现代CPU设计
为了看到我们在本章讨论的所有概念如何在实践中使用,让我们来看看英特尔第12代酷睿处理器Goldencove的实现,该处理器于2021年上市。该核心被用作Alderlake和Sapphire Rapids平台中的P核心。图 @fig:Goldencove_diag 显示了Goldencove核心的模块图。请注意,本节仅描述了单个核心,而不是整个处理器。因此,我们将跳过关于频率、核心数量、L3缓存、核心互连、内存延迟和带宽以及其他内容的讨论。
]。*](https://raw.githubusercontent.com/dendibakh/perf-book/main/img/uarch/goldencove_block_diagram.png)
该核心分为一个按顺序执行的前端,负责从内存中提取和解码x86指令为ops,以及一个6宽度的超标量、乱序执行的后端。Goldencove核心支持2路SMT。它有一个32KB的一级指令缓存(L1 I-cache),和一个48KB的一级数据缓存(L1 D-cache)。L1缓存由统一的1.25MB(服务器芯片中为2MB)L2缓存支持。L1和L2缓存对每个核心是私有的。在本节末尾,我们还将查看TLB层次结构。
CPU前端
CPU前端由一些数据结构组成,用于从内存中提取和解码指令。其主要目的是向CPU后端提供准备好的指令,后者负责实际执行指令。
技术上讲,指令提取是执行指令的第一阶段。但一旦程序达到稳定状态,分支预测单元(BPU)就会引导CPU前端的工作。这就是从BPU到指令缓存的箭头的原因。BPU预测所有分支指令的方向,并根据这个预测引导下一个指令提取。
BPU的核心是一个包含12K条目的分支目标缓冲区(BTB),其中包含有关分支及其目标的信息。这些信息被预测算法使用。每个周期,BPU生成下一个提取地址,并将其传递给CPU前端。
CPU前端每个周期从L1 I-cache中提取32字节的x86指令。这在两个线程之间共享,因此每个线程每隔一个周期会获得32字节。这些是复杂的、可变长度的x86指令。首先,预解码阶段通过检查指令来确定和标记可变指令的边界。在x86中,指令长度可以从1字节到15字节不等。该阶段还识别分支指令。预解码阶段将多达6条指令(也称为宏指令)移动到指令队列(图表中未显示)中,该队列在两个线程之间划分。指令队列还支持一个宏指令融合单元,它检测到两个宏指令可以融合成一个单一的微操作(op)。这种优化可以节省流水线中的带宽。
稍后,多达六个预解码指令每个周期从指令队列发送到解码器单元。两个SMT线程每个周期交替访问此接口。6路解码器将复杂的宏操作转换为固定长度的ops。解码后的ops被排队到指令解码队列(IDQ),在图表上标记为“op队列”。
前端的一个主要性能提升特性是解码流缓冲区(DSB)或op缓存。其动机是在与L1 I-cache并行工作的单独结构中缓存宏操作到ops的转换。当BPU生成一个新地址进行提取时,也会检查DSB,以查看ops的转换是否已经在DSB中可用。频繁发生的宏操作会命中DSB,流水线将避免为32字节的捆绑重复执行昂贵的预解码和解码操作。DSB每个周期可以提供八个ops,并且最多可以容纳4K个条目。
