开发指令级并行性(ILP)
程序中的大多数指令都适合进行流水线处理并并行执行,因为它们是独立的。现代CPU实现了大量额外的硬件功能来利用这种指令级并行性(ILP)。与先进的编译器技术配合使用,这些硬件功能可以提供显著的性能改进。
乱序执行(OOO Execution)
图@fig:Pipelining中的流水线示例显示所有指令按顺序通过流水线的不同阶段移动,即按照它们在程序中出现的顺序。大多数现代CPU支持乱序执行(OOO execution),即顺序指令可以以任意顺序进入执行流水线阶段,仅受其依赖关系的限制。乱序执行的CPU仍然必须产生与所有指令按程序顺序执行相同的结果。当指令最终执行且其结果正确且可见于体系结构状态时,该指令被称为retired。为确保正确性,CPU必须按照程序顺序使所有指令退役。乱序执行主要用于避免由于依赖关系引起的停顿而导致CPU资源的低利用率,特别是在下一节中描述的超标量引擎中。
这些指令的动态调度是由复杂的硬件结构(如分数板)和技术(如寄存器重命名)启用的,以减少数据冲突。在1960年代,一些支持动态调度和乱序执行的工作包括Tomasulo算法4(在IBM360中实现)和Scoreboading5(在CDC6600中实现)。这些开创性的工作影响了所有现代CPU架构。分数板硬件用于调度按顺序退役和所有机器状态更新。它跟踪每条指令的数据依赖关系以及流水线中数据的可用位置。大多数实现都致力于在硬件成本与潜在回报之间取得平衡。通常,分数板的大小决定了硬件可以查找的独立指令的距离有多远以进行调度。
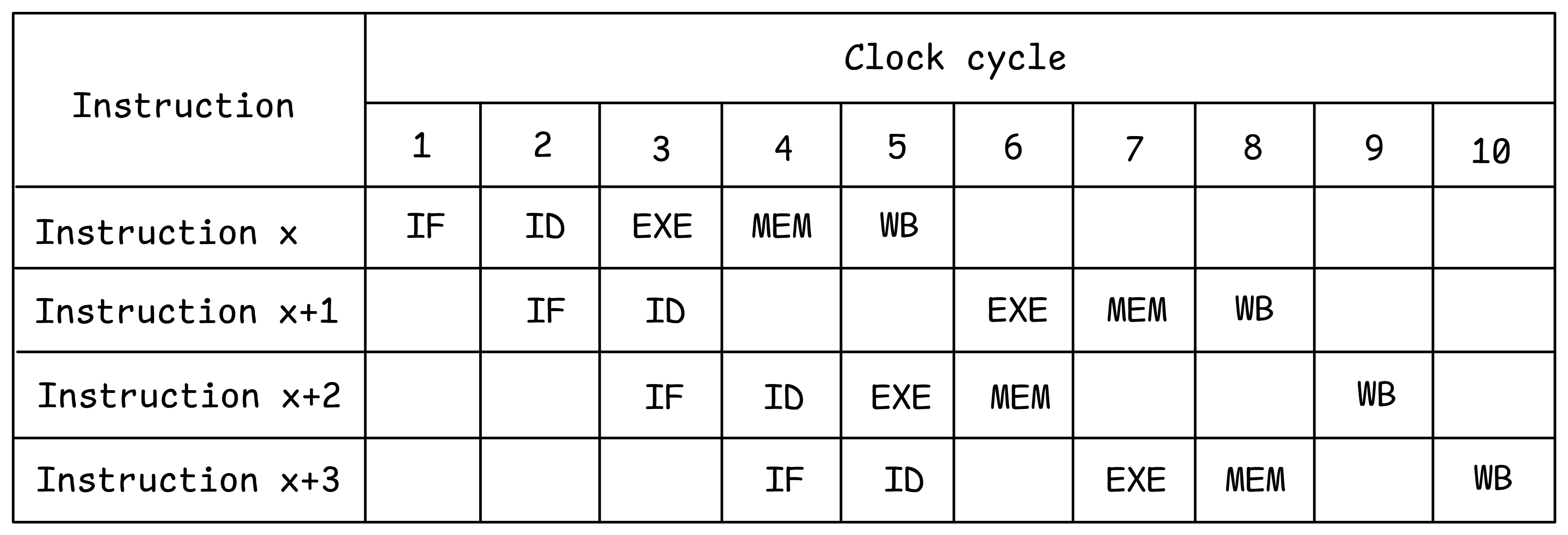
