引言
在大多数情况下,编写可读、清晰的代码比编写经过优化但更复杂、更难理解的代码要好,不要过早的优化。建议遵循软件工程师 Wes Dyer 的这句名言:
Make it correct, make it clear, make it concise, make it fast, in that order.
并不意味着禁止为速度和效率优化应用程序, 了解并掌握这些优化点,以备不时之需;文中给出了常见的优化技术;有些特定于 Go 内存模型,内存分配,GPM调度模型;有些是关于了解硬件有助于写出好的代码(适用于不同语言),其中会有硬件方面的术语,可以结合wiki进行学习;
笔记
91.不了解 CPU 缓存
Mechanical sympathy(机械同情) 来自三届 F1 世界冠军 Jackie Stewart 创造的一个术语
You don’t have to be an engineer to be a racing driver, but you do have to have mechanical sympathy.
简而言之,当了解系统的设计用途时,无论是 F1 赛车、飞机还是计算机,都可以与设计保持一致以获得最佳性能。对 CPU 缓存工作方式的机械同情可以帮助优化 Go 应用程序。
CPU架构 CPU architecture
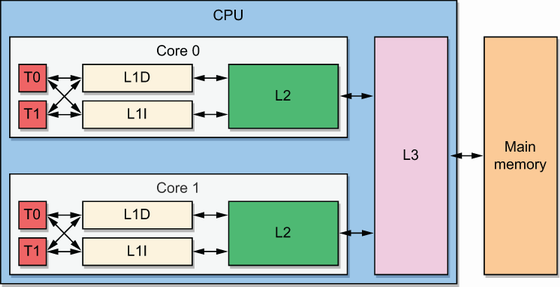
上图为简单的Intel Core i5-7300u cpu架构图;https://en.wikichip.org/wiki/intel/core_i5/i5-7300u
每个物理核心(Core0和Core1)被分成两个逻辑核心Hyper-Threading(T0和T1)。
L1 缓存分为两个子缓存:用于数据的 L1D 和用于指令的 L1I(每个 32 KB)。当 CPU 执行应用程序时,缓存不仅仅与数据相关,它还可以缓存一些指令,L2, L3其原理相同:加快整体执行速度。
内存位置离逻辑核心越近,访问速度越快(参见http://mng.bz/o29v):
- L1:约1ns
- L2:比L1慢约4倍
- L3:比L1慢10倍左右
CPU 缓存的物理位置也可以解释这些差异。L1 和 L2 是称为on-die(片上),这意味着它们与处理器的其余部分属于同一块硅片。相反,L3 是off-die(片外)。
对于主存储器(RAM),平均访问速度比 L1 慢 50 到 100 倍。可以访问存储在 L1 上的多达 100 个变量,只需访问一次主内存的价格。因此,作为 Go 开发人员,改进的一种途径是确保应用程序使用 CPU 缓存。进一不了解可以查看以下视频:
缓存行 Cache Line
缓存行的概念对于理解至关重要。但在介绍它们是什么之前,了解为什么需要它们。
当访问特定的内存位置时(例如 通过读取变量),在不久的将来可能会发生以下情况之一:
- 将再次引用相同的位置;时间局部性。
- 附近的内存位置将被引用;空间局部性。
两者都是局部性原则 locality of reference
时间局部性是需要 CPU 缓存的部分原因:加速对相同变量的重复访问。由于空间局部性,CPU 会复制缓存行将包括单个变量的缓存行从主存复制到高速缓存,并加载到寄存器中执行。
高速缓存行是固定大小的连续内存段,通常为 64 字节(8 个int64变量)。每当 CPU 决定缓存 RAM 中的内存块时,它会将内存块复制到缓存行。因为内存是有层次结构的,所以当CPU要访问一个特定的内存位置时,它首先检查L1,然后是L2,然后是L3,最后,如果位置不在那些缓存中,则在主内存中。
举一个简单的例子, 遍历容量为16的slice切片s []int64; 这个内存地址还没在缓存中;程序开始遍历,cpu决定缓存这个s[0]这个变量,会复制整个内存块复制到缓存行,缓存行中包含了8个int64,0到7的数据将会在cpu cache中命中;访问s[8]时同理;迭代16个int64元素导致2次强制缓存未命中(compulsory miss)和 14 次缓存命中。
CPU缓存策略有个大致的了解:有时缓存是包容性的(例如,L2 数据也存在于 L3 中),有时缓存是排他性的(例如,L3 称为受害者缓存,因为它只包含从 L2 逐出的数据);这些策略被 CPU 供应商隐藏起来;大致了解下即可。
如果感兴趣,可以通过 https://en.wikipedia.org/wiki/CPU_cache 进一步了解,比较硬核。
结构切片与切片结构 Slice of structs vs. struct of slices
type Foo struct {
a int64
b int64
}
type Bar struct {
a []int64
b []int64
}
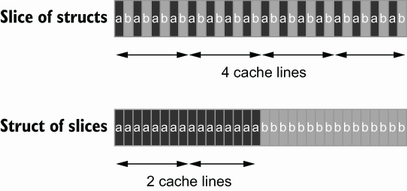
对[]Foo 和 Bar.a 容量长度为16的切片遍历,遍历数据结构切片 比 遍历切片结构 慢, 因为cache line的空间局部性原理,加载切片结构更紧凑,需要更少的缓存行来迭代,如图所示:
可预测性 Predictability
要理解这一点,必须了解跨步striding的概念。跨步与 CPU 如何处理数据有关。共有三种不同类型的步幅(stride)
- 单位步幅Unit stride:全部想要访问的值是连续分配的:例如,切片[]int64元素。这个步幅对于 CPU 来说是可预测的并且是最有效的,因为它需要最少数量的缓存行来遍历元素。
- 恒定步幅Constant stride:对于 CPU 来说仍然是可预测的:例如,一个切片每两个元素迭代一次。此步幅需要更多缓存行来遍历数据,因此它的效率低于单位步幅。
- 非单位步幅Non-unit stride :CPU 无法预测的跨步:例如,链表或指针切片。因为 CPU 不知道数据是否连续分配,所以它不会获取任何缓存行。
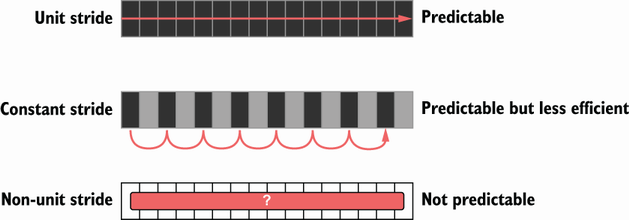
由于不同的步幅和相似的空间局部性,迭代链表比值的切片要慢得多。由于更好的空间局部性,通常应该支持单位步幅而不是恒定步幅。但是当CPU 都无法预测非单位步长,无论数据如何分配,都会有性能上的影响。
到目前为止,已经讨论了 CPU 缓存速度很快但比主内存小得多。因此,CPU 需要一种策略来将内存块提取到缓存行。此策略称为缓存放置策略,并且会显着影响性能。
缓存放置策略 Cache placement policy
当 CPU 决定复制一个内存块并将其放入缓存时,它必须遵循特定的策略。假设一个 32 KB 的 L1D 缓存和一个 64 字节的缓存行,如果一个块被随机放入 L1D,CPU 在最坏的情况下将不得不迭代 512 个缓存行来读取一个变量。这种缓存是称为完全结合(fully associative)。
为了提高从 CPU 缓存访问地址的速度,设计人员制定了有关缓存放置的不同策略。跳过历史,讨论当今使用最广泛的策略:集合关联缓存策略(set-associative cache) ,它依赖缓存分区。
具体参考以下资料进一步了解:
https://en.wikipedia.org/wiki/Cache_placement_policies
https://lwn.net/Articles/250967/
https://coolshell.cn/articles/20793.html (结合文章中c++代码)
为了便于理解,举一个简单的例子,有一个矩阵 二维数组arr [4][32]int64 4行32列存放int64,从中取出前8列res [4][8]int64;假设L1D缓存大小512B, 缓存行cache line 64B, 有8个cache line;
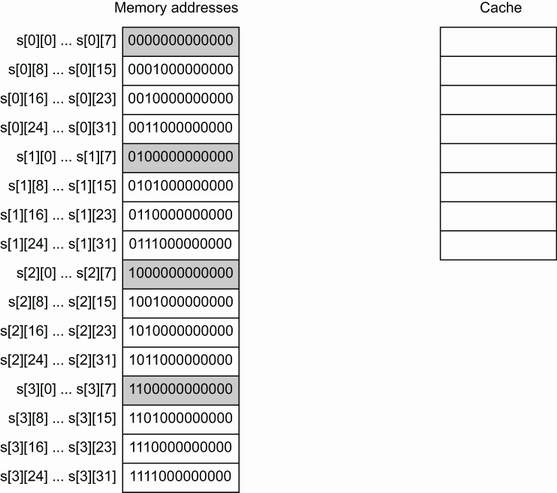
图中所示该矩阵如何存储在内存中。这里使用二进制表示来表示内存块地址,为简单起见,使用 13 位表示一个地址;灰色块代表迭代的前 8 个int64元素,其余块在迭代期间被跳过。每个主存内存块包含 64 个字节,因此块内包含 8 个int64元素。第一个内存块从 0x0000000000000 开始,第二个从 0001000000000(二进制为 512)开始,依此类推。 以及可以容纳 8 行的缓存cache。
