想把 HuggingFaceTB/cosmopedia 英文数据中的prompt和text 翻译成 中文, 然后看了下python库 deep_translator的实现, 翻译调用的是三方接口集成库, 于是使用这个库封装的谷歌翻译接口来翻译,但是三方平台接口多会有限流和接口调用频率限制,即使在代码中有容错处理, 比如常规的sleep下再调用,不影响整理处理流程,但是整体处理时间受接口限制,即使用批处理也如此,这个在大规模数据处理中使用三方接口时,经常会遇到的问题,用的三方服务,如果不升级接口服务,在技术上不太好解决; 于是选择另外一种方案,看是否有开源的翻译模型,底层模型结构一般也是Transform架构 Encoder-Decoder model ,也称sequence-to-sequence model; 比如 谷歌的T5模型, 但是推理速度受硬件条件影响,比较慢,而且原始模型不支持英文翻译成中文。
然后看了下meta nllb 模型,专门用来处理翻译的模型,单个 AI 模型中支持 200 种语言,开源地址: https://github.com/facebookresearch/fairseq/tree/nllb 模型相对现在的LLM参数量小一些,也在huggingface的Transforms库中集成 nllb-200-distilled-600M,直接可以load使用, 等等。。。 既然llm推理可以通过想llama.cpp通过加载ggml格式进行量化,在性能有少许折损的情况下降低推理成本,但是ggml gguf格式还不支持nllb模型权重文件(貌似llama.cpp只支持Transform Decoder模型结构);那就直接用Transforms库来加载facebook/nllb-200-distilled-600M 模型来批量翻译试试看;后续还尝试使用 Helsinki-NLP/opus-mt-en-zh 模型,进行了简单对比。
使用已有翻译模型推理
首先把依赖安装上
!pip install -q -U datasets deep-translator transformers
住备好实验数据, 使用 HuggingFaceTB/cosmopedia stories 数据,这里直接下载一个文件,用于测试
!huggingface-cli login
!huggingface-cli download \
--repo-type dataset HuggingFaceTB/cosmopedia data/stories/train-00000-of-00043.parquet \
--local-dir ./datas/datasets/HuggingFaceTB/cosmopedia \
--local-dir-use-symlinks False
在线服务调用(deep_translator)
这里从stories数据文件中取出100个做为测试数据,具体文件:translate.py
# https://huggingface.co/learn/nlp-course/chapter5/
from deep_translator import GoogleTranslator
from datasets import load_dataset, load_from_disk
import argparse
import time
def translate_en2cn(item):
translated = ""
try_cn = 100
while try_cn > 0:
try:
translated_prompt = GoogleTranslator(source='en', target='zh-CN').translate(
item["prompt"])
translated_text = GoogleTranslator(source='en', target='zh-CN').translate(
item["text"])
break
except Exception as e:
print("An error occurred:", e)
time.sleep(1)
try_cn -= 1
return {"text_zh": translated_text, "prompt_zh": translated_prompt}
def batch_check_data(batch):
return [len(item) != 0 for item in batch["text_zh"]]
def translate2save(src_dataset_dir: str, target_dataset_dir: str):
data = load_dataset(src_dataset_dir, split="train[:100]")
data = data.map(translate_en2cn, batched=False)
data.save_to_disk(target_dataset_dir)
print(data)
def load2check(dataset_dir):
data = load_from_disk(dataset_dir)
print("filter before", data)
data = data.filter(batch_check_data, batched=True)
print("filter after", data)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("stage", type=str, choices=["translate", "check"])
parser.add_argument("-s", "--src_dir", type=str,
help="path to src dataset dir ")
parser.add_argument("-t", "--target_dir", type=str,
help="path to target dataset dir ", required=lambda x: x is not None)
args = parser.parse_args()
if args.stage == "translate":
translate2save(args.src_dir, args.target_dir)
elif args.stage == "check":
load2check(args.target_dir)
运行翻译
# translate2save("./datas/datasets/HuggingFaceTB/cosmopedia/data/stories","/datas/datasets/HuggingFaceTB/cosmopedia_zh")
!python translate.py translate -s ./datas/datasets/HuggingFaceTB/cosmopedia/data/stories \
-t ./datas/datasets/HuggingFaceTB/cosmopedia_zh
检查翻译
#load2check("/datas/datasets/HuggingFaceTB/cosmopedia_zh")
!python translate.py check -t ./datas/datasets/HuggingFaceTB/cosmopedia_zh
使用 facebook/nllb 翻译模型
使用 facebook/nllb-200-distilled-600M 模型
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", use_auth_token=True, src_lang="eng_Latn",target_lang="zho_Hans")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", use_auth_token=True)
模型结构
M2M100ForConditionalGeneration(
(model): M2M100Model(
(shared): Embedding(256206, 1024, padding_idx=1)
(encoder): M2M100Encoder(
(embed_tokens): Embedding(256206, 1024, padding_idx=1)
(embed_positions): M2M100SinusoidalPositionalEmbedding()
(layers): ModuleList(
(0-11): 12 x M2M100EncoderLayer(
(self_attn): M2M100Attention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(activation_fn): ReLU()
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(decoder): M2M100Decoder(
(embed_tokens): Embedding(256206, 1024, padding_idx=1)
(embed_positions): M2M100SinusoidalPositionalEmbedding()
(layers): ModuleList(
(0-11): 12 x M2M100DecoderLayer(
(self_attn): M2M100Attention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(encoder_attn): M2M100Attention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(lm_head): Linear(in_features=1024, out_features=256206, bias=False)
)
进行批量推理翻译
%%time
article = [
"""
Dr. Mitchell nodded approvingly. "Yes, indeed! Fatty fish boast rich stores of omega-3 fatty acids – specifically EPA and DHA – which work miracles within our bodies.
