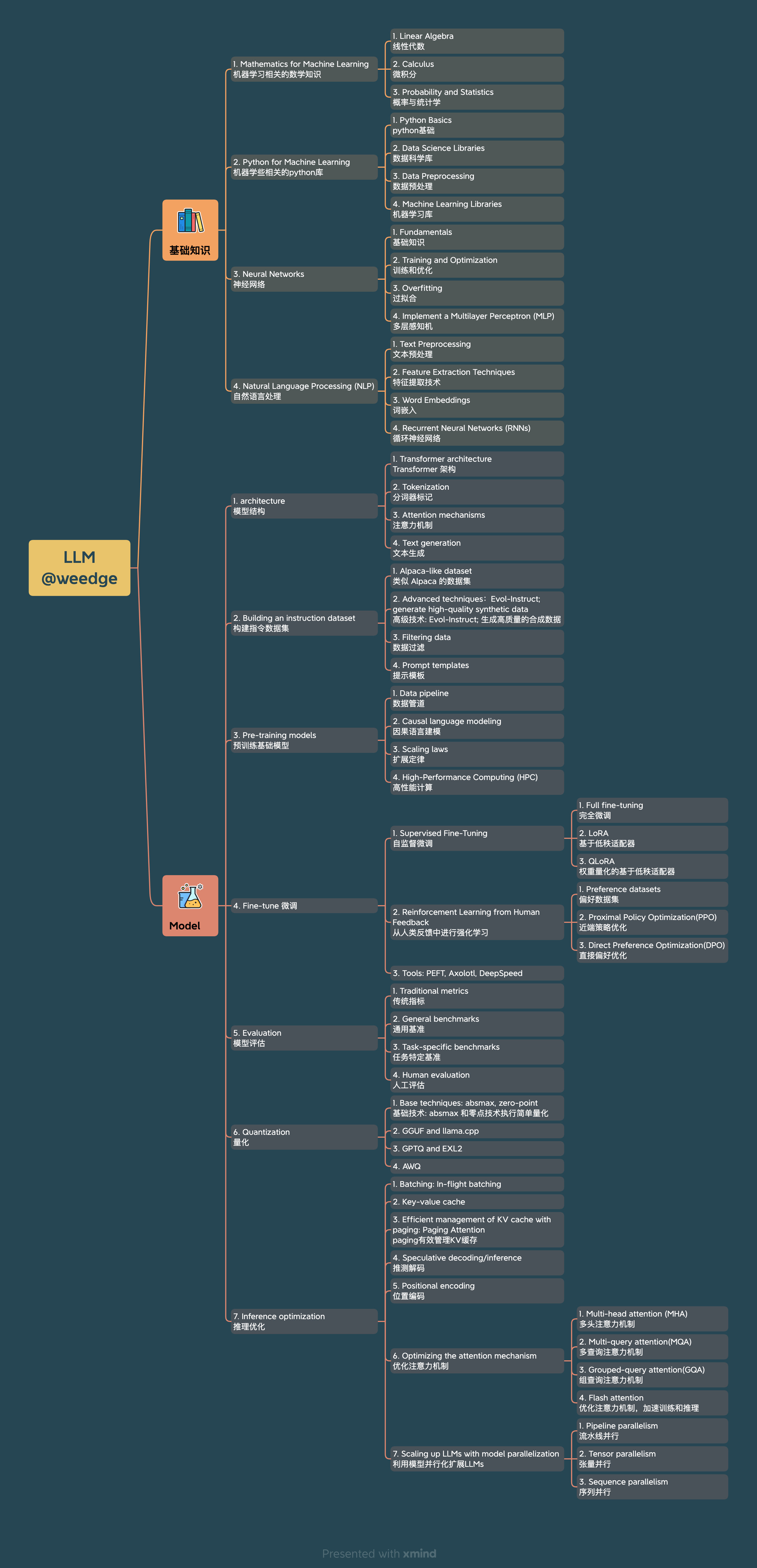
上图给出了学习LLM所需要的知识点。
该文主要是梳理LLM基础结构知识点,模型结构大多相同,以llama2模型结构为切入点,梳理相关知识点,以便构建整体知识体系,可方便快速阅读其他论文的改进点;结合参考学习中给出的链接补充基础知识。
训练推理LLM结构知识点 The LLM architecture
-
SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing tokenizer 使用 BPE 算法,将一个大的词汇表分成多个小的词汇表,然后将每个词汇表中的词汇进行编码,最后将编码后的词汇进行拼接,形成一个新的词汇表。
- https://github.com/google/sentencepiece
- 训练的分词模型 用于 模型的训练和推断
- 训练的词汇表 用于 词汇表的构建
- BPE [Sennrich et al.] llama2 使用BPE算法
- unigram language model [Kudo.]