图@fig:OOO详细说明了乱序执行的概念,以一个示例为例。假设由于冲突,指令x+1在周期4和5无法执行。顺序CPU将阻塞所有后续指令进入EXE流水线阶段。在具有乱序执行的CPU中,不具有任何冲突(例如,指令x+2)的后续指令可以进入并完成其执行。所有指令仍然按顺序退役,即指令按程序顺序完成WB阶段。
超标量引擎和VLIW
大多数现代CPU都是超标量的,即它们可以在给定周期内发出多个指令。发出宽度是在同一周期内发出的指令的最大数量。当前一代CPU的典型发出宽度范围为2到6。为了确保正确平衡,这种超标量引擎还具有多个执行单元和/或流水线执行单元。CPU还将超标量功能与深度流水线和乱序执行结合起来,以提取给定软件的最大ILP。
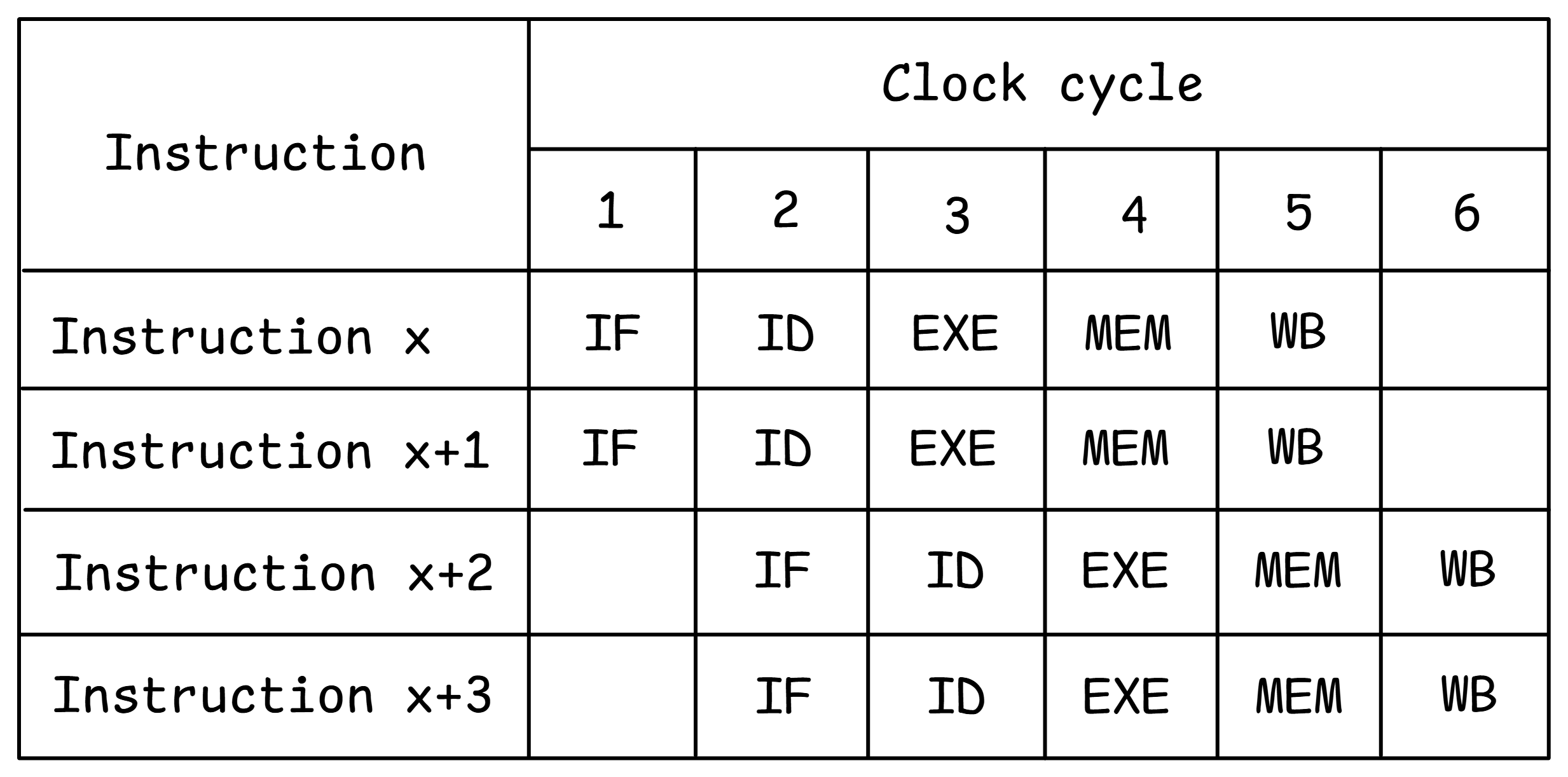
图@fig:SuperScalar显示了支持2路发出宽度的CPU的示例,即在每个周期内,每个流水线阶段处理两条指令。超标量CPU通常支持多个独立执行单元,以确保指令在流水线中无冲突地流动。除了流水线化之外,复制执行单元还进一步提高了机器的性能。
像英特尔Itanium这样的体系结构将调度超标量、多执行单元机器的负担从硬件转移到了编译器,使用了一种称为VLIW(Very Long Instruction Word)的技术。其理念是通过要求编译器选择正确的指令组合来使机器保持完全利用。编译器可以使用软件流水线和循环展开等技术,查看远远超出硬件结构合理支持范围的指令,以找到正确的ILP。
推测执行
正如前一节所述,如果指令在分支条件解析之前被停顿,控制冲突可能会导致流水线的显著性能损失。为了避免这种性能损失,一种技术是使用硬件分支预测逻辑来预测分支的可能方向,并允许从预测路径执行指令(推测执行)。