Amongst numerous benefits, they decrease triglyceride levels, lower blood pressure, discourage plaque formation, and even suppress irregular heartbeats."
""",
"""
An intriguing idea took root in Alex's mind, blossoming rapidly into resolve. If these simple changes could make such profound differences in his life,
why stop there? Why not share this gift with others – friends, colleagues, strangers who might also benefit from understanding how food choices impact heart health?
Perhaps he could host educational events, cooking demonstrations, or write articles championing these powerful culinary tools.
Yes, he decided, that would be his mission – to spread awareness and inspire change, one plate at a time.
""",
"""
His thoughts must have shown on his face because Dr. Mitchell suddenly grinned, leaning back in her chair with satisfaction.
"Ah, I see the wheels turning in that brilliant mind of yours, Alex. Go ahead, run with it!"
""",
]
for item in article:
print(len(item))
inputs = tokenizer(article, return_tensors="pt",padding=True,truncation=True)
translated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.lang_code_to_id["zho_Hans"], max_new_tokens=1024)
tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)
使用 Helsinki-NLP/opus-mt-en-zh 模型
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_checkpoint = "Helsinki-NLP/opus-mt-en-zh"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
模型结构
MarianMTModel(
(model): MarianModel(
(shared): Embedding(65001, 512, padding_idx=65000)
(encoder): MarianEncoder(
(embed_tokens): Embedding(65001, 512, padding_idx=65000)
(embed_positions): MarianSinusoidalPositionalEmbedding(512, 512)
(layers): ModuleList(
(0-5): 6 x MarianEncoderLayer(
(self_attn): MarianAttention(
(k_proj): Linear(in_features=512, out_features=512, bias=True)
(v_proj): Linear(in_features=512, out_features=512, bias=True)
(q_proj): Linear(in_features=512, out_features=512, bias=True)
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(self_attn_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(activation_fn): SiLU()
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
)
(decoder): MarianDecoder(
(embed_tokens): Embedding(65001, 512, padding_idx=65000)
(embed_positions): MarianSinusoidalPositionalEmbedding(512, 512)
(layers): ModuleList(
(0-5): 6 x MarianDecoderLayer(
(self_attn): MarianAttention(
(k_proj): Linear(in_features=512, out_features=512, bias=True)
(v_proj): Linear(in_features=512, out_features=512, bias=True)
(q_proj): Linear(in_features=512, out_features=512, bias=True)
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(activation_fn): SiLU()
(self_attn_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(encoder_attn): MarianAttention(
(k_proj): Linear(in_features=512, out_features=512, bias=True)
(v_proj): Linear(in_features=512, out_features=512, bias=True)
(q_proj): Linear(in_features=512, out_features=512, bias=True)
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
)
)
(lm_head): Linear(in_features=512, out_features=65001, bias=False)
)
批量推理翻译
%%time
#text = ["In terms of time, the Chinese space station was built more than 20 years later than the International Space Station.","hello world."]
article = [
"""
Dr. Mitchell nodded approvingly. "Yes, indeed! Fatty fish boast rich stores of omega-3 fatty acids – specifically EPA and DHA – which work miracles within our bodies.
Amongst numerous benefits, they decrease triglyceride levels, lower blood pressure, discourage plaque formation, and even suppress irregular heartbeats."
""",
"""
An intriguing idea took root in Alex's mind, blossoming rapidly into resolve. If these simple changes could make such profound differences in his life,
why stop there? Why not share this gift with others – friends, colleagues, strangers who might also benefit from understanding how food choices impact heart health?
Perhaps he could host educational events, cooking demonstrations, or write articles championing these powerful culinary tools.
Yes, he decided, that would be his mission – to spread awareness and inspire change, one plate at a time.
""",
"""
His thoughts must have shown on his face because Dr. Mitchell suddenly grinned, leaning back in her chair with satisfaction.
"Ah, I see the wheels turning in that brilliant mind of yours, Alex. Go ahead, run with it!"
""",
]
for item in article:
print(len(item))
# Tokenize the text
inputs = tokenizer(article, return_tensors="pt",padding=True,truncation=True).input_ids
# Perform the translation and decode the output
translation = model.generate(inputs, max_new_tokens=512, do_sample=True, top_k=30, top_p=0.95)
result = tokenizer.batch_decode(translation, skip_special_tokens=True)
print(result)
pipeline 适合离线任务流,批量翻译
%%time
from transformers import pipeline
article = [
"""
Dr. Mitchell nodded approvingly. "Yes, indeed! Fatty fish boast rich stores of omega-3 fatty acids – specifically EPA and DHA – which work miracles within our bodies.
Amongst numerous benefits, they decrease triglyceride levels, lower blood pressure, discourage plaque formation, and even suppress irregular heartbeats."
