案例研究:对最后一级缓存大小的敏感性
本案例研究的目的是展示如何确定应用程序是否对最后一级缓存 (LLC) 的大小敏感。利用这些信息,您可以在购买计算系统硬件组件时做出明智的决策。同样,您以后可以确定对其他因素(例如内存带宽、核心数量、处理器频率等)的敏感性,并可能购买更便宜的计算机,同时保持相同的性能水平。
在这个案例研究中,我们对同一组应用程序运行多次,LLC 大小各不相同。现代服务器处理器允许用户控制 LLC 空间分配给处理器线程。通过这种方式,用户可以限制每个线程仅使用其分配的共享资源数量。此类设施通常称为服务质量 (QoS) 扩展。它们可用于优先处理关键性能应用程序并减少与同一系统中其他线程的干扰。除了 LLC 分配之外,QoS 扩展还支持限制内存读取带宽。
我们的分析将帮助我们识别当 LLC 大小减小时性能显著下降的应用程序。我们称这样的应用程序对 LLC 大小敏感。我们还确定了不敏感的应用程序,即 LLC 大小不会影响性能。此结果可用于正确调整处理器 LLC 的大小,特别是考虑到市场上可用范围广泛。例如,我们可以确定应用程序是否可以从更大的 LLC 中受益,即投资新硬件是否合理。相反,如果应用程序对小缓存大小已足够,那么我们可以购买更便宜的处理器。
对于本案例研究,我们使用 AMD Milan 处理器,但其他服务器处理器,例如 Intel Xeon 和 ARM ThunderX,也包含硬件支持,允许用户控制 LLC 空间和内存读取带宽分配给处理器线程。
目标机器:AMD EPYC 7313P
我们使用了一个服务器系统,该系统配有 16 核 AMD EPYC 7313P 处理器,代号为 Milan,AMD 于 2021 年推出。该系统的关键特性在表@tbl:experimental_setup](#experimental_setup) 中指定。
| 特性 | 值 |
|---|---|
| 处理器 | AMD EPYC 7313P |
| 核心数 x 线程数 | 16 × 2 |
| 配置 | 4 CCX × 4 个核心/CCX |
| 频率 | 3.0/3.7 GHz, 基础/最大 |
| L1 缓存 (I, D) | 8 通道,32 KiB (每个核心) |
| L2 缓存 | 8 通道,512 KiB (每个核心) |
| LLC | 16 通道,32 MiB,非包容式 (每个 CCX) |
| 主内存 | 512 GiB DDR4,8 个通道,标称峰值带宽:204.8 GB/s |
| TurboBoost | 已禁用 |
| 超线程 | 已禁用 (1 个线程/核心) |
| 操作系统 | Ubuntu 22.04,内核 5.15.0-76 |
表: 实验所用服务器的主要特性。
AMD Milan 7313P 处理器的集群式内存层次结构
