显式内存预取
到现在为止,您应该已经知道未能在缓存中解析的内存访问通常代价高昂。现代 CPU 非常努力地降低预取请求提前足够发出时的缓存未命中惩罚。如果请求的内存位置不在缓存中,我们将无论如何遭受缓存未命中,因为我们必须访问 DRAM 并提取数据。但是,如果我们在程序需要数据时将该内存位置引入缓存,那么我们实际上可以将缓存未命中惩罚降为零。
现代 CPU 有两种解决这个问题的机制:硬件预取和 OOO 执行。硬件预取器通过对重复内存访问模式发起预取请求来帮助隐藏内存访问延迟。而 OOO 引擎则向前看 N 条指令,并提前发出加载指令,以允许平滑执行未来将需要此数据的指令。
当数据访问模式太复杂无法预测时,硬件预取器就会失败。软件开发人员对此无能为力,因为我们无法控制该单元的行为。另一方面,OOO 引擎不像硬件预取器那样试图预测未来需要的内存位置。因此,它成功的唯一衡量标准是它通过提前调度加载隐藏了多少延迟。
考虑 @lst:MemPrefetch1 中的一段代码片段,其中 arr 是一个包含一百万个整数的数组。索引 idx 被赋予一个随机值,然后立即用于访问 arr 中的一个位置,该位置几乎肯定会错过缓存,因为它是随机的。硬件预取器不可能预测,因为每次加载都进入内存中一个完全新的位置。从知道内存位置的地址(从函数 random_distribution 返回)到需要该内存位置的值(调用 doSomeExtensiveComputation)的时间间隔称为 预取窗口。在这个例子中,由于预取窗口非常小,OOO 引擎没有机会提前发出加载指令。这导致内存访问 arr[idx] 的延迟成为执行循环时的关键路径,如图 @fig:SWmemprefetch1 所示。可以看到,程序在没有取得值的情况下等待(阴影填充矩形),无法向前推进。
代码清单:随机数为后续加载提供数据。
for (int i = 0; i < N; ++i) {
size_t idx = random_distribution(generator);
int x = arr[idx]; // cache miss
doSomeExtensiveComputation(x);
}
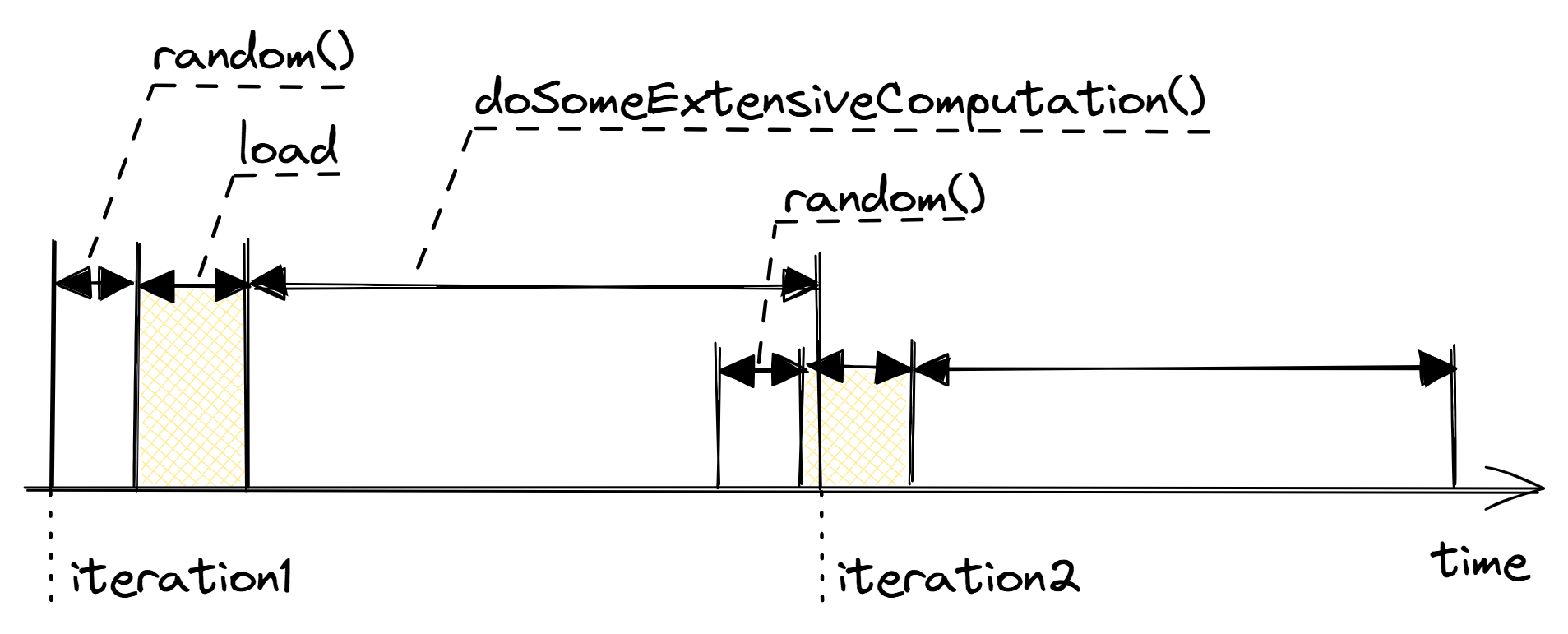
这里还有另一个重要观察。当 CPU 接近完成第一次迭代时,它会推测性地开始执行来自第二次迭代的指令。这在迭代之间创建了一个积极的执行重叠。然而,即使在现代处理器中,也缺少足够的 OOO 功能,无法完全将缓存未命中延迟与来自迭代 1 的 doSomeExtensiveComputation 的执行重叠。换句话说,在我们的例子中,CPU 无法提前查看当前执行,以便足够早地发出加载指令。
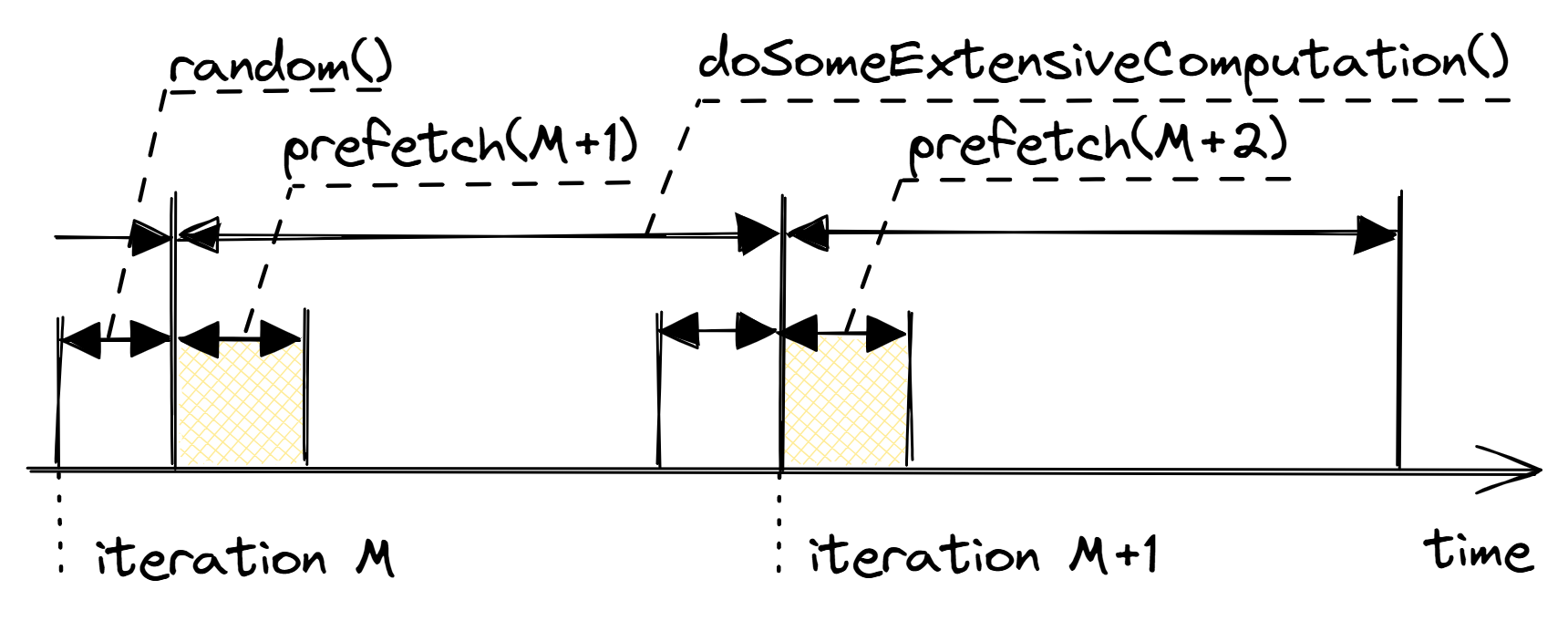
