持续性能分析
在第 6 章中,我们介绍了进行性能分析的各种方法,包括但不限于代码注入、跟踪和采样。在这三种方法中,采样会带来相对较小的运行时开销,并且需要最少的预先工作,同时仍然可以提供宝贵的应用程序热点洞察。但这种洞察仅限于收集样本时的特定时间点 - 如果我们能为这种采样添加时间维度呢?与其只知道函数 A 在特定时间点消耗了 30% 的 CPU 周期,不如跟踪函数 A 在几天、几周甚至几个月内的 CPU 使用率变化?或者在同一时间段内检测其堆栈跟踪的变化,所有这些都在生产环境中进行?持续性能分析应运而生,将这些想法变成了现实。
什么是持续性能分析?
持续性能分析 (CP) 是一种始终处于开启状态的系统级、基于采样的性能分析器,但采样率较低,以尽量减少运行时影响。通过持续收集所有进程的数据,可以比较代码执行在不同时间段为什么会不同,甚至可以在事件发生后进行调试。CP 工具提供了宝贵的见解,可以了解哪些代码使用了最多的资源,从而使工程师能够减少生产环境中的资源使用,从而节省成本。与 Linux perf 或 Intel VTune 等典型性能分析器不同,CP 可以从应用程序堆栈一直向下定位到内核堆栈,从 任何 指定的日期和时间找到性能问题,并支持比较任意两个日期/时间的调用堆栈,以突出性能差异。
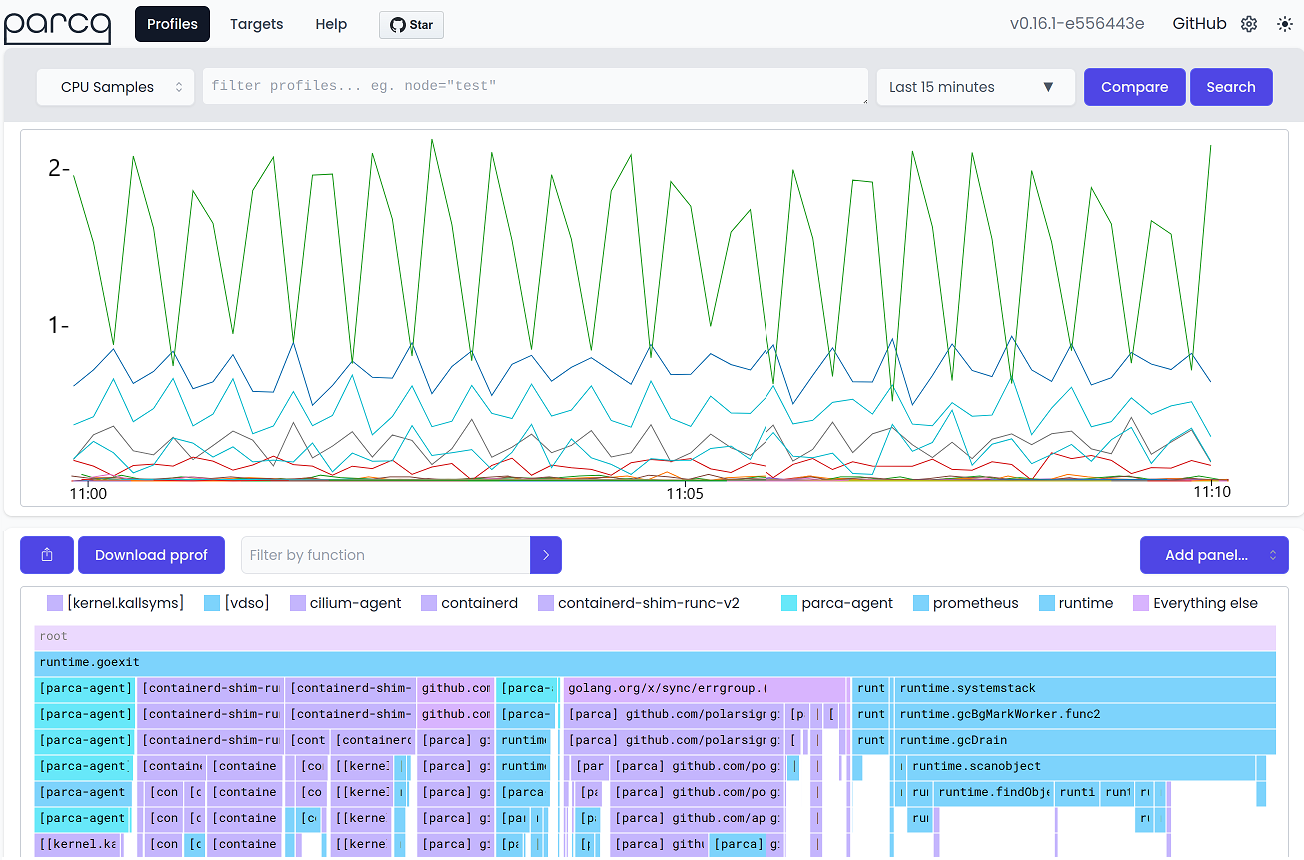
为了展示典型 CP 的外观,让我们来看看开源 CP 之一 Parca: https://github.com/parca-dev/parca1 的 Web 界面,如图 @fig:Continuous_profiling 所示。顶部面板显示了一个时间序列图,其中包含在从时间窗口下拉列表中选择的期间(在本例中为“最近 15 分钟”)机器上各种进程收集的 CPU 样本数量,但是为了适应页面,图片被裁剪为仅显示最后 10 分钟。默认情况下,Parca 每秒收集 19 个样本。对于每个样本,它都会收集主机系统上所有进程的堆栈跟踪。分配给特定进程的样本越多,它在一段时间内的 CPU 活动就越多。在我们的例子中,您可以看到最繁忙的进程(顶部线条)表现出突发性行为,CPU 活动出现峰值和下降。如果您是此应用程序的主要开发人员,您可能会好奇为什么会发生这种情况。当您推出新版本的应用程序,突然看到分配给进程的 CPU 样本出现意外峰值,这表明出现了问题。
持续性能分析工具不仅可以更容易地发现性能变化点,还可以找到问题的根源。一旦您点击图表上的任何感兴趣点,工具就会在底部面板中显示与该周期相关的冰柱图。冰柱图是火焰图的倒置版本。使用它,您可以比较前后调用堆栈,并找到导致性能问题的确切原因。
想象一下,你将代码更改合并到了生产环境中,运行了一段时间后,收到关于间歇性响应时间峰值的报告 - 这些峰值可能与用户流量或一天中的任何特定时间相关,也可能不相关。这就是 CP 闪耀的地方。您可以拉起 CP Web UI 并搜索响应时间峰值日期和时间的堆栈跟踪,然后将它们与其他日期和时间的堆栈跟踪进行比较,以识别应用程序和/或内核堆栈级别的异常执行。这种类型的“视觉差异”直接在 UI 中支持,类似于图形“perf diff”或 差异火焰图: https://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html。