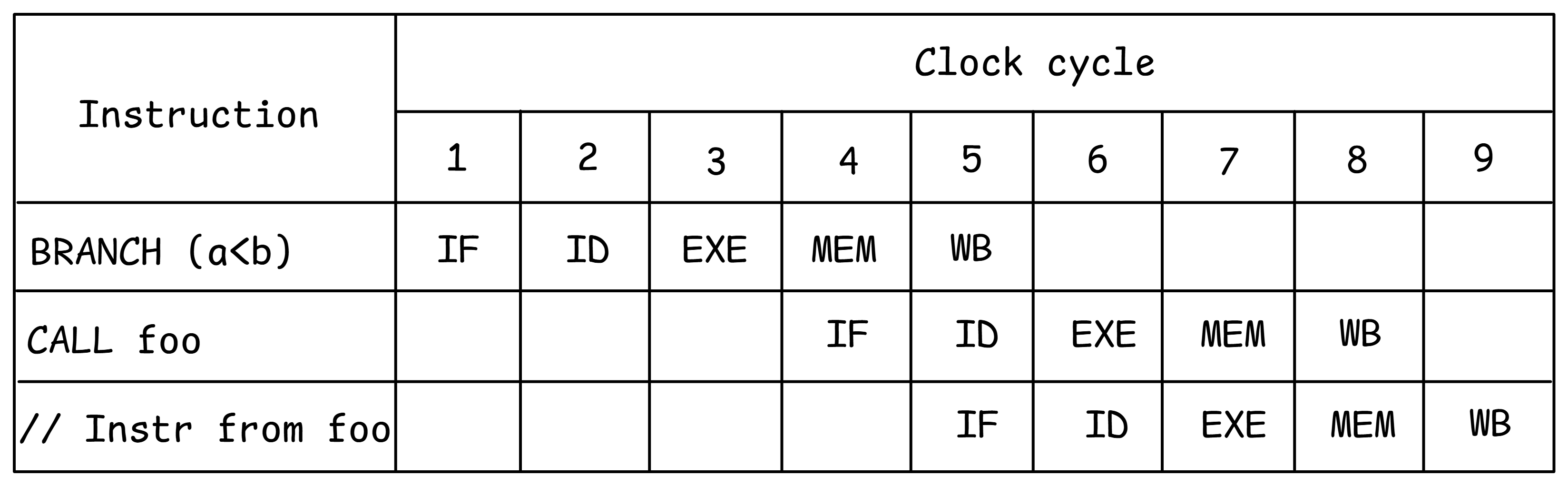
让我们考虑@lst:Speculative中的短代码示例。为了让处理器了解它应该执行哪个函数,它应该知道条件a < b是false还是true。如果不知道,CPU将等待分支指令的结果,如图@fig:NoSpeculation所示。
代码示例:推测执行
if (a < b)
foo();
else
bar();
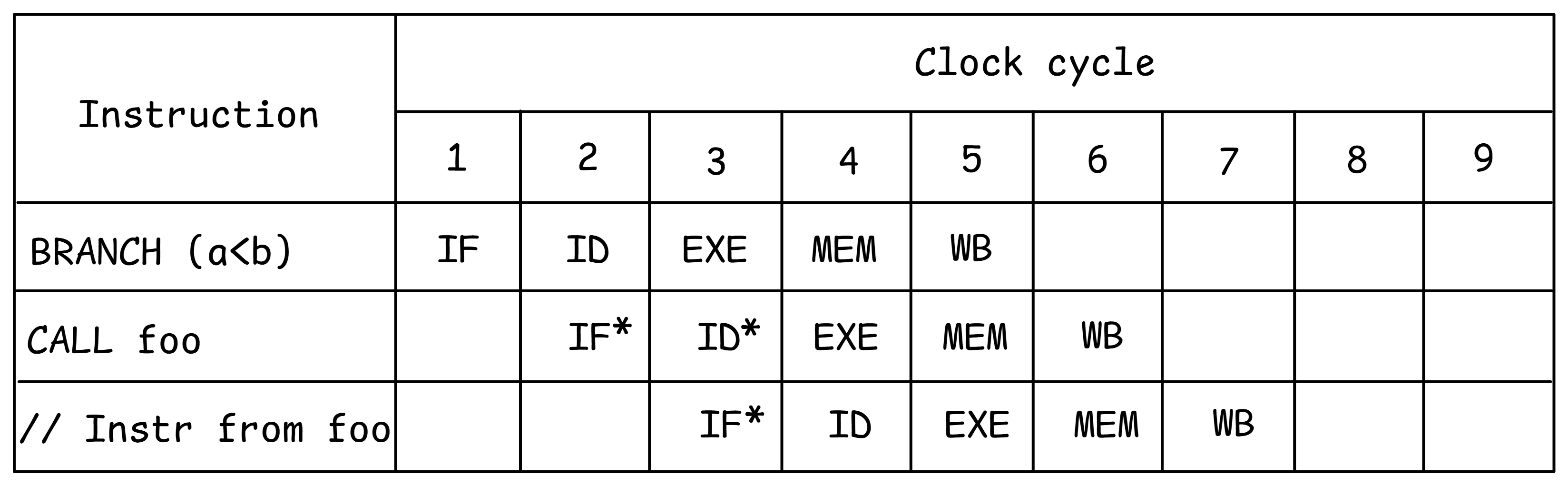
使用推测执行,CPU猜测分支的结果,并开始处理所选择路径的指令。假设处理器预测条件a < b将被评估为true。它继续执行而不等待分支结果,并推测性地调用函数foo(见图@fig:SpeculativeExec,推测工作用*标记)。直到条件解析为止,机器状态变化才能被提交,以确保机器的体系结构状态永远不会受到推测执行指令的影响。在上面的例子中,分支指令比较了两个标量值,这很快。但实际上,分支指令可能取决于从内存加载的值,这可能需要数百个周期。如果预测是正确的,它将节省大量周期。然而,有时预测是错误的,应该调用函数bar。在这种情况下,推测执行的结果必须被取消并丢弃。这称为分支错误预测的惩罚,我们将在[@sec:BbMisp]中讨论。
为了跟踪推测的进展,现代CPU支持一种称为重新排序缓冲区(ROB)的结构。ROB维护所有指令执行的状态,并按顺序退役指令。推测执行的结果写入ROB,并按程序流程的相同顺序提交给体系结构寄存器,仅在推测是正确的情况下。CPU还可以将推测执行与乱序执行相结合,并使用ROB来跟踪推测和乱序执行。
分支预测
