint32_t num_keys = *internal_node_num_keys(node);
+ if (child_num > num_keys) {
+ printf("Tried to access child_num %d > num_keys %d\n", child_num, num_keys);
+ exit(EXIT_FAILURE);
+ } else if (child_num == num_keys) {
+ return internal_node_right_child(node);
+ } else {
+ return internal_node_cell(node, child_num);
+ }
+}
+
+uint32_t* internal_node_key(void* node, uint32_t key_num) {
+ return internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
+}
对于内部节点,最大键值始终是它的右键。而对于叶节点,则是最大索引处的键值:
+uint32_t get_node_max_key(void* node) {
+ switch (get_node_type(node)) {
+ case NODE_INTERNAL:
+ return *internal_node_key(node, *internal_node_num_keys(node) - 1);
+ case NODE_LEAF:
+ return *leaf_node_key(node, *leaf_node_num_cells(node) - 1);
+ }
+}
跟踪根节点状态
我们终于在通用节点头部使用了 is_root 字段。回想一下,我们用它来决定如何拆分叶节点:
if (is_node_root(old_node)) {
return create_new_root(cursor->table, new_page_num);
} else {
printf("Need to implement updating parent after split\n");
exit(EXIT_FAILURE);
}
}
以下是获取器和设置器:
+bool is_node_root(void* node) {
+ uint8_t value = *((uint8_t*)(node + IS_ROOT_OFFSET));
+ return (bool)value;
+}
+
+void set_node_root(void* node, bool is_root) {
+ uint8_t value = is_root;
+ *((uint8_t*)(node + IS_ROOT_OFFSET)) = value;
+}
初始化两种类型的节点应默认将 is_root 设置为 false:
void initialize_leaf_node(void* node) {
set_node_type(node, NODE_LEAF);
+ set_node_root(node, false);
*leaf_node_num_cells(node) = 0;
}
+void initialize_internal_node(void* node) {
+ set_node_type(node, NODE_INTERNAL);
+ set_node_root(node, false);
+ *internal_node_num_keys(node) = 0;
+}
在创建表的第一个节点时,我们应将 is_root 设置为 true:
// New database file. Initialize page 0 as leaf node.
void* root_node = get_page(pager, 0);
initialize_leaf_node(root_node);
+ set_node_root(root_node, true);
}
return table;
打印树结构
为了帮助可视化数据库的状态,我们应该更新 .btree 元命令以打印多级树结构。
我将替换当前的 print_leaf_node() 函数:
-void print_leaf_node(void* node) {
- uint32_t num_cells = *leaf_node_num_cells(node);
- printf("leaf (size %d)\n", num_cells);
- for (uint32_t i = 0; i < num_cells; i++) {
- uint32_t key = *leaf_node_key(node, i);
- printf(" - %d : %d\n", i, key);
- }
-}
使用一个新的递归函数,它接收任何节点,然后打印节点及其子节点。该函数接受一个缩进级别作为参数,并随着每次递归调用而增加。我还添加了一个小的缩进辅助函数。
+void indent(uint32_t level) {
+ for (uint32_t i = 0; i < level; i++) {
+ printf(" ");
+ }
+}
+
+void print_tree(Pager* pager, uint32_t page_num, uint32_t indentation_level) {
+ void* node = get_page(pager, page_num);
+ uint32_t num_keys, child;
+
+ switch (get_node_type(node)) {
+ case (NODE_LEAF):
+ num_keys = *leaf_node_num_cells(node);
+ indent(indentation_level);
+ printf("- leaf (size %d)\n", num_keys);
+ for (uint32_t i = 0; i < num_keys; i++) {
+ indent(indentation_level + 1);
+ printf("- %d\n", *leaf_node_key(node, i));
+ }
+ break;
+ case (NODE_INTERNAL):
+ num_keys = *internal_node_num_keys(node);
+ indent(indentation_level);
+ printf("- internal (size %d)\n", num_keys);
+ for (uint32_t i = 0; i < num_keys; i++) {
+ child = *internal_node_child(node, i);
+ print_tree(pager, child, indentation_level + 1);
+
+ indent(indentation_level + 1);
+ printf("- key %d\n", *internal_node_key(node, i));
+ }
+ child = *internal_node_right_child(node);
+ print_tree(pager, child, indentation_level + 1);
+ break;
+ }
+}
并且更新对打印函数的调用,传入缩进级别为零。
} else if (strcmp(input_buffer->buffer, ".btree") == 0) {
printf("Tree:\n");
- print_leaf_node(get_page(table->pager, 0));
+ print_tree(table->pager, 0, 0);
return META_COMMAND_SUCCESS;
这是新打印功能的测试用例!
+ it 'allows printing out the structure of a 3-leaf-node btree' do
+ script = (1..14).map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << "insert 15 user15 person15@example.com"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result[14...(result.length)]).to match_array([
+ "db > Tree:",
+ "- internal (size 1)",
+ " - leaf (size 7)",
+ " - 1",
+ " - 2",
+ " - 3",
+ " - 4",
+ " - 5",
+ " - 6",
+ " - 7",
+ " - key 7",
+ " - leaf (size 7)",
+ " - 8",
+ " - 9",
+ " - 10",
+ " - 11",
+ " - 12",
+ " - 13",
+ " - 14",
+ "db > Need to implement searching an internal node",
+ ])
+ end
新格式有些简化,因此我们需要更新现有的 .btree 测试:
"db > Executed.",
"db > Executed.",
"db > Tree:",
- "leaf (size 3)",
- " - 0 : 1",
- " - 1 : 2",
- " - 2 : 3",
+ "- leaf (size 3)",
+ " - 1",
+ " - 2",
+ " - 3",
"db > "
])
end
这是新测试的 .btree 输出:
Tree:
- internal (size 1)
- leaf (size 7)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- key 7
- leaf (size 7)
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在最少缩进的级别上,我们看到了根节点(内部节点)。它说 size 1,因为它有一个键。缩进一级,我们看到了一个叶节点、一个键,和另一个叶节点。根节点中的键值(7)是第一个叶节点中的最大键值。大于 7 的每个键都在第二个叶节点中。
一个大问题
如果你一直密切关注,你可能会注意到我们漏掉了一个很大的问题。看看如果我们尝试插入一行额外的数据会发生什么:
db > insert 15 user15 person15@example.com
Need to implement searching an internal node
哎呀!谁写了这个 TODO 提示? :P
下次我们将继续 B 树的史诗故事,实现在多级树上的搜索。
第十一部分 - 递归搜索 B 树
上次我们在插入第 15 行时出现了错误:
db > insert 15 user15 person15@example.com
Need to implement searching an internal node
首先,用一个新的函数调用替换代码存根。
if (get_node_type(root_node) == NODE_LEAF) {
return leaf_node_find(table, root_page_num, key);
} else {
return internal_node_find(table, root_page_num, key);
}
这个函数将执行二分搜索,以找到应包含给定键的子节点。记住,每个子指针右侧的键是该子节点包含的最大键。
因此,我们的二分搜索比较要找到的键和子节点指针右侧的键:
Cursor* internal_node_find(Table* table, uint32_t page_num, uint32_t key) {
void* node = get_page(table->pager, page_num);
uint32_t num_keys = *internal_node_num_keys(node);
/* Binary search to find index of child to search */
uint32_t min_index = 0;
uint32_t max_index = num_keys; /* there is one more child than key */
while (min_index != max_index) {
uint32_t index = (min_index + max_index) / 2;
uint32_t key_to_right = *internal_node_key(node, index);
if (key_to_right >= key) {
max_index = index;
} else {
min_index = index + 1;
}
}
还要记住,内部节点的子节点可以是叶节点,也可以是更多的内部节点。在找到正确的子节点后,在其上调用适当的搜索函数:
uint32_t child_num = *internal_node_child(node, min_index);
void* child = get_page(table->pager, child_num);
switch (get_node_type(child)) {
case NODE_LEAF:
return leaf_node_find(table, child_num, key);
case NODE_INTERNAL:
return internal_node_find(table, child_num, key);
}
}
测试
现在在多节点 B 树中插入一个键不再导致错误。我们可以更新我们的测试:
" - 12",
" - 13",
" - 14",
- "db > Need to implement searching an internal node",
+ "db > Executed.",
+ "db > ",
])
end
我也认为是时候重新审视另一个测试了。试图插入 1400 行的测试。它仍然出错,但错误消息是新的。目前,我们的测试在程序崩溃时处理得并不好。如果发生这种情况,让我们只使用到目前为止得到的输出:
raw_output = nil
IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
- pipe.puts command
+ begin
+ pipe.puts command
+ rescue Errno::EPIPE
+ break
+ end
end
pipe.close_write
这暴露了我们 1400 行测试的错误输出:
end
script << ".exit"
result = run_script(script)
- expect(result[-2]).to eq('db > Error: Table full.')
