专业和混合性能分析器
到目前为止,我们探索的大部分工具都属于采样性能分析器。当你想识别代码中的热点时,它们非常有用,但在某些情况下,它们可能无法提供足够的粒度进行分析。根据性能分析器的采样频率和程序的行为,大多数函数可能足够快,不会出现在性能分析器中。在某些情况下,您可能想要手动定义程序哪些部分需要始终测量。例如,视频游戏渲染帧(显示在屏幕上的最终图像)平均每秒 60 帧 (FPS); 一些显示器允许高达 144 FPS。在 60 FPS 时,每个帧只有不到 16 毫秒的时间完成工作,然后才能继续下一个帧。开发人员特别关注超过此阈值的帧,因为这会导致游戏中出现明显的卡顿,从而破坏玩家体验。这种情况很难用采样性能分析器捕捉,因为它们通常只提供给定函数所花费的总时间。
开发人员创建了性能分析器,这些性能分析器提供特定环境中的一些有用功能,通常带有您可以用于手动为代码插入标记的标记 API。这允许您观察特定函数或代码块(稍后称为 zone)的性能。继续游戏行业,这个领域有一些工具:一些直接集成到游戏引擎中,如 Unreal,而另一些则作为外部库和工具提供,可以集成到您的项目中。一些最常用的性能分析器是 Tracy、RAD Telemetry、Remotery: https://github.com/Celtoys/Remotery 和 Optick: https://github.com/bombomby/optick(仅限 Windows)。接下来,我们展示了 Tracy: https://github.com/wolfpld/tracy,1 因为这似乎是一个更受欢迎的项目,但是这些概念也适用于其他性能分析器。
你可以用 Tracy 做什么:
- 调试程序中的性能异常,例如慢帧。
- 将慢事件与系统中的其他事件关联起来。
- 找到慢事件的共同特征。
- 检查源代码和汇编代码。
- 在代码更改后进行“前后”比较。
你不能用 Tracy 做什么:
- 检查 CPU 微架构问题,例如收集各种性能计数器。
案例研究:使用 Tracy 分析慢帧
在下面的例子中,我们使用了 ToyPathTracer: https://github.com/wolfpld/tracy/tree/master/examples/ToyPathTracer2 程序,这是一个简单的路径追踪器,类似于光线追踪技术,通过向场景中每个像素发射数千条射线来渲染逼真的图像。为了处理一帧,该实现将每个像素行的处理分配给一个单独的线程。
为了模拟 Tracy 可以帮助找到问题根源的典型场景,我们手动修改了代码,使某些帧比其他帧消耗更多时间。@lst:TracyInstrumentation 显示了添加了 Tracy 插桩的代码草图。请注意,我们随机选择帧来减慢速度。此外,我们还包含了 Tracy 的头文件,并向我们想要跟踪的函数添加了 ZoneScoped 和 FrameMark 宏。FrameMark 宏可以插入到性能分析器中标识单个帧。每个帧的持续时间将在时间线上可见,这非常有用。
代码清单:Tracy 插桩
#include "tracy/Tracy.hpp"
void TraceRowJob() {
ZoneScoped;
if (frameCount == randomlySelected)
DoExtraWork();
// ...
