工作负载特征化
工作负载特征化是通过定量参数和函数描述工作负载的过程。简单来说,它意味着计算某些性能事件的绝对数量。特征化的目标是定义工作负载的行为并提取其最重要的特征。在高层次上,一个应用程序可以属于以下一种或多种类型:交互式、数据库、实时、基于网络的、大规模并行等。不同的工作负载可以使用不同的指标和参数来解决特定的应用程序领域。
这是一本关于低级性能的书,记住了吗?所以,我们将专注于提取与CPU和内存性能相关的特征。从CPU角度看,最好的工作负载特征化示例是顶层微体系结构分析(Top-down Microarchitecture Analysis,TMA)方法,我们将在[@sec:TMA]中仔细研究。TMA试图通过将应用程序放入以下4个桶之一来表征其性能:CPU前端、CPU后端、退役和错误预测,具体取决于造成最多性能问题的原因。TMA使用性能监视计数器(PMCs)收集所需信息,并识别CPU微体系结构的低效使用。
但即使没有完全成熟的特征化方法,收集某些性能事件的绝对数量也可能会有所帮助。我们希望前一章中对四种不同基准测试的性能指标进行的案例研究证明了这一点。PMCs是低级性能分析的非常重要的工具。它们可以提供有关程序执行的独特信息。PMCs通常以两种模式使用:“计数”和“采样”。计数模式用于工作负载特征化,而采样模式用于查找热点,我们将很快讨论。
计数性能事件
计数背后的想法非常简单:我们希望在程序运行时计数某些性能事件的绝对数量。图@fig:Counting。
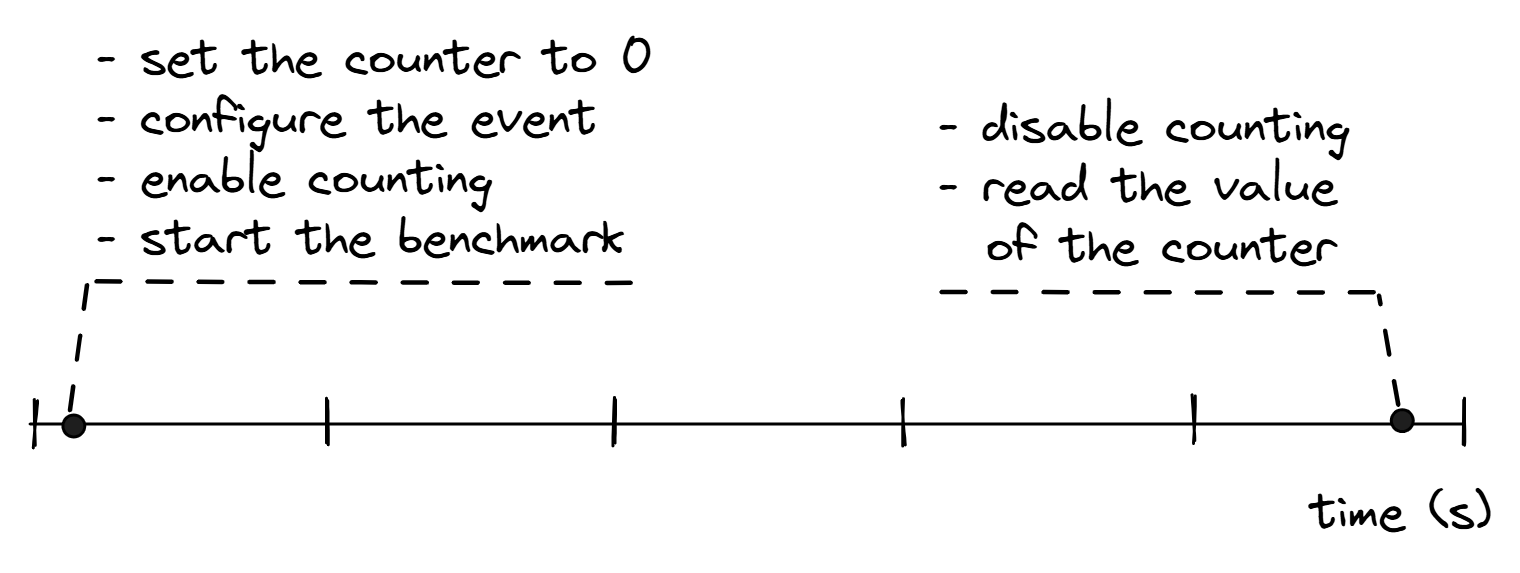
图@fig:Counting。这个过程是在perf stat工具中实现的,它可以用于计数各种硬件事件,比如指令数、周期数、缓存失效等。下面是perf stat的输出示例:
$ perf stat -- ./a.exe
10580290629 cycles # 3,677 GHz
8067576938 instructions # 0,76 insn per cycle
3005772086 branches # 1044,472 M/sec
239298395 branch-misses # 7,96% of all branches
知道这些数据非常有用。首先,它使我们能够快速发现一些异常,比如高的分支误预测率或低的IPC。此外,当您进行了代码更改并希望验证更改是否改进了性能时,它可能会派上用场。查看绝对数值可能有助于您证明或拒绝代码更改。主要作者将perf stat用作简单的基准包装器。由于计数事件的开销很小,几乎所有基准测试都可以自动在perf stat下运行。它作为性能调查的第一步。有时,可以立即发现异常,这可以节省一些分析时间。
手动收集性能计数器数据
现代CPU拥有数百个可计数的性能事件。记住所有这些事件及其含义是非常困难的。更难的是理解何时使用特定的PMC。这就是为什么通常我们不建议手动收集特定的PMCs,除非您真的知道自己在做什么。相反,我们建议使用像Intel Vtune Profiler这样的工具来自动化这个过程。尽管如此,有时候您可能有兴趣收集特定的PMCs。
您可以在[@IntelOptimizationManual,第3B卷,第19章]中找到所有Intel CPU代数的性能事件的完整列表。PMCs的描述也可以在perfmon-events.intel.com上找到。每个事件都使用Event和Umask十六进制值进行编码。有时性能事件还可以使用附加参数进行编码,例如Cmask、Inv等。表[@tbl:perf_count]显示了针对Intel Skylake微体系结构编码的两个性能事件的示例。
| 事件编号 | Umask值 | 事件掩码助记符 | 描述 |
|---|---|---|---|
| C0H | 00H | INST_RETIRED.ANY_P | 退役的指令数量。 |