""",
"""
An intriguing idea took root in Alex's mind, blossoming rapidly into resolve. If these simple changes could make such profound differences in his life,
why stop there? Why not share this gift with others – friends, colleagues, strangers who might also benefit from understanding how food choices impact heart health?
Perhaps he could host educational events, cooking demonstrations, or write articles championing these powerful culinary tools.
Yes, he decided, that would be his mission – to spread awareness and inspire change, one plate at a time.
""",
"""
His thoughts must have shown on his face because Dr. Mitchell suddenly grinned, leaning back in her chair with satisfaction.
"Ah, I see the wheels turning in that brilliant mind of yours, Alex. Go ahead, run with it!"
""",
]
for item in article:
print(len(item))
translator = pipeline("translation", model=model_checkpoint, max_length=1024)
res=translator(article)
print(res)
如果在翻译过程中,发现一些badcase, 可以在已有预训练好模型的基础上进行微调,比如这里使用的 Helsinki-NLP/opus-mt-en-zh
使用WMT19数据集微调训练 Helsinki-NLP/opus-mt-en-zh 翻译模型
本节将介绍如何为翻译任务微调一个🤗Transformers模型。我们将使用WMT19数据集,这是一个由各种来源组成的机器翻译数据集,包括新闻评论和议会会议记录。
安装依赖
安装🤗 Transformers和🤗 Datasets 以及模型训练翻译评估evaluate sacrebleu, 用于加速训练的 accelerate;还有个机器翻译的 sacremoses库, 需要执行以下命令:
! pip install -q transformers datasets evaluate sacrebleu accelerate sacremoses
如果您在本地打开这个笔记本,请确保您的环境已经安装了这些库的最新版本。
为了能够通过推理API与社区共享您的模型并生成如下图所示的结果,您还需要遵循一些额外的步骤。
-
需要从Hugging Face网站存储您的认证令牌,然后执行下面的单元格并输入您的用户名和密码;或者在colab中执行时加入秘钥 HF_TOKEN
-
接下来需要安装Git-LFS:
apt install git-lfs -
请确保你使用的transformers版本不低于4.11.0,因为该功能是在4.11.0版本中引入的:
import transformers print(transformers.__version__)可以在这里找到此笔记本的脚本版本,以分布式方式使用多个gpu或tpu微调您的模型。
-
上传一些监控数据(telemetry)——这告诉我们正在使用哪些示例和软件版本,以便我们知道在哪里优先进行维护工作。我们不收集(或关心)任何个人身份信息,但如果您希望不被计算在内,请随时跳过此步骤或完全删除此单元格。
from transformers.utils import send_example_telemetry send_example_telemetry("translation_notebook", framework="pytorch")
加载wmt19数据集
我们将使用🤗Datasets库下载数据并获得我们需要用于评估的指标(将我们的模型与基准进行比较)。这可以通过load_dataset和load_metric函数轻松实现。这里我们使用haggingface datasets WMT19数据集的英语/中文(zh-en)部分 19M 条数据, 这里使用train 训练数据集的前100,0000条作为训练数据, 其中20%的数据用于测试。
from datasets import load_dataset
raw_datasets = load_dataset("wmt19", "zh-en")
#raw_datasets = load_dataset("wmt19", "zh-en",split="train[:1000]")
#raw_datasets = load_dataset("wmt19", "zh-en",split="train[:1000000]")
print(raw_datasets)
# 取样一部分用来训练测试
train_datasets = raw_datasets["train"].train_test_split(train_size=100000,test_size=1000)
train_datasets["validation"] = raw_datasets["validation"]
print(train_datasets)
#要访问一个实际的元素,首先需要选择一个切分,然后给出一个索引:
print(train_datasets["train"][0])
print(train_datasets["test"][0])
print(train_datasets["validation"][0])
为了对数据的形状有一个大致的了解,下面的函数将展示一些从数据集中随机选取的示例。
import datasets
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=5):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, datasets.ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
show_random_elements(train_datasets["train"])
show_random_elements(train_datasets["test"])
show_random_elements(train_datasets["validation"])