正如我们刚才看到的,正确的预测极大地提高了执行效率,因为它们允许CPU在没有前一条指令结果的情况下继续前进。然而,错误的推测通常会导致昂贵的性能惩罚。现代CPU采用了复杂的动态分支预测机制,提供非常高的准确性,并能够适应分支行为的动态变化。有三种类型的分支可能需要以特殊方式处理:
- 无条件跳转和直接调用:它们最容易预测,因为它们总是被执行并且每次都以相同的方向执行。
- 条件分支:它们有两个潜在的结果:被执行或不被执行。被执行的分支可以向前或向后跳转。前向条件分支通常用于生成
if-else语句,其不被执行的可能性很高,因为通常表示错误检查代码。后向条件跳转经常出现在循环中,并用于转到循环的下一次迭代;此类分支通常被执行。 - 间接调用和跳转:它们具有许多目标。间接跳转或间接调用可以生成
switch语句、函数指针或virtual函数。函数返回也值得关注,因为它也有许多潜在的目标。
大多数预测算法基于分支的先前结果。分支预测单元(BPU)的核心是分支目标缓冲区(BTB),它为每个分支缓存目标地址。预测算法每个周期都要查询BTB,以生成下一个要提取指令的地址。CPU使用该新地址提取下一个指令块。如果在当前提取块中没有识别出分支,则提取的下一个地址将是下一个顺序对齐的提取块(顺序提取)。
无条件分支不需要预测;我们只需要在BTB中查找目标地址。记住,每个周期BPU都需要生成下一个地址,以避免流水线停滞。我们可以仅从指令编码中提取地址,但这样我们必须等到解码阶段结束,这将在流水线中引入一个气泡并使事情变慢。因此,在提取分支时必须确定下一个提取地址。