+ expect(result.last(2)).to match_array([
+ "db > Executed.",
+ "db > Need to implement updating parent after split",
+ ])
end
看起来这是我们接下来要做的事情!
第十二部分 - 扫描多层 B 树
我们现在支持构建多层 B 树,但在此过程中我们破坏了 select 语句。下面是一个测试案例,插入了 15 行然后尝试打印它们。
+ it 'prints all rows in a multi-level tree' do
+ script = []
+ (1..15).each do |i|
+ script << "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << "select"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result[15...result.length]).to match_array([
+ "db > (1, user1, person1@example.com)",
+ "(2, user2, person2@example.com)",
+ "(3, user3, person3@example.com)",
+ "(4, user4, person4@example.com)",
+ "(5, user5, person5@example.com)",
+ "(6, user6, person6@example.com)",
+ "(7, user7, person7@example.com)",
+ "(8, user8, person8@example.com)",
+ "(9, user9, person9@example.com)",
+ "(10, user10, person10@example.com)",
+ "(11, user11, person11@example.com)",
+ "(12, user12, person12@example.com)",
+ "(13, user13, person13@example.com)",
+ "(14, user14, person14@example.com)",
+ "(15, user15, person15@example.com)",
+ "Executed.", "db > ",
+ ])
+ end
但当我们现在运行该测试案例时,实际发生的是:
db > select
(2, user1, person1@example.com)
Executed.
这很奇怪。只打印了一行,并且该行看起来损坏了(注意 id 不匹配用户名)。
这种奇怪现象是因为 execute_select() 从表的开头开始,而我们当前的 table_start() 实现返回根节点的第 0 个单元格。但是我们的树的根现在是一个内部节点,它不包含任何行。打印出来的数据必须是当根节点是叶子节点时留下的。execute_select() 实际上应该返回最左边叶子节点的第 0 个单元格。
因此,去掉旧的实现:
-Cursor* table_start(Table* table) {
- Cursor* cursor = malloc(sizeof(Cursor));
- cursor->table = table;
- cursor->page_num = table->root_page_num;
- cursor->cell_num = 0;
-
- void* root_node = get_page(table->pager, table->root_page_num);
- uint32_t num_cells = *leaf_node_num_cells(root_node);
- cursor->end_of_table = (num_cells == 0);
-
- return cursor;
-}
并添加一个新的实现,搜索键为 0(可能不存在于表中,但此方法将返回最小 id 的位置,即最左叶子节点的开头)。
+Cursor* table_start(Table* table) {
+ Cursor* cursor = table_find(table, 0);
+
+ void* node = get_page(table->pager, cursor->page_num);
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ cursor->end_of_table = (num_cells == 0);
+
+ return cursor;
+}
有了这些更改,它仍然只打印了一节点的行:
db > select
(1, user1, person1@example.com)
(2, user2, person2@example.com)
(3, user3, person3@example.com)
(4, user4, person4@example.com)
(5, user5, person5@example.com)
(6, user6, person6@example.com)
(7, user7, person7@example.com)
Executed.