使用集合关联缓存策略(set-associative cache),缓存被划分为集合。假设缓存是N-way集合关联的(N=2),这意味着每个集合包含两行。一个内存块只能属于一个集合,其放置位置由其内存地址决定。要理解这一点,必须将内存块地址分解为三个部分:
- 块偏移量是基于块大小。这里的块大小是 512 字节,512 等于 2^9。因此,地址的前 9 位代表块偏移量(bo)。
- 集合索引表示地址所属的集合。因为缓存是两路集合关联的并且包含 8 行,所以有 8 / 2 = 4 个集合。此外,4 等于 2^2,因此接下来的两位代表集合索引 (si)。
- 地址的其余部分由标记位 (tb) 组成。为简单起见使用 13 位表示一个地址。计算 tb 位数 = 13 – bo – si。这意味着剩下的两位代表标记位。
假设该函数启动并尝试读取s[0][0]属于地址 0000000000000 的地址。由于该地址尚未出现在缓存中,因此 CPU 计算其集合索引并将其复制到相应的缓存集合。

如前所述,9 位表示块偏移量:它是每个内存块地址的最小公共前缀。然后,2位表示集合索引。地址为 0000000000000 时,si 等于 00。因此,该内存块被复制到Set 0。
当函数从 读取s[0][1]到时s[0][7],数据已经在缓存中。CPU 是怎么知道的?CPU 计算内存块的起始地址,计算集合索引和标记位,然后检查Set 0 中是否存在 00。
接下来函数读取s[1][0],这个地址还没有被缓存。因此复制内存块 0100000000000 时发生相同的操作
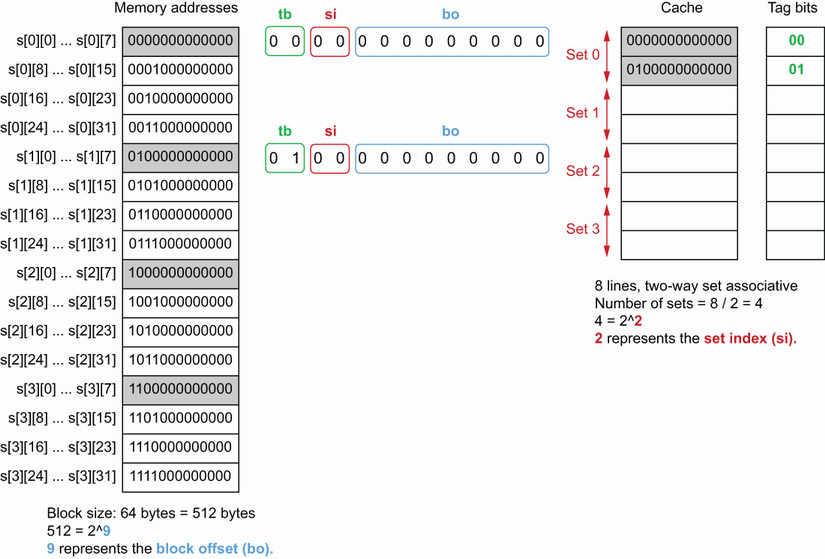
该内存的集合索引等于 00,因此它也属于Set 0。缓存行被复制到Set 0 中的下一个可用行。然后,再次从 读取到导致缓存s[1][1]命中s[1][7]。
现在事情变得有趣了。该函数读取s[2][0],并且该地址不存在于缓存中。执行相同的操作
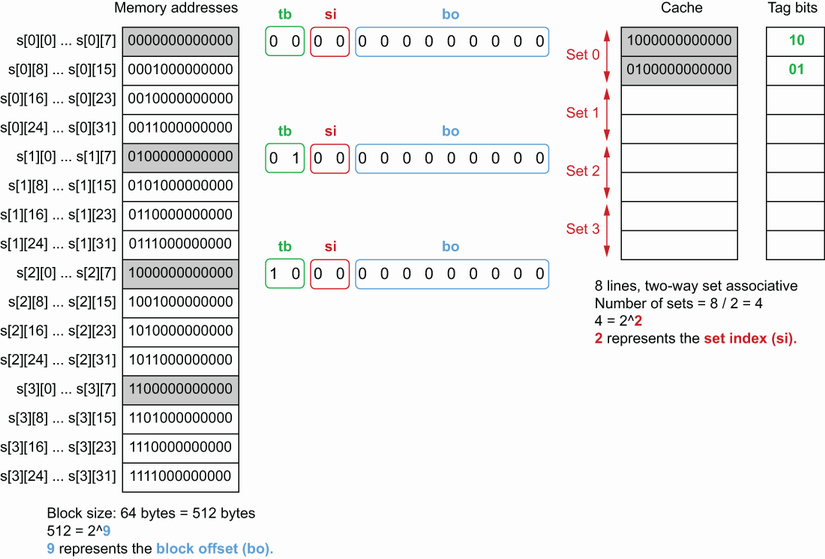
集合索引再次等于 00。但是, Set0 已满,CPU 会替换现有缓存行之一以复制内存块 1000000000000。
缓存替换策略(Cache replacement policies)取决于 CPU,但它通常是伪 LRU 策略(真正的 LRU [最近最少使用] 会太复杂而无法处理)。在这种情况下,假设它替换了第一个缓存行:0000000000000。当迭代第 3 行时会重复这种情况:内存地址 1100000000000 也有一个等于 00 的集合索引,导致替换现有的缓存行。
现在,假设基准测试执行函数,其中一个切片指向从地址 0000000000000 开始的相同矩阵。每次基准测试,当函数读取时,s[0][0]地址不在缓存中;该块已被替换。
基准测试将导致更多的缓存未命中,而不是从一个执行到另一个执行使用 CPU 缓存。这种类型的缓存未命中称为*冲突未命中conflict miss;*如果未对缓存进行分区,则不会发生未命中。迭代的所有变量都属于一个集合索引为00的内存块。因此,只使用一个缓存集合,而不是分布在整个缓存中。
之前讨论了步幅stride的概念, CPU 如何遍历数据。在这个例子中,这个步幅是称为*临界步幅critical stride;*它导致访问具有相同集合索引的内存地址,存储到相同的缓存集合中。
Intel 大多数处理器的存放数据的L1D都是32KB,8-Way 组相联,Cache Line 是64 Bytes。
- 32KB可以分成,32KB / 64 = 512 条 Cache Line。
- 因为有8 Way,于是会每一Way 有 512 / 8 = 64 条 Cache Line。
- 于是每一路就有 64 x 64 = 4096 Byts 的内存。
回到前面#89 真实示例中,使用两个函数calculateSum512和calculateSum513。基准测试在 32 KB 8-way set-associative L1D cache上执行,总共 64 组。因为缓存行是 64 字节,所以每一路步长等于 64 × 64 字节 = 4 KB;代表512 个int64类型元素。因此,达到了 512 列矩阵的临界步幅critical stride,缓存分布很差(冲突未命中conflict miss)。同时,如果矩阵包含 513 列,则不会导致临界步幅。这就是为什么观察到两个基准之间存在如此巨大差异的原因。这个同样适用于在intel CPU架构上运行的其他语言。
总之,必须意识到现代缓存是分区的。根据步幅,在某些情况下只使用一组,这可能会损害应用程序性能并导致冲突未命中。这种步幅称为临界步幅。对于性能密集型应用程序,应该避免关键步骤来充分利用 CPU 缓存。
tips: 应该注意基准测试的结果在不同底层CPU架构而有所不同。注意开发测试 和 生产环境下的CPU架构一致,如果有对计算密集型的调优,最好在生产环境待部署的机器上都进行基准测试一下。
92.编写导致伪共享(false sharing)的并发代码
由于多核处理器cpu之间独立的L1/L2 cache,会出现cache line不一致的问题,为了解决这个问题,有相关协议模型,常用MESI协议,MESI 通过 这个网站模拟更直观的了解 https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm;为了保证一个core上修改的cache line数据同步到其他core的cache line上,则需要MESI协议来保证,如果同一个cache line上有个两个变量sum1 和 sum2 之间虽然没有相互依赖逻辑,但是当修改sum1 或者sum2 时,需要同步同一块cache line的内容,导致 即使没有相互关系的变量在同一cache line中, 需要彼此共享同步,从而出现所说的伪共享 flase sharing。伪共享因为cache line的同步会带来一些cpu 时钟周期的性能损失。
了解伪共享的情况,知道如何破解了,直接让sum1和sum2 放置在不同的cache line就可以;比如一个结构体中sum1和sum2 的存放结构:
type Result2 struct {
sumA int64
_ [56]byte // a cache line 64B
sumB int64 // sumB in other cache line
}
还有一种解决方案是重新设计算法的结构。例如,不是让两个 goroutines 共享相同的结构,通过channel传递它们的本地结果。结果基准与填充大致相同。
并发编程中,操作cpu L1/L2 cache 时,因为多核同步cache的最小单元是cache line,所以当缓存行在两个内核之间共享时,至少一个 goroutine 是 writer 时,就会发生伪共享。如果需要优化依赖于并发的应用程序,应该检查是否存在伪共享的代码,众所周知这种模式会降低应用程序性能。可以通过填充或通信来防止虚假共享。
93.不考虑指令级并行性 instruction-level parallelism
这个很大一部分取决于编程语言的编译器软件,编译优化之后代码指令是否可以充分利用指令级并行instruction-level parallelism(ILP);以及在硬件cpu上进行指令级并行(ILP);
tips: 两者结合效果更佳,对于上层应用使用语言的开发者,了解其背后的原理即可,在应用程序上的性能优化可能效果不大,因为随着编译器升级可能会兼顾了应用程序上对ILP考虑优化。不过了解原理可以有助于上层宏观层面的思考并行,用于借鉴嘛~,微观到宏观(3体里经常浮现的词汇,降维打击)
编译器和CPU设计人员的目标是尽可能多地识别和利用 ILP。普通程序通常是在顺序执行模型下编写的,其中指令一条接一条地执行,并按照程序员指定的顺序执行。ILP 允许编译器和处理器重叠执行多条指令,甚至可以改变指令执行的顺序。cpu利用ILP执行指令时,当表现出数据依赖性的指令在流水线的不同阶段修改数据时,就会发生数据冒险危害。忽略潜在的数据危害会导致竞争条件(也称为竞争危害),进而触发控制风险;为了避免控制风险发生,可以通过预测分支来解决。