幸运的是,这并不是死路一条,因为有一种方法可以加速这段代码。为了隐藏缓存未命中延迟,我们需要将其与 doSomeExtensiveComputation 的执行重叠。如果我们管道化随机数生成并在下一次迭代中开始预取内存位置,就可以实现这一点,如 @lst:MemPrefetch2 所示。请注意使用 __builtin_prefetch: https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html,4 开发人员可以使用的特殊提示,明确请求 CPU 预取特定内存位置。图 @fig:SWmemprefetch2 展示了这种转换的图形说明。
代码清单:利用明确的软件内存预取提示。
size_t idx = random_distribution(generator);
for (int i = 0; i < N; ++i) {
int x = arr[idx];
idx = random_distribution(generator);
// prefetch the element for the next iteration
__builtin_prefetch(&arr[idx]);
doSomeExtensiveComputation(x);
}
在 x86 平台上利用显式软件预取的另一种选择是使用编译器内部函数 _mm_prefetch。有关更多详细信息,请参见 Intel 内部函数指南。无论如何,编译器都会将其编译成机器指令:x86 的 PREFETCH 和 ARM 的 pld。对于某些平台,编译器可能会跳过插入指令,因此检查生成的机器代码是一个好主意。
存在一些情况下,软件内存预取是不可能的。例如,当遍历链表时,预取窗口非常小,无法隐藏指针追逐的延迟。
在 @lst:MemPrefetch2 中,我们看到了针对下一次迭代进行预取的示例,但您也经常会遇到需要为 2、4、8 甚至更多次迭代进行预取的情况。@lst:MemPrefetch3 中的代码就是这种情况之一,当图非常稀疏并且有很多顶点时,访问 this->out_neighbors 和 this->in_neighbors 向量很可能会错过缓存。
这段代码与前面的例子不同,因为每个迭代中都没有大量计算,所以缓存未命中的惩罚很可能主导了每个迭代的延迟。但是我们可以利用我们知道未来将访问的所有元素这一事实。向量 edges 的元素被顺序访问,因此很可能由硬件预取器及时地引入 L1 缓存。我们在这里的目标是将缓存未命中延迟与执行足够多的迭代重叠,以完全隐藏它。
一般来说,为了让预取提示有效,它们必须提前插入,以便在加载的值用于其他计算时,它已经存在于缓存中。但是,也不应该插入得太早,因为它可能会污染缓存,使数据长时间未使用。请注意,在 @lst:MemPrefetch3 中,lookAhead 是一个模板参数,它允许尝试不同的值并查看哪个值能提供最佳性能。更高级的用户可以尝试使用 [@sec:timed_lbr] 中描述的方法估计预取窗口,在 easyperf 博客上可以找到使用这种方法的例子。5
代码清单:接下来8次迭代的SW预获取示例。
template <int lookAhead = 8>
