Intel Vtune
VTune Profiler(之前称为VTune Amplifier)是一款适用于基于x86架构的机器的性能分析工具,具有丰富的图形用户界面。它可以在Linux或Windows操作系统上运行。我们跳过了关于 VTune 对 MacOS 的支持的讨论,因为它不适用于苹果芯片(例如,M1 和 M2),而且基于英特尔的 MacBook 很快就会过时。
Vtune 可以在英特尔和 AMD 系统上使用,许多功能都可以工作。但是,高级基于硬件的采样需要英特尔制造的 CPU。例如,在 AMD 系统上,你将无法使用 Intel Vtune 收集硬件性能计数器。
截至 2023 年初,VTune 作为一个独立工具或作为英特尔 oneAPI 基础工具包的一部分免费提供。
如何配置
在 Linux 上,Vtune 可以使用两个数据收集器:Linux perf 和 Vtune 自己的驱动程序,称为 SEP。第一种类型用于用户模式采样,但如果你想进行高级分析,你需要构建并安装 SEP 驱动程序,这并不太难。
# 进入 vtune 安装的 sepdk 文件夹
$ cd ~/intel/oneapi/vtune/latest/sepdk/src
# 构建驱动程序
$ ./build-driver
# 添加 vtune 组并将你的用户添加到该组
# 创建一个新的 shell,或者重新启动系统
$ sudo groupadd vtune
$ sudo usermod -a -G vtune `whoami`