-
定义一个神经网络Embedding嵌入权重层:torch.nn.Embedding(params.vocab_size, params.dim)
- embedding 把数据集合映射到向量空间,进而把数据进行向量化的过程
- 将稀疏向量转化为稠密向量,便于上层神经网络的处理
- 在训练的过程中 找到一组合适的向量,来刻画现有的数据集合
- 将客观世界中的物体不失真的映射到高维特征空间中,进而可以使用这些embedding向量 实现分类、回归和预测等操作
- 详细介绍:
- https://mp.weixin.qq.com/s/FsqCNPtDPMdH0WGI0niELw
- https://vickiboykis.com/what_are_embeddings/
-
定义一个全连接神经网络线性权重层:torch.nn.Linear 特征维度转化, $$y = xA^T + b$$
- 训练权重和偏置bias
- 可将输出维度变大,参数变多了,模型的拟合能力也变强
- 多层组合为多层感知机 (Multilayer Perceptron, MLP),后面接一个激活函数,
-
Root Mean Square Layer Normalization RMSNorm 归一化权重层.
- https://github.com/bzhangGo/rmsnorm
- RMSNorm 根据均方根 (RMS) 对一层神经元的输入求和进行正则化,从而赋予模型重新缩放不变性和隐式学习率自适应能力。
- RMSNorm 计算更简单,因此比 LayerNorm 更高效。
- 计算公式:
$$ \begin{align} \begin{split} & \bar{a}i = \frac{a_i}{\text{RMS}(\mathbf{a})} g_i, \quad \text{where}~~ \text{RMS}(\mathbf{a}) = \sqrt{\frac{1}{n} \sum{i=1}^{n} a_i^2}. \end{split}\nonumber \end{align} $$
-
attention is all u need, transformer 注意力机制
- MHA: multihead attention -> MQA: Multi-Query Attention -> GQA: Grouped-Query Attention(llama2-34B/70B)
- Fast Transformer Decoding: One Write-Head is All You Need MQA: Multi-Query Attention
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints 较大模型kv缓存成为瓶颈, 训练质量和MHA差不多, 但是速度快很多,与MQA相当.
- MHA简单来说就是通过多次线性投影linear projection得到原始输入的多个子空间,然后再每个子空间分别进行SDPA(Scaled Dot-Product Attention), 再把SDPA的结果进行聚合Concatenation,最后再做一个linear projection。
- SDPA的全称为Scaled Dot-Product Attention, 属于点积注意力机制, 简单一句话来说就是,根据Query (Q)与Key之间的匹配度来对Value进行加权,而事实上不管是Query, Key还是Value都来自于输入,因此所谓的SDPA本质上是对输入信息信息进行重组。
- 通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