db >
有 15 条目,我们的 B 树包含一个内部节点和两个叶子节点,大致如下:
为了扫描整个表,我们需要在到达第一个叶子节点的末尾后跳转到第二个叶子节点。为此,我们将在叶子节点头部添加一个新的字段,称为 “next_leaf”,它将保存右侧叶子节点的页面号。最右侧的叶子节点的 next_leaf 值将为 0,表示没有兄弟节点(页面 0 通常保留给表的根节点)。
更新叶子节点头部格式以包括新的字段:
const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
-const uint32_t LEAF_NODE_HEADER_SIZE =
- COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
+const uint32_t LEAF_NODE_NEXT_LEAF_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_NEXT_LEAF_OFFSET =
+ LEAF_NODE_NUM_CELLS_OFFSET + LEAF_NODE_NUM_CELLS_SIZE;
+const uint32_t LEAF_NODE_HEADER_SIZE = COMMON_NODE_HEADER_SIZE +
+ LEAF_NODE_NUM_CELLS_SIZE +
+ LEAF_NODE_NEXT_LEAF_SIZE;
添加一个访问新字段的方法:
+uint32_t* leaf_node_next_leaf(void* node) {
+ return node + LEAF_NODE_NEXT_LEAF_OFFSET;
+}
在初始化新的叶子节点时,默认将 next_leaf 设置为 0:
@@ -322,6 +330,7 @@ void initialize_leaf_node(void* node) {
set_node_type(node, NODE_LEAF);
set_node_root(node, false);
*leaf_node_num_cells(node) = 0;
+ *leaf_node_next_leaf(node) = 0; // 0 表示无兄弟节点
}
每当我们拆分叶子节点时,更新兄弟节点指针。旧叶子节点的兄弟节点变成新的叶子节点,新叶子节点的兄弟节点变成旧叶子节点的兄弟节点。
@@ -659,6 +671,8 @@ void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
uint32_t new_page_num = get_unused_page_num(cursor->table->pager);
void* new_node = get_page(cursor->table->pager, new_page_num);
initialize_leaf_node(new_node);
+ *leaf_node_next_leaf(new_node) = *leaf_node_next_leaf(old_node);
+ *leaf_node_next_leaf(old_node) = new_page_num;
添加新字段会更改一些常量:
it 'prints constants' do
script = [
".constants",
@@ -199,9 +228,9 @@ describe 'database' do
"db > Constants:",
"ROW_SIZE: 293",
"COMMON_NODE_HEADER_SIZE: 6",
- "LEAF_NODE_HEADER_SIZE: 10",
+ "LEAF_NODE_HEADER_SIZE: 14",
"LEAF_NODE_CELL_SIZE: 297",
- "LEAF_NODE_SPACE_FOR_CELLS: 4086",
+ "LEAF_NODE_SPACE_FOR_CELLS: 4082",
"LEAF_NODE_MAX_CELLS: 13",
"db > ",
])
现在,每当我们想要推进游标超出叶子节点的末尾时,可以检查叶子节点是否有兄弟节点。如果有,就跳到兄弟节点;否则,我们到达表的末尾。
@@ -428,7 +432,15 @@ void cursor_advance(Cursor* cursor) {
cursor->cell_num += 1;
if (cursor->cell_num >= (*leaf_node_num_cells(node))) {
- cursor->end_of_table = true;
+ /* 前进到下一个叶子节点 */
+ uint32_t next_page_num = *leaf_node_next_leaf(node);
+ if (next_page_num == 0) {
+ /* 这是最右边的叶子节点 */
+ cursor->end_of_table = true;
+ } else {
+ cursor->page_num = next_page_num;
+ cursor->cell_num = 0;
+ }
}
}
在这些更改之后,我们实际上打印了 15 行…
db > select
(1, user1, person1@example.com)
(2, user2, person2@example.com)
(3, user3, person3@example.com)
(4, user4, person4@example.com)
(5, user5, person5@example.com)
(6, user6, person6@example.com)
(7, user7, person7@example.com)
(8, user8, person8@example.com)
(9, user9, person9@example.com)
(10, user10, person10@example.com)
(11, user11, person11@example.com)
(12, user12, person12@example.com)
(13, user13, person13@example.com)
(1919251317, 14, on14@example.com)
(15, user15, person15@example.com)
Executed.
db >
…但其中一行看起来损坏了。
(1919251317, 14, on14@example.com)
经过一些调试,我发现是因为我们在拆分叶子节点时存在一个 bug:
@@ -676,7 +690,9 @@ void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
void* destination = leaf_node_cell(destination_node, index_within_node);
if (i == cursor->cell_num) {
- serialize_row(value, destination);
+ serialize_row(value,
+ leaf_node_value(destination_node, index_within_node));
+ *leaf_node_key(destination_node, index_within_node) = key;
} else if (i > cursor->cell_num) {
memcpy(destination, leaf_node_cell(old_node, i - 1), LEAF_NODE_CELL_SIZE);
} else {
请记住,叶子节点中的每个单元格首先是一个键,然后是一个值:
我们将新行(值)写入了单元格的开头,而其中应该放置键。这意味着用户名的一部分进入了 id 的部分(因此 id 很大)。
修复了这个 bug 之后,我们最终按预期打印了整个表:
db > select
(1, user1, person1@example.com)
(2, user2, person2@example.com)
(3, user3, person3@example.com)
(4, user4, person4@example.com)
(5, user5, person5@example.com)
(6, user6, person6@example.com)
(7, user7, person7@example.com)
(8, user8, person8@example.com)
(9, user9, person9@example.com)
(10, user10, person10@example.com)
(11, user11, person11@example.com)
(12, user12, person12@example.com)
(13, user13, person13@example.com)
(14, user14, person14@example.com)
(15, user15, person15@example.com)
Executed.
db >
哇!一个接一个的 bug,但我们正在取得进展。
下次再见。
第十三部分 - 分裂叶子节点后更新父节点
在我们史诗般的 B 树实现旅程中的下一步,我们将处理分裂叶子节点后修复父节点。我将使用以下示例作为参考:
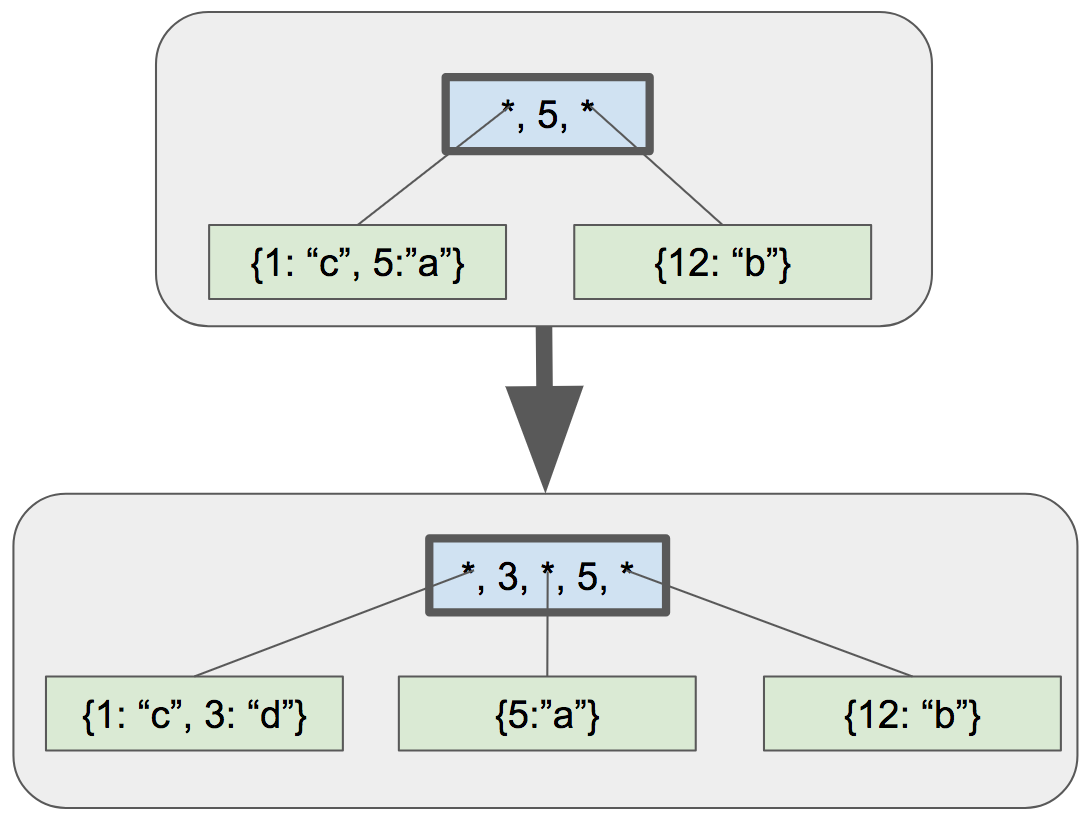
在这个示例中,我们将键“3”添加到树中。这导致左叶子节点分裂。在分裂后,我们进行以下操作来修复树:
- 将父节点中的第一个键更新为左子节点中的最大键(“3”)
- 在更新后的键之后添加一个新的子节点/键对
- 新指针指向新的子节点
- 新键是新子节点中的最大键(“5”)
首先,替换我们的存根代码为两个新的函数调用:update_internal_node_key() 用于步骤 1 和 internal_node_insert() 用于步骤 2。
@@ -670,9 +725,11 @@ void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
*/
void* old_node = get_page(cursor->table->pager, cursor->page_num);
+ uint32_t old_max = get_node_max_key(old_node);
uint32_t new_page_num = get_unused_page_num(cursor->table->pager);
void* new_node = get_page(cursor->table->pager, new_page_num);
initialize_leaf_node(new_node);