# 安装 sep 驱动程序
$ sudo ./insmod-sep -r -g vtune
完成上述步骤后,你应该能够使用像微架构探索和内存访问之类的高级分析类型。
在 Windows 上,在安装 Vtune 后不需要进行任何额外的配置。收集硬件性能事件需要管理员权限。
它能做什么
- 找到热点:函数、循环、语句。
- 监控各种特定于 CPU 的性能事件,例如分支误判和 L3 缓存未命中。
- 定位这些事件发生的代码行。
- 使用 TMA 方法论对 CPU 性能瓶颈进行特征化。
- 为特定函数、进程、时间段或逻辑核心过滤数据。
- 随时间观察工作负载行为(包括 CPU 频率、内存带宽利用率等)。
VTune 可以提供关于运行中进程的非常丰富的信息。如果你想要提高应用程序的整体性能,这是一个合适的工具。Vtune 总是提供一段时间内的聚合数据,因此它可用于找到“平均情况”下的优化机会。
它不能做什么
- 分析非常短的执行异常。
- 观察系统范围的复杂软件动态。
由于该工具的采样性质,它最终会错过持续时间非常短的事件(例如,亚微秒级)。
示例
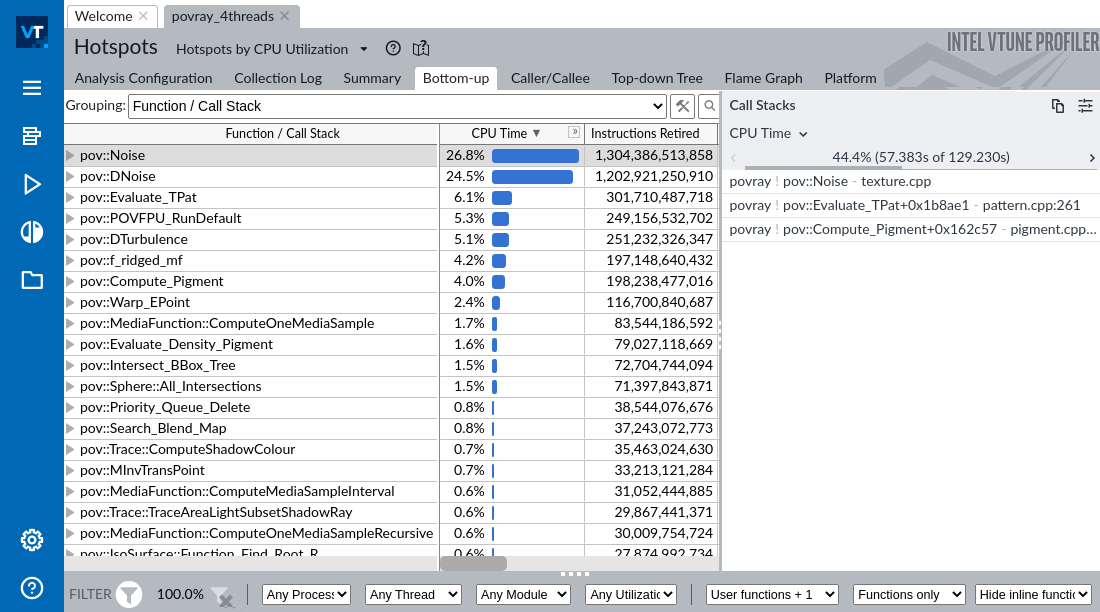
以下是 VTune 最有趣的功能的一系列截图。为了这个示例,我们使用了 POV-Ray,一个用于创建 3D 图形的光线追踪器。图 @fig:VtuneHotspots 显示了 povray 3.7 的内置基准测试的热点分析,该基准测试使用 clang14 编译器编译,并使用 -O3 -ffast-math -march=native -g 选项在英特尔 Alderlake 系统上运行(Core i7-1260P,4 个 P 核 + 8 个 E 核),并使用 4 个工作线程。