图 @fig:milan7313P 展示了 AMD Milan 7313P 处理器的集群式内存层次结构。它由四个核心复合芯片 (CCD) 组成,这些 CCD 通过一个 I/O 芯片连接彼此和片外内存。每个 CCD 集成一个核心复合体 (CCX) 和一个 I/O 连接。反过来,每个 CCX 都有四个 Zen3 内核,可以运行八个线程,共享一个 32 MiB 的受害者 LLC,即 LLC 填充了从 CCX 的四个 L2 缓存驱逐的缓存行。
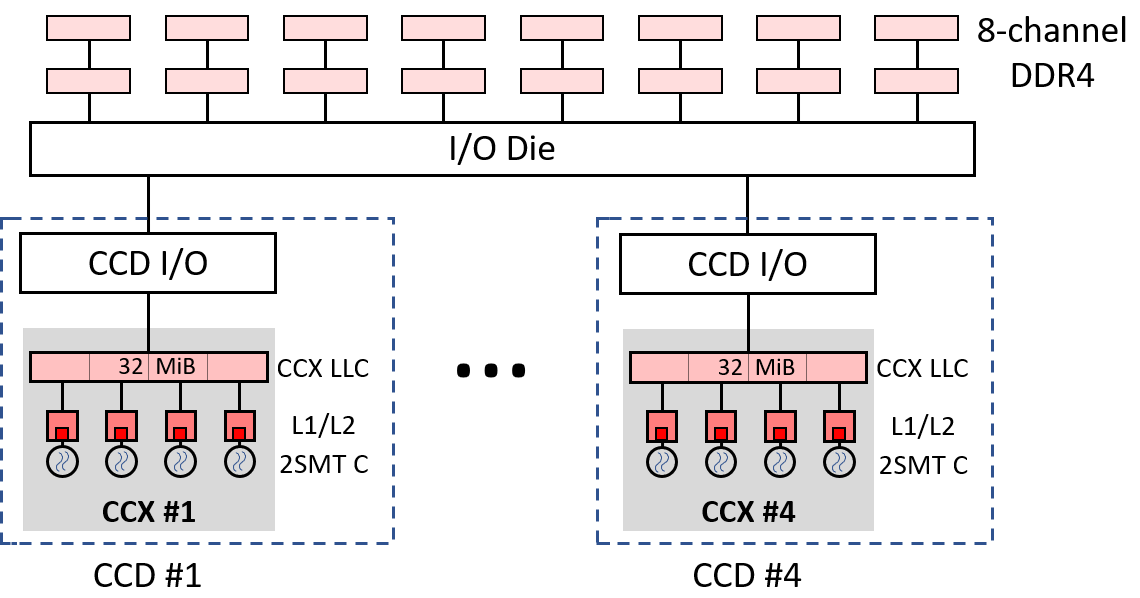
虽然总共有 128 MiB 的 LLC,但 CCX 的四个内核无法将缓存行存储在除其自己的 32 MiB LLC (32 MiB/CCX x 4 CCX) 以外的 LLC 中。由于我们将运行单线程基准测试,因此我们可以关注单个 CCX。实验中 LLC 的大小将在 0 到 32 MiB 之间变化,步长为 2 MiB。
工作负载:SPEC CPU2017
我们使用 SPEC CPU2017 套件中的部分基准测试。4 SPEC CPU2017 包含一组行业标准性能基准测试,可对处理器、内存子系统和编译器进行压力测试。它被广泛用于比较高性能系统的性能。它也广泛用于计算机架构研究。
具体来说,我们从 SPEC CPU2017 中选择了 15 个内存密集型基准测试(6 个 INT 和 9 个 FP),正如 [@MemCharacterizationSPEC2006] 中建议的那样。这些应用程序使用 GCC 6.3.1 和以下编译器选项编译:-g -O3 -march=native -fno-unsafe-math-optimizations -fno-tree-loop-vectorize,正如 SPEC 在套件提供的配置文件中指定的。
控制和监控 LLC 分配
为了监控和执行 LLC 分配和内存读取带宽的限制,我们将使用 AMD64 技术平台服务质量扩展 [@QoSAMD]。用户可以通过特定于模型的寄存器 (MSR) 的库来管理此 QoS 扩展。首先,必须通过写入 PQR_ASSOC 寄存器 (MSR 0xC8F) 为线程或一组线程分配资源管理标识符 (RMID) 和服务类别 (COS)。以下是硬件线程 1 的示例命令:
# 写入 PQR_ASSOC (MSR 0xC8F): RMID=1, COS=2 -> (COS << 32) + RMID
$ wrmsr -p 1 0xC8F 0x200000001
其中 -p 1 表示硬件线程 1. 我们显示的所有 rdmsr 和 wrmsr 命令都需要 root 访问权限。
LLC 空间管理通过写入每个线程的 16 位二进制掩码执行。掩码的每个位允许线程使用给定的十六分之一的 LLC(在 AMD Milan 7313P 的情况下为 1/16 = 2 MiB)。多个线程可以使用相同的片段,这意味着竞争性地共享相同的 LLC 子集。
