内存延迟和带宽
在现代环境中,低效的内存访问通常是主要的性能瓶颈。因此,处理器从内存子系统中获取单个字节的速度(延迟)以及每秒可以获取多少字节(带宽)是决定应用程序性能的关键因素之一。这两个方面在各种场景中都很重要,我们稍后将看到一些示例。在本节中,我们将专注于测量内存子系统组件的峰值性能。
在x86平台上,可以成为有用工具之一的是英特尔内存延迟检查器(MLC),1它在Windows和Linux上都可以免费使用。MLC可以使用不同的访问模式和负载来测量缓存和内存的延迟和带宽。在基于ARM的系统上没有类似的工具,但是用户可以从源代码中下载并构建内存延迟和带宽基准测试。这类项目的示例包括lmbench2,bandwidth4和Stream。3
我们只关注一个子集指标,即空闲读取延迟和读取带宽。让我们从读取延迟开始。空闲表示在进行测量时,系统处于空闲状态。这将为我们提供从内存系统组件获取数据所需的最小时间,但是当系统被其他“内存消耗量大”的应用程序加载时,此延迟会增加,因为在各个点上可能会有更多的资源排队。MLC通过进行相关加载(也称为指针追踪)来测量空闲延迟。一个测量线程分配一个非常大的缓冲区,并对其进行初始化,以便缓冲区内的每个(64字节)缓存行包含指向该缓冲区内另一个非相邻缓存行的指针。通过适当调整缓冲区的大小,我们可以确保几乎所有的加载都命中某个级别的缓存或主存。
我们的测试系统是一台英特尔Alderlake主机,配备Core i7-1260P CPU和16GB DDR4 @ 2400 MT/s双通道内存。该处理器有4个P(性能)超线程核心和8个E(高效)核心。每个P核心有48KB的L1数据缓存和1.25MB的L2缓存。每个E核心有32KB的L1数据缓存,而四个E核心组成一个集群,可以访问共享的2MB L2缓存。系统中的所有核心都由18MB的L3缓存支持。如果我们使用一个10MB的缓冲区,我们可以确保对该缓冲区的重复访问会在L2中未命中,但在L3中命中。以下是示例 mlc 命令:
$ ./mlc --idle_latency -c0 -L -b10m