在图像的左侧部分,你可以看到工作负载中一系列热点函数,以及相应的 CPU 时间百分比和退休指令的数量。在右侧面板中,你可以看到导致调用函数 pov::Noise 的最频繁的调用栈之一。根据该截图,44.4% 的时间函数 pov::Noise 是从 pov::Evaluate_TPat 被调用的,而 pov::Evaluate_TPat 又是从 pov::Compute_Pigment 被调用的。请注意,调用栈并没有一直指向 main 函数。这是因为使用基于硬件的收集时,VTune 使用 LBR 来采样调用栈,其深度有限。在这里很可能涉及递归函数,要进一步调查,用户必须深入代码。
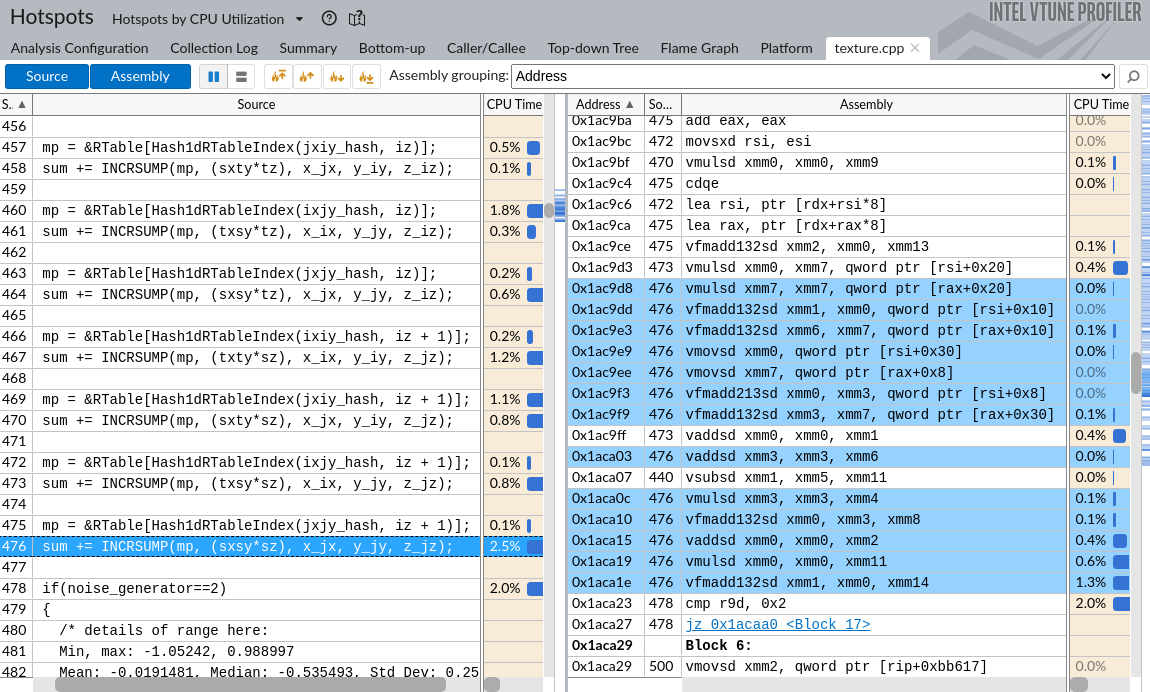
如果你双击 pov::Noise 函数,你会看到图 @fig:VtuneSourceView 所示的图像。出于篇幅考虑,只显示了最重要的列。左侧面板显示了源代码和每行代码对应的 CPU 时间。右侧,你可以看到一些汇编指令以及它们被归因的 CPU 时间。在左侧面板中高亮显示的机器指令对应于右侧面板中的第 476 行。两个面板中所有 CPU 时间百分比的总和等于归因给 pov::Noise 的总 CPU 时间,即 26.8%。
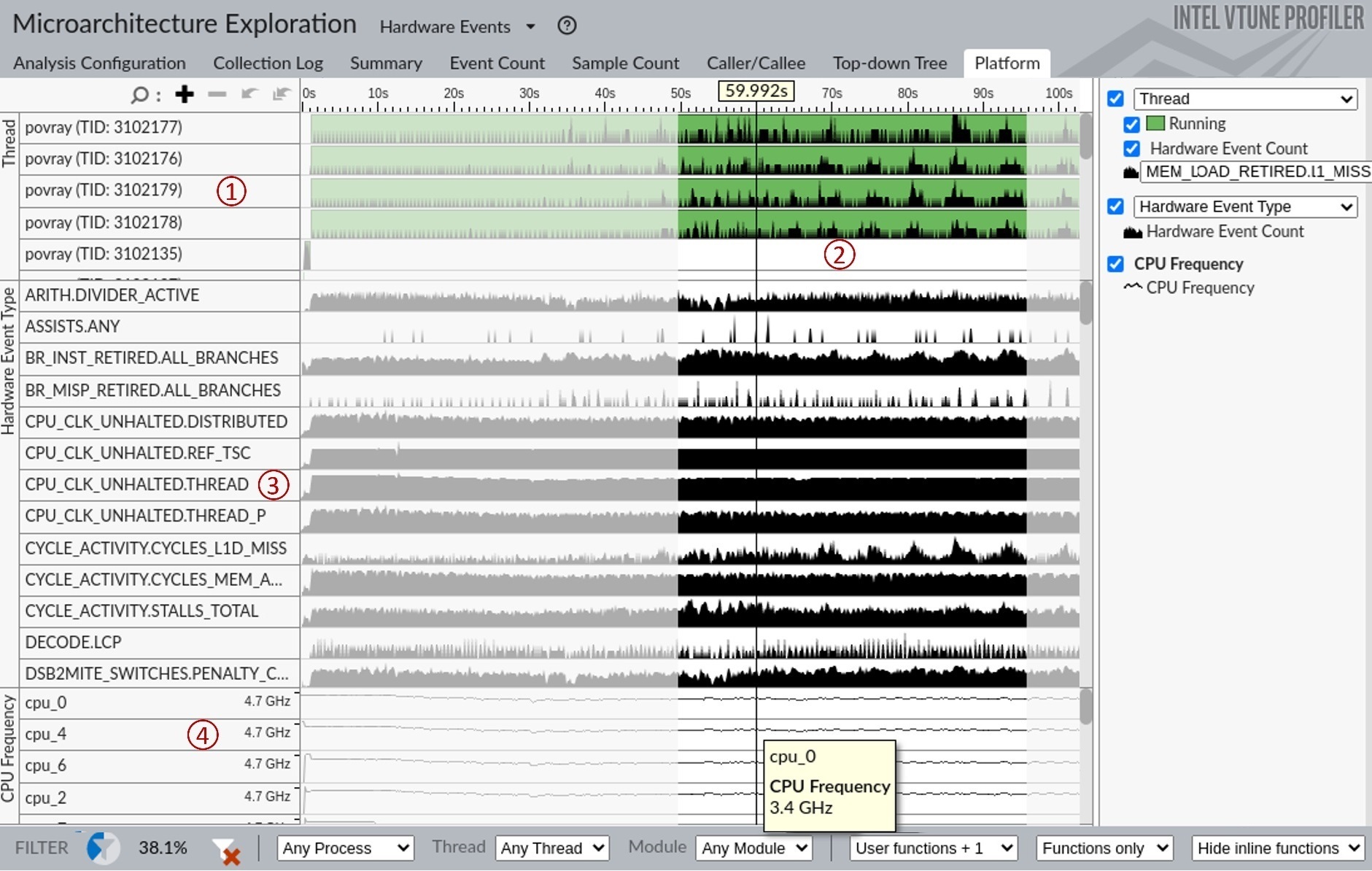
