采样
采样是最常用的性能分析方法。人们通常将其与程序中的热点识别联系起来。广义而言之,采样有助于找到代码中对特定性能事件贡献最多的位置。如果我们考虑发现热点,那么这个问题可以重新表述为程序中的哪个地方消耗了最多的 CPU 周期。人们通常将技术上称为采样的操作称为“性能分析”。根据维基百科https://en.wikipedia.org/wiki/Profiling_(computer_programming)1的说法,性能分析是一个更广泛的术语,包括各种收集数据的技术,例如中断、代码检测和 PMC。
令人惊讶的是,人们可以想象到的最简单的采样性能分析器就是调试器。事实上,您可以通过以下步骤识别热点:a) 在调试器下运行程序,b) 每 10 秒暂停一次程序,c) 记录程序停止的位置。如果您多次重复 b) 和 c),您就可以从这些样本构建一个直方图。您停止最多的代码行将是程序中最热的代码行。当然,这不是一种高效的发现热点的方法,我们也不推荐这样做。它只是为了说明这个概念。尽管如此,它是关于真实性能分析工具如何工作的简化描述。现代性能分析器每秒可以收集数千个样本,这为基准测试中的热点提供了相当准确的估计。
与调试器的例子一样,每次捕获新的样本时,被分析程序的执行都会中断。在中断时,性能分析器会收集程序状态的快照,构成一个样本。为每个样本收集的信息可能包括中断时执行的指令地址、寄存器状态、调用堆栈(见 [@sec:secCollectCallStacks]),等等。收集到的样本存储在一个转储文件中,该文件可以进一步用于显示程序中耗时最多的部分、调用图等。
用户模式和基于硬件事件的采样
采样可以采用两种不同的模式进行,即用户模式采样或基于硬件事件的采样 (EBS)。用户模式采样是一种纯软件方法,将代理库嵌入到被分析的应用程序中。代理为应用程序中的每个线程设置操作系统计时器。计时器到期后,应用程序会收到由收集器处理的 SIGPROF 信号。EBS 使用硬件 PMC 触发中断。特别是,它使用 PMU 的计数器溢出功能,我们将在稍后讨论。
用户模式采样只能用于识别热点,而 EBS 可用于涉及 PMC 的其他分析类型,例如,基于缓存未命中、TMA(见 [@sec:TMA])等进行采样。
与 EBS 相比,用户模式采样的运行时开销更大。当采样间隔为 10ms 时,用户模式采样的平均开销约为 5%,而 EBS 的开销不到 1%。由于开销更低,您可以使用更高的采样率使用 EBS,这将提供更准确的数据。然而,用户模式采样生成的数据更少,因此处理起来也更快。
寻找热点
在本节中,我们将讨论使用 PMC 和 EBS 的机制。图 @fig:Sampling 说明了 PMU 的计数器溢出功能,该功能用于触发性能监控中断 (PMI),也称为 SIGPROF。在基准测试开始时,我们会配置我们想要采样的事件。识别热点意味着知道程序花费大部分时间在哪里。因此,在周期上进行采样是非常自然的,这也是许多性能分析工具的默认设置。但这并不一定是严格的规则;我们可以对任何想要的性能事件进行采样。例如,如果我们想知道程序中 L3 缓存未命中最多的位置,我们将在相应的事件上进行采样,即 MEM_LOAD_RETIRED.L3_MISS。
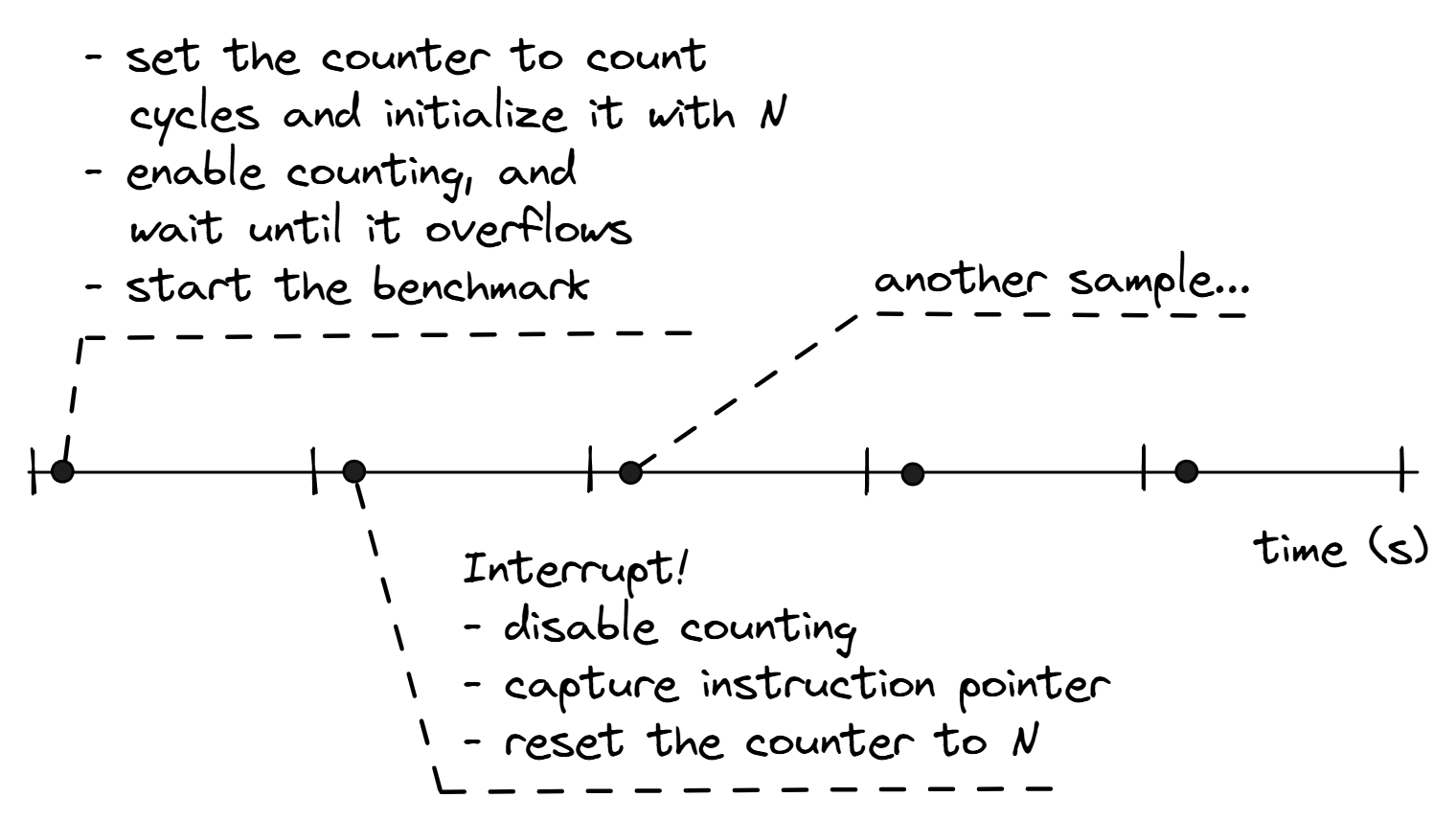