+ *node_parent(new_node) = *node_parent(old_node);
*leaf_node_next_leaf(new_node) = *leaf_node_next_leaf(old_node);
*leaf_node_next_leaf(old_node) = new_page_num;
@@ -709,8 +766,12 @@ void leaf_node_split_and_insert(Cursor* cursor, uint32_t key, Row* value) {
if (is_node_root(old_node)) {
return create_new_root(cursor->table, new_page_num);
} else {
- printf("Need to implement updating parent after split\n");
- exit(EXIT_FAILURE);
+ uint32_t parent_page_num = *node_parent(old_node);
+ uint32_t new_max = get_node_max_key(old_node);
+ void* parent = get_page(cursor->table->pager, parent_page_num);
+
+ update_internal_node_key(parent, old_max, new_max);
+ internal_node_insert(cursor->table, parent_page_num, new_page_num);
+ return;
}
}
为了获取父节点的引用,我们需要开始在每个节点中记录指向其父节点的指针。
+uint32_t* node_parent(void* node) { return node + PARENT_POINTER_OFFSET; }
@@ -660,6 +675,48 @@ void create_new_root(Table* table, uint32_t right_child_page_num) {
uint32_t left_child_max_key = get_node_max_key(left_child);
*internal_node_key(root, 0) = left_child_max_key;
*internal_node_right_child(root) = right_child_page_num;
+ *node_parent(left_child) = table->root_page_num;
+ *node_parent(right_child) = table->root_page_num;
}
现在我们需要找到受影响的父节点中的单元格。子节点不知道自己的页面号,所以我们无法查找它。但是它知道自己的最大键,所以我们可以在父节点中搜索该键。
+void update_internal_node_key(void* node, uint32_t old_key, uint32_t new_key) {
+ uint32_t old_child_index = internal_node_find_child(node, old_key);
+ *internal_node_key(node, old_child_index) = new_key;
+}
在 internal_node_find_child() 中,我们将重用已经存在的用于在内部节点中查找键的一些代码。重构 internal_node_find() 以使用新的辅助方法。
-uint32_t* internal_node_key(void* node, uint32_t key_num) {
- return internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
+uint32_t internal_node_find_child(void* node, uint32_t key) {
+ /*
+ 返回应包含给定键的子节点的索引。
+ */
+
+ uint32_t num_keys = *internal_node_num_keys(node);
+
+ /* 二分查找 */
+ uint32_t min_index = 0;
+ uint32_t max_index = num_keys; /* 子节点数比键数多一个 */
+
+ while (min_index != max_index) {
+ uint32_t index = (min_index + max_index) / 2;
+ uint32_t key_to_right = *internal_node_key(node, index);
+
+ if (key_to_right >= key) {
+ max_index = index;
+ } else {
+ min_index = index + 1;
+ }
+ }
+
+ return min_index;
}
现在让我们来看看 internal_node_insert() 的其余部分。我会分步解释。
+void internal_node_insert(Table* table, uint32_t parent_page_num,
+ uint32_t child_page_num) {
+ /*
+ 向父节点添加一个新的子节点/键对,对应于子节点
+ */
+
+ void* parent = get_page(table->pager, parent_page_num);
+ void* child = get_page(table->pager, child_page_num);
+ uint32_t child_max_key = get_node_max_key(child);
+ uint32_t index = internal_node_find_child(parent, child_max_key);
+
+ uint32_t original_num_keys = *internal_node_num_keys(parent);
+ *internal_node_num_keys(parent) = original_num_keys + 1;
+
+ if (original_num_keys >= INTERNAL_NODE_MAX_CELLS) {
+ printf("Need to implement splitting internal node\n");
+ exit(EXIT_FAILURE);
+ }
新单元格(子节点/键对)应该插入的索引取决于新子节点中的最大键。在我们查看的示例中,child_max_key 将为 5,index 将为 1。
如果内部节点没有足够的空间容纳另一个单元格,则抛出错误。稍后我们将实现这一点。
现在让我们看看函数的其余部分:
+
+ uint32_t right_child_page_num = *internal_node_right_child(parent);
+ void* right_child = get_page(table->pager, right_child_page_num);
+
+ if (child_max_key > get_node_max_key(right_child)) {
+ /* 替换右子节点 */
+ *internal_node_child(parent, original_num_keys) = right_child_page_num;
+ *internal_node_key(parent, original_num_keys) =
+ get_node_max_key(right_child);
+ *internal_node_right_child(parent) = child_page_num;
+ } else {
+ /* 为新单元格腾出空间 */
+ for (uint32_t i = original_num_keys; i > index; i--) {
+ void* destination = internal_node_cell(parent, i);
+ void* source = internal_node_cell(parent, i - 1);
+ memcpy(destination, source, INTERNAL_NODE_CELL_SIZE);
+ }
+ *internal_node_child(parent, index) = child_page_num;
+ *internal_node_key(parent, index) = child_max_key;
+ }
+}
因为我们单独存储了最右边的子节点指针和其他子节点/键对,所以如果新子节点将成为最右边的子节点,则必须以不同的方式处理事情。
在我们的示例中,我们将进入 else 块。首先,我们为新单元格腾出空间,将其他单元格向右移动一位。(尽管在我们的示例中没有要移动的单元格)
接下来,我们将新子节点指针和键写入由 index 确定的单元格。
为了减少所需的测试用例大小,我现在先硬编码 INTERNAL_NODE_MAX_CELLS。
@@ -126,6 +126,8 @@ const uint32_t INTERNAL_NODE_KEY_SIZE = sizeof(uint32_t);
const uint32_t INTERNAL_NODE_CHILD_SIZE = sizeof(uint32_t);
const uint32_t INTERNAL_NODE_CELL_SIZE =
INTERNAL_NODE_CHILD_SIZE + INTERNAL_NODE_KEY_SIZE;
+/* 为了测试,保持较小 */
+const uint32_t INTERNAL_NODE_MAX_CELLS = 3;
说到测试,我们的大型数据集测试已经通过了旧的存根,并且到达了我们的新存根:
@@ -65,7 +65,7 @@ describe 'database' do
result = run_script(script)
expect(result.last(2)).to match_array([
"db > Executed.",
- "db > Need to implement updating parent after split",
+ "db > Need to implement splitting internal node",
])
非常令人满意,我知道。
我将添加另一个测试,用于打印一个四节点树的结构。为了测试更多情况,而不仅仅是顺序 id,这个测试将以伪随机顺序添加记录。
+ it 'allows printing out the structure of a 4-leaf-node btree' do