}
void RenderFrame() {
ZoneScoped;
for (...) {
TraceRowJob();
}
FrameMark;
}
每个帧可以包含许多区域,由 ZoneScoped 宏指定。与帧类似,一个区域可以有许多实例。每次我们进入一个区域时,Tracy 都会捕获该区域新实例的统计数据。ZoneScoped 宏在堆栈上创建一个对象,该对象将记录对象范围内代码的运行时活动。Tracy 将此范围称为“区域”。在进入区域时,会捕获当前的时间戳。一旦函数退出,对象将记录一个新的 timestamp 并将此时间数据与函数名称一起存储。
Tracy 有两种操作模式:它可以存储所有时间数据,直到分析器连接到应用程序(默认模式),或者它只能在分析器连接时开始记录。后一个选项可以通过在编译应用程序时指定 TRACY_ON_DEMAND 预处理器宏来启用。如果要分发可以根据需要进行分析的应用程序,则应首选此模式。使用此选项,跟踪代码可以编译到应用程序中,并且除非附加了分析器,否则它对正在运行的程序几乎没有开销。分析器是一个单独的应用程序,它连接到正在运行的应用程序以捕获和显示实时分析数据,也称为“飞行记录器”模式。分析器可以在单独的机器上运行,这样它就不会干扰正在运行的应用程序。但是请注意,这并不意味着由插桩代码引起的运行时开销消失了——它仍然存在,但在这种情况下避免了可视化数据的开销。
我们使用 Tracy 调试程序并找出为什么某些帧比其他帧慢的原因。数据是在一台配备 Ryzen 7 5800X 处理器的 Windows 11 机器上捕获的。该程序是用 MSVC 19.36.32532 编译的。Tracy 图形界面非常丰富,不幸的是太难容纳在一张屏幕截图中,所以我们将其分解。在顶部,有一个时间线视图,如图 @fig:Tracy_Main_View 所示,已裁剪以适合页面。它仅显示第 76 帧的一部分,渲染该帧需要 44.1 毫秒。在该图上,我们看到了在该帧期间处于活动状态的 Main thread 和五个 WorkerThread。所有线程,包括主线程,都在执行工作以推进最终图像的渲染进度。