load_metric 返回datasets.Metric实例:
from datasets import load_metric
metric = load_metric("sacrebleu")
print(metric)
在Hugging Face的Datasets库中,datasets.Metric是一个用于评估模型性能的类。它提供了一种标准化的方式来计算和报告模型在特定任务上的性能指标,例如准确度、精确度、召回率或F1分数等。 通过使用datasets.Metric类,您可以确保您的评估过程与其他人的工作保持一致,并且可以轻松地与其他模型或结果进行比较。这个类封装了计算指标所需的所有逻辑,因此您只需要提供模型的预测结果和真实的标签,它就会为您计算出相应的性能指标。 此外,datasets.Metric类还支持多种不同的评估指标,并且可以轻松地扩展以支持更多的指标。这使得它成为一个非常灵活和强大的工具,适用于各种不同的自然语言处理任务和评估场景。
您可以使用您的预测结果和标签调用其compute方法,这些预测结果和标签需要是解码后的字符串列表(labels为列表的列表):
fake_preds = ["hello there", "general kenobi"]
fake_labels = [["hello there"], ["general kenobi"]]
metric.compute(predictions=fake_preds, references=fake_labels)
在训练过程中包含一个度量标准通常有助于评估模型的性能。您可以使用 🤗 Evaluate 库快速加载一个评估方法。对于这个任务,加载 SacreBLEU 度量标准(查看 🤗 Evaluate 快速入门 以了解如何加载和计算度量标准);
注:验证/测试循环负责评估模型的性能。对于翻译任务,经典的评估指标是 Kishore Papineni 等人在《BLEU: a Method for Automatic Evaluation of Machine Translation》中提出的 BLEU 值,用于度量两个词语序列之间的一致性,但是其并不会衡量语义连贯性或者语法正确性。
由于计算 BLEU 值需要输入分好词的文本,而不同的分词方式会对结果造成影响,因此现在更常用的评估指标是 SacreBLEU,它对分词的过程进行了标准化。SacreBLEU 直接以未分词的文本作为输入,并且对于同一个输入可以接受多个目标作为参考。
预处理数据
在我们将这些文本输入模型之前,我们需要对它们进行预处理。这是通过🤗 Transformers的Tokenizer完成的,它将(正如其名称所示)对输入进行分词(包括将分词转换为预训练词汇表中对应的ID)并将其置于模型期望的格式中,同时生成模型所需的其他输入。
为了完成所有这些工作,我们使用AutoTokenizer.from_pretrained方法实例化我们的分词器,这将确保:
- 我们获得与我们想要使用的模型架构相对应的分词器,
- 我们下载了预训练这个特定检查点时使用的词汇表。
这个词汇表将被缓存,因此下次我们运行单元格时不会再次下载。
通过使用AutoTokenizer.from_pretrained方法,我们可以轻松地加载与特定模型架构相匹配的分词器,而无需担心词汇表的下载和处理。这不仅简化了预处理步骤,还提高了效率,因为缓存的词汇表可以在后续的运行中重复使用,避免了重复下载的开销。
一旦我们有了分词器,我们就可以对数据集中的文本进行分词处理,将它们转换成模型能够理解的格式。这通常包括将文本分割成单独的单词或子词单元(tokens),将这些单元转换为数值ID,并将它们组合成适合模型输入的批次。
此外,分词器还可以处理其他与模型输入相关的任务,例如添加必要的特殊标记(如开始、结束或分隔符标记),填充或截断序列以确保一致的输入长度,以及生成注意力掩码等。
总之,分词器在将原始文本数据转换为模型可以处理的格式方面发挥着关键作用,是自然语言处理任务中不可或缺的一部分。通过使用Hugging Face的Transformers库中的AutoTokenizer,我们可以轻松地为各种模型架构进行高效的文本预处理。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
tokenizer("Hello, this one sentence!")
默认情况下,上面的调用将使用🤗tokenizers库中的一个快速分词器(底层由Rust封装支持 )。
根据您选择的模型,您将在上述单元格返回的字典中看到不同的键。对于我们在这里要做的事情,它们并不重要(只需知道它们是我们稍后将实例化的模型所需的),如果您感兴趣,可以在这个教程中了解更多关于它们的信息。
我们可以传递一个句子列表,而不仅仅是一个句子:
test_token=tokenizer(["Hello, this one sentence!", "This is another sentence.","hello"],return_tensors="pt",padding=True,truncation=True).input_ids
print(test_token)
在模型预测出的标签序列与答案标签序列之间计算损失来调整模型参数,因此我们同样需要将填充的 pad 字符设置为 -100,以便在使用交叉熵计算序列损失时将它们忽略:
import torch
torch.where(test_token == tokenizer.pad_token_id, -100, test_token)
print(test_token)
end_token_index = torch.where(test_token == tokenizer.eos_token_id)[1]
print(end_token_index)
for idx, end_idx in enumerate(end_token_index):
print(idx,end_idx)
test_token[idx][end_idx+1:] = -100
print(test_token)
为了准备我们模型的目标序列,我们需要在as_target_tokenizer上下文管理器中对它们进行分词。这样可以确保分词器使用与目标相对应的特殊标记:
在进行机器翻译或其他序列到序列任务时,通常需要对目标序列(例如,翻译目标语言的句子)进行分词处理。为了确保目标序列的分词正确地使用了特殊标记(如开始、结束、分隔符等),我们可以使用as_target_tokenizer上下文管理器。
下面是一个如何使用as_target_tokenizer来对目标序列进行分词的示例:
from transformers import AutoTokenizer
# 假设您已经加载了适合您模型的分词器
tokenizer = AutoTokenizer.from_pretrained("model-name-or-path")
# 目标序列列表
targets = ["The translated sentence.", "Another translated sentence."]