初始化寄存器后,我们开始计数并让基准测试继续。我们将 PMC 配置为计数周期,因此它将在每个周期递增。最终,它会溢出。当寄存器溢出时,硬件将引发 PMI。性能分析工具被配置为捕获 PMI,并具有用于处理它们的中断服务程序 (ISR)。我们在 ISR 中执行多个步骤:首先,我们禁用计数;然后,我们记录 CPU 在计数器溢出时执行的指令;然后,我们将计数器重置为 N 并恢复基准测试。
现在,让我们回到值 N。使用这个值,我们可以控制我们想要多久获得一个新的中断。假设我们想要更细粒度的粒度,每 100 万条指令获得一个样本。为了实现这一点,我们可以将计数器设置为 (unsigned) -1'000'000,这样它将在每 100 万条指令后溢出。这个值也称为“采样后”值。
我们重复这个过程多次,以建立足够的样本集合。如果我们稍后聚合这些样本,就可以构建程序中最热位置的直方图,就像下面 Linux perf record/report 输出所示。这给了我们按降序排序的程序函数开销的细分(热点)。下面展示了一个来自 Phoronix 测试套件: https://www.phoronix-test-suite.com/8 的 x264: https://openbenchmarking.org/test/pts/x2647 基准测试的采样示例:
$ time -p perf record -F 1000 -- ./x264 -o /dev/null --slow --threads 1 ../Bosphorus_1920x1080_120fps_420_8bit_YUV.y4m
[ perf record: Captured and wrote 1.625 MB perf.data (35035 samples) ]
real 36.20 sec
$ perf report -n --stdio
# Samples: 35K of event 'cpu_core/cycles/'
# Event count (approx.): 156756064947
# Overhead Samples Shared Object Symbol
# ........ ....... ............. ........................................
7.50% 2620 x264 [.] x264_8_me_search_ref
7.38% 2577 x264 [.] refine_subpel.lto_priv.0
6.51% 2281 x264 [.] x264_8_pixel_satd_8x8_internal_avx2
6.29% 2212 x264 [.] get_ref_avx2.lto_priv.0
5.07% 1787 x264 [.] x264_8_pixel_avg2_w16_sse2
3.26% 1145 x264 [.] x264_8_mc_chroma_avx2
2.88% 1013 x264 [.] x264_8_pixel_satd_16x8_internal_avx2
2.87% 1006 x264 [.] x264_8_pixel_avg2_w8_mmx2
2.58% 904 x264 [.] x264_8_pixel_satd_8x8_avx2
2.51% 882 x264 [.] x264_8_pixel_sad_16x16_sse2
...