当你使用 VTune 来分析运行在英特尔 CPU 上的应用程序时,它可以收集许多不同的性能事件。为了说明这一点,我们运行了不同的分析类型,微架构探索,我们已经在上一章中展示过。那时我们用它来进行自顶向下的微架构分析,而我们也可以用它来观察原始性能事件。要访问原始事件计数,可以将视图切换为硬件事件,如图 @fig:VtuneTimelineView 所示。要启用视图切换,你需要在选项 -> 通用 -> 显示所有适用的视角 中选中标记。还有两个有用的页面,没有显示在图像上:摘要页面提供了从 CPU 计数器收集的原始性能事件的绝对数目,事件计数页面提供了相同数据的函数级别细分。读者可以自行尝试并查看这些视图。
图 @fig:VtuneTimelineView 相当繁忙,需要一些解释。顶部面板(区域 1)是一个时间轴视图,显示了我们四个工作线程随时间的行为,关于 L1 缓存未命中,以及主线程(TID:3102135)的一些微小活动,它生成所有工作线程。黑色条的高度越高,每时每刻发生的事件(在这种情况下是 L1 缓存未命中)就越多。注意到所有四个工作线程的 L1 未命中偶发性峰值。我们可以使用这个视图来观察工作负载的不同或可重复的阶段。然后为了弄清楚在那个时间执行了哪些函数,我们可以选择一个时间间隔,并点击“筛选进来”以只关注运行时间的那一部分。区域 2 就是这种过滤的一个示例。要查看更新后的函数列表,你可以转到自下而上或,在这种情况下,事件计数视图。这样的过滤和缩放功能在所有 Vtune 时间轴视图中都可用。