了解利用ILP的微架构技术见wiki: https://en.wikipedia.org/wiki/Instruction-level_parallelism
在Go中,可以通过 https://research.swtch.com/mm 来了解在这方面的思考
94.不知道数据对齐
数据对齐是一种安排数据分配方式以加速 CPU 访问内存的方法。不了解这个概念会导致额外的内存消耗甚至性能下降。
tips: 这个属于老生常谈的问题了,尤其在c语言开发的程序中,数据对齐,直接通过地址+偏移大小来指向对应内存数据,进行读写操作;golang很多思想来自c,自然也会有,只不过更加友好,unsafe形式来操作指针。
在 64 位cpu架构上,处理最小单位是8字节的地址,如果没有数据对齐,变量j分配可以分布在两个地址上。如果 CPU 想要读取j,则需要两次而不是一次内存访问。
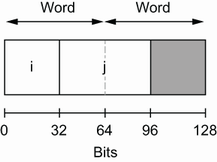
为防止这种情况,变量的内存地址应该是其自身大小的倍数。这就是数据对齐的概念。在 Go 中,对齐保证如下:
byte,uint8,int8: 1 字节uint16,int16: 2 字节uint32,int32,float32: 4 字节uint64,int64,float64,complex64: 8 字节complex128: 16 字节
所有这些类型都保证对齐:它们的地址是它们大小的倍数。例如,任何int32变量的地址都是 4 的倍数。
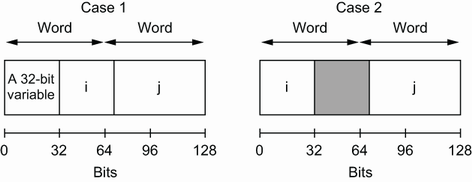
这样上面的情况,按在字节对齐,出现两种情况:
第一种情况,在i之前分配了一个32位变量。因此i和j被连续分配。
第二种情况,在i之前没有分配32位变量;i被分配在一个词的开头。为了数据对齐(地址是 64 的倍数),i不能与下一个 64 的倍数j一起分配。灰色框表示 32 位填充。
所以了解了字节对齐之后,在设计数据结构的时候,需要清楚,数据结构通过编译器优化编译之后方便cpu访问 的数据对齐结构,所占内存大小;防止出现本来不需要这么多内存空间的设计。尤其在设计非常依赖缓存存储的项目中。申请内存空间越多越频繁,对于Go来说,将带来更多的GC, 影响整体应用性能。
还有一个好处是,考虑了字节对齐后的合理结构体(所占内存空间的结构体大小最小情况,结构体中的字段按大小降序对它们进行排序对齐);利用cache 局部性原理,可以在cpu cache line中存放更多的对象,这样在遍历对象时,需要更少的缓存行总数,性能更好。
PS: 在硬件存储设备上,也存在同样的读写IO对齐,在编写硬件存储系统,使用直接io(linux fs.open O_DIRECT 模式)的情况,硬件存储IO性能尤其注意的地方,比如磁盘最小单元扇区 512B 对齐,SSD最小单元page 4K 对齐。如果不利用好对齐,会增加额外的读写放大,比如读写一个存储单元大小数据,数据没有对齐,需要访问多个存储单元数据,存在读写放大,增加IO次数,影响性能。一次磁盘读 io 2ms 级别,ssd则在几十us;相对于cpu cache的读写 几ns级别,磁盘io通常是系统主要优化的点。不过这方面操作系统和硬件打交道都已经考虑了,除非不使用操作系统的系统调用函数操作硬件。
附:Latency Numbers Every Programmer Should Know: https://colin-scott.github.io/personal_website/research/interactive_latency.html
95.不了解栈与堆
在 Go 中,变量可以分配在栈上或堆上。这两种类型的内存根本不同,影响数据密集型应用程序。需要了解栈和堆这些概念,以及编译器决定变量分配位置所遵循的规则。
栈与堆
首先,讨论一下栈和堆的区别。栈是它是一种后进先出 (LIFO) 数据结构,用于存储特定 goroutine 的所有局部变量。当一个 goroutine 启动时,它会获得 2 KB 的连续内存作为它的栈空间(这个大小随着时间的推移而变化并且可能会再次改变)。但是,此大小在运行时不是固定的,可以根据需要增大和缩小(但它始终在内存中保持连续,从而保留数据局部性)。
tips: Go 在1.3之前栈扩容采用的是分段栈(Segemented Stack),在栈空间不够的时候新申请一个栈空间用于被调用函数的执行, 执行后销毁新申请的栈空间并回到老的栈空间继续执行,当函数出现频繁调用(递归)时可能会引发hot split。为了避免hot split, 1.3之后采用的是连续栈(Contiguous Stack),栈空间不足的时候申请一个2倍于当前大小的新栈,并把所有数据拷贝到新栈, 接下来的所有调用执行都发生在新栈上。
当 Go 进入一个函数时,会创建一个栈帧,代表内存中只有当前函数才能访问的一个区间。
通过一个简单示例来介绍stack的指令执行过程

为了简化,图中stack没有使用汇编指令来表明,执行了main,所以为这个函数创建了一个栈帧,a和b都分配在栈上,valid为有效地址,invalid为无效地址。栈从高地址往地址空间增长,其中基准指针寄存器BP 来维护栈基地址 ,栈指针寄存器SP 指向栈顶地址; 至于汇编相关的细节见官方文档查阅解释:https://go.dev/doc/asm。查看命令如下:
GOOS=linux GOARCH=amd64 go tool compile -S -L -N -l -m 12-optimizations/95-stack-heap/main.go | less

调用sumValue创建一个新的栈帧。x,y为值传递分别赋值,x+y后(简单起见,操作指令未给出),z赋值; 先前的栈帧(main)包含仍被视为有效的地址,但无法访问a和b对其操作,如果是指针传递则可以获取地址对其操作。

执行完出函数,出栈,sumValue栈帧被擦除,替换为原来的main栈帧,x已经被擦除,y和z仍在内存中分配,但是无法访问。
注意 栈sumValue帧并未从内存中完全删除。当函数返回时,Go 不会花时间释放变量来回收可用空间。但是这些以前的变量不能再被访问,当来自父函数的新变量被分配到栈时,它们取代了之前的分配。从某种意义上说,栈是自清洁的;它不需要额外的机制,例如 GC。
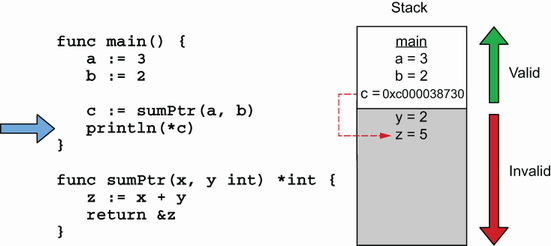
把调用函数改成指针返回时,z 如果 继续分配在栈上的话,函数返回后,z不在有效,main栈帧继续增长,会擦除掉z, 这样c指向的地址空间已经不存在了,变成了错位的悬挂指针,如果使用c进行操作会出现异常(C语言中,会出现Segmentation fault),所以在Go中,为了代码安全,在编译的时候,将z 原本在栈上分配的空间,逃逸分配到了堆上。
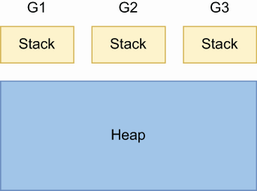
堆内存空间是所有goroutine的共享池,由Go的内存分配器来管理,具体见Go Memory Allocator
三个协程G1,G2和G3都有自己的栈,共享同一个堆进行内存分配管理。
tips: 在Go中,为了加速内存分配,Golang自己维护了类似https://github.com/google/tcmalloc 的内存分配器来管理,每个运行时P都有一个本地mcache,用于执行状态的协程G分配内存空间,对应多线程中内存tcmalloc的分配机制,线程本地mcache。
栈是自清洁的,并由单个 goroutine 访问。相反,堆上分配的对象需要通过GC标注扫描进行清理。堆分配越多对象,对 GC 施加的压力就越大。当 GC 运行时,会使用大约 25% 的可用 CPU 容量,并且可能会产生毫秒级的“停止世界”延迟(应用程序暂停的阶段)。具体见官方文档: gc-guide
在基准压测的结果中,使用的testing.B.ReportAllocs函数, 或者使用参数-benchmem ,显示了堆分配情况(栈分配不计算在内):
B/op:每个操作分配多少字节allocs/op:每个操作有多少分配
tips:
由于Go中的用户栈空间是自动扩缩容的,需要注意每个协程goroutine栈扩容对内存空间的影响,特别是在长连接的场景,单机连接数在100w级别的时候,尽量保持每个goroutine 处理函数的逻辑在2kb内(功能职责分离),防止栈扩容,导致内存指数级暴涨。
栈扩容了,长时间没有运行,为了提高内存利用率,在GC触发的时候,计算当前栈使用的空间,小于栈空间的1/4,会触发栈缩容操作到原来的1/2,最小到2kb,不会再缩容;但在缩容过程中会存在栈拷贝和写屏障(write barrier),对于一些准实时应用可能会存在一些影响。 好在go提供了可设置的参数,可以通过设置环境变量 GODEBUG=gcshrinkstackoff=1 来关闭栈缩容。关闭栈缩容后, 需要承担栈持续增长的风险,在关闭前需要慎重考虑。
逃逸分析 (重要)
逃逸分析(escape analysis) 在程序编译阶段根据程序代码中的数据变量,对代码中哪些变量需要在栈上分配,哪些变量需要在堆上分配进行静态分析的方法;Go 语言的逃逸分析遵循以下两个不变性:
- 指向栈对象的指针不能存储在堆中(pointers to stack objects cannot be stored in the heap);
- 指向栈对象的指针不能超过该栈对象的存活期(pointers to a stack object cannot outlive that object)。
tips: 发生逃逸时,底层会使用runtime.newobject调用mallocgc通过内存分配器来管理分配;
无法在栈上完成分配时,它会在堆上完成, 比如:
- 如果局部变量太大而不适合栈。
- 如果局部变量的大小未知。例如,
s := make([]int, 10)可能不会逃逸到堆中,但s := make([]int, n)会,因为它的大小是基于变量的。
// go run -gcflags='-m=1 -l -L -S -N'
func test1() {
a := make([]int, 0, 8193) // >64kb a and a.Data escape to heap
printSliceLocalAndDataPointAddr(&a)
aa := make([]int, 0, 8192) // <=64kb aa and aa.Data don't escape to heap
printSliceLocalAndDataPointAddr(&aa)
aaa := make([]int, 8192) // <=64kb aaa and aaa.Data don't escape to heap
printSliceLocalAndDataPointAddr(&aaa)
aaa = append(aaa, 1) // happen runtime.growslice; aaa don't escape to heap,but aaa.Data move to heap
printSliceLocalAndDataPointAddr(&aaa)
// so if make a slice, <=64kb please init cap, eg: make([]int, 0, 8192) allocate in stack
bb := [1024 * 1024 * 10]byte{} // don't move to heap
bbb := [1024 * 1024 * 11]byte{} // move to heap
n := 1
s := make([]int, n) // escapes to heap
_, _, _, _, _, _ = s, a, aa, aaa, bb, bbb
}
func printSliceLocalAndDataPointAddr(p *[]int) {
println("addr of local slice = ", p)
pd := (*reflect.SliceHeader)(unsafe.Pointer(p))
println("slice data =", unsafe.Pointer(pd.Data))
}
指向栈对象的指针不能在栈对象回收后存活;interface操作以及返回函数中局部变量的指针, 比如:
// go tool compile -m=1 -l -L -S -N use -m=2 , -m3, -m4 see more
a := "hi"
fmt.Printf("%s", a) // a escapes to heap
func sum(x, y *int) *int {
z := (*x + *y)
return &z // moved to heap: z
}
func noescape(p unsafe.Pointer) unsafe.Pointer {// p does not escape
x := uintptr(p)
return unsafe.Pointer(x ^ 0)
}
func leakNoEscape(p *int) *int { // leaking param: p to result ~r0 level=0
x := p
return x
}
func escape(p *int) *int {
x := *p // x escapes to heap
return &x
}
如果指向栈对象的指针存在于栈中;这不会分配到堆上,比如
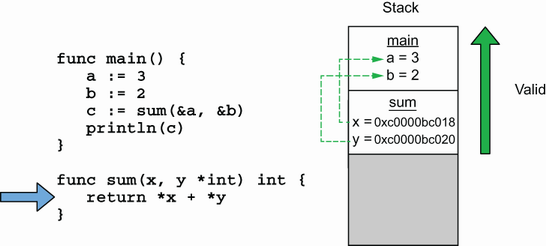
x, y 的值(对象地址),以及指向对象 a 和 b. 都在栈上,所以不会分配在堆上。
以下是变量可以逃逸到堆的其他情况:
- 全局变量,因为多个 goroutines 可以访问它们。
- 发送到channel的指针:
type Foo struct{ s string }
ch := make(chan *Foo, 1)
foo := &Foo{s: "x"} // escapes to heap
ch <- foo
- 由发送到通道的值引用的变量:
type Foo struct{ s *string }
ch := make(chan Foo, 1)
s := "x" // moved to heap
bar := Foo{s: &s}
ch <- bar
以上逃逸分析的测试随着编译器的升级,可能在未来的 Go 版本中发生变化。为了确认假设,可以使用 go build -gcflags "-m=2" -m=3,-m4 来进行详细分析。
了解堆和栈之间的根本区别对于优化 Go 应用程序至关重要。堆分配对于 Go 运行时处理来说更为复杂,并且需要具有 GC 的外部系统来释放数据。在某些数据密集型应用程序中,堆管理可占总 CPU 时间消耗的 20% 或 30%。另一方面,栈是自清洁的,并且对单个 goroutine 而言是本地的,从而使分配速度更快。因此,优化内存分配可以获得很大的投资回报。
理解逃逸分析的规则对于编写更高效的代码也很重要。一般来说,向下共享留在栈上,而向上共享逃逸到堆中。这应该可以防止常见错误,例如想要返回指针的过早优化,例如“避免复制”。首先关注可读性和语义,然后在需要时优化分配。
tips: 想更深入了解逃逸分析,可以一起学习这篇论文:Escape from Escape Analysis of Golang
96.不知道如何减少分配
减少分配是加速 Go 应用程序的常见优化技术。已经涵盖了一些减少堆分配数量的方法:
- 未优化的字符串连接(错误 #39):使用
strings.Builder替代+运算符来连接字符串。 - 无用的字符串转换(错误 #40):尽可能避免转换
[]byte成字符串。 - 切片和映射初始化效率低下(错误 #21 和 #27):如果长度已知,则预分配切片和映射。
- 更好的数据结构对齐以减少结构大小(错误 #94)。
另外还有三种减少内存分配的常见方式:
API 设计
只要涉及到I/O读写,会大量使用到在io库https://pkg.go.dev/io中,定义的读Reader / 写Writer接口, 对应的API方法,设计时为什么使用[]byte 作为传入参数,返回读取了多少, 而不使用读取多少来返回对应[]byte呢?