Linux perf 采集了 35'035 个样本,这意味着中断执行的过程发生了这么多次。我们还使用了 -F 1000,将采样率设置为每秒 1000 个样本。这大致与 36.2 秒的整体运行时间相匹配。请注意,Linux perf 提供了大约经过的总周期数。如果我们将它除以样本数,我们将得到 156756064947 个周期 / 35035 个样本 = 450 万 个周期/样本。这意味着 Linux perf 将数字 N 设置为大约 4'500'000 以每秒收集 1000 个样本。数字 N 可以由工具根据实际 CPU 频率动态调整。
当然,对我们最有价值的是按每个函数分配的样本数量排序的热点列表。在知道最热门的函数之后,我们可能想要更深入地研究:每个函数内部代码的热门部分是什么。要查看内联函数的配置文件数据以及为特定源代码区域生成的汇编代码,我们需要使用调试信息(-g 编译器标志)构建应用程序。
调试信息有两个主要用例:调试功能问题(错误)和性能分析。对于功能调试,我们需要尽可能多的信息,这是您传递 -g 编译器标志时的默认设置。但是,如果用户不需要完整的调试体验,那么只需要行号就足以进行性能分析。您可以通过使用 -gline-tables-only 选项将生成的调试信息量减少到代码中符号的行号。4
Linux perf 没有丰富的图形支持,因此查看源代码的热门部分非常不方便,但可以做到。Linux perf 将源代码与生成的汇编代码混合在一起,如下所示:
# snippet of annotating source code of 'x264_8_me_search_ref' function
$ perf annotate x264_8_me_search_ref --stdio
Percent | Source code & Disassembly of x264 for cycles:ppp
----------------------------------------------------------
...
: bmx += square1[bcost&15][0]; <== source code
1.43 : 4eb10d: movsx ecx,BYTE PTR [r8+rdx*2] <== corresponding machine code
: bmy += square1[bcost&15][1];
0.36 : 4eb112: movsx r12d,BYTE PTR [r8+rdx*2+0x1]
: bmx += square1[bcost&15][0];
0.63 : 4eb118: add DWORD PTR [rsp+0x38],ecx
: bmy += square1[bcost&15][1];
...
大多数带有图形用户界面 (GUI) 的性能分析器,例如 Intel VTune Profiler,都可以并排显示源代码和关联的汇编代码。此外,还有一些工具可以以类似于 Intel Vtune 和其他工具的丰富图形界面可视化 Linux perf 原始数据的输出。您将在第 7 章中更详细地看到所有这些内容。
收集调用堆栈
在采样时,我们经常会遇到程序中最热门的函数被多个函数调用的情况。图 @fig:CallStacks 显示了一个这样的场景示例。性能分析工具的输出可能显示 foo 是程序中最热门的函数之一,但如果它有多个调用者,我们想知道哪个调用者调用 foo 的次数最多。对于程序中出现诸如 memcpy 或 sqrt 之类的库函数的热点,这是典型情况。要了解特定的函数为什么成为热点,我们需要知道程序控制流图 (CFG) 中哪个路径导致了这种情况。
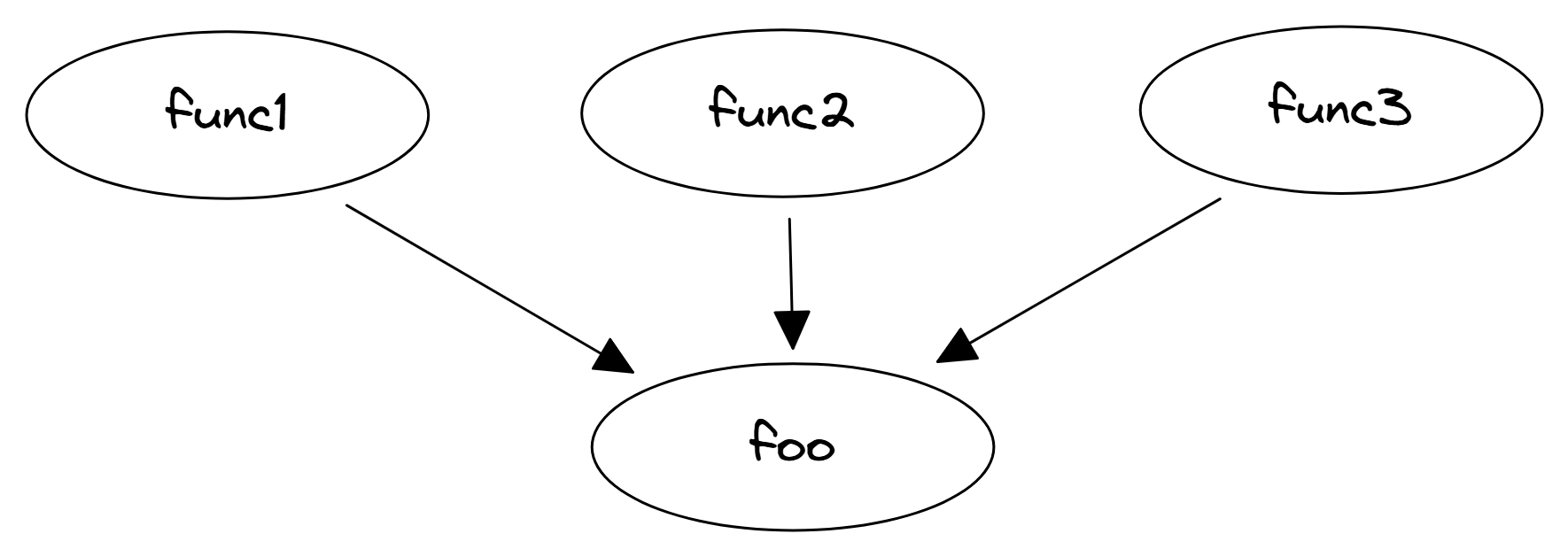
分析 foo 所有调用者的源代码可能非常耗时。我们只想关注那些导致 foo 成为热点的调用者。换句话说,我们想要找出程序 CFG 中最热门的路径。性能分析工具通过在收集性能样本时捕获进程的调用堆栈和其他信息来实现这一点。然后,对所有收集到的堆栈进行分组,使我们能够看到导致特定函数的最热门路径。