一些非常复杂的指令可能需要比解码器处理的ops更多。这些指令的ops来自微码顺序器(MSROM)。这些指令的示例包括用于字符串操作、加密、同步等的HW操作支持。此外,MSROM保留了处理异常情况的微码操作,例如分支预测失败(需要流水线刷新)、浮点辅助(例如,当指令与非规范化的浮点值进行操作时)等。MSROM每个周期可以向IDQ推送最多4个ops。
指令解码队列(IDQ)提供了顺序CPU前端和乱序CPU后端之间的接口。IDQ按顺序排列ops,并且每个逻辑处理器在单线程模式下可以容纳144个ops,在SMT活跃时每个线程可以容纳72个ops。这是顺序CPU前端结束并且乱序CPU后端开始的地方。
CPU后端
CPU后端采用乱序执行引擎执行指令并存储结果。CPU后端的核心是512条目的重排序缓冲区(ROB)。该单元在图表中被称为"分配/重命名(Allocate / Rename)"。它有几个作用。首先,它提供寄存器重命名。只有16个通用整数寄存器和32个向量/SIMD体系结构寄存器,但是物理寄存器的数量要多得多1。物理寄存器位于称为物理寄存器文件(PRF)的结构中。从体系结构可见寄存器到物理寄存器的映射保存在寄存器别名表(RAT)中。
其次,ROB分配执行资源。当一条指令进入ROB时,将分配一个新条目,并为其分配资源,主要是一个执行单元和目标物理寄存器。ROB每个周期可以分配多达6个ops。
第三,ROB跟踪推测执行。当一条指令完成其执行时,其状态会更新,并且会保留在那里,直到前面的指令也完成。之所以这样做,是因为指令总是按程序顺序退役。一旦一条指令退役,其ROB条目将被释放,并且指令的结果变得可见。退役阶段比分配阶段更宽:ROB每个周期可以退役8条指令。
处理器以特定方式处理某些操作,通常称为习惯用法,这些操作不需要或成本较低。处理器识别这些情况并允许它们比常规指令运行得更快。以下是一些这种情况:
- 置零(Zeroing):为了将零赋值给一个寄存器,编译器通常使用
XOR / PXOR / XORPS / XORPD等指令,例如XOR RAX, RAX,编译器更喜欢使用这些指令,而不是等效的MOV RAX, 0x0指令,因为XOR编码使用的编码字节较少。这种置零习惯用法不会像其他常规指令一样执行,而是在CPU前端解析,这样可以节省执行资源。指令随后像通常一样被退役(retires)。 - 移动消除(Move elimination):类似于前一个,寄存器到寄存器的mov操作,例如
MOV RAX, RBX,可以在零周期延迟内执行。 - NOP指令:
NOP通常用于填充或对齐的目的。它只是被标记为已完成,而不将其分配到保留站(Reservation Station)。 - 其他旁路(Other bypasses):CPU设计架构师还优化了某些算术操作。例如,任何数乘以一始终得到相同的数。除以一也是如此。任何数乘以零始终得到零,等等。某些CPU可以在运行时识别这些情况,并以比常规乘法或除法更短的延迟执行它们。
"调度器/保留站(Scheduler / Reservation Station)"(RS)是跟踪给定op的所有资源可用性并在准备就绪时将op分派到分配端口的结构。当一条指令进入RS时,调度器开始跟踪其数据依赖关系。一旦所有源操作数可用,RS尝试将op分派到空闲的执行端口。RS的条目比ROB少。它每个周期最多可以分派6个ops。
如图 @fig:Goldencove_diag 所示,有12个执行端口:
- 端口0、1、5、6和10提供所有整数(INT)以及浮点和向量(VEC/FP)操作。分派到这些端口的指令不需要内存操作。