正如我们之前所说,每个线程在 TraceRowJob 区域内处理一行像素。每个 TraceRowJob 区域实例包含许多较小的区域,这些区域不可见。Tracy 会折叠内部区域并仅显示折叠实例的数量——例如,主线程中第一个 TraceRowJob 下方的数字“4,109”表示的意思。请注意,DoExtraWork 区域的实例嵌套在 TraceRowJob 区域下。这种观察已经可以导致发现,但在实际应用中可能并不那么明显。现在让我们先放下这个。

在主面板的正上方,有一个直方图显示所有记录的帧的时间,请参见图 @fig:Tracy_Frame_Time_View。它可以更容易地发现可能导致卡顿的长时间运行的帧。它可以更容易地发现那些比平均时间更长才能完成的帧。在此示例中,大多数帧大约需要 33 毫秒(黄色条)。但是也有一些帧需要更长的时间,并用红色标记。如屏幕截图所示,将鼠标悬停在直方图中的条形图上时,会显示一个工具提示,显示给定帧的详细信息。在此示例中,我们显示了最后一个帧的详细信息,以绿色突出显示。

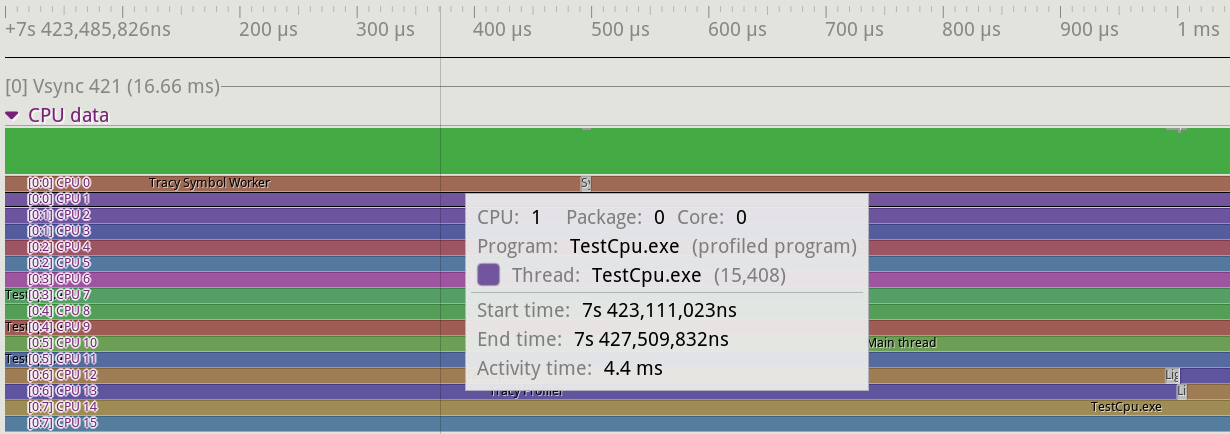
Figure @fig:Tracy_CPU_Data 展示了分析器的 CPU 数据部分。该区域显示给定线程正在哪个内核上执行,它还显示上下文切换。此部分还将显示其他正在 CPU 上运行的程序。如图像所示,将鼠标悬停在 CPU 数据视图中的给定部分上时,会显示给定线程的详细信息。详细信息包括线程运行所在的 CPU、父程序、单个线程和计时信息。我们可以看到 TestCpu.exe 线程在 CPU 1 上活动了 4.4 毫秒。
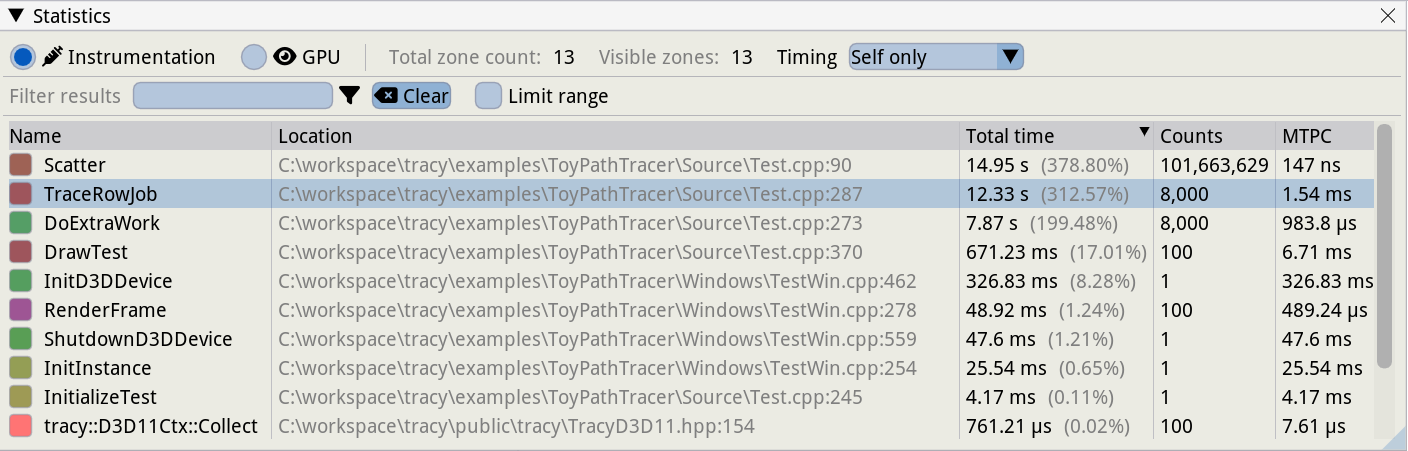
接下来是一个面板,提供有关程序花费时间的位置的信息,也称为热点。图 @fig:Tracy_Hotspots 捕获了 Tracy 统计窗口的屏幕截图。我们可以检查记录的数据,包括给定函数处于活动状态的总时间、它被调用的次数等。还可以选择主视图中的时间范围,仅过滤与该时间间隔相对应的信息。