区域 3 显示了收集的性能事件及其随时间的分布。这次不是 perf-thread 视图,而是在所有线程上聚合的数据。除了观察执行阶段外,你还可以从中直观地提取一些有趣的信息。例如,我们可以看到执行的分支数很高(BR_INST_RETIRED.ALL_BRANCHES),但误判率相当低(BR_MISP_RETIRED.ALL_BRANCHES)。这可能导致你得出结论,分支误判不是 POV-Ray 的瓶颈。如果你向下滚动,你会看到 L3 未命中的数量为零,而 L2 缓存未命中也非常罕见。这告诉我们,在 99% 的时间里,内存访问请求由 L1 处理,并且其余部分由 L2 处理。两个观察结合起来,我们可以得出结论,应用程序很可能受到计算的限制,即 CPU 忙于计算某些东西,而不是在等待内存或从误判中恢复。
最后,底部面板(区域 4)显示了四个硬件线程的 CPU 频率图表。悬停在不同的时间片上告诉我们,这些核心的频率在 3.2GHz - 3.4GHz 区域波动。内存访问分析类型还显示了随时间变化的内存带宽(以 GB/s 为单位)。
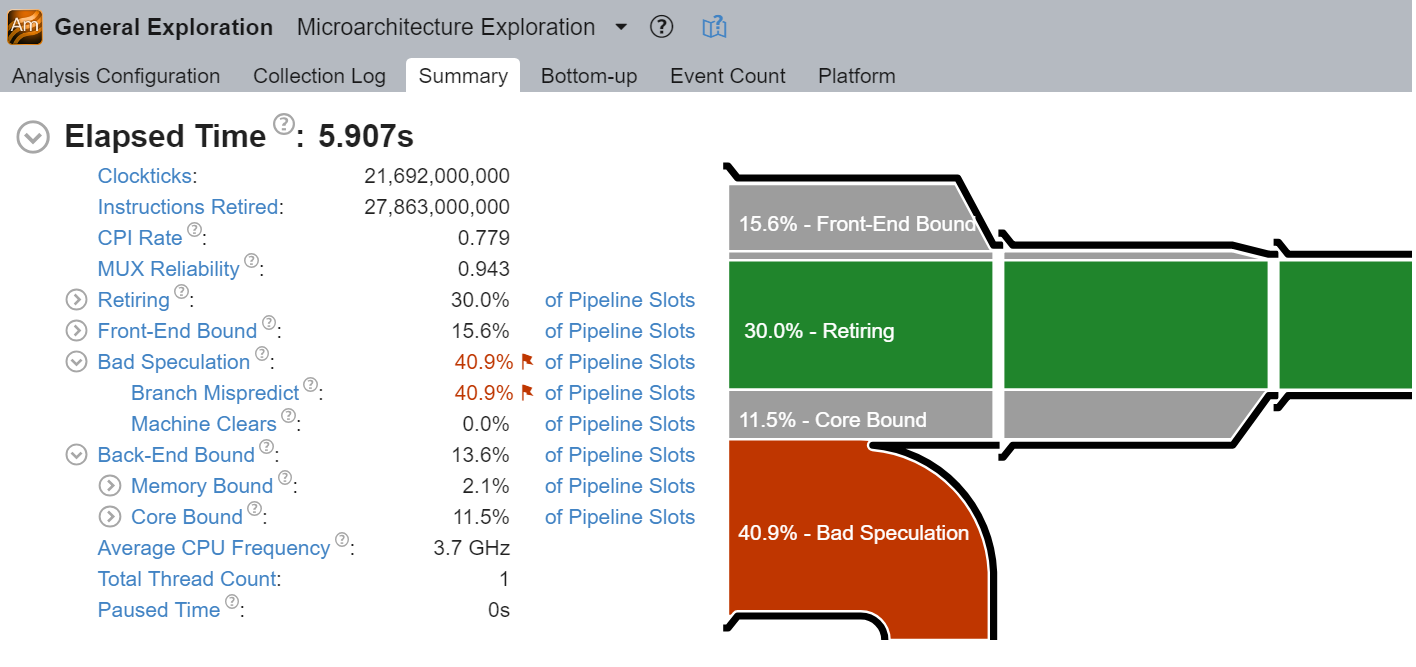
Intel® VTune™ Profiler 中的 TMA
TMA 通过最新的 Intel VTune Profiler 中的 "微架构探索"3 分析进行展示。图 @fig:Vtune_GE 显示了 7-zip 基准测试4 的分析摘要。在图表中,你可以看到由于 CPU Bad Speculation(坏的猜测)以及特别是由于误判的分支,大量的执行时间被浪费了。