# 使用as_target_tokenizer上下文管理器进行分词
with tokenizer.as_target_tokenizer():
# 对目标序列进行分词
encoded_targets = tokenizer(targets, padding=True, truncation=True, return_tensors="pt")
# 后续transforms升级使用 text_target 参数
# print(tokenizer(text_target=["Hello, this one sentence!", "This is another sentence."],return_tensors="pt",padding=True,truncation=True))
# 现在encoded_targets包含了分词后的目标序列,可以使用它们作为模型的目标输入
在这个例子中,我们首先加载了一个适合我们模型的分词器。然后,我们创建了一个包含目标序列的列表targets。通过使用as_target_tokenizer上下文管理器,我们确保了在对目标序列进行分词时,分词器使用了正确的特殊标记。
在上下文管理器的作用下,我们调用了tokenizer方法对目标序列进行分词,并通过padding参数对序列进行填充,truncation参数截断较长的序列,return_tensors参数设置为"pt"表示返回的是PyTorch张量格式。
最后,encoded_targets将包含分词后的目标序列,它们已经转换成了模型所需的格式,可以直接用于模型训练或评估时的目标输入。通过这种方式,我们可以确保目标序列的分词与模型的期望相匹配,从而提高模型的性能。
然后我们可以编写一个函数来预处理我们的样本。我们只需将它们传递给tokenizer,并使用参数truncation=True。这将确保如果输入长度超过了模型能够处理的最大长度,它将被截断到模型所能接受的最大长度。填充操作将在后续处理中进行(通过数据整理器),因此我们只需将样本填充到批次中的最长长度,而不是整个数据集的长度。
以下是一个预处理样本的函数示例:
from transformers import AutoTokenizer
# 假设您已经加载了适合您模型的分词器
tokenizer = AutoTokenizer.from_pretrained("model-name-or-path")
def preprocess_samples(samples):
"""
对样本列表进行预处理,包括分词和截断。
参数:
samples (list): 要预处理的样本列表。
返回:
list: 预处理后的样本列表。
"""
# 使用分词器对样本进行分词和截断
encoded_inputs = tokenizer(samples, truncation=True, padding='max_length', max_length=512, return_tensors="pt")
return encoded_inputs
# 示例:预处理一些样本
samples = ["The first sample text.", "A longer sample text that might need to be truncated."]
preprocessed_samples = preprocess_samples(samples)
# 预处理后的样本现在可以直接用于模型的输入
在这个函数中,我们首先加载了一个适合我们模型的分词器。然后,我们定义了一个preprocess_samples函数,它接受一个样本列表作为输入,使用分词器对每个样本进行分词和截断。
我们通过设置padding='max_length'来指定所有样本都应该填充到批次中的最大长度,而max_length参数设置了这个长度的具体值。在这个例子中,我们将其设置为512,这是一个常用的长度限制值,但您应该根据您的模型和任务需求来调整这个值。
return_tensors="pt"参数表示我们希望返回的是PyTorch张量格式,这样我们就可以直接将预处理后的数据传递给PyTorch模型。
最后,preprocessed_samples将包含预处理后的样本,它们已经转换成了模型所需的格式,可以直接用于模型的输入。通过这种方式,我们可以确保所有输入数据都符合模型的预期格式,并且处理了过长的输入,使得模型能够高效地处理它们。
具体实现:
import torch
max_input_length = 512
max_target_length = 512
source_lang = "en"
target_lang = "zh"
def preprocess_function(examples):
inputs = [prefix + ex[source_lang] for ex in examples["translation"]]
targets = [ex[target_lang] for ex in examples["translation"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True, padding=True,return_tensors="pt")
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels_input_ids = tokenizer(targets, max_length=max_target_length, truncation=True, padding=True,return_tensors="pt").input_ids
end_token_index = torch.where(labels_input_ids == tokenizer.eos_token_id)[1]
for idx, end_idx in enumerate(end_token_index):
labels_input_ids[idx][end_idx+1:] = -100
model_inputs["labels"] = labels_input_ids
return model_inputs
要将此函数应用于数据集中的所有句子对,我们只需使用之前创建的dataset对象的map方法。这将对dataset中所有划分的所有元素应用该函数,因此我们的训练、验证和测试数据将在一个命令中预处理。
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True, load_from_cache_file=False,remove_columns=["translation"])
print(tokenized_datasets)
DatasetDict({
train: Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 100000
})
test: Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 1000
})
validation: Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 3981
})
})
更好的是,🤗数据集库会自动缓存结果,以避免下次运行笔记本时在这一步上花费时间。🤗数据集库通常足够智能,可以检测传递给map的函数何时发生了变化(因此需要不使用缓存数据)。例如,它会正确地检测你是否更改了第一个单元格中的任务并重新运行notebook。🤗数据集警告您,当它使用缓存文件时,您可以在调用map时传递load_from_cache_file=False,以不使用缓存文件,并强制再次应用预处理。
注意,我们传入batched=True来将文本按批次编码在一起。这是为了充分利用前面加载的快速分词器的优势,它将使用多线程并发地处理一批文本。更多操作见NLP课程中的datasets库操作 Huggingface NLP course datasets lib
微调模型
现在我们的数据已经准备好了,我们可以下载预训练模型并对其进行微调。由于我们的任务是序列到序列的类型,我们使用AutoModelForSeq2SeqLM类。与tokenizer一样,from_pretrained方法将为我们下载并缓存模型。
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
首先用wmt19本身的验证集来来测试下未微调的模型 BLEU得分,SacreBLEU 默认会采用 mteval-v13a.pl 分词器对文本进行分词,但是它无法处理中文、日文等非拉丁系语言。对于中文就需要设置参数 tokenize=‘zh’ 手动使用中文分词器,否则会计算出不正确的 BLEU 值,以下是使用 原始的 sacrebleu库中metrics BLEU来评估处理:
from sacrebleu.metrics import BLEU
from tqdm import tqdm
bleu = BLEU(tokenize='zh')
#应该使用批处理方式,验证数据集前100个进行评估
validation_examples = train_datasets['validation'][:100]