- 端口2、3和11用于地址生成(AGU)和加载操作。
- 端口4和9用于存储操作(STD)。
- 端口7和8用于地址生成。
分派的算术操作可以进入INT或VEC/FP执行端口。整数和向量/FP寄存器堆栈位于不同位置。从INT堆栈到VEC/FP以及反之的操作(例如,转换、提取或插入)会带来额外的惩罚。
Load-Store Unit
Goldencove核心每个周期最多可以执行三次加载和两次存储操作。一旦加载或存储操作离开调度器,加载-存储(LS)单元负责访问数据并将其保存在寄存器中。LS单元有一个加载队列(LDQ,标记为“加载缓冲区”)和一个存储队列(STQ,标记为“存储缓冲区”),它们的大小未公开2 。LDQ和STQ都在调度器分派时接收操作。
当有内存加载请求时,LS使用虚拟地址查询L1缓存,并在TLB中查找物理地址转换。这两个操作同时启动。L1 D-cache的大小为48KB。如果两个操作都命中,则加载将数据传递给整数单元或浮点单元,并离开LDQ。类似地,存储将数据写入数据缓存并退出STQ。
在发生L1未命中时,硬件会启动对(私有)L2缓存标签的查询。L2缓存有两种变体:客户端为1.25MB,服务器处理器为2MB。在查询L2缓存时,会分配一个64字节宽的填充缓冲区条目(FB),一旦缓存行到达,它将保留缓存行。Goldencove核心有16个填充缓冲区。为了降低延迟,同时会向L3缓存发送一次猜测查询,与L2缓存查找并行进行。
如果两个加载访问相同的缓存行,它们将命中相同的FB。这样的两个加载将被"粘合(glued)"在一起,只会启动一个内存请求。LS单元动态重新排序操作,支持旧加载操作绕过旧加载和旧非冲突存储操作绕过旧加载。此外,LS单元在存在包含加载的所有字节的较旧存储并且存储的数据已生成并在存储队列中可用时,支持存储到加载的转发。
如果确认L2未命中,则加载将继续等待L3缓存的结果,这会产生更高的延迟。从那时起,请求离开核心并进入"uncore",这是您可能经常在性能分析工具中看到的术语。核心中未完成的未命中在超级队列(SQ,图中未显示)中被跟踪,该队列可以跟踪高达48个uncore请求。在L3未命中的情况下,处理器开始设置内存访问。进一步的细节超出了本章的范围。
当发生存储时,在一般情况下,要修改一个内存位置,处理器需要加载完整的缓存行,对其进行更改,然后将其写回内存。如果要写入的地址不在缓存中,则需要执行与加载类似的机制将数据带入。在将数据写入缓存层之前,存储不能完成。
当然,存储操作也有一些优化。首先,如果我们处理的是一个存储或多个相邻存储(也称为流存储(streaming stores)),这些存储修改了整个缓存行,则无需首先读取数据,因为所有字节都将被覆盖。因此,处理器将尝试组合写入以填充整个缓存行。如果成功,根本不需要内存读取操作。
其次,写入组合使多个存储组装在一起,并作为一个单元写入缓存层次结构。因此,如果多个存储修改同一缓存行,则只会向内存子系统发出一个内存写入请求。现代处理器具有称为存储缓冲区(store buffer)的数据结构,该结构尝试合并存储。存储指令将数据从寄存器复制到存储缓冲区。从那里,它可以写入L1缓存,或者它可以与其他存储组合到同一缓存行。存储缓冲区的容量有限,因此它只能暂时保存对缓存行的部分写入的请求。然而,当数据在存储缓冲区等待写入时,其他加载指令可以直接从存储缓冲区读取数据(存储到加载的转发(store-to-load forwarding))。