谷歌在 2010 年的论文“Google-Wide Profiling”中介绍了这个概念,倡导了在生产环境中始终启用性能分析的价值。然而,它花了近十年才在业界获得关注:
- 2019 年 3 月,Google Cloud 发布了其持续性能分析器。
- 2020 年 7 月,AWS 发布了 CodeGuru Profiler。
- 2020 年 8 月,Datadog 发布了其持续性能分析器。
- 2020 年 12 月,New Relic 收购了 Pixie 持续性能分析器。
- 2021 年 1 月,Pyroscope 发布了其开源的持续性能分析器。
- 2021 年 10 月,Elastic 收购了 Optimize 及其持续性能分析器 (Prodfiler);Polar Signals 发布了其开源的 Parca 持续性能分析器。
- 2021 年 12 月,Splunk 发布了其 AlwaysOn Profiler。
- 2022 年 3 月,英特尔收购了 Granulate 及其持续性能分析器 (gProfiler)。
该领域的新的参与者继续出现,既有开源版本也有商业版本。其中一些产品比其他产品需要更多的手动操作。例如,有些产品需要对源代码或配置文件进行更改才能开始性能分析。其他产品则针对不同的语言运行时(例如 ruby、python、golang、C/C++/Rust)需要不同的代理。最好的产品围绕 eBPF 制作了秘密武器,因此只需要安装运行时代理就可以了。
它们还支持的语言运行时数量、获取可读堆栈跟踪所需的调试符号的工作量以及除了 CPU 之外可以分析的系统资源类型(例如内存、I/O、锁定等)方面有所不同。虽然持续性能分析器在上述方面存在差异,但它们都具有为各种语言运行时提供低开销、基于采样的性能分析的共同功能,以及用于基于 Web 的搜索和查询功能的远程堆栈跟踪存储。
持续性能分析器将走向何方?Optimyze 公司的联合创始人 Thomas Dullien 开发了创新的持续性能分析器 Prodfiler,他在 QCon London 2023 上发表了主题演讲,表达了他希望拥有一款集群级工具,可以回答“为什么这个请求慢?”或“为什么这个请求昂贵?”等问题。在一个多线程应用程序中,一个特定的函数可能在性能分析中显示为 CPU 和内存消耗最高的函数,但它的职责可能完全不在应用程序关键路径上,例如,一个维护线程。与此同时,另一个函数的 CPU 执行时间非常短,在性能分析中几乎没有记录,但却可能对整体应用程序延迟和/或吞吐量产生过大的影响。典型的性能分析器无法解决这个缺点。由于持续性能分析器基本上是始终运行的性能分析器,它们也继承了同样的盲点。
值得庆幸的是,新一代的持续性能分析器已经出现,它们利用人工智能和 LLM 启发架构来处理性能分析样本,分析函数之间关系,最终高精度地找出直接影响整体吞吐量和延迟的函数和库。Raven.io 就是今天提供这种功能的一家公司。随着该领域的竞争加剧,创新能力将继续增长,使持续性能分析工具变得像典型性能分析器一样强大和稳健。
1. Parca - https://github.com/parca-dev/parca ↩