+ script = [
+ "insert 18 user18 person18@example.com",
+ "insert 7 user7 person7@example.com",
+ "insert 10 user10 person10@example.com",
+ "insert 29 user29 person29@example.com",
+ "insert 23 user23 person23@example.com",
+ "insert 4 user4 person4@example.com",
+ "insert 14 user14 person14@example.com",
+ "insert 30 user30 person30@example.com",
+ "insert 15 user15 person15@example.com",
+ "insert 26 user26 person26@example.com",
+ "insert 22 user22 person22@example.com",
+ "insert 19 user19 person19@example.com",
+ "insert 2 user2 person2@example.com",
+ "insert 1 user1 person1@example.com",
+ "insert 21 user21 person21@example.com",
+ "insert 11 user11 person11@example.com",
+ "insert 6 user6 person6@example.com",
+ "insert 20 user20 person20@example.com",
+ "insert 5 user5 person5@example.com",
+ "insert 8 user8 person8@example.com",
+ "insert 9 user9 person9@example.com",
+ "insert 3 user3 person3@example.com",
+ "insert 12 user12 person12@example.com",
+ "insert 27 user27 person27@example.com",
+ "insert 17 user17 person17@example.com",
+ "insert 16 user16 person16@example.com",
+ "insert 13 user13 person13@example.com",
+ "insert 24 user24 person24@example.com",
+ "insert 25 user25 person25@example.com",
+ "insert 28 user28 person28@example.com",
+ ".btree",
+ ".exit",
+ ]
+ result = run_script(script)
目前,它将输出:
- internal (size 3)
- leaf (size 7)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- key 1
- leaf (size 8)
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- key 15
- leaf (size 7)
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- key 22
- leaf (size 8)
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
db >
仔细观察,您会发现一个 bug:
- 5
- 6
- 7
- key 1
那里的键应该是 7,而不是 1!
经过一番调试,我发现这是由于一些错误的指针算术引起的。
uint32_t* internal_node_key(void* node, uint32_t key_num) {
- return internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
+ return (void*)internal_node_cell(node, key_num) + INTERNAL_NODE_CHILD_SIZE;
}
INTERNAL_NODE_CHILD_SIZE 是 4。我在这里的意图是将 4 字节添加到 internal_node_cell() 的结果中,但由于 internal_node_cell() 返回一个 uint32_t*,因此实际上添加了 4 * sizeof(uint32_t) 字节。我通过在进行算术运算之前将其转换为 void* 来进行修复。
注意!C 标准中没有 void 指针的指针算术,可能无法与你的编译器一起工作。也许将来我会撰写一篇关于可移植性的文章,但目前我保留了我的 void 指针算术。
好的,又迈出了一步,朝着一个完全可操作的 B 树实现迈进。下一步应该是拆分内部节点。在那之前!
第十四部分 - 拆分内部节点
我们旅程的下一段将是拆分无法容纳新键的内部节点。考虑下面的例子:
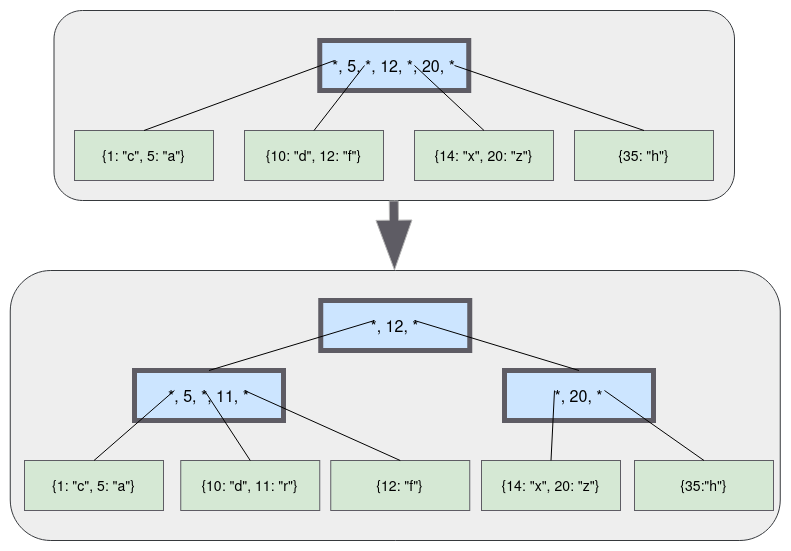
在这个例子中,我们向树中添加键“11”。这将导致我们的根节点拆分。在拆分内部节点时,为了保持一切的正常运作,我们需要做一些事情:
- 创建一个兄弟节点来存储原始节点的(n-1)/2个键
- 将这些键从原始节点移动到兄弟节点
- 更新父节点中原始节点的键,以反映其在拆分后的新最大键
- 将兄弟节点插入父节点(可能导致父节点也被拆分)
我们将首先用internal_node_split_and_insert来替换我们的存根代码:
+void internal_node_split_and_insert(Table* table, uint32_t parent_page_num,
+ uint32_t child_page_num);
+
void internal_node_insert(Table* table, uint32_t parent_page_num,
uint32_t child_page_num) {
/*
@@ -685,25 +714,39 @@ void internal_node_insert(Table* table, uint32_t parent_page_num,
void* parent = get_page(table->pager, parent_page_num);
void* child = get_page(table->pager, child_page_num);
- uint32_t child_max_key = get_node_max_key(child);
+ uint32_t child_max_key = get_node_max_key(table->pager, child);
uint32_t index = internal_node_find_child(parent, child_max_key);
uint32_t original_num_keys = *internal_node_num_keys(parent);
- *internal_node_num_keys(parent) = original_num_keys + 1;
if (original_num_keys >= INTERNAL_NODE_MAX_CELLS) {
- printf("Need to implement splitting internal node\n");
- exit(EXIT_FAILURE);
+ internal_node_split_and_insert(table, parent_page_num, child_page_num);
+ return;
}
uint32_t right_child_page_num = *internal_node_right_child(parent);
+ /*
+ An internal node with a right child of INVALID_PAGE_NUM is empty
+ */
+ if (right_child_page_num == INVALID_PAGE_NUM) {
+ *internal_node_right_child(parent) = child_page_num;
+ return;
+ }
+
void* right_child = get_page(table->pager, right_child_page_num);
+ /*
+ If we are already at the max number of cells for a node, we cannot increment
+ before splitting. Incrementing without inserting a new key/child pair
+ and immediately calling internal_node_split_and_insert has the effect
+ of creating a new key at (max_cells + 1) with an uninitialized value
+ */
+ *internal_node_num_keys(parent) = original_num_keys + 1;
- if (child_max_key > get_node_max_key(right_child)) {
+ if (child_max_key > get_node_max_key(table->pager, right_child)) {
/* Replace right child */
*internal_node_child(parent, original_num_keys) = right_child_page_num;
*internal_node_key(parent, original_num_keys) =
- get_node_max_key(right_child);
+ get_node_max_key(table->pager, right_child);
*internal_node_right_child(parent) = child_page_num;
除了替换存根之外,这里我们进行了三个重要的更改:
- 首先,
internal_node_split_and_insert被提前声明,因为我们将在其定义中调用internal_node_insert,以避免代码重复。 - 此外,我们将递增父节点的键数逻辑移到函数定义的下方,以确保在拆分之前不要执行这一步。