要设置线程 1 对 LLC 使用的限制,我们需要写入 L3_MASK_n 寄存器,其中 n 是 COS,即相应 COS 可以使用的缓存分区。例如,要限制线程 1 仅使用 LLC 可用空间的一半,请运行以下命令:
# 写入 L3_MASK_2 (MSR 0xC92): 0x00FF (LLC 空间的一半)
$ wrmsr -p 1 0xC92 0x00FF
现在,要监控硬件线程 1 对 LLC 的使用情况,首先我们需要将监控标识符 RMID 与 LLC 监控事件 (L3 缓存占用率监控,evtID 0x1) 关联起来。我们通过写入 QM_EVTSEL 控制寄存器 (MSR 0xC8D) 来做到这一点。之后,我们应该读取 QM_CTR 寄存器 (MSR 0xC8E):
# 写入 QM_EVTSEL (MSR 0xC8D): RMID=1, evtID=1 -> (RMID << 32) + evtID
$ wrmsr -p 1 0xC8D 0x100000001
# 读 QM_CTR (MSR 0xC8E)
$ rdmsr -p 1 0xC8E
这将使我们能够估计缓存行中的 LLC 使用情况7。要将此值转换为字节,我们需要将 rdmsr 命令返回的值乘以缓存行大小。
同样,可以限制分配给线程的内存读取带宽。这是通过将无符号整数写入特定的 MSR 寄存器来实现的,该寄存器以 1/8 GB/s 的增量设置最大读取带宽。欢迎感兴趣的读者阅读 [@QoSAMD] 了解更多详细信息。
评估指标
用于量化应用程序性能的最终指标是执行时间。为了分析内存层次结构对系统性能的影响,我们还将使用以下三个指标:1) CPI,每条指令的周期数6,2) DMPKI,每千条指令的 LLC 中的需求缺失,以及 3) MPKI,每千条指令的 LLC 中的总缺失(需求 + 预取)。虽然 CPI 与应用程序性能直接相关,但 DMPKI 和 MPKI 不一定会影响性能。表@tbl:metrics](#metrics) 显示了用于从特定硬件计数器计算每个指标的公式。有关每个计数器的详细描述,请参见 AMD 的处理器编程参考 [@amd_ppr]。
| 指标 | 公式 |
|---|---|
| CPI | 非暂停周期 (PMCx076) / 退休指令 (PMCx0C0) |
| DMPKI | 需求数据缓存填充9 (PMCx043) / (退休指令 (PMCx0C0) / 1000) |
| MPKI | L3 缺失8 (L3PMCx04) / (退休指令 (PMCx0C0) / 1000) |
表:案例研究中使用的指标计算公式。