type Reader interface {
Read(p []byte) (n int, err error)
}
type Reader interface {
Read(n int) (p []byte, err error)
}
如果使用切片[]byte返回的方式,Read函数内部会读取函数局部变量的切片赋值给返回的切片, 类似如下操作:
type HiString struct{}
func (m *HiString) Read(n int) (p []byte, err error) {
s := []byte{1, 2, 3, 4, 5, 6, 7}
p = s[:n] //[]byte{...} escapes to heap
return
}
这样函数局部变量会逃逸到堆上分配,这样带了额外的gc影响,而且io库的接口经常会被不同对象实例化使用到。所以Go 的设计者使用向下共享的方法来防止自动将切片转义到堆中;由调用者提供读写的切片[]byte,至于是否分配在堆上还是栈上,这取决于调用者来处理它,而不是直接返回,导致逃逸发生的可能。
有时,即使是 API 的微小变化也会对分配产生积极影响。在设计 API 时,了解逃逸分析规则,并在需要时使用它-gcflags来理解编译器的决策。
依赖编译器优化
// go tool compile -m=1 -l -L -S -N see if use runtime.slicebytetostring
m := map[string]int{}
bytes := []byte{1, 2, 3}
key := string(bytes) // m[string(key)] would be more efficient than k := string(key); m[k] (SA6001)go-staticcheck
_, _ = m[key]
_, _ = m[string(bytes)]
如上代码,通过linter相关静态编译检查工具可以提示出 直接使用m[string(key)]的方式比k := string(key); m[k] 效率更高一些,因为编译器对m[string(key)] 进行了优化,不会调用runtime.slicebytetostring 进行复制转化,执行效率更快,也不会带了额外内存分配。
池化sync.Pool
当处理的对象,分配在堆上,且频繁被创建使用,这样会触发频繁gc,对这些临时对象标记扫描,会带来额外性能影响,所以在Go引入了sync.Pool,复用临时对象,减少频繁创建,并且在池中的临时对象一段时间不在使用时,会从对象池中移出,并被gc回收,合理的触发机制由gc来管理,进而减少频繁gc。而且sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用Get方法存取对象;sync.Pool 不可在使用之后再复制使用,引入了noCopy机制,可以通过go vet来检查。
sync.Pool有两个公开方法Get, Put 以及初始化Pool是的New 函数成员。
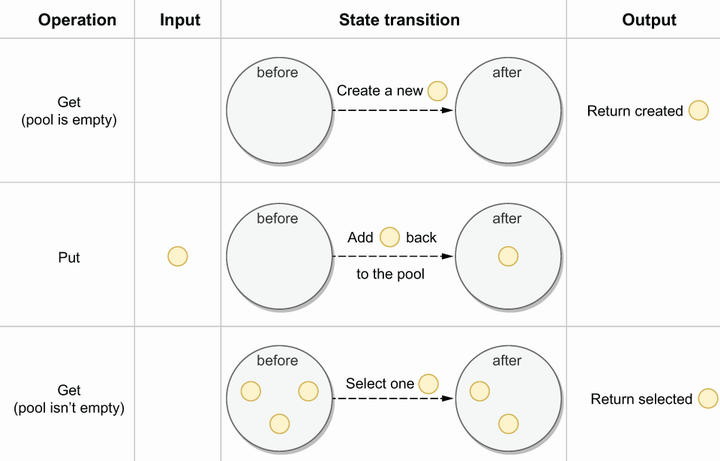
Get 方法分为两种情况:
- pool为空,通过自定义的New方法创建一个新对象,注意这个对象是同一类型;然后返回刚创建的对象,除了返回值是正常实例化的对象,Get 方法的返回值还可能会是一个 nil(Pool.New 字段没有设置,又没有空闲元素可以返回),所以在使用的时候,需要判断。当没有设置 New 字段,没有更多的空闲元素可返回时,Get 方法将返回 nil,表明当前没有可用的元素。
- pool不为空, 直接从池子中选一个复用对象返回
Put: 将对象重置为初始对象,放入池子中(poolLocalInternal结构),如果放入对象为nil,则会忽略掉。
// Local per-P Pool appendix.
type poolLocalInternal struct {
private any // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
private: 仅被本地P使用,互斥 Put/Get
shared: poolChain(lock-free queue): 一个本地的 P 作为生产者(Producer)pushHead/popHead (Put/Get),多个 P 作为消费者(Consumer)popTail (Get)
具体见源码分析:go1.20/src/sync/pool.go
在频繁读写IO场景下,sync.Pool 常用作 buffer pool(缓冲池)来提升读写性能。类似这种封装:
var bufferPool = &sync.Pool{
New: func() any {
return &bytes.Buffer{}
},
}
// GetBuffer returns a buffer from the pool.
func GetBuffer() (buf *bytes.Buffer) {
return bufferPool.Get().(*bytes.Buffer)
}
// PutBuffer returns a buffer to the pool.
// The buffer is reset before it is put back into circulation.
func PutBuffer(buf *bytes.Buffer) {
buf.Reset()
bufferPool.Put(buf)
}
sync.Pool不适合长时间不会释放的资源 比如长连接;因为sync.Pool池化的对象可能会被垃圾回收掉,对于数据库长连接等场景是不合适。
如果经常分配很多同类型的对象,可以考虑使用sync.Pool. 它是一组临时对象,可以防止重复重新分配同一种数据;并且sync.Pool可以安全地同时被多个 goroutines 使用。
97.不依赖内联
内联是将较小的函数组合到它们各自的调用者中的行为。在计算的早期,这种优化通常是手动执行的。如今,内联是在编译过程中自动执行的一类基本优化之一。
内联很重要有两个原因。首先是它消除了函数调用本身的开销。第二个是它允许编译器更有效地应用其他优化策略,比如栈中内联(Go 1.9 引入 Mid-stack inlining);
了解更多Mid-stack inlining相关内容: 提案 , HN 上的讨论以及PPT: Mid-stack inlining in the Go compiler
这种优化技术是关于区分快路径和慢路径。如果可以内联快速路径但不能内联慢速路径,可以将慢速路径提取到专用函数中。如果没有超出内联预算,函数就是内联的候选者。
了解内联如何工作以及如何访问编译器的决定,可以成为使用快速路径内联技术进行优化的途径。如果执行快速路径,则在专用函数中提取慢速路径可防止函数调用。例如:sync库中使用Mutex.Lock Mutex.UnLock;Once.Do 用到了快速路径内联技术进行优化。
tips: 具体优化收益,都需要进行基准压测为准
98.不使用 Go 诊断工具 (重要)
Go 提供了一些优秀的诊断工具来帮助深入了解应用程序的执行情况,重点介绍最重要的部分:剖析Profiling 和 执行跟踪器 Execution Tracer。具体查看官方文档: https://go.dev/doc/diagnostics
Profiling 对运行中的代码采用基于定时器的采样。其缺点是,采样只能提供一个关于目标的粗略的图像,并且可能会遗漏事件。 比如cpu数据的采集,由于每次采集都会触发一次SIGPROF 信号中断,收集当时的调用堆栈;会对被采集的系统带来额外的负载影响,在采集cpu数据频率一般控制毫秒级别,所以存在采集精度的影响;对于微妙级别的采样,现在还不支持,有个改进的 提案 ,还未合并。
Execution Tracer用来捕获各种运行时事件。调度、系统调用、垃圾收集、堆大小和其他事件由运行时收集,并可通过 go 工具跟踪进行可视化。执行跟踪器是一种检测延迟和利用率问题的工具,可以用来检查 CPU 的使用情况,以及在网络或系统调用时goroutine 抢占的原因。
分析 Profiling
分析提供了对应用程序执行的洞察力。能够解决性能问题、检测争用、定位内存泄漏等。通过如下几个采集类型收集,并通过go tool pprof 分析:
- cpu: 确定应用程序将时间花在哪里
- threadcreate: 创建的线程数, 这个采集点,2013年 https://github.com/golang/go/issues/17280 这个issue 已经不可用了,新的还未merged。
- goroutine:报告正在进行的 goroutines 的堆栈跟踪
- heap:报道堆内存分配以监视当前内存使用情况并检查可能的内存泄漏
- mutex:报告锁查看代码中使用的互斥体的行为以及应用程序是否在锁定调用上花费了太多时间的争用
- block:显示 goroutines 阻塞等待同步原语的位置
Go中提供3种方式使用pprof来采样数据,通过go tool pprof 工具来分析,具体见文档说明: https://github.com/google/pprof/blob/main/doc/README.md
使用运行时pprof包 接口API来采样数据: https://pkg.go.dev/runtime/pprof ;接口 api分析采样数据类型如下:
goroutine - stack traces of all current goroutines
heap - a sampling of memory allocations of live objects
allocs - a sampling of all past memory allocations
threadcreate - stack traces that led to the creation of new OS threads
block - stack traces that led to blocking on synchronization primitives
mutex - stack traces of holders of contended mutexes
具体见源码:go1.20/src/runtime/pprof/pprof.go,可以使用Profile结构来进行二次开发,新增采样类型。运行时分析适用于没有 HTTP 接口的应用程序,通常用于库。必须在主函数中放置一个启动和停止函数句柄。
使用网络net/http pprof包 http接口来采样数据: https: //pkg.go.dev/net/http/pprof; http api接口采样数据类型如下:
import _ "net/http/pprof"
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