- 最后,我们确保将插入到空内部节点的子节点成为该内部节点的右子节点,而不执行任何其他操作,因为空的内部节点没有其他可以操作的键。
上述更改要求我们能够识别空节点 - 为此,我们首先定义一个常量,表示每个空节点的无效页面编号。
+#define INVALID_PAGE_NUM UINT32_MAX
现在,当初始化内部节点时,我们将其右子节点初始化为此无效页面编号。
@@ -330,6 +335,12 @@ void initialize_internal_node(void* node) {
set_node_type(node, NODE_INTERNAL);
set_node_root(node, false);
*internal_node_num_keys(node) = 0;
+ /*
+ Necessary because the root page number is 0; by not initializing an internal
+ node's right child to an invalid page number when initializing the node, we may
+ end up with 0 as the node's right child, which makes the node a parent of the root
+ */
+ *internal_node_right_child(node) = INVALID_PAGE_NUM;
}
这一步是必要的,因为上面的注释试图总结的问题 - 在初始化内部节点时,如果没有明确初始化右子节点字段,那么运行时该字段的值可能为0,这取决于编译器或程序执行的机器体系结构。由于我们使用0作为根页面编号,这意味着新分配的内部节点将是根的父节点。
我们在internal_node_child函数中添加了一些防护措施,在尝试访问无效页面时会引发错误。
@@ -186,9 +188,19 @@ uint32_t* internal_node_child(void* node, uint32_t child_num) {
printf("Tried to access child_num %d > num_keys %d\n", child_num, num_keys);
exit(EXIT_FAILURE);
} else if (child_num == num_keys) {
- return internal_node_right_child(node);
+ uint32_t* right_child = internal_node_right_child(node);
+ if (*right_child == INVALID_PAGE_NUM) {
+ printf("Tried to access right child of node, but was invalid page\n");
+ exit(EXIT_FAILURE);
+ }
+ return right_child;
} else {
- return internal_node_cell(node, child_num);
+ uint32_t* child = internal_node_cell(node, child_num);
+ if (*child == INVALID_PAGE_NUM) {
+ printf("Tried to access child %d of node, but was invalid page\n", child_num);
+ exit(EXIT_FAILURE);
+ }
+ return child;
}
}
我们的print_tree函数还需要添加一个防护措施,以确保我们不会尝试打印一个空节点,因为这会涉及尝试访问一个无效页面。
@@ -294,15 +305,17 @@ void print_tree(Pager* pager, uint32_t page_num, uint32_t indentation_level) {
num_keys = *internal_node_num_keys(node);
indent(indentation_level);
printf("- internal (size %d)\n", num_keys);
- for (uint32_t i = 0; i < num_keys; i++) {
- child = *internal_node_child(node, i);
+ if (num_keys > 0) {
+ for (uint32_t i = 0; i < num_keys; i++) {
+ child = *internal_node_child(node, i);
+ print_tree(pager, child, indentation_level + 1);
+
+ indent(indentation_level + 1);
+ printf("- key %d\n", *internal_node_key(node, i));
+ }
+ child = *internal_node_right_child(node);
print_tree(pager, child, indentation_level + 1);
-
- indent(indentation_level + 1);
- printf("- key %d\n", *internal_node_key(node, i));
}
- child = *internal_node_right_child(node);
- print_tree(pager, child, indentation_level + 1);
break;
}
}
现在是关于 internal_node_split_and_insert 的主要部分。我们首先提供完整的内容,然后逐步分解说明。
+void internal_node_split_and_insert(Table* table, uint32_t parent_page_num,
+ uint32_t child_page_num) {
+ uint32_t old_page_num = parent_page_num;
+ void* old_node = get_page(table->pager,parent_page_num);
+ uint32_t old_max = get_node_max_key(table->pager, old_node);
+
+ void* child = get_page(table->pager, child_page_num);
+ uint32_t child_max = get_node_max_key(table->pager, child);
+
+ uint32_t new_page_num = get_unused_page_num(table->pager);
+
+ /*
+ 在更新指针之前声明一个标志,
+ 记录此操作是否涉及分割根节点 -
+ 如果是的话,我们将在创建表的新根时插入我们新创建的节点。
+ 如果不是,我们必须在旧节点的键已转移后将新创建的节点插入其父节点。
+ 如果新创建的节点的父节点不是新初始化的根节点,我们无法这样做,
+ 因为在这种情况下,其父节点可能有除我们正在分割的旧节点之外的现有键。
+ 如果是这样,我们需要在其父节点中为新创建的节点找到一个位置,
+ 如果它还没有任何键,则无法在正确的索引处插入它
+ */
+ uint32_t splitting_root = is_node_root(old_node);
+
+ void* parent;
+ void* new_node;
+ if (splitting_root) {
+ create_new_root(table, new_page_num);
+ parent = get_page(table->pager,table->root_page_num);
+ /*
+ 如果我们正在分割根节点,我们需要将 old_node 更新为指向新根的左子节点,
+ new_page_num 已经指向新根的右子节点
+ */
+ old_page_num = *internal_node_child(parent,0);
+ old_node = get_page(table->pager, old_page_num);
+ } else {
+ parent = get_page(table->pager,*node_parent(old_node));
+ new_node = get_page(table->pager, new_page_num);
+ initialize_internal_node(new_node);
+ }
+
+ uint32_t* old_num_keys = internal_node_num_keys(old_node);
+
+ uint32_t cur_page_num = *internal_node_right_child(old_node);
+ void* cur = get_page(table->pager, cur_page_num);
+
+ /*
+ 首先将右子节点放入新节点,并将旧节点的右子节点设置为无效页码
+ */
+ internal_node_insert(table, new_page_num, cur_page_num);
+ *node_parent(cur) = new_page_num;
+ *internal_node_right_child(old_node) = INVALID_PAGE_NUM;
+ /*
+ 对于每个键,直到达到中间键,将键和子节点移动到新节点
+ */
+ for (int i = INTERNAL_NODE_MAX_CELLS - 1; i > INTERNAL_NODE_MAX_CELLS / 2; i--) {
+ cur_page_num = *internal_node_child(old_node, i);
+ cur = get_page(table->pager, cur_page_num);
+
+ internal_node_insert(table, new_page_num, cur_page_num);
+ *node_parent(cur) = new_page_num;
+
+ (*old_num_keys)--;
+ }
+
+ /*
+ 设置中间键之前的子节点,现在是最高的键,为节点的右子节点,
+ 并减少键的数量
+ */
+ *internal_node_right_child(old_node) = *internal_node_child(old_node,*old_num_keys - 1);
+ (*old_num_keys)--;
+
+ /*
+ 确定分割后的两个节点中应包含要插入的子节点,
+ 并插入子节点