batch_data=preprocess_function(validation_examples)
print(batch_data["input_ids"].shape)
generated_tokens = model.generate(batch_data["input_ids"].to("cuda"), max_new_tokens=1024, do_sample=True, top_k=30, top_p=0.95)
label_tokens = batch_data["labels"]
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
label_tokens = np.where(label_tokens != -100, label_tokens, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(label_tokens, skip_special_tokens=True)
preds = [pred.strip() for pred in decoded_preds]
labels = [[label.strip()] for label in decoded_labels]
bleu_score = bleu.corpus_score(preds, labels).score
print(f"BLEU: {bleu_score:>0.2f}\n")
BLEU: 12.70
在该数据集测试下分数不高
可以直接使用HF的 evaluate库,通过加载验证数据集,对模型进行打分,具体操作见文档:https://huggingface.co/docs/evaluate/index,操作如下:
from transformers import pipeline
from datasets import load_dataset
from evaluate import evaluator
import evaluate
#pipe = pipeline("translation", model=model_checkpoint, device=0)
#data = raw_datasets["validation"].shuffle().select(range(1000))
#metric = load_metric("sacrebleu")
#eval = evaluator("translation")
#results = eval.compute(model_or_pipeline=model, data=train_datasets["validation"], metric=metric)
#print(results)
注: https://huggingface.co/docs/evaluate/considerations 评估注意事项
注意,我们没有像分类示例那样得到警告。这意味着我们使用了预训练模型的所有权重,在这种情况下没有随机初始化头部。
要实例化一个Seq2SeqTrainer,我们还需要定义三件事。最重要的是Seq2SeqTrainingArguments,这是一个包含所有自定义训练属性的类。它需要一个文件夹名,用于保存模型的检查点,其他所有参数都是可选的:
batch_size = 16
model_name = model_checkpoint.split("/")[-1]
args = Seq2SeqTrainingArguments(
f"{model_name}-finetuned-{source_lang}-to-{target_lang}",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True,
fp16=True,
push_to_hub=True,
)
在这里,我们将评估设置为在每个epoch结束时完成,调整学习率,使用单元顶部定义的batch_size并自定义权重衰减。由于Seq2SeqTrainer将定期保存模型,并且我们的数据集非常大,我们告诉它最多保存三次。最后,我们使用predict_with_generate选项(以正确地生成摘要)并激活混合精度训练(以更快一些)。
附:问chatGPT参数回答内容:(相对于查文档方便很多,如果公共数据如果能被chatGPT学习到,对于复杂问题检索是很方便的,没有的话需要外挂检索系统帮忙填充上下文来Q&A)
这些参数是用于配置序列到序列(Seq2Seq)训练的相关设置。下面是各个参数的含义:
1. `output_dir`: 模型和训练过程中产生的文件的输出目录。模型训练完成后,训练的权重、日志文件等将保存在该目录下。
2. `evaluation_strategy`: 评估策略,指定模型何时进行评估。在这个例子中设置为 `"epoch"`,表示每个训练轮次结束时进行一次评估。其他选项还包括 `"steps"`(根据步数进行评估)和 `"no"`(不进行评估)。
3. `learning_rate`: 学习率,控制模型参数更新的速度。在训练过程中,模型参数根据损失函数的梯度和学习率进行更新。
4. `per_device_train_batch_size`: 每个设备上的训练批次大小。指定模型在每个设备上同时处理的训练样本数。
5. `per_device_eval_batch_size`: 每个设备上的评估批次大小。类似于训练批次大小,但用于评估阶段。
6. `weight_decay`: 权重衰减(L2正则化)参数,用于控制模型参数的正则化程度,以减少过拟合。
7. `save_total_limit`: 最大保存模型检查点数量。当训练期间保存模型检查点时,这个参数指定了保留的检查点数量。
8. `num_train_epochs`: 训练的轮次数,即模型将遍历整个训练数据集的次数。
9. `predict_with_generate`: 是否使用生成方式进行预测。在序列到序列模型中,可以选择直接对目标序列进行生成预测,而不是采用传统的分类/回归预测方式。
10. `fp16`: 是否使用混合精度训练。混合精度训练利用半精度浮点数(16位)来加速模型训练过程,降低显存占用。
11. `push_to_hub`: 是否将模型推送到 Hugging Face 模型中心。如果设置为 `True`,训练完成后,模型将被上传到 Hugging Face 模型中心,供其他用户使用和共享。
这些参数可以根据具体任务和需求进行调整,以获得最佳的模型训练效果。
注:这些参数原理进一步了解的话,可以直接查看Transforms库对应源码,会有相关的论文给出。
最后一个参数设置一切,以便我们可以在训练期间定期将模型推送到Hub。如果没有按照笔记本顶部的安装步骤操作,请删除它。如果你想将你的模型保存在本地的名称与它将被推送的存储库的名称不同,或者如果你想将你的模型推送到一个组织而不是你的名称空间下,使用hub_model_id参数来设置仓库名称(它需要是完整的名称,包括你的命名空间:例如weege007/opus-mt-en-zh-finetuned-en-to-zh)。
然后,我们需要一种特殊的数据整理器,它不仅会将输入填充到批数据的最大长度,还会将标签填充到最大长度:
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
为Seq2SeqTrainer定义的最后一件事是如何根据预测计算指标。我们需要为此定义一个函数,它将使用我们之前加载的metric,并且我们必须进行一些预处理以将预测结果解码为文本:
import numpy as np
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
然后我们只需要将所有这些以及我们的数据集传递给Seq2SeqTrainer:
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
现在我们可以通过调用train方法来微调我们的模型:
trainer.train()
你现在可以将训练结果上传到Hub, 比如我的HF上的模型地址 https://huggingface.co/weege007/opus-mt-en-zh-finetuned-en-to-zh ,只需执行此指令:
trainer.push_to_hub()
训练的时候会上传训练好的 checkpoint 模型权重到模型hub库中, 最后一步是把生成的readme 和配置文件generation_config.json上传到 huggingface models hub 。
通过: https://huggingface.co/weege007/opus-mt-en-zh-finetuned-en-to-zh/tensorboard 查看训练过程loss等监控指标信息
你现在可以与你的所有朋友、家人、最喜欢的宠物共享这个模型:他们都可以使用标识符"your-username/the-name-you-picked"来加载它,例如:
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("weege007/opus-mt-en-zh-finetuned-en-to-zh")
使用微调训练好的模型进行推理翻译
很好,现在你已经对模型进行了微调,你可以使用它进行推理!