Intel(R) Memory Latency Checker - v3.10
Command line parameters: --idle_latency -c0 -L -b10m
Using buffer size of 10.000MiB
*** Unable to modify prefetchers (try executing 'modprobe msr')
*** So, enabling random access for latency measurements
Each iteration took 31.1 base frequency clocks ( 12.5 ns)
选项 --idle_latency 测量读取延迟而不加载系统。MLC具有 --loaded_latency 选项,用于在由其他线程生成的内存流量存在时测量延迟。选项 -c0 将测量线程固定在逻辑CPU 0上,该CPU位于P核心上。选项 -L 启用大页以限制我们的测量中的TLB效应。选项 -b10m 告诉MLC使用10MB缓冲区,在我们的系统上可以放在L3缓存中。
图 @fig:MemoryLatenciesCharts 显示了L1、L2和L3缓存的读取延迟。图中有四个不同的区域。从1KB到48KB缓冲区大小
的左侧的第一个区域对应于L1d缓存,该缓存是每个物理核心私有的。我们可以观察到E核心的延迟为0.9ns,而P核心稍高为1.1ns。此外,我们可以使用此图来确认缓存大小。请注意,当缓冲区大小超过32KB时,E核心的延迟开始上升,但是在48KB之前E核心的延迟保持不变。这证实了E核心的L1d缓存大小为32KB,而P核心的L1d缓存大小为48KB。
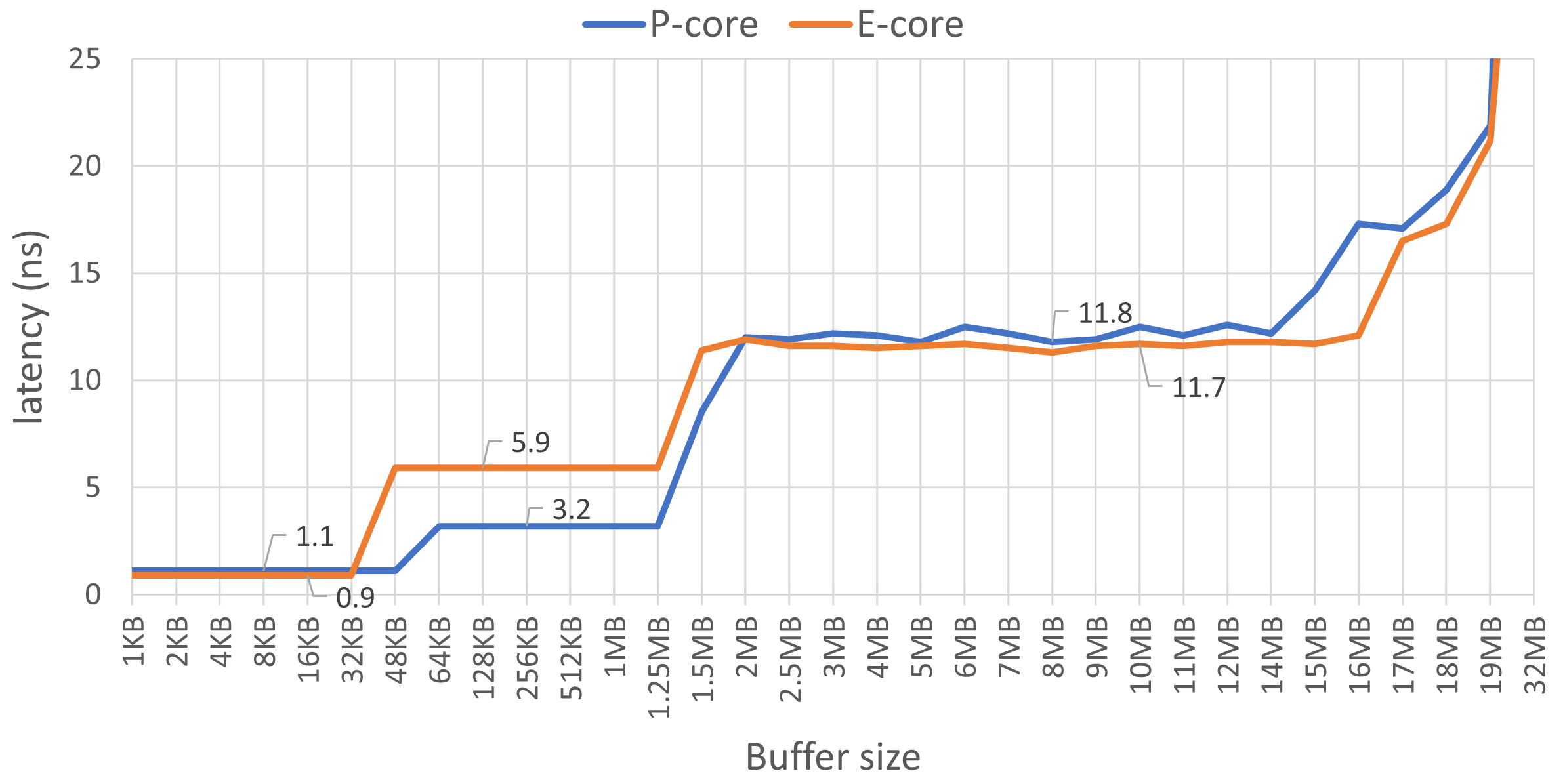
第二个区域显示 L2 缓存延迟,E 核的延迟几乎是 P 核的两倍(5.9ns vs. 3.2ns)。对于 P 核,延迟在我们超过 1.25MB 缓冲区大小后会增加,这是预期的。但我们期望 E 核的延迟保持不变,直到 2MB,但在我们的测量中没有发生这种情况。