# use 6060 port
# cpu seconds=30s , debug=1
http://localhost:6060/debug/pprof/profile?seconds=30&debug=1
http://localhost:6060/debug/pprof/heap
http://localhost:6060/debug/pprof/block
http://localhost:6060/debug/pprof/mutex
http://localhost:6060/debug/pprof/goroutine?debug=1
http://localhost:6060/debug/pprof/allocs?debug=1
http://localhost:6060/debug/pprof/threadcreate?debug=1
http://localhost:6060/debug/pprof/cmdline?debug=1
# view all pprof
http://localhost:6060/debug/pprof
网络分析更适合依赖 HTTP 的 API 应用程序。
使用基准压测来采样数据: https://pkg.go.dev/cmd/go#hdr-Testing_flags ,没有goroutine的采样,可以借助 trace工具来分析goroutine的细粒度调度情况,使用 -trace trace.out 。
# sampling
go test -v -bench=Benchmark_parallelMergesortV1$ -count=1 -benchtime=1s -benchmem -cpuprofile cpu.out -memprofile mem.out -mutexprofile mutex.out -blockprofile block.out ./08-concurrency-foundations/56-faster/
最终采集的样本数据, 这些数据由pb格式编码(pb格式数据经常用于大数据场景,数据占用空间低), pprof 读取 profile.proto 格式的分析样本集合并生成报告以可视化和帮助分析数据。它可以生成文本和图形报告(通过使用点可视化包)。通过命令 go tool pprof 来分析:
# text cmd pprof or use web cmd in pprof view need graphviz
go tool pprof cpu.out
go tool pprof mem.out
go tool pprof mutex.out
go tool pprof block.out
# http webui pprof view see flamegraph
go tool pprof -http=":8080" cpu.out
# if use net/http/pprof; use http api fetch sample data **.pb.gz file to pprof
# fetch cpu profiling
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30&debug=1
go tool pprof http://localhost:6060/debug/pprof/heap
go tool pprof http://localhost:6060/debug/pprof/block
go tool pprof http://localhost:6060/debug/pprof/mutex
go tool pprof http://localhost:6060/debug/pprof/goroutine?debug=1
go tool pprof http://localhost:6060/debug/pprof/allocs?debug=1
go tool pprof http://localhost:6060/debug/pprof/threadcreate?debug=1
CPU分析
CPU 分析器依赖于操作系统和信号。当它被激活时,应用程序默认要求操作系统每 10 毫秒中断一次,通过一个SIGPROF信号。当应用程序收到一个 时SIGPROF,它会暂停当前活动并将执行转移到探查器。探查器收集诸如当前 goroutine 活动之类的数据,并汇总可以检索的执行统计信息。然后它停止,并继续执行直到下一个SIGPROF.
可以访问 /debug/pprof/profile 端点来激活 CPU 分析。默认情况下,访问此端点会执行 30 秒的 CPU 分析。在 30 秒内,应用程序每 10 毫秒中断一次。请注意,可以更改这两个默认值:可以使用参数seconds将分析应该持续多长时间传递给端点(例如,/debug/pprof/profile?seconds=15),可以更改中断率(甚至小于 10 毫秒)。但在大多数情况下,10 毫秒应该足够了,在减小这个值(意味着增加速率)时,应该注意不要损害性能。30 秒后,下载 CPU 分析器的结果。
可以为不同的函数附加标签。例如,想象一个从不同客户端调用的通用函数。要跟踪两个客户花费的时间,可以使用pprof.Labels.Go 1.9 开始引入 profiler labels, 对于特殊调优性能,比如某个算法模型,或者线上特殊场景触发的性能问题,在这些特殊逻辑段,单独打上一个tag label 进行profiling的收集,通过pprof 工具分析,可以通过tag相关命令来过滤出样本数据分析。使用 pprofutil 包自动将 HTTP 路径标签添加到处理程序。
Heap堆分析
堆分析可以获得有关当前堆使用情况的统计信息。与 CPU 分析一样,堆分析也是基于样本的。可以更改此速率,但不应该过于细化,因为降低速率越多,堆分析收集数据所需的工作就越多。默认情况下,样本在每 512 KB 堆分配的一次分配中进行分析。
堆分析还可以查看不同的样本类型:
alloc_objects全部的分配的对象数alloc_space全部的分配的内存量inuse_objects数字已分配但尚未释放的对象inuse_space数量已分配但尚未释放的内存
堆分析的另一个非常有用的功能是跟踪内存泄漏。使用基于 GC 的语言,通常的过程如下:
- 触发 GC。
- 下载堆分析数据。
- 等待几秒钟/分钟。
- 触发另一个 GC。
- 下载另一个堆分析数据。
- 比较这两个采集的分析文件。
在下载数据之前强制执行 GC 是一种防止错误假设的方法。例如,如果在没有先运行 GC 的情况下看到保留对象的峰值,无法确定这是泄漏还是下一次 GC 将收集的对象。
使用pprof,可以下载堆分析文件并同时强制执行 GC。Go中的过程如下:
- 转到 /debug/pprof/heap?gc=1(触发 GC 并下载采集的样本文件)。
- 等待几秒钟/分钟。
- 再次转到 /debug/pprof/heap?gc=1。
- 用于
go tool pprof -http=:8080 -diff_base <file2> <file1>比较两个采集文件:
注意 与堆相关的另一种分析类型是allocs,它报告分配。堆分析显示堆内存的当前状态。要了解自应用程序启动以来过去的内存分配情况,可以使用分配分析。如前所述,由于栈分配很便宜,因此它们不属于此分析的一部分,该分析仅关注堆。
tips: 关于性能分析,方法论,关注的指标,可以在 性能之巅 这本书中找到相关介绍,本质上都是在系统层面监控,分析,定位。
Goroutines分析
该goroutine配置文件报告应用程序中所有当前 goroutine 的堆栈跟踪。可以使用 debug/pprof/goroutine/?debug=0 下载一个文件并go tool pprof再次采集分析, 可以分析是否golang在持续上涨,进而判断是否泄露。可以查看 goroutine 分析器数据以了解系统的哪一部分是可疑的。
Block分析
block 分析正在进行的 goroutines 阻塞等待同步原语的位置,包括
- 在无缓冲通道上发送或接收
- 发送到一个完整的频道
- 从空频道接收
- 互斥锁争用
- 网络或文件系统等待
Block分析还记录了 goroutine 等待的时间,可以通过 debug/pprof/block 访问。如果怀疑性能因阻止调用而受到损害,此采样分析文件可能会非常有用。
block默认情况下不启用采样分析文件:必须调用才能runtime.SetBlockProfileRate启用它。此函数控制报告的 goroutine 阻塞事件的比例。一旦启用,分析器将继续在后台收集数据,即使不调用 debug/pprof/block 。如果想设置一个高速率,那么要小心,以免损害性能。
完整的 goroutine 栈dump
如果遇到死锁或怀疑 goroutines 处于阻塞状态,则完整的 goroutine 栈dump (debug/pprof/goroutine/?debug=2) 会创建所有当前 goroutine 堆栈跟踪的dump数据。这有助于作为分析首次步骤
Mutex分析
如果怀疑应用程序花费大量时间等待锁定互斥量,从而损害执行,可以使用mutex分析。
在生产环境建议启用pprof,在发现性能问题,延时,负载,内存空间上涨等问题,可以采集对应现场信息进行分析,对于cpu的采集会导致性能下降,但仅在启用它们期间才会发生。
tips: 通过 https://go.dev/blog/pprof 学习pprof 入门很合适,demo: https://github.com/rsc/benchgraffiti
执行跟踪器 Execution Tracer
trace和pprof一样,也有三种方式:
使用运行时trace包 接口API来采样数据:https://pkg.go.dev/runtime/trace 接口api来收集开始到结束区间的trace信息,和 runtime/pprof 包一样将采集的trace信息写入文件,或者二次开发写入网络io, push到三方平台去分析,常用语微服务的可视化分析监控。
使用网络net/http pprof包 http接口来采样数据: https: //pkg.go.dev/net/http/pprof; 和pprof http接口一样,采集trace的下载接口,如下:
http://localhost:6060/debug/pprof/trace?seconds=5
使用基准压测来采样数据: https://pkg.go.dev/cmd/go#hdr-Testing_flags 使用 -trace trace.out
# sampling
go test -v -bench=Benchmark_parallelMergesortV1$ -count=1 -benchtime=1s ./08-concurrency-foundations/56-faster/ -trace=trace.out
将采集到的trace数据通过 go tool trace 对采集数据文件 trace.out 进行可视化分析。在可视化页面就可以看到对应分析的信息,有对应说明,其分析的信息如下:
- 运行 goroutines 的事件时间表:查看整体时间段的trace信息,线程数,协程数,堆,GC时间等等; goroutine 分析,查看每个goroutine的执行时间,包括网络等待,同步block, 系统调用,调度等待,GC清扫,GC暂停(SWT)
- 查看调用链路即每个函数耗时delay,包括net 网络io, block 阻塞io, syscall 系统调用,sched 协程调度情况,这些profile 可以导出,进行单独分析
- 使用https://pkg.go.dev/runtime/trace 包开发,具体在模块区域Region,摸个任务task下的监控信息,开放出来,根据用户场景自定以开发。显示的每个直方图桶都包含一个样本跟踪记录事件序列,例如 goroutine 创建、日志事件和子区域开始/结束时间。
- 垃圾收集指标, Minimum mutator utilization。
而且可以通过go tool trace -pprof=TYPE trace.out > TYPE.pprof 将不同采集类型的数据从trace数据中导出,进而可以通过go tool pprof进行单独分析,导出数据类型如下:
# net: network blocking profile
# sync: synchronization blocking profile
# syscall: syscall blocking profile
# sched: scheduler latency profile
profiling和tracer结合使用: 比如 使用profiling分析工具来分析内存或 CPU 使用率过高的原因;然后通过tracer 工具来分析每个goroutine的调度情况,以及时间段的执行情况,是否发生GC, 是否有系统调用等等。trace粒度更细,但是分析更耗时。
tips: 具体进一步实践,可以一起学习,掌握原理,熟练工具:
Felix Geisendörfer The Busy Developer’s Guide to Go Profiling, Tracing and Observability 中的profiling, tracing, ob相关实验notes;
Russ Cox 关于 telemetry 引入 go toolchain(工具链)相关的设计思考; 讨论非常活跃,与时俱进呀~ 很期待这个功能。可以打通golang开发的应用程序 和 OTEL 相关监控系统的数据格式交互,进行同一标准管理。
99.不了解 GC 的工作原理
垃圾收集器(GC)是Go 语言的重要组成部分,跟踪和释放不再需要的堆分配。了解 GC 的工作原理有助于优化应用程序。
概念简介
跟踪垃圾回收,其通过循着指针来标识正在使用的、所谓的活动对象,通过活动对象构建的对象图,
GC是基于标记清除算法,主要是mark-sweep 2个阶段,将mark操作进行进一分解,其过程如下:
Mark setup (func Stack scan) → Make (concurrent make and assist make, make termination) → concurrent Sweep ; 其中 开始Mark setup的时候会有非常短暂的STW(平均每 10 到 30 微秒), 标记终止(make termination) 也会有STW, 进行收尾工作时间稍长,可以简单认为,STW发生在mark的开始和结束(开始时找到扫描开始的初始位置,开启写屏障;结束时关闭写屏障,进行收尾)
-
Mark 标记阶段:遍历堆的所有对象,采用 三色标记算法 (Go 1.5引入),标记是否还在使用。
- mark setup: 即mark开始前的准备工作,找到goroutine中函数栈帧中的扫描位置, 打开写屏障(write barrier,前面已经介绍过),允许在垃圾回收期间在堆上保持数据完整性,因为回收器和应用程序的 goroutine 将同时运行。要打开写保护,必须停止运行的每个应用程序 goroutine,产生STW,通常非常快,平均每 10 到 30 微秒;但是有特殊情况,紧密循环比如一个死循环或者循环时间长,没有调用函数触发,进而可能导致垃圾回收无法开始;
- concurrent mark: 在开启写保护器后,开始并发标记阶段。首先,回收器为其自身保留了 25% 可用 CPU 容量 。使用 Goroutine 执行回收工作,并需要应用程序 Goroutine 使用的相同的 P 和 M。开始标记堆内存中仍在使用的值。该工作首先通过检查所有现有 Goroutine 的栈帧以找到指向堆内存的根指针。然后从这些根指针遍历对象图 进行标记。
- assist mark: 如果收集器确定它需要减缓分配,它将会招募应用程序的 Goroutine 协助 Marking 工作,这称为 Mark Assist。任何应用程序 Goroutine 在 Mark Assist 中的时间量与它对堆内存的数据添加量成比例,可以更快地完成收集;如果任意一次收集最终需要大量的 Mark Assist,收集器可以更早开始下一次垃圾收集,以减少下一次收集所需的 Mark Assist 数量(需要辅助mark的任务多,需要提早开始)。
- make termination: 一旦标记工作完成,开始标记终止。这个阶段将关闭写屏障,执行各种清理任务以及计算下一个回收目标的时刻。在标记阶段处于紧密循环的协程也可能导致标记终止 STW 延迟延长。回收完成后,应用程序协程可以再次使用每个P,应用程序Goroutine可以充分使用cup资源。
-
Sweep 清除阶段:从根开始遍历对象图并释放不再被引用的对象块,清除操作是并发的;释放的过程是异步的,不是真正的清除;当应用程序goroutine尝试在堆内存中分配新内存时,会触发该操作,清理导致的延迟和吞吐量降低被分散到每次内存分配时。
ps: 整体思想可以借鉴
整体GC算法如下:from:https://go.dev/talks/2015/go-gc.pdf

Go GC 还包括一种在消耗高峰后释放内存的方法。假设应用程序基于两个阶段:
- 导致频繁分配大的堆空间的初始化阶段
- 具有适度分配小的堆空间的运行时阶段
Go 将如何解决大的heap空间回收后,还会继续使用呢?这是作为 GC 中的周期清理 periodic scavenger 所考虑的问题(具体可以看go1.20:src/runtime/mgcscavenge.go 代码了解)。一段时间后,GC 检测到不再需要这么大的堆空间,因此它会释放一些内存并将其返回给 OS。
tips:
如果GC periodic scavenger 不够快呢,可以使用手动强制将内存返回给操作系统debug.FreeOSMemory();但是这样有些问题,需要慎重使用:
- 一次将内存都归还给系统,这个操作太重了。会有延迟抖动,因为涉及到 lock
- 需要用户自己调这个函数,对代码是有侵入性
- 再次重用内存的时候会有较多开销,因为有 page fault
通过pprof/heap采集到的数据,在监控查看 RSS(进程/线程使用的物理内存) 的值 比 正常计算的Go应用进程使用的内存空间要大,主要原因是 Go GC之后内存空间没有马上返回给OS, 而是等到GC periodic scavenger 触发之后才会释放内存空间到OS中, GC之后未归还的内存空间大小为:HeapIdle(空闲内存大小) - HeapReleased(已释放归还给OS内存大小);
重要的问题是,GC 何时运行?Go 中提供两种方式设置 GOGC 环境变量 or debug.SetGCPercent 以及 debug.SetMaxHeap :
GOGC (debug.SetGCPercent )
与 Java 等其他语言相比,Go 配置仍然相当简单。它依赖于单一环境变量:GOGC. 该变量定义了自上次 GC 后触发另一次 GC 之前堆增长的百分比;默认值为 100%。
看一个具体的例子,假设 GC 刚刚被触发,当前堆大小为 128 MB。默认GOGC=100,则在堆大小达到 256 MB 时触发下一次 GC。每当堆大小翻倍时,默认情况下都会执行一次 GC。此外,如果在过去 2 分钟内未执行 GC,Go 将强制执行一次。
在生产环境中使用GOGC使用时需要注意,分析进行微调(取决于具体场景,机器性能):
- 减少阈值,会减低 堆空间 增长,但是增加了 GC 的压力。
- 增加阈值,会增加 堆空间 增长,但是减少了 GC 的压力。(适用于free 内存空间大的场景,因为清扫是异步触发的~)
tips: 通过设置GOGC=off或者debug.SetGCPercent(-1)关闭GC
debug.SetMaxHeap
对内存不足(OOM)的情况非常敏感的场景,直接自定一个使用堆大小的上限,可以结合debug.SetGCPercent(-1)手动关闭GC 使用,到达最大限制,则触发GC, 对于内存使用比较有规律的场景适合使用,如果频繁很快到达最大限制,则会频繁GC,得不偿失了。
GC 跟踪
可以通过设置打印 GC 跟踪GODEBUG环境变量,例如在运行基准测试时:
GODEBUG=gctrace=1 go test -bench=. -v
tips: 命令中的环境变量GODEBUG值 参考官方文档:Environment_Variables 设置,以及查看输出格式具体内容说明。每次 GC 运行时启用一个跟踪gctrace都会写入stderr。
必须了解 GC 的行为方式才能对其进行优化。可以使用GOGC来配置下一个 GC 周期何时被触发。在大多数情况下,保持它就100足够了。但是,如果应用程序可能面临导致频繁 GC 和延迟影响的请求峰值,可以增加该值。最后,在异常请求高峰的情况下,可以考虑使用将虚拟堆大小保持在最小值的技巧。
tips: 上面只是简单概括的介绍了下,随着时间推移可能不准确,Go中GC是一个复杂的过程,具体细节,可以通过如下文档一起实践学习:
了解GC细节入门: A Guide to the Go Garbage Collector Getting to Go: The Journey of Go’s Garbage Collector
了解通过GC Trace定位问题: Garbage Collection In Go : Part I - Semantics
100.不了解在 Docker 和 Kubernetes 中运行 Go 的影响
根据 2021 年 Go 开发人员调查 ( https://go.dev/blog/survey2021-results ),使用 Go 编写服务是最常见的用途。同时,Kubernetes 是部署这些服务的最广泛使用的平台。了解在 Docker 和 Kubernetes 中运行 Go 的含义非常重要,以防止出现 CPU 节流等常见情况。
GOMAXPROCS变量定义了负责同时执行用户级代码的操作系统线程的限制。默认情况下,它设置为 OS-apparent 逻辑 CPU 核心数。这在 Docker 和 Kubernetes 的上下文中意味着什么?