我们展示的最后一组面板允许我们更深入地分析单个区域实例。一旦您单击任何区域实例,例如,在主时间线视图或 CPU 数据视图上,Tracy 将打开一个区域信息窗口(参见图 @fig:Tracy_Zone_Details,左侧面板),其中包含此区域实例的详细信息。它告诉了区域本身或其子区域消耗了多少执行时间。在此示例中,TraceRowJob 函数的执行耗时 19.24 毫秒,但函数本身消耗的时间不包括其被调用者,仅为 1.36 毫秒,仅占 7%。其余时间由子区域占用。
很容易发现调用 DoExtraWork 占据了大部分时间,16.99 毫秒中的 19.24 毫秒。请注意,这个特定的 TraceRowJob 实例运行时间比平均情况长 4.4 倍(图像上找到“平均时间的 437.93%”)。Bingo! 我们发现了一个慢实例,其中 TraceRowJob 函数由于一些额外工作而变慢。一种方法是单击 DoExtraWork 行以检查此区域实例。这将使用 DoExtraWork 实例的详细信息更新区域信息视图,以便我们可以深入了解导致性能问题的原因。此视图还显示了区域启动的源文件和代码行。因此,另一个策略是检查源代码以了解为什么当前的 TraceRowJob 实例比平时花费更多时间。
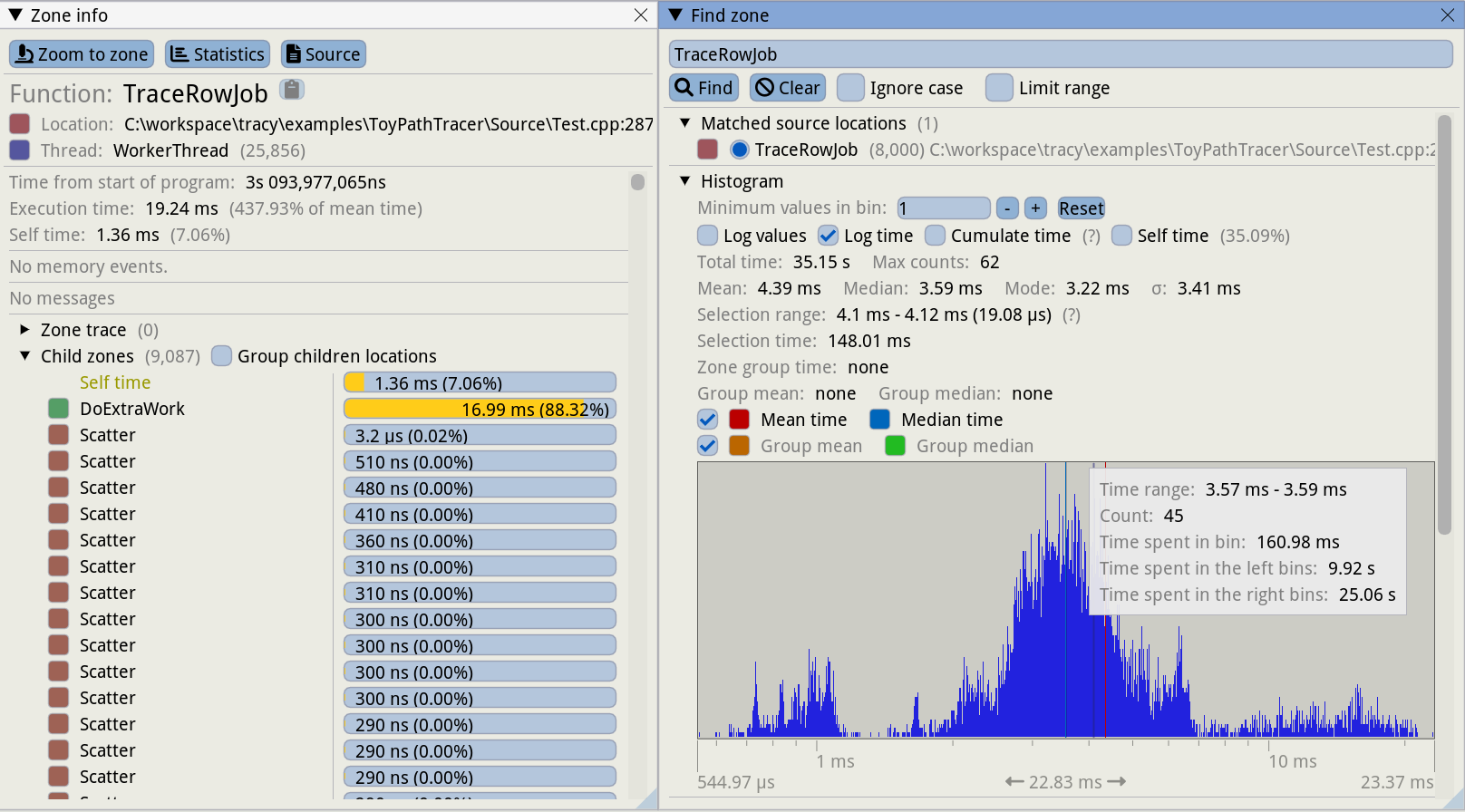
记得我们在图 @fig:Tracy_Frame_Time_View 上看到,还有其他慢帧。让我们看看这是否是所有慢帧的常见问题。如果我们点击“统计”按钮,它将显示“查找区域”面板(图 @fig:Tracy_Zone_Details,右侧)。在这里,我们可以看到聚合所有区域实例的时间直方图。这对于确定执行函数时有多少差异特别有用。查看右侧的直方图,我们看到 TraceRowJob 函数的中位数持续时间为 3.59 毫秒,大多数调用花费 1 到 7 毫秒之间。但是,有一些实例花费的时间超过 10 毫秒,峰值为 23 毫秒。请注意,时间轴是对数的。“查找区域”窗口还提供其他数据点,包括所检查区域的平均值、中位数和标准差。
现在我们可以检查其他慢实例,找到它们之间的共同点,这将帮助我们找到问题的根源。从这个视图中,您可以选择一个慢区域。这将使用该区域实例的详细信息更新区域信息窗口 (2),然后单击“缩放到区域”按钮,主窗口将聚焦于此慢区域。从这里我们可以检查选定的 TraceRowJob 实例是否具有与我们刚刚分析的实例类似的特征。