该工具的美妙之处在于,你可以点击你感兴趣的指标,工具会带你到显示对该特定指标做出贡献的顶级函数的页面。例如,如果你点击 Bad Speculation 指标,你会看到类似于图 @fig:Vtune_GE_func 所示的内容。19
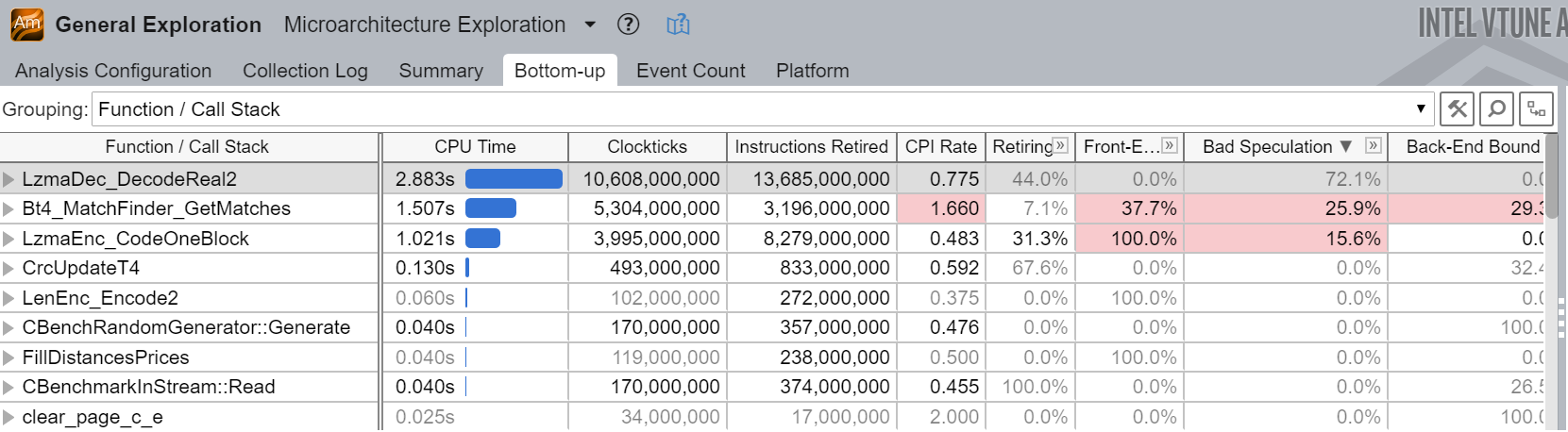
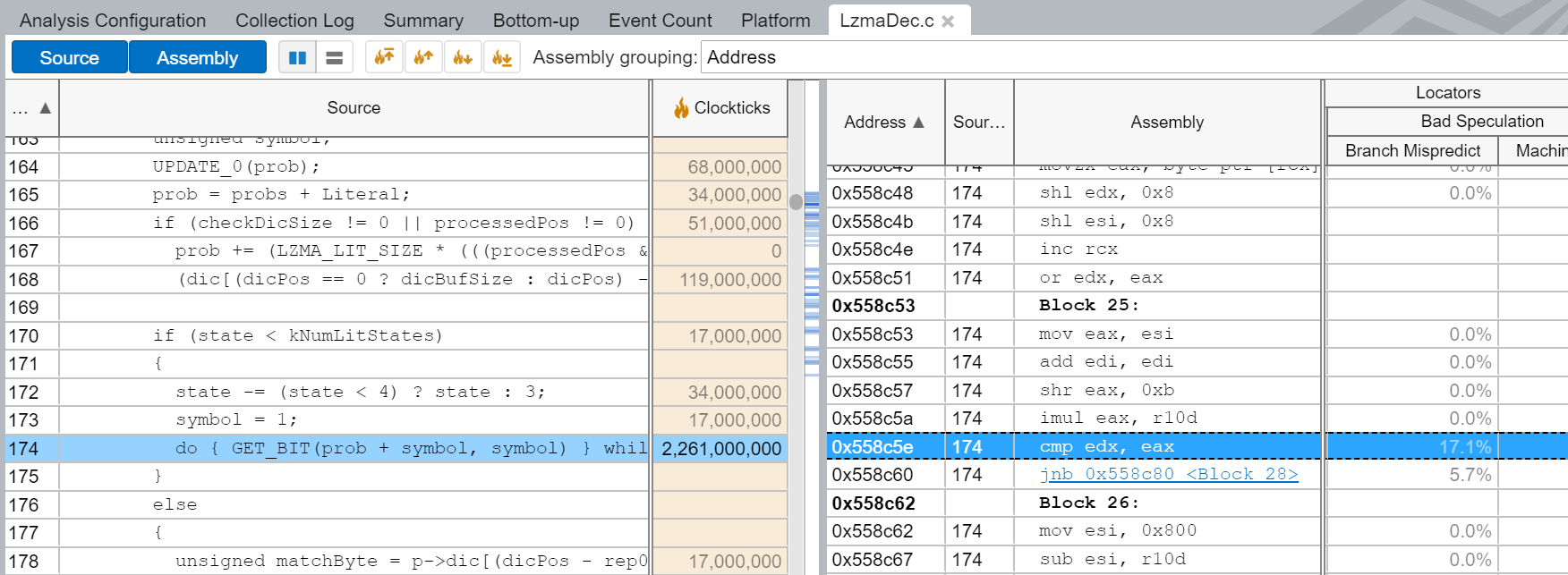
从那里,如果你双击 LzmaDec_DecodeReal2 函数,Intel® VTune™ Profiler 将带你到类似图 @fig:Vtune_GE_code 所示的源码级别视图。高亮显示的行在 LzmaDec_DecodeReal2 函数中贡献了最大数量的分支误判。
3. VTune 微架构分析 - https://software.intel.com/en-us/vtune-help-general-exploration-analysis。在 Intel® VTune Profiler 的 2019 年之前的版本中,它被称为“通用探索”分析。 ↩
4. 7zip 基准测试 - https://github.com/llvm-mirror/test-suite/tree/master/MultiSource/Benchmarks/7zip。 ↩
19. TMA指标的每个函数视图是Intel®VTune profiler独有的功能。 ↩