+ */
+ uint32_t max_after_split = get_node_max_key(table->pager, old_node);
+
+ uint32_t destination_page_num = child_max < max_after_split ? old_page_num : new_page_num;
+
+ internal_node_insert(table, destination_page_num, child_page_num);
+ *node_parent(child) = destination_page_num;
+
+ update_internal_node_key(parent, old_max, get_node_max_key(table->pager, old_node));
+
+ if (!splitting_root) {
+ internal_node_insert(table,*node_parent(old_node),new_page_num);
+ *node_parent(new_node) = *node_parent(old_node);
+ }
+}
+
我们首先需要创建一个变量来存储我们要拆分的节点的页面编号(从这里开始称为旧节点)。这是必要的,因为如果旧节点恰好是表的根节点,则旧节点的页面编号将会改变。我们还需要记住节点的当前最大值,因为该值代表其在父节点中的键,在拆分发生后,需要更新该键为旧节点的新最大值。
+ uint32_t old_page_num = parent_page_num;
+ void* old_node = get_page(table->pager,parent_page_num);
+ uint32_t old_max = get_node_max_key(table->pager, old_node);
下一个重要步骤是基于旧节点是否为表的根节点的分支逻辑。我们需要跟踪这个值以备后用;正如注释所述,如果我们不在函数定义的开始存储这些信息,我们将遇到问题——如果我们不是拆分根节点,则无法立即将新创建的兄弟节点插入到旧节点的父节点中,因为父节点还不包含任何键,因此新节点无法正确放置在父节点中的其他键/子节点对之间,这些键/子节点对可能已经存在于父节点中,也可能不存在。
+ uint32_t splitting_root = is_node_root(old_node);
+
+ void* parent;
+ void* new_node;
+ if (splitting_root) {
+ create_new_root(table, new_page_num);
+ parent = get_page(table->pager,table->root_page_num);
+ /*
+ 如果我们在拆分根节点,我们需要更新旧节点,使其指向新根节点的左子节点,而new_page_num将指向新根节点的右子节点
+ */
+ old_page_num = *internal_node_child(parent,0);
+ old_node = get_page(table->pager, old_page_num);
+ } else {
+ parent = get_page(table->pager,*node_parent(old_node));
+ new_node = get_page(table->pager, new_page_num);
+ initialize_internal_node(new_node);
+ }
当我们解决了是否拆分根节点的问题后,我们开始将键从旧节点移动到其兄弟节点。我们必须首先移动旧节点的右子节点,并将其右子节点字段设置为无效页面编号,以表示它为空。现在,我们循环遍历旧节点剩余的键,在每次迭代中执行以下步骤:
- 获取旧节点当前索引处的键和子节点的引用
- 将子节点插入到兄弟节点中
- 更新子节点的父节点值,使其指向兄弟节点
- 减少旧节点的键数
+ uint32_t* old_num_keys = internal_node_num_keys(old_node);
+
+ uint32_t cur_page_num = *internal_node_right_child(old_node);
+ void* cur = get_page(table->pager, cur_page_num);
+
+ /*
+ 首先将右子节点放入新节点中,并将旧节点的右子节点字段设置为无效页面编号
+ */
+ internal_node_insert(table, new_page_num, cur_page_num);
+ *node_parent(cur) = new_page_num;
+ *internal_node_right_child(old_node) = INVALID_PAGE_NUM;
+ /*
+ 对于每个键,直到达到中间键,将键和子节点移动到新节点中
+ */
+ for (int i = INTERNAL_NODE_MAX_CELLS - 1; i > INTERNAL_NODE_MAX_CELLS / 2; i--) {
+ cur_page_num = *internal_node_child(old_node, i);
+ cur = get_page(table->pager, cur_page_num);
+
+ internal_node_insert(table, new_page_num, cur_page_num);
+ *node_parent(cur) = new_page_num;
+
+ (*old_num_keys)--;
+ }
第4步很重要,因为它的目的是“擦除”旧节点的键/子节点对。虽然我们实际上没有释放旧节点页面中该字节偏移量的内存,但
通过减少旧节点的键数,我们使得该内存位置无法访问,并且下次插入子节点到旧节点时,这些字节将被覆盖。
同时注意我们循环不变式的行为——如果将来我们的内部节点最大键数发生变化,我们的逻辑确保在拆分后,无论是旧节点还是兄弟节点,它们都会拥有(n-1)/2个键,而剩余的1个键会移动到父节点。如果选择偶数作为节点的最大键数,那么n/2个节点将留在旧节点,而(n-1)/2个节点将移动到兄弟节点。这种逻辑修改将会很直接。
当需要移动的键移动完成后,我们将旧节点的第i个子节点设置为其右子节点,并减少其键数。
+ /*
+ 将中间键(现在是最大键)之前的子节点设置为节点的右子节点,并减少键数
+ */
+ *internal_node_right_child(old_node) = *internal_node_child(old_node,*old_num_keys - 1);
+ (*old_num_keys)--;
然后,我们根据子节点的最大键将子节点插入到旧节点或兄弟节点中。
+ uint32_t max_after_split = get_node_max_key(table->pager, old_node);
+
+ uint32_t destination_page_num = child_max < max_after_split ? old_page_num : new_page_num;
+
+ internal_node_insert(table, destination_page_num, child_page_num);
+ *node_parent(child) = destination_page_num;
最后,我们在旧节点的父节点中更新旧节点的键,并在必要时插入兄弟节点,并更新兄弟节点的父指针。
+ update_internal_node_key(parent, old_max, get_node_max_key(table->pager, old_node));
+
+ if (!splitting_root) {
+ internal_node_insert(table,*node_parent(old_node),new_page_num);
+ *node_parent(new_node) = *node_parent(old_node);
+ }
要支持这种新逻辑的一个重要更改是在我们的create_new_root函数中进行的。以前,我们只考虑了新根节点的子节点将是叶节点的情况。如果新根节点的子节点实际上是内部节点,我们需要做两件事:
- 正确地初始化根节点的新子节点为内部节点
- 除了对memcpy的调用之外,我们还需要将根节点的每个键插入到其新左子节点中,并更新每个子节点的父指针
@@ -661,22 +680,40 @@ void create_new_root(Table* table, uint32_t right_child_page_num) {
uint32_t left_child_page_num = get_unused_page_num(table->pager);
void* left_child = get_page(table->pager, left_child_page_num);
+ if (get_node_type(root) == NODE_INTERNAL) {
+ initialize_internal_node(right_child);
+ initialize_internal_node(left_child);
+ }
+
/* 左子节点复制了旧根节点的数据 */
memcpy(left_child, root, PAGE_SIZE);
set_node_root(left_child, false);
+ if (get_node_type(left_child) == NODE_INTERNAL) {
+ void* child;
+ for (int i = 0; i < *internal_node_num_keys(left_child); i++) {
+ child = get_page(table->pager, *internal_node_child(left_child,i));
+ *node_parent(child) = left_child_page_num;
+ }
+ child = get_page(table->pager, *internal_node_right_child(left_child));
+ *node_parent(child) = left_child_page_num;
+ }
+
/* 根节点是一个新的内部节点,有一个键和两个子节点 */
initialize_internal_node(root);
set_node_root(root, true);
*internal_node_num_keys(root) = 1;
*internal_node_child(root, 0) = left_child_page_num;
- uint32_t left_child_max_key = get_node_max_key(left_child);