Tracy 的其他功能
Tracy 不仅监控应用程序本身,还监控整个系统的性能。它还像传统采样分析器一样,报告与分析程序同时运行的应用程序的数据。该工具通过跟踪内核上下文切换(需要管理员权限)来监控线程迁移和空闲时间。区域统计数据(调用次数、时间、直方图)是准确的,因为 Tracy 会捕获每个区域的进入/退出,但系统级数据和源代码级数据是采样的。
在本节的示例中,我们使用了手动标记代码中感兴趣的区域。但这并不是开始使用 Tracy 的严格要求。您可以分析未修改的应用程序,稍后在需要时添加检测工具。Tracy 还提供许多其他功能,本文档无法全部涵盖。以下是一些值得注意的功能:
- 跟踪内存分配和锁。
- 会话比较。这对于确保更改提供了预期的益处至关重要。可以加载两个分析会话并比较更改前后区域数据。
- 源代码和汇编视图。如果可以使用调试符号,Tracy 还可以像 Intel Vtune 和其他分析器一样在源代码和相关汇编中显示热点。
与 Intel Vtune 和 AMD uProf 等其他工具相比,Tracy 无法获得相同级别的 CPU 微架构洞察力(例如,各种性能事件)。这是因为 Tracy 不利用特定于特定平台的硬件功能。
使用 Tracy 进行分析的开销取决于您激活的区域数量。Tracy 的作者提供了一些他在图像压缩程序上测量的数据点:使用两种不同的压缩方案,开销分别为 18% 和 34%。总共分析了 2 亿个区域,每个区域的平均开销为 2.25 纳秒。该测试检测了一个非常热的功能。在其他情况下,开销会低得多。虽然可以将开销保持在较低水平,但您需要谨慎选择要检测的代码部分,尤其是在决定将其用于生产环境时。
1. Tracy - https://github.com/wolfpld/tracy ↩
2. ToyPathTracer - https://github.com/wolfpld/tracy/tree/master/examples/ToyPathTracer ↩