硬件计数器可以通过 MSR 进行配置和读取。配置包括指定要监视的事件以及如何监视它。在我们的系统中,每个线程有 6 个核心计数器,每个 L3-CCX 有 6 个计数器,以及 4 个数据结构计数器。访问核心事件通过写入 PERF_CTL[0-5] 控制寄存器 (MSR 0xC001020[0,2,4,6,8,A]) 完成。PERF_CTR[0-5] 寄存器 (MSR 0xC001020[1,3,5,7,9,B]) 是与这些控制寄存器关联的计数器。例如,对于计数器 0 来收集在硬件线程 1 上运行的应用程序退休的指令数,执行以下命令:
$ wrmsr -p 1 0xC0010200 0x5100C0
$ rdmsr -p 1 0xC0010201
其中 -p 1 表示硬件线程 1,0xC0010200 是计数器 0 (PERF_CTL[0]) 的控制 MSR,0x5100C0 指定要测量的事件标识符(已退休指令,PMCx0C0)以及如何测量它(用户事件)。使用 wrmsr 完成配置后,可以使用 rdmsr 命令读取收集已退休指令数的计数器 0。
类似地,通过写入 L3 控制寄存器 (MSR 0xC001023[0,2,4,6,8,A]) 并读取其关联计数器 (MSR 0xC001023[1,3,5,7,9,B]) 来访问 L3 缓存事件。最后,通过写入 DF_PERF_CTL[0-3] 控制寄存器 (MSR 0xC001024[0,2,4,6]) 并读取其关联的 DF_PERF_CTR[0-3] 寄存器 (MSR 0xC001024[1,3,5,7]) 来访问数据结构事件10。
本案例研究中使用的的方法在 [@Balancer2023] 中更详细地描述。可以在以下公共存储库中找到重现实验所需的代码和信息:https://github.com/agusnt/BALANCER。
结果
我们在系统中单独运行一套 SPEC CPU2017 基准测试,仅使用一个实例和单个硬件线程。重复这些运行,同时将可用 LLC 大小从 0 更改为 32 MiB,步长为 2 MiB。图 @fig:characterization_llc 从左到右以图形方式显示每个分配的 LLC 大小的 CPI、DMPKI 和 MPKI。对于 CPI 图表,Y 轴上的较低值意味着更好的性能。此外,由于系统上的频率是固定的,因此 CPI 图表反映了绝对分数。例如,具有 32 MiB LLC 的 520.omnetpp (虚线) 比 0 MiB LLC 快 2.5 倍。
对于 DMPKI 和 MPKI 图表,Y 轴上的值越低越好。对应于 503.bwaves (实线)、520.omnetpp (虚线) 和 554.roms (虚线) 的三条线代表了所有应用程序中观察到的三个主要趋势。我们不显示其余基准测试。
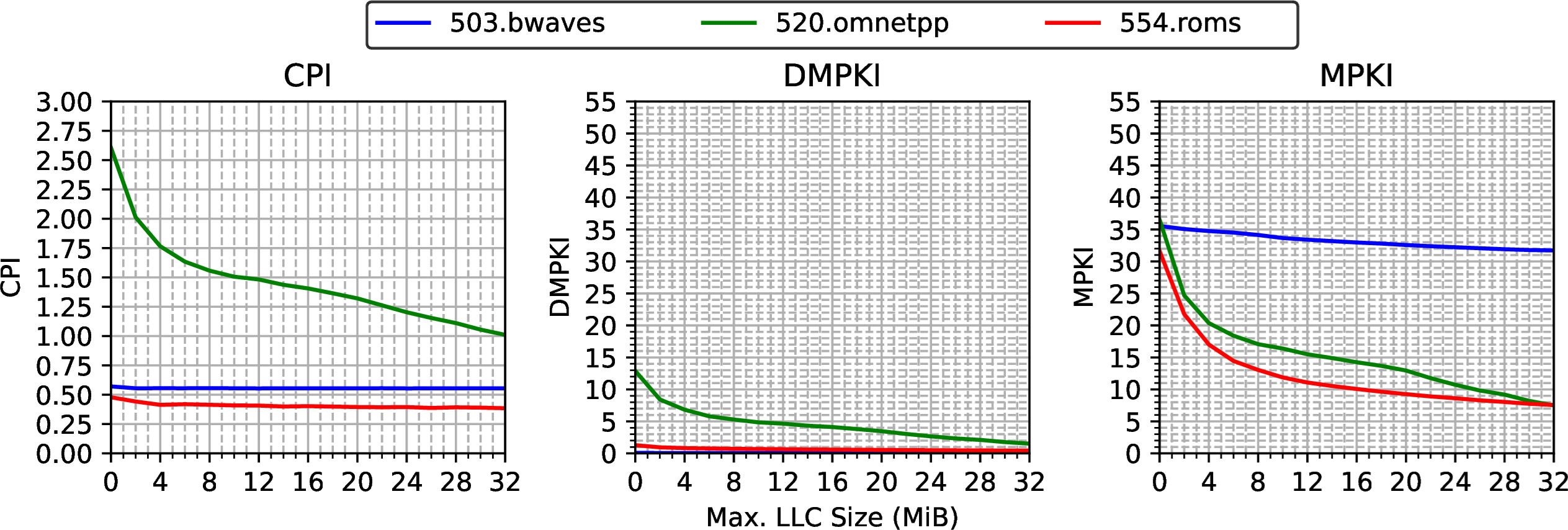
在 CPI 和 DMPKI 图表中可以区分两种行为。一方面,520.omnetpp 利用了其在 LLC 中的可用空间:随着 LLC 中分配的空间增加,CPI 和 DMPKI 都显着降低。我们可以说 520.omnetpp 的行为对 LLC 可用大小敏感。增加分配的 LLC 空间可以提高性能,因为它避免了驱逐将来会使用的缓存行。