在 Linux perf 中,可以使用三种方法收集调用堆栈:
- 帧指针(
perf record --call-graph fp)。要求使用--fnoomit-frame-pointer构建二进制文件。历史上,帧指针(RBP 寄存器)用于调试,因为它使我们能够在不弹出所有参数的情况下获取调用堆栈(也称为堆栈展开)。帧指针可以立即告诉返回地址。但是,它仅为此目的占用了一个寄存器,所以开销很大。它也可用用于性能分析,因为它可以进行廉价的堆栈展开。 - DWARF 调试信息(
perf record --call-graph dwarf)。要求使用 DWARF 调试信息-g(-gline-tables-only)构建二进制文件。通过堆栈展开过程获取调用堆栈。 - 英特尔最后分支记录 (LBR) 硬件功能(
perf record --call-graph lbr)。通过解析 LBR 堆栈(一组硬件寄存器)获取调用堆栈。调用图不像前两种方法那么深。有关 LBR 的更多信息,请参见 [@sec:lbr]。
下面是使用 LBR 在程序中收集调用堆栈的示例。通过查看输出,我们知道 55% 的时间 foo 是由 func1 调用的,33% 的时间是由 func2 调用的,11% 的时间是由 fun3 调用的。我们可以清楚地看到 foo 的调用者之间的开销分布,现在可以将注意力集中在程序 CFG 中最热的边 func1 -> foo 上,但我们也应该关注边 func2 -> foo。
$ perf record --call-graph lbr -- ./a.out
$ perf report -n --stdio --no-children
# Samples: 65K of event 'cycles:ppp'
# Event count (approx.): 61363317007
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................ ......................
99.96% 65217 a.out a.out [.] foo
|
--99.96%--foo
|
|--55.52%--func1
| main
| __libc_start_main
| _start
|
|--33.32%--func2
| main
| __libc_start_main
| _start
|
--11.12%--func3
main
__libc_start_main
_start
当使用 Intel VTune Profiler 时,可以在配置分析时勾选相应的“收集堆栈”框来收集调用堆栈数据。当使用命令行界面时,指定 -knob enable-stack-collection=true 选项。
知道一种有效的收集调用堆栈的方法非常重要。不熟悉该概念的开发人员会尝试使用调试器来获取此信息。他们通过中断程序的执行并分析调用堆栈(例如,gdb 调试器中的 backtrace 命令)来做到这一点。不要这样做,让性能分析工具来完成这项工作,它更快、更准确。
1. Profiling(wikipedia) - https://en.wikipedia.org/wiki/Profiling_(computer_programming). ↩
4. 过去,使用调试信息 (-g) 编译时存在 LLVM 编译器错误。代码转换传递错误地处理了调试内部函数的存在,导致了不同的优化决策。它不会影响功能,只会影响性能。其中一些已经修复,但很难说是否存在其他问题。 ↩
7. x264 benchmark - https://openbenchmarking.org/test/pts/x264. ↩
8. Phoronix test suite - https://www.phoronix-test-suite.com/. ↩