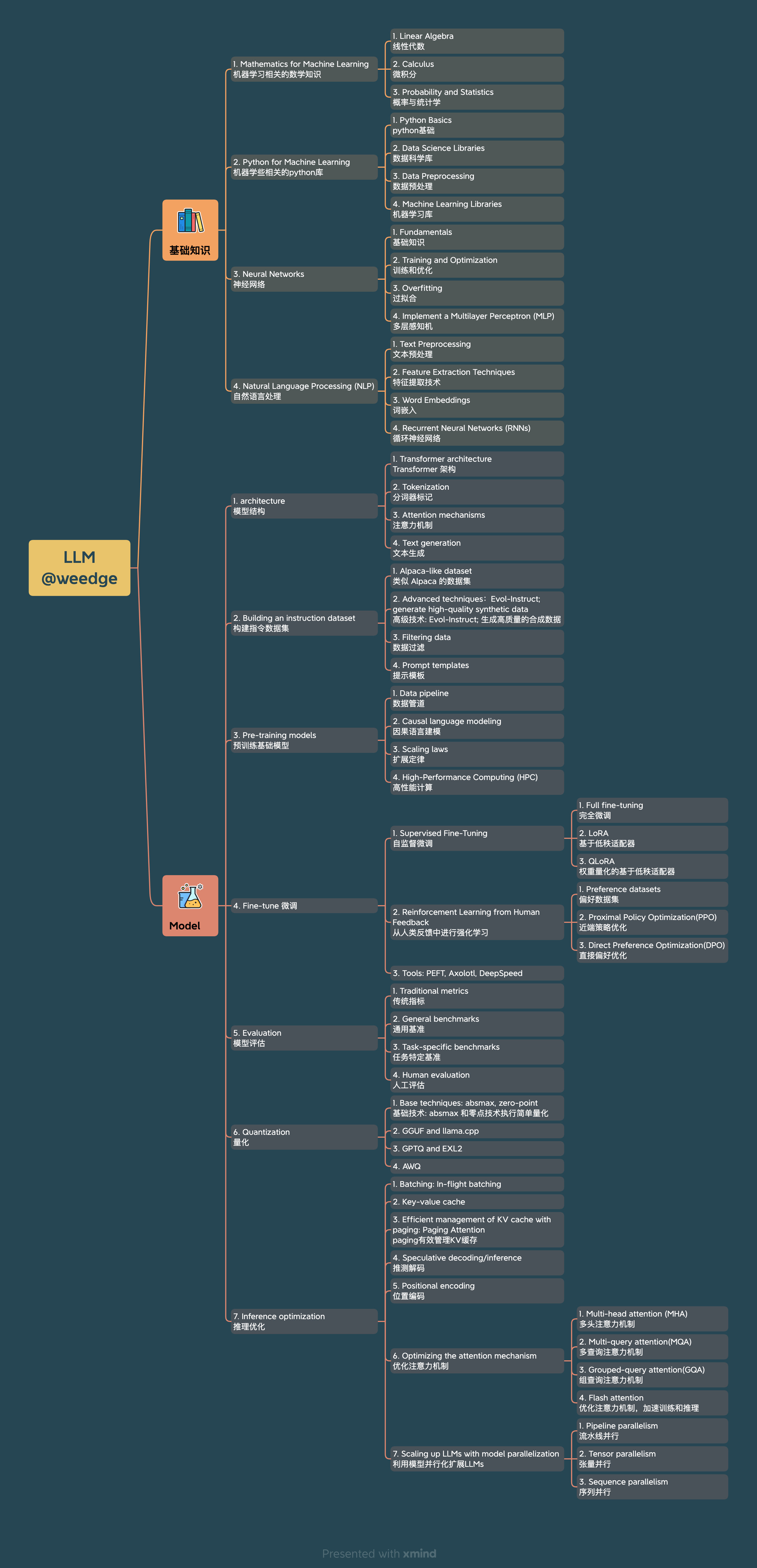
上图给出了学习LLM所需要的知识点。
该文主要是梳理LLM基础结构知识点,模型结构大多相同,以llama2模型结构为切入点,梳理相关知识点,以便构建整体知识体系,可方便快速阅读其他论文的改进点;结合参考学习中给出的链接补充基础知识。
将transformer层叠以创建大型模型会在各种语言任务中带来更高的准确性、少样本学习能力,甚至接近人类的新兴能力。这些基础模型在训练过程中成本高昂,而在推理过程中(一个经常发生的成本)可能需要大量内存和计算资源。如今最受欢迎的大型语言模型(LLMs)可以达到数百亿到数千亿个参数的规模,并且根据使用情况,可能需要处理长输入(或上下文),这也会增加成本。
本文讨论了LLM推理中最紧迫的挑战,以及一些实用的解决方案。读者应该对transformer架构和注意力机制有基本的理解。理解LLM推理的复杂性至关重要,我们将在接下来的部分进行介绍。
注:上篇译文有对 transformer 有相关的介绍,以及相关编码笔记入门;或者深入学习CS25: Transformers United V2 video