相比之下,503.bwaves 和 554.roms 不会利用所有可用的 LLC 空间。对于这两个基准测试,随着 LLC 中的分配限制增加,CPI 和 DMPKI 大致保持不变。我们可以说这两个应用程序的性能对其在 LLC 中的可用空间不敏感。如果我们的应用程序表现出这种行为,我们可以选择具有较小 LLC 尺寸的处理器而不牺牲性能。
现在让我们分析 MPKI 图表,其中结合了 LLC 需求缺失和预取请求。首先,我们可以看到 MPKI 值总是远高于 DMPKI 值。也就是说,大多数块都是由预取器从内存加载到芯片内层次结构中的。这种行为是由于预取器在预加载私有缓存以供使用的数据方面非常高效,从而消除了大多数需求缺失。
对于 503.bwaves,我们观察到 MPKI 与 CPI 和 DMPKI 图表大致保持在相同水平。基准测试中可能没有太多数据重用和/或内存流量非常低。520.omnetpp 工作负载的行为与我们之前确定的相同:MPKI 随着可用空间的增加而减少。但是对于 554.roms,MPKI 图表显示随着可用空间增加,总缺失急剧下降,而 CPI 和 DMPKI 保持不变。在这种情况下,基准测试中存在数据重用,但这对性能无关紧要。预取器可以提前获取所需数据,消除需求缺失,无论 LLC 中可用空间如何。但是,随着可用空间减少,预取器无法在 LLC 中找到块并且必须从内存加载它们的可能性会增加。因此,为这类应用程序提供更多 LLC 容量不会直接提升其性能,但会使系统受益,因为它减少了内存流量。
通过查看 CPI 和 DMPKI,我们最初认为 554.roms 对 LLC 大小不敏感。但通过分析 MPKI 图表,我们需要重新考虑我们的陈述并得出结论,即 554.roms 也对 LLC 大小敏感,因此最好不要限制其可用 LLC 空间,以免增加内存带宽消耗。更高的带宽消耗可能会增加内存访问延迟,进而意味着系统上运行的其他应用程序的性能下降 [@Balancer2023]。
4. SPEC CPU® 2017 - https://www.spec.org/cpu2017/ ↩
6. 我们使用 CPI 而不是每条指令的时间,因为我们假设 CPU 频率在实验过程中不会改变。 ↩
7. AMD 文档 [@QoSAMD] 更准确地使用了术语 L3 缓存转换因子,可以通过 cpuid 指令确定。 ↩
8. 我们仅使用掩码计算 L3 缺失,具体为 L3Event[0x0300C00000400104]。 ↩
9. 我们使用了MemIoRemote和MemIoLocal这两个子变量,它们从连接在远程/本地NUMA节点上的DRAM或IO请求填充数据缓存。 ↩
10. 在我们的研究中,我们没有使用数据结构计数器。 ↩