void Graph::update(const std::vector<Edge>& edges) {
for(int i = 0; i + lookAhead < edges.size(); i++) {
VertexID v = edges[i].from;
VertexID u = edges[i].to;
this->out_neighbors[u].push_back(v);
this->in_neighbors[v].push_back(u);
// prefetch elements for future iterations
VertexID v_next = edges[i + lookAhead].from;
VertexID u_next = edges[i + lookAhead].to;
__builtin_prefetch(this->out_neighbors.data() + v_next);
__builtin_prefetch(this->in_neighbors.data() + u_next);
}
// process the remainder of the vector `edges` ...
}
软件内存预取最常用于循环中,但也可以将这些提示插入到父函数中,这再次取决于可用的预取窗口。
这种技术是一个强大的武器,但应该非常谨慎地使用,因为它并不容易正确使用。首先,显式内存预取不可移植,这意味着如果它在一个平台上带来了性能提升,并不保证在另一个平台上也能获得类似的加速。它非常依赖于实现,并且平台不需要遵守这些提示。在这种情况下,它可能会降低性能。我的建议是使用所有可用工具验证影响是积极的。不仅要检查性能数字,还要确保缓存未命中数量(尤其是 L3)下降。一旦将更改提交到代码库中,请监控您运行应用程序的所有平台上的性能,因为它可能对周围代码的更改非常敏感。如果收益不超过潜在的维护负担,请考虑放弃这个想法。
对于一些复杂的场景,请确保代码实际预取了正确的内存位置。当循环的当前迭代依赖于前一个迭代时,事情可能会变得棘手,例如存在 continue 语句或通过 if 条件改变要处理的下一个元素。在这种情况下,我的建议是使用工具代码来测试预取提示的准确性。因为使用不当,它会通过驱逐其他有用数据来降低缓存的性能。
最后,显式预取会增加代码大小,并增加 CPU 前端压力。预取提示只是一个进入内存子系统的伪加载,但没有目标寄存器。就像任何其他指令一样,它会消耗 CPU 资源。请极其谨慎地应用它,因为使用错误时,它可能会降低程序的性能。
4. GCC内置程序- https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html。 ↩
5:“精确计时的机器代码与Linux perf”- https://easyperf.net/blog/2019/04/03/Precise-timing-of-machine-code-with-Linux-perf#application-estimating-prefetch-window。