本文旨在让没有计算机科学背景的人深入了解 ChatGPT 和类似的 AI 系统(GPT-3、GPT-4、Bing Chat、Bard 等)的工作原理。ChatGPT 是一个聊天机器人——一种构建的对话式人工智能——但建立在大型语言模型之上。我们将把它们全部分解。在此过程中,我们将讨论它们背后的核心概念。本文不需要任何技术或数学背景。我们将大量使用隐喻来说明这些概念。我们将讨论为什么核心概念以它们的方式工作,以及我们可以期望或不期望像 ChatGPT 这样的大型语言模型做什么。
这就是我们要做的事情。我们将温和地介绍一些与大型语言模型和 ChatGPT 相关的术语,不使用任何行话。如果我必须使用行话,我会不使用行话来分解它。我们将从“什么是人工智能”开始,然后逐步提高。我会尽可能地使用一些反复出现的隐喻。我将讨论这些技术的影响,即我们应该期望它们做什么或不应该期望它们做什么。let’s go~!
注:主要是结合论文「Attention Is All You Need」理解Transformer。Transformer论文逐段精读

本文的目的是简单地解释开始开发基于 LLM 的应用程序所需的关键技术。它面向对机器学习概念有基本了解并希望深入研究的软件开发人员、数据科学家和人工智能爱好者。本文还提供了许多有用的链接以供进一步研究。这会很有趣!
注:本文可以作为一个索引目录(进一步阅读资料深入学习),从整体上了解下,毕竟现在LLM发展很快,可以发散或者focus某个领域;大部分LLM相关开源实现,可以手动demo下过程,至于炼丹了解过程即可,主要在场景上结合工程去利用好大力神丸在生产环境落地;还有就是应用场景,国内app应该可以复刻,如果模型和数据有了,缺个落地idea的话~

字符串数据的高效处理对于许多数据科学应用至关重要。为了从字符串数据中提取有价值的信息,RAPIDS libcudf提供了强大的工具来加速字符串数据转换。libcudf 是一个 C++ GPU DataFrame 库,用于加载、连接、聚合和过滤数据。
在数据科学中,字符串数据代表语音、文本、基因序列、日志记录和许多其他类型的信息。在使用字符串数据进行机器学习和特征工程时,必须经常对数据进行规范化和转换,然后才能将其应用于特定用例。libcudf 提供通用 API 和设备端实用程序,以支持各种自定义字符串操作。
这篇文章演示了如何使用 libcudf 通用 API 巧妙地转换字符串列。您将获得有关如何使用自定义内核和 libcudf 设备端实用程序解锁峰值性能的新知识。这篇文章还向您介绍了如何最好地管理 GPU 内存和高效构建 libcudf 列以加速字符串转换的示例。
(注:从文件中获取数据到buffer中,都需要通过字符串处理操作,特别是split操作,如果是数值,需要atoi,atof操作进行数据分析,向量化操作等, 和数据处理打交道的 super 马里奥 应该学会这个工具,这里直接使用底层操作库libcudf;集成的其他语言有java(JNI)和python(cython), 主要是方便和现有 大数据生态打通(会有一些内存方面的性能损耗),大多是离线处理场景,特别是LLM的预训练场景)

执行详尽的精确 k 最近邻 (kNN) 搜索,也称为暴力搜索(brute-force search),成本高昂,并且它不能很好地扩展到更大的数据集。在向量搜索期间,暴力搜索需要计算每个查询向量和数据库向量之间的距离。对于常用的欧几里德和余弦距离,计算任务等同于大型矩阵乘法。
虽然 GPU 在执行矩阵乘法方面效率很高,但随着数据量的增加,计算成本变得令人望而却步。然而,许多应用程序不需要精确的结果,而是可以为了更快的搜索而牺牲一些准确性。当不需要精确的结果时,近似最近邻 (ANN) 方法通常可以减少搜索期间必须执行的距离计算的数量。
本文主要介绍了 IVF-Flat,这是 NVIDIA RAPIDS RAFT 中的一种方法。IVF-Flat 方法使用原始(即Flat)向量的倒排索引 (IVF)。此算法提供了简单的调整手段,以减少整体搜索空间并在准确性和速度之间进行权衡。
为了帮助了解如何使用 IVF-Flat,我们讨论了该算法的工作原理,并演示了Python和C++ APIs我们介绍了索引构建的设置参数,并提供了如何配置 GPU 加速的 IVF-Flat搜索的技巧。这些步骤也可以在示例中遵循Python notebook和C++ project.最后,我们演示了 GPU 加速的向量搜索比 CPU 搜索快一个数量级。