+ uint32_t left_child_max_key = get_node_max_key(table->pager, left_child);
*internal_node_key(root, 0) = left_child_max_key;
*internal_node_right_child(root) = right_child_page_num;
*node_parent(left_child) = table->root_page_num;
*node_parent(right_child) = table->root_page_num;
}
另一个重要更改是对get_node_max_key进行的,就像本文开头提到的一样。由于内部节点的键表示其左侧子树的最大键,并且该子树可以是任意深度的树,因此我们需要沿着该树的右子节点走下去,直到到达叶节点,然后取该叶节点的最大键。
+uint32_t get_node_max_key(Pager* pager, void* node) {
+ if (get_node_type(node) == NODE_LEAF) {
+ return *leaf_node_key(node, *leaf_node_num_cells(node) - 1);
+ }
+ void* right_child = get_page(pager,*internal_node_right_child(node));
+ return get_node_max_key(pager, right_child);
+}
我们编写了一个单一测试来证明在引入内部节点拆分后,我们的print_tree函数仍然有效。
+ it 'allows printing out the structure of a 7-leaf-node btree' do
+ script = [
+ "insert 58 user58 person58@example.com",
+ "insert 56 user56 person56@example.com",
+ "insert 8 user8 person8@example.com",
+ "insert 54 user54 person54@example.com",
+ "insert 77 user77 person77@example.com",
+ "insert 7 user7 person7@example.com",
+ "insert 25 user25 person25@example.com",
+ "insert 71 user71 person71@example.com",
+ "insert 13 user13 person13@example.com",
+ "insert 22 user22 person22@example.com",
+ "insert 53 user53 person53@example.com",
+ "insert 51 user51 person51@example.com",
+ "insert 59 user59 person59@example.com",
+ "insert 32 user32 person32@example.com",
+ "insert 36 user36 person36@example.com",
+ "insert 79 user79 person79@example.com",
+ "insert 10 user10 person10@example.com",
+ "insert 33 user33 person33@example.com",
+ "insert 20 user20 person20@example.com",
+ "insert 4 user4 person4@example.com",
+ "insert 35 user35 person35@example.com",
+ "insert 76 user76 person76@example.com",
+ "insert 49 user49 person49@example.com",
+ "insert 24 user24 person24@example.com",
+ "insert 70 user70 person70@example.com",
+ "insert 48 user48 person48@example.com",
+ "insert 39 user39 person39@example.com",
+ "insert 15 user15 person15@example.com",
+ "insert 47 user47 person47@example.com",
+ "insert 30 user30 person30@example.com",
+ "insert 86 user86 person86@example.com",
+ "insert 31 user31 person31@example.com",
+ "insert 68 user68 person68@example.com",
+ "insert 37 user37 person37@example.com",
+ "insert 66 user66 person66@example.com",
+ "insert 63 user63 person63@example.com",
+ "insert 40 user40 person40@example.com",
+ "insert 78 user78 person78@example.com",
+ "insert 19 user19 person19@example.com",
+ "insert 46 user46 person46@example.com",
+ "insert 14 user14 person14@example.com",
+ "insert 81 user81 person81@example.com",
+ "insert 72 user72 person72@example.com",
+ "insert 6 user6 person6@example.com",
+ "insert 50 user50 person50@example.com",
+ "insert 85 user85 person85@example.com",
+ "insert 67 user67 person67@example.com",
+ "insert 2 user2 person2@example.com",
+ "insert 55 user55 person55@example.com",
+ "insert 69 user69 person69@example.com",
+ "insert 5 user5 person5@example.com",
+ "insert 65 user65 person65@example.com",
+ "insert 52 user52 person52@example.com",
+ "insert 1 user1 person1@example.com",
+ "insert 29 user29 person29@example.com",
+ "insert 9 user9 person9@example.com",
+ "insert 43 user43 person43@example.com",
+ "insert 75 user75 person75@example.com",
+ "insert 21 user21 person21@example.com",
+ "insert 82 user82 person82@example.com",
+ "insert 12 user12 person12@example.com",
+ "insert 18 user18 person18@example.com",
+ "insert 60 user60 person60@example.com",
+ "insert 44 user44 person44@example.com",
+ ".btree",
+ ".exit",
+ ]
+ result = run_script(script)
+
+ expect(result[64...(result.length)]).to match_array([
+ "db > Tree:",
+ "- internal (size 1)",
+ " - internal (size 2)",
+ " - leaf (size 7)",
+ " - 1",
+ " - 2",
+ " - 4",
+ " - 5",
+ " - 6",
+ " - 7",
+ " - 8",
+ " - key 8",
+ " - leaf (size 11)",
+ " - 9",
+ " - 10",
+ " - 12",
+ " - 13",
+ " - 14",
+ " - 15",
+ " - 18",
+ " - 19",
+ " - 20",
+ " - 21",
+ " - 22",
+ " - key 22",
+ " - leaf (size 8)",
+ " - 24",
+ " - 25",
+ " - 29",
+ " - 30",
+ " - 31",
+ " - 32",
+ " - 33",
+ " - 35",
+ " - key 35",
+ " - internal (size 3)",
+ " - leaf (size 12)",
+ " - 36",
+ " - 37",
+ " - 39",
+ " - 40",
+ " - 43",
+ " - 44",
+ " - 46",
+ " - 47",
+ " - 48",
+ " - 49",
+ " - 50",
+ " - 51",
+ " - key 51",
+ " - leaf (size 11)",
+ " - 52",
+ " - 53",
+ " - 54",
+ " - 55",
+ " - 56",
+ " - 58",
+ " - 59",
+ " - 60",
+ " - 63",
+ " - 65",
+ " - 66",
+ " - key 66",
+ " - leaf (size 7)",
+ " - 67",
+ " - 68",
+ " - 69",
+ " - 70",
+ " - 71",
+ " - 72",
+ " - 75",
+ " - key 75",
+ " - leaf (size 8)",
+ " - 76",
+ " - 77",
+ " - 78",
+ " - 79",
+ " - 81",
+ " - 82",
+ " - 85",
+ " - 86",
+ "db > ",
+ ])
+ end