第三个区域从 2MB 到 14MB 对应于 L3 缓存延迟,对于两种类型的内核都大约为 12ns。系统中所有内核共享的 L3 缓存的总大小为 18MB。有趣的是,我们从 15MB 开始看到一些意想不到的动态,而不是 18MB。这很可能是因为一些访问错过了 L3,需要去主内存。
第四个区域对应于内存延迟,图表上只显示了其开始部分。当我们越过18MB的边界时,延迟会急剧上升,并在E核心的24MB和P核心的64MB处开始趋于稳定。使用更大的缓冲区大小为500MB时,E核心的访问延迟为45ns,P核心为90ns。这测量了内存延迟,因为几乎没有加载会命中L3缓存。
使用类似的技术,我们可以测量内存层次结构的各个组件的带宽。为了测量带宽,MLC执行的加载请求不会被任何后续指令使用。这允许MLC生成可能的最大带宽。MLC在每个配置的逻辑处理器上生成一个软件线程。每个线程访问的地址是独立的,线程之间没有数据共享。与延迟实验一样,线程使用的缓冲区大小确定了MLC是在测量L1/L2/L3缓存带宽还是内存带宽。
./mlc --max_bandwidth -k0-15 -Y -L -b10m
Measuring Maximum Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 33691.53
3:1 Reads-Writes : 30352.45
2:1 Reads-Writes : 29722.28
1:1 Reads-Writes : 28382.45
Stream-triad like: 30503.68
这里的新选项是 -k,它指定了用于测量的CPU编号列表。-Y 选项告诉MLC使用AVX2加载,即每次加载32字节。MLC使用不同的读写比例来测量带宽,但在下图中,我们只显示了全部读取带宽,因为它可以让我们对内存带宽的峰值有一个直观的了解。但其他比例也可能很重要。我们在使用Intel MLC测量的系统的组合延迟和带宽数字如图 @fig:MemBandwidthAndLatenciesDiagram 所示。
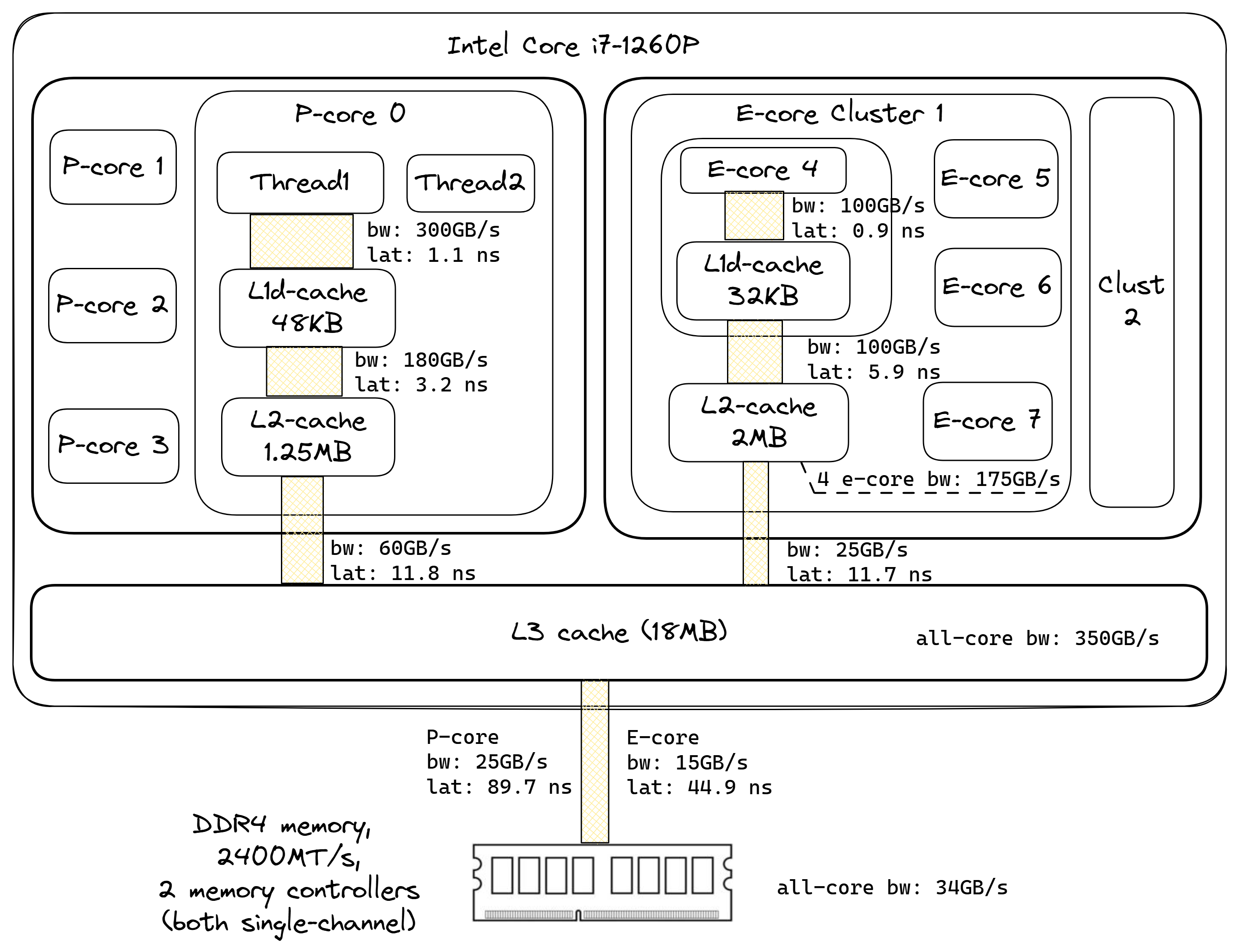