假设 Kubernetes 集群由八个核心节点组成。当一个容器部署在 Kubernetes 中时,可以定义一个 CPU 限制,以确保一个应用程序不会耗尽宿主机的所有资源。例如,以下配置将 CPU 的使用限制为 4,000 millicpu(或 millicores),因此四个 CPU 内核
可以假设在部署应用程序时,GOMAXPROCS将基于这些限制,因此值为4. 但事实并非如此;它被设置为主机上的逻辑核心数:8。那么,有什么影响呢?
Kubernetes 使用完全公平调度器 (CFS) 作为进程调度程序。CFS 还用于对 Pod 资源实施 CPU 限制。在管理 Kubernetes 集群时,管理员可以配置这两个参数:
- cpu.cfs_period_us(全局设置)
- cpu.cfs_quota_us(每个 Pod设置)
前者定义了一个时期,后者定义了一个配额。默认情况下,周期设置为 100 毫秒。同时,默认配额值是应用程序在 100 毫秒内可以消耗多少 CPU 时间。限制设置为四个核心,这意味着 400 ms (4 × 100 ms)。因此,CFS 将确保应用程序不会在 100 毫秒内消耗超过 400 毫秒的 CPU 时间。
想象一个场景,多个 goroutine 当前正在四个不同的线程上执行。每个线程被安排在不同的核心(1、3、4 和 8)上;
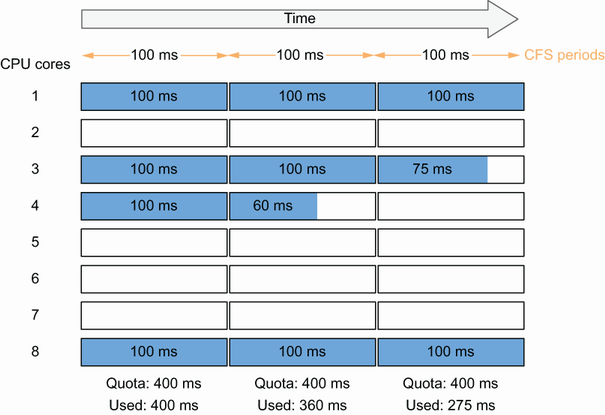
在第一个 100 ms 期间,有四个线程处于忙碌状态,因此消耗了 400 ms 中的 400:100% 的配额。在第二个时期,消耗了 400 毫秒中的 360 毫秒,依此类推。一切都很好,因为应用程序消耗的资源少于配额。
但是,记住GOMAXPROCS设置为8。因此,在最坏的情况下,可以有八个线程,每个线程都安排在不同的核心上。
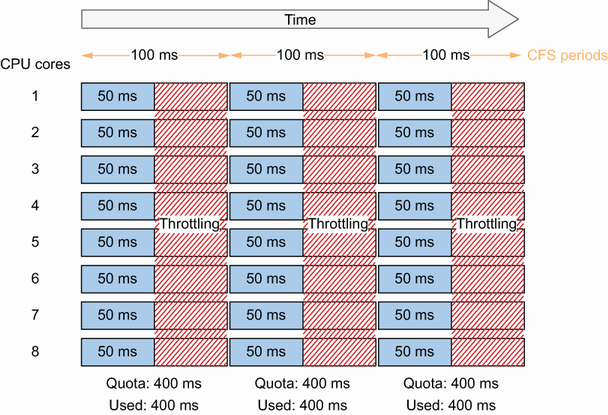
对于每 100 毫秒,配额设置为 400 毫秒。如果八个线程忙于执行 goroutine,50 毫秒后,达到 400 毫秒的配额(8 × 50 毫秒 = 400 毫秒)。会有什么后果?CFS 将限制 CPU 资源。因此,在另一个周期开始之前不会分配更多的 CPU 资源。换句话说,应用程序将暂停 50 毫秒。
例如,平均延迟为 50 毫秒的服务最多可能需要 150 毫秒才能完成。这可能是延迟的 300% 惩罚。
首先,请关注 Go issue 33803。也许在 Go 的未来版本中,GOMAXPROCS将支持 CFS。
今天的解决方案是依赖于由优步调用automaxprocs(github.com/uber-go/automaxprocs)。可以通过go.uber.org/automaxprocs 在main.go 中添加一个空白导入来使用这个库;它会自动设置GOMAXPROCS以匹配 Linux 容器 CPU 配额。在前面的示例中,GOMAXPROCS将设置为4而不是8,因此将无法达到 CPU 被节流的状态。
目前Go 不支持 CFS。GOMAXPROCS基于主机而不是定义的 CPU 限制。因此,可能会达到 CPU 被节流的状态,从而导致长时间的暂停和显着的延迟增加等实质性影响。在 Go 变得支持 CFS 之前,一种解决方案是依靠automaxprocs自动设置GOMAXPROCS为定义的配额。
概括
- 了解如何使用 CPU 缓存对于优化受 CPU 限制的应用程序很重要,因为 L1 缓存比主内存快大约 50 到 100 倍。
- 了解高速缓存行概念对于理解如何在数据密集型应用程序中组织数据至关重要。CPU 不会逐字获取内存;相反,它通常将内存块复制到 64 字节的缓存行。要充分利用每个单独的缓存行,利用好空间局部性。
- 让 CPU 可以预测代码也是优化某些功能的有效方法。例如,单位或恒定步幅对于 CPU 是可预测的,但非单位步幅(例如,链表)是不可预测的。
- 为避免关键步幅,从而只使用缓存的一小部分,请注意缓存是分区的。
- 了解false sharing对并发程序的影响,伪共享因为cache line的同步会带来一些cpu 时钟周期的性能损失。
- 使用指令级并行 (ILP) 来优化代码的特定部分,以允许 CPU 执行尽可能多的并行指令。识别数据危害是主要步骤之一。
- 可以通过记住在 Go 中基本类型与它们自己的大小对齐来避免常见错误。例如,请记住,按大小降序重组结构的字段可以导致更紧凑的结构(更少的内存分配和可能更好的空间局部性)。
- 在优化 Go 应用程序时,理解堆和栈之间的根本区别也应该是你的核心知识的一部分。栈分配几乎是免费的,而堆分配速度较慢并且依赖于 GC 来清理内存。
- 减少分配也是优化 Go 应用程序的一个重要方面。这可以通过不同的方式完成,例如仔细设计 API 以防止共享,了解常见的 Go 编译器优化,以及使用sync.Pool.
- 使用快速路径内联技术有效地减少调用函数的摊销时间。
- 依靠分析和执行跟踪器来了解应用程序的执行方式和要优化的部分。
- 了解如何调整 GC 可以带来多种好处,例如更有效地处理突然增加的负载。
- 为帮助避免在 Docker 和 Kubernetes 中部署时出现 CPU 节流,请记住 Go 不支持 CFS。
总结
总共花了10天左右把 100-go-mistakes-and-how-to-avoid-them 这本书看完,对于一些文中不够升入的地方,进行挖掘了下,了解弄清楚了背后的原理,知其然知其所以然之后,有些mistake是一些共性的问题,而且对于文中每个mistake,都应去实践操作一下,熟悉利用好Go相关工具,编译,测试,构建等等,文中大部分是语言层面的,工程方面也有些,特别像最后介绍的在K8S docker中CPU对Go语言本身的影响,实际遇到之后才会印象更深,应该从错误中去总结,而不是总结之后继续犯错,如此折返,意义不大;从错误点中多挖掘底层逻辑多思考总结。
原书地址: https://learning.oreilly.com/library/view/100-go-mistakes/9781617299599/
TIPS: 文中对于channel 介绍的比较少,比如channel 在生产(发送)和消费(接受)之间,1:1,1:N,M:1,M:N场景下如何关闭; 还有GPM的调度模型的详细介绍,以及内存分配器(这块在每个版本中相对迭代比较多,最好结合当前开发生产环境中使用的Go版本对其源码分析) 没有详细涉及到,可参考这些资料扩展: channel-closing , Understanding Channels , Go Memory Allocator ,scheduling-in-go , LearnConcurrency