对于条件分支,我们首先需要预测分支是否被执行。如果未执行,则我们会顺序执行,并且无需查找目标。否则,我们将在BTB中查找目标地址。条件分支通常占据总分支的最大部分,并且是生产软件中错误预测的主要来源。对于间接分支,我们需要选择可能的目标之一,但是预测算法可以与条件分支非常相似。
所有预测机制都试图利用两个重要原则,这与我们稍后将讨论的缓存类似:
- 时间相关性:分支的解决方式可能是下次执行时解决方式的很好的预测器。这也称为局部相关性。
- 空间相关性:几个相邻的分支可能以高度相关的方式解决(执行的首选路径)。这也称为全局相关性。
最佳的准确性通常通过同时利用局部和全局相关性来实现。因此,我们不仅查看当前分支的结果历史,还将其与其他分支的结果相关联。
另一种常见的技术是混合预测。其思想是一些分支具有偏向行为。例如,如果条件分支99.9%的时间都朝着一个方向走,就没有必要使用复杂的预测器并污染其数据结构。可以使用一个简单得多的机制。另一个示例是循环分支。如果分支具有循环行为,则可以使用专用的循环预测器进行预测,该预测器将记住循环通常执行的迭代次数。
如今,最先进的预测主要由类似TAGE [@Seznec2006]或感知器-based [@Jimenez2001]的预测器主导。冠军6分支预测器在每1000条指令中不到3次错误预测。现代CPU在大多数工作负载上通常达到超过95%的预测率。
4. Tomasulo algorithm - https://en.wikipedia.org/wiki/Tomasulo_algorithm. ↩
5. Score boarding - https://en.wikipedia.org/wiki/Scoreboarding. ↩
6. 第五届冠军分支预测大赛 - https://jilp.org/cbp2016 ↩