核心可以从较低级别的缓存(如L1和L2)中获得比从共享的L3缓存或主内存中更高的带宽。共享缓存(如L3和E核心L2)相当好地扩展,可以同时为多个核心提供请求。例如,单个E核心L2的带宽为100GB/s。使用来自同一集群的两个E核心,我测量了140GB/s,三个E核心为165GB/s,而所有四个E核心可以从共享L2中获得175GB/s。对于L3缓存也是如此,单个P核心的带宽为60GB/s,而单个E核心只有25GB/s。但是当所有核心都被使用时,L3缓存可以维持300GB/s的带宽。
请注意,我们用纳秒测量延迟,用GB/s测量带宽,因此它们还取决于核心运行的频率。在各种情况下,观察到的数字可能不同。例如,假设当仅在系统上以最大睿频运行时,P核心的L1延迟为 X ,L1带宽为 Y 。当系统负载满时,我们可能观察到这些指标分别变为 1.25X 和 0.75Y。为了减轻频率效应,与其使用纳秒,延迟和度量可以使用核心周期来表示,并归一化为一些样本频率,比如3Ghz。
了解计算机的主要特征是评估程序如何利用可用资源的基本方法。当我们讨论Roofline性能模型时,我们将在[@sec:roofline]返回到这个主题。如果您经常在单个平台上分析性能,最好记住内存层次结构的各个组件的延迟和带宽,或者将它们随时备查。这有助于建立对测试系统的心理模型,将有助于您进一步的性能分析,正如您将在接下来看到的那样。
1. Intel MLC工具 - https://www.intel.com/content/www/us/en/download/736633/intel-memory-latency-checker-intel-mlc.html ↩
2. lmbench - https://sourceforge.net/projects/lmbench ↩
3. Stream - https://github.com/jeffhammond/STREAM ↩
4. Zack Smith的内存带宽基准测试 - https://zsmith.co/bandwidth.php ↩