最后,如果我们在覆盖数据之前读取数据,缓存行通常会保留在缓存中,替换其他行。通过使用非临时(non-temporal)存储,可以改变这种行为,这是一种特殊的CPU指令,不会保留修改后的行在缓存中。在我们知道一旦更改数据就不再需要数据的情况下,非临时存储有助于更有效地利用缓存空间。非临时存储通过不驱逐其他可能很快需要的数据来帮助更有效地利用缓存空间。
TLB层次结构
回想一下[@sec:TLBs],虚拟地址到物理地址的转换被缓存在TLB中。Golden Cove的TLB层次结构如图 @fig:GLC_TLB 所示。与常规数据缓存类似,它有两个级别,其中级别1分别为指令(ITLB)和数据(DTLB)有单独的实例。L1 ITLB有256个条目,用于常规的4KB页面,覆盖256 * 4KB等于1MB的内存空间,而L1 DTLB有96个条目,覆盖384KB。
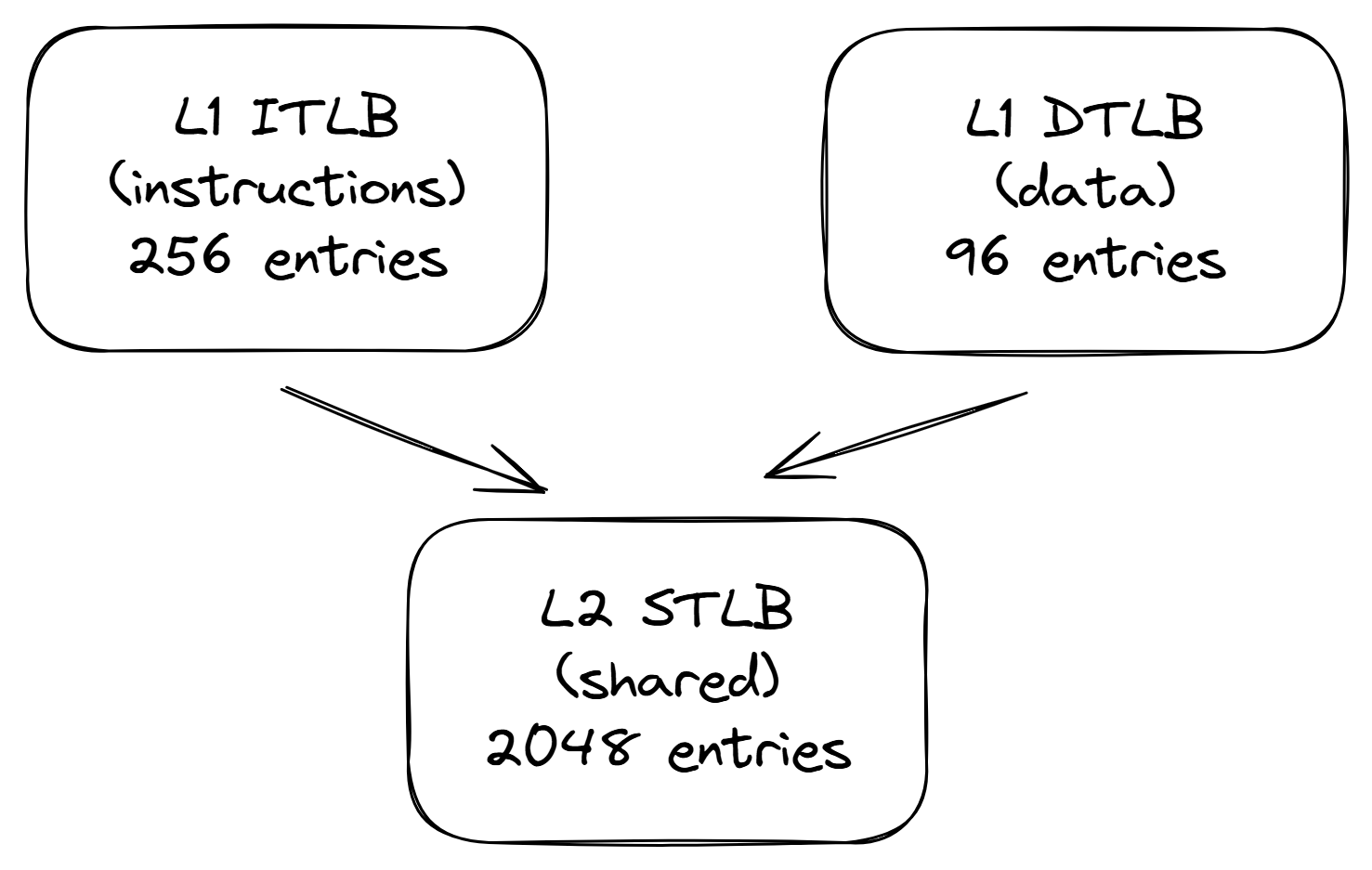
第二级别的层次结构(STLB)缓存了指令和数据的转换。这是一个更大的存储,用于为在L1 TLB中未命中的请求提供服务。L2 STLB可以容纳2048个最近的数据和指令页面地址转换,覆盖总共8MB的内存空间。对于2MB的大页面,可用的条目较少:L1 ITLB有32个条目,L1 DTLB有32个条目,而L2 STLB只能使用1024个条目,这些条目也是共享的常规4KB页面。
如果在TLB层次结构中找不到转换,则必须通过"行走(walking)"内核页表来检索。有一种机制可以加速这种情况,称为硬件页行走器。回想一下,页表是一个根据子表构建的基数树,其中子表的每个条目都包含指向树下一级的指针。
加速页行走过程的关键要素是一组页结构缓存3,它缓存了页表结构中的热点条目。对于4级页表,我们有最低有效的十二位(11:0)用于页面偏移(未转换),并且页面编号的位47:12。虽然TLB中的每个条目都是一个完整的单独转换,但页结构缓存仅覆盖地址的上3级(位47:21)。其思想是减少在TLB未命中的情况下所需的加载数量。例如,如果我们在地址的第1级和第2级找到了一个转换(位47:30),则我们只需要执行剩下的2个加载。
Goldencove微体系结构有四个专用页行走器,允许它同时处理4个页面行走。在TLB未命中的情况下,这些硬件单元将向内存子系统发出所需的加载,并使用新条目填充TLB层次结构。由页行走器生成的页表加载可以在L1、L2或L3缓存中命中(详细信息未公开)。最后,页行走器可以预测未来的TLB未命中,并在未命中实际发生之前进行推测性页面行走以更新TLB条目。
Goldencove的规格未公开两个SMT线程之间资源共享的方式。但是一般来说,为了提高这些资源的动态利用,缓存、TLB和执行单元是完全共享的。另一方面,用于在主要流水线阶段之间分段指令的缓冲区要么被复制,要么被分区。这些缓冲区包括IDQ、ROB、RAT、RS、LDQ和STQ。PRF也是复制的。
1. 大约有300个物理通用寄存器(GPRs)和类似数量的向量寄存器。实际寄存器数量未公开。 ↩
2. LDQ和STQ的大小未公开,但人们已经测量过分别为192和114条目。 ↩
3. AMD的等效物称为Page Walk Caches。 ↩