- self-attention 自注意力机制用于计算序列中当前token关注与其他token的联系,就是一个序列内的token,互相看其他token对自己的影响力有多大
-
Enhanced Transformer with Rotary Position Embedding RoPE relative positional embeddings
-
residual connection 残差连接(residual connection)是深度神经网络中的一种常见技术,它的作用是解决梯度消失和梯度爆炸问题,同时也可以帮助模型更快地收敛。
- 在传统的神经网络中,每个层的输出都是通过对前一层输出的非线性变换得到的。但是,当网络的深度增加时,前一层的输出可能会被过度压缩或拉伸,导致信息丢失或重复。这种情况下,网络的性能可能会受到影响,同时也会出现梯度消失或梯度爆炸的问题。
- 残差连接通过在每个层的输出与输入之间添加一个跨层连接来解决这个问题。更具体地说,残差连接将前一层的输出直接添加到当前层的输出中,从而提供了一种绕过非线性变换的路径。这样,网络就可以学习到在信息压缩或拉伸后保留重要信息的方法,同时也减轻了梯度消失或梯度爆炸的问题。
-
Improving neural networks by preventing co-adaptation of feature detectors dropout 解决过拟合
- 训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低
- Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征,
-
GLU Variants Improve Transformer FFN 中激活函数SwiGLU/SiLU
-
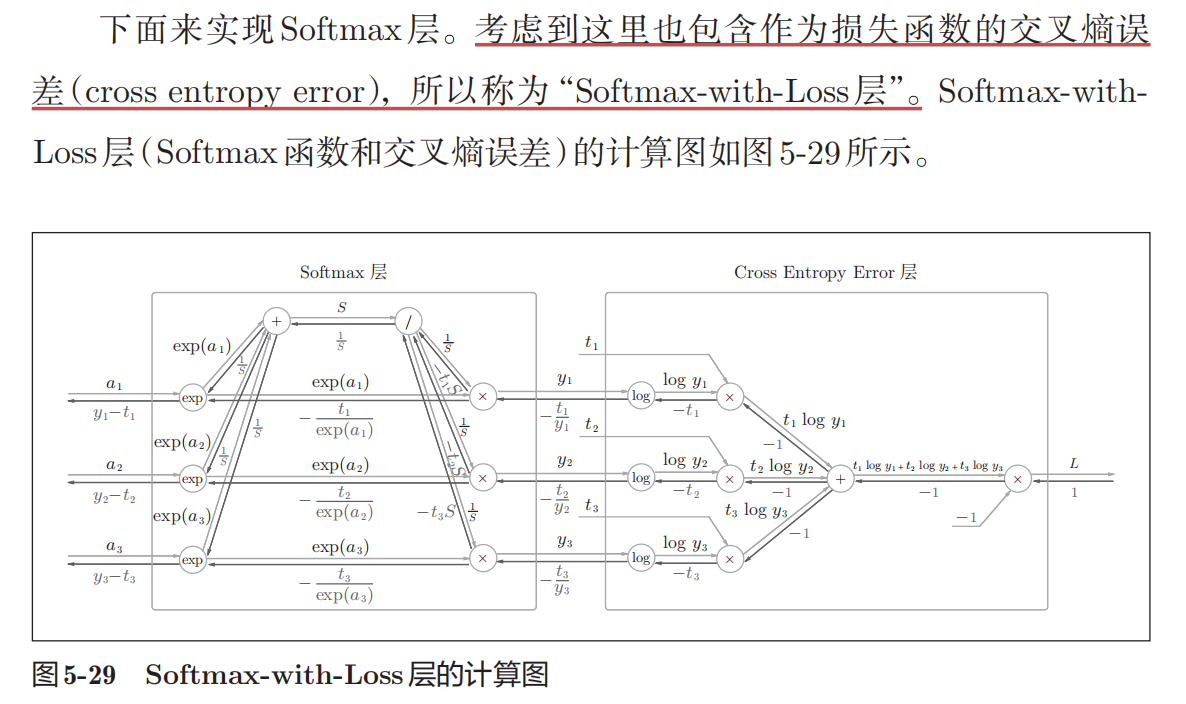
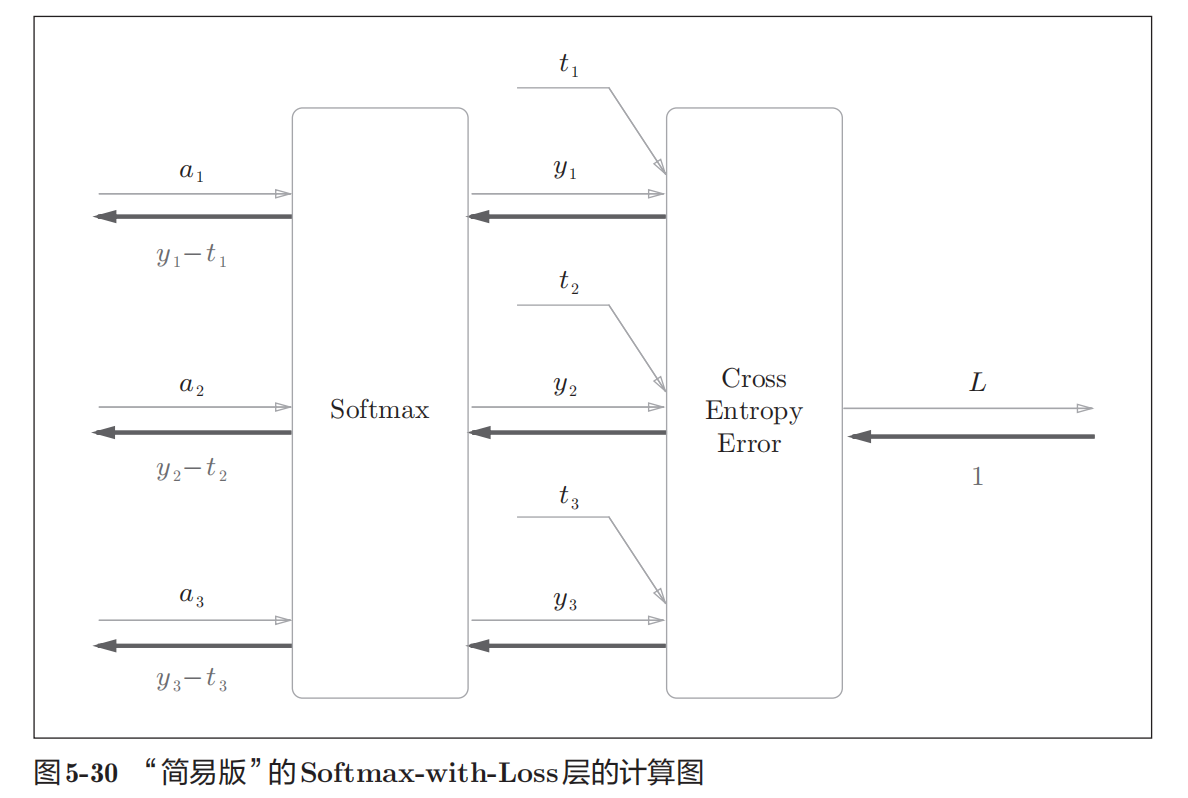
Rethinking the Inception Architecture for Computer Vision 交叉熵 cross_entropy 损失函数的计算公式: $$L = -\frac{1}{N}\sum_{i=1}^{N}t_i\log(y_i)$$
- $t_i$ 表示真实值
- $y_i$ 表示预测值
- 目的是获取输出概率($y$)并测量与真值的误差
- 一般 $t$ 为one-hot编码, 交叉熵误差值是由正确解标签所对应的输出结果决定
- 使用softmax函数(多类问题)或者sigmoid函数(二类问题)将网络的输出转换为概率
- PyTorch中它自带的命令torch.nn.functional.cross_entropy已经将转换概率值的操作整合了进去,所以不需要额外进行转换概率值的操作
-
Decoupled Weight Decay Regularization 优化器 AdamW: Adam + Weight Decay(权重衰减,抑制权重变大);
- learning rate (学习率)和weight decay (权重衰减) 参数调整,固定一个调整另一个
- 在训练llama2模型中,
- $β_1 = 0.9, β_2 = 0.95, eps = 10^{-5}$
- 权重衰减(weight_decay):0.1;梯度裁剪(gradient_clipping):1.0
- learning rate: 3e-4(7B/13B), 1.5e-4(34B/70B)
- 学习率调度器:
- SGDR: Stochastic Gradient Descent with Warm Restarts 余弦调度器。不想在一开始就太大地降低学习率,而且可能希望最终能用非常小的学习率来“改进”解决方案 ;
- 使用预热期,在此期间学习率将增加至初始最大值,然后冷却直到优化过程结束(类似tcp中流量控制机制想法);预热可以应用于任何调度器;
- https://zh-v2.d2l.ai/chapter_optimization/lr-scheduler.html#id8
-
PaLM: Scaling Language Modeling with Pathways 模型训练效率的评估工作 比如 MFU
-
Scaling Laws for Neural Language Models | Training Compute-Optimal Large Language Models 一些缩放定律结果指南,帮助确定计算最优模型。还包含用于计算浮点运算数(FLOPs)和参数数量的相关实用工具。
预训练基础模型简单概括 Pre-training models
- 训练一个神经网络(transformer结构),数据通过tokenizer分词,输入token数据embedding, 首先要跑一遍前向Forward的过程,计算wx+b线性层权重,激活函数,之后计算Loss function,利用损失函数进行Backward对参数求导得到梯度Grad,拿到Grad后扔给优化器Optimizer更新模型权重,反复迭代,直到损失函数收敛。
推理
- Inference Sampling params (top-k, top-p, temperature)
参考学习
- 《深度学习入门基于Python的理论与实现》(前2-6章相关基础知识解释,通俗易懂)
- https://vickiboykis.com/what_are_embeddings/ | 自己翻译的中文版
- http://neuralnetworksanddeeplearning.com/
- https://www.3blue1brown.com/topics/neural-networks
- https://karpathy.ai/zero-to-hero.html (nanoGPT,llama2.c)| Andrej Karpathy’s blog “Hacker’s guide to Neural Networks”
- https://courses.d2l.ai/zh-v2/ (看沐神视频学+代码运行)
- https://github.com/mlabonne/llm-course
LLMs
- GPT1: Improving Language Understanding by Generative Pre-Training
- GPT2: Language Models are Unsupervised Multitask Learners
- GPT-3: Language Models are Few-Shot Learners
- InstructGPT: Aligning language models to follow instructions
- ChatGPT | Proximal Policy Optimization Algorithms
- GPT-4 Technical Report
- LLaMA: Open and Efficient Foundation Language Models
- LLaMA 2: Open Foundation and Fine-Tuned Chat Models (GQA, GAtt for chat 长序列上下文tokens 有用,保多轮对话一致)