| C4H | 00H | BR_INST_RETIRED.ALL_BRANCHES | 退役的分支指令。 |
表:Skylake性能事件的编码示例。
Linux perf提供了常用性能计数器的映射。可以通过伪名称而不是指定Event和Umask十六进制值来访问它们。例如,branches只是BR_INST_RETIRED.ALL_BRANCHES的同义词,并且将测量相同的内容。可以使用perf list查看可用映射名称的列表:
$ perf list
branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
但是,Linux perf并不为每个CPU架构的所有性能计数器提供映射。如果您要查找的PMC没有映射,则可以使用以下语法进行收集:
$ perf stat -e cpu/event=0xc4,umask=0x0,name=BR_INST_RETIRED.ALL_BRANCHES/ -- ./a.exe
由于访问PMCs需要root访问权限,因此并非每个环境都可以使用性能计数器。在虚拟化环境中运行的应用程序通常没有root访问权限。对于在公共云中执行的程序,如果虚拟机(VM)管理器未正确向客户端公开PMU编程接口,则在客户端容器中直接运行基于PMU的分析器将不会产生有用的输出。因此,基于CPU性能计数器的分析器在虚拟化和云环境中效果不佳[@PMC_virtual]。尽管情况正在改善。VmWare®是第一个启用4虚拟CPU性能计数器(vPMC)的VM管理器之一。AWS EC2云5为专用主机启用了PMCs。
多路复用和事件缩放
有些情况下,我们希望同时计数许多不同的事件。但是只有一个计数器,一次只能计数一件事情。这就是为什么PMU中有多个计数器的原因(在最近的英特尔Goldencove微体系结构中,每个硬件线程有12个可编程的PMC,每个线程有6个)。即使这样,固定和可编程计数器的数量并不总是足够的。Top-down微体系结构分析(TMA)方法要求在单个程序执行中收集多达100种不同的性能事件。现代CPU没有那么多的计数器,这就是多路复用发挥作用的时候。
如果事件比计数器多,分析工具使用时间多路复用为每个事件提供访问监视硬件的机会。图@fig:Multiplexing1。
8个性能事件之间的多路复用示例,只有4个PMC可用。 </div>
通过多路复用,事件并不是一直被测量的,而只在一段时间内被测量。在运行结束时,性能分析工具需要根据总启用时间对原始计数进行缩放:
让我们以图@fig:Multiplexing2。假设在分析过程中,我们能够在三个时间间隔内测量来自第1组的一个事件。每个测量间隔持续100ms(启用时间)。程序运行时间为500ms(运行时间)。该计数器的总事件数为10'000(原始计数)。因此,最终计数需要按以下方式进行缩放:
这提供了在整个运行过程中测量事件时计数的估计。非常重要的是要理解,这仍然是一个估计值,而不是实际计数。多路复用和缩放可以安全地用于执行长时间间隔内相同代码的稳定工作负载。然而,如果程序经常在不同的热点之间跳转,即有不同的阶段,那么就会产生盲点,这可能会在缩放过程中引入错误。为了避免缩放,可以尝试将事件的数量减少到不超过可用物理PMC的数量。然而,这将需要多次运行基准测试,以测量感兴趣的所有计数器。
4. VMWare PMCs - https://www.vladan.fr/what-are-vmware-virtual-cpu-performance-monitoring-counters-vpmcs/ ↩
5. Amazon EC2 PMCs - http://www.brendangregg.com/blog/2017-05-04/the-pmcs-of-ec2.html ↩