想出一些你想翻译成另一种语言的文本。
PS: 对于T5,您需要根据您正在处理的任务为输入添加前缀。为了从英语翻译到中文,你应该像下面这样在输入前加上前缀:
text = ["hello.","translate English to Chinese: Legumes share resources with nitrogen-fixing bacteria."]
尝试用于推理的微调模型的最简单方法是在pipeline()中使用它。用你的模型实例化一个用于翻译的pipeline,并将你的文本传递给它:
from transformers import pipeline
checkpoint = "weege007/opus-mt-en-zh-finetuned-en-to-zh"
#translator = pipeline("translation_en_to_zh", model=checkpoint, max_length=1024)
translator = pipeline("translation", model=checkpoint, max_length=1024)
translator(text)
如果你愿意,你也可以手动复制pipeline的结果: 将文本分词并将input_ids作为PyTorch张量返回:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 注意如果是多个文本,长度不一样,需要padding, truncation
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True).input_ids
print(inputs)
使用generate()方法创建翻译。有关控制生成的不同文本生成策略和参数的更多详细信息,请查看text generation API。
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
outputs = model.generate(inputs, max_new_tokens=1024, do_sample=True, top_k=30, top_p=0.95)
outputs
将生成的token id解码为文本:
#tokenizer.decode(outputs[0], skip_special_tokens=True)
#tokenizer.decode(outputs[1], skip_special_tokens=True)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
重新评估下:
from sacrebleu.metrics import BLEU
from tqdm import tqdm
bleu = BLEU(tokenize='zh')
#应该使用批处理方式,验证数据集前100个进行评估
validation_examples = train_datasets['validation'][:100]
batch_data=preprocess_function(validation_examples)
print(batch_data["input_ids"].shape)
generated_tokens = model.generate(batch_data["input_ids"], max_new_tokens=1024, do_sample=True, top_k=30, top_p=0.95)
label_tokens = batch_data["labels"]
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
label_tokens = np.where(label_tokens != -100, label_tokens, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(label_tokens, skip_special_tokens=True)
preds = [pred.strip() for pred in decoded_preds]
labels = [[label.strip()] for label in decoded_labels]
bleu_score = bleu.corpus_score(preds, labels).score
print(f"BLEU: {bleu_score:>0.2f}\n")
BLEU: 23.64 ;从原来的BLEU: 12.70 提高到 23.64 ;为了方便快速测试, 这里仅仅用了10万训练集进行训练,1000测试集进行测试,100验证集用来评估;(整体训练集19M条训练集数据,3981条验证集数据)
总结
facebook/nllb-200-distilled-600M 模型 翻译 效果一般,Helsinki-NLP/opus-mt-en-zh 整体效果还可以;以上翻译文本受文本长度限制,中文token可能由一个或者多个字组成(比如:“一种”),需要对长文本进行切割,然后在批量翻译,最后在组合;
在本地部署模型翻译的方式pass,需要加载参数大模型才能有好的翻译效果(和硬件无关,和模型推理有关), 而且推理速度需要硬件GPU来加持,会有模型调参实现成本和计算成本在;
- 如果有机器硬件支持推理翻译加速,可以选用本地批量翻译的方式
- 如果使用三方翻译接口,批量处理就会受制于接口的限制(限速,翻译文本长度,并发请求数等等)
- 也上处理在单机情况下,如果有条件(大厂多有分布式计算平台可供提交,或者基于云服务花些钱搞定),通过M/R 分布式并行处理数据,sink pipeline 对接到最终数据格式(parquet/arrow 列存),这样可以方便类似bigquery(bigtable)的AP数据库load数据进行建表查询分析(udfs算子);也可以方便后续机器学习平台(autoML)对接进行模型训练。
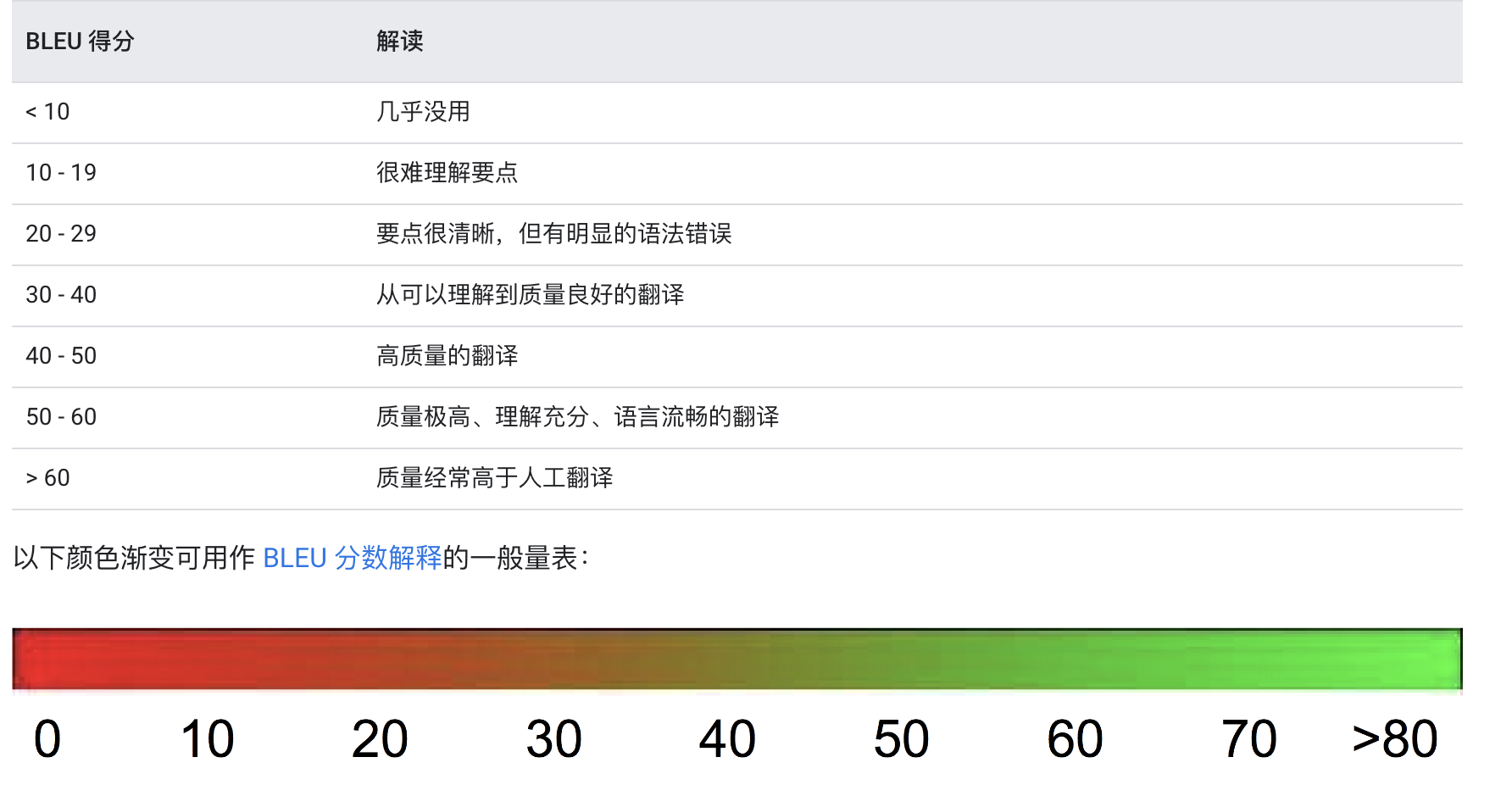
这里没有使用T5来进行英文到中文的微调,因为T5模型本身不支持英文到中文翻译,需要基于T5模型结构,使用英文-中文数据集,去训练tokenizer,然后分好词之后喂给模型进行预训练,训练周期长(mt5暂时没有考虑);这里选择已有英文到中文的翻译模型Helsinki-NLP/opus-mt-en-zh进行微调,使用wmt19 英文-中文数据集来训练,每轮训练epoch 会计算对应的评估分数compute_metrics, BLEU的计算和翻译评估,可以看谷歌autoML Translation中的介绍: https://cloud.google.com/translate/automl/docs/evaluate?hl=zh-cn#bleu 很详细讲解:
OK, 如果BLEU评估得分在50以上,翻译效果应该不错了;应该到了4,6级水平吧。。。
附操作笔记:
- https://github.com/weedge/doraemon-nb/blob/main/translate.ipynb
- https://github.com/weedge/doraemon-nb/blob/main/hf_train_my_translation_model.ipynb
- https://github.com/weedge/doraemon-nb/blob/main/transformers_translate.ipynb
参考
-
使用Transforms库进行翻译任务: https://huggingface.co/docs/transformers/tasks/translation
-
https://ai.meta.com/blog/nllb-200-high-quality-machine-translation/
-
https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation
-
zh2en: https://transformers.run/c3/2022-03-24-transformers-note-7/
-
https://cloud.google.com/translate/automl/docs/evaluate?hl=zh-cn#bleu
-
https://www.cs.cmu.edu/%7Ealavie/Presentations/MT-Evaluation-MT-Summit-Tutorial-19Sep11.pdf
-
When Scaling Meets LLM Finetuning - The Effect of Data, Model and Finetuning Method: https://arxiv.org/abs/2402.17193