附录 D. Intel 处理器跟踪
Intel 处理器跟踪(PT)是一种 CPU 功能,通过将数据包编码为高度压缩的二进制格式记录程序执行,可以在每条指令上附带时间戳,用于重构执行流。PT 具有广泛的覆盖范围和相对较小的开销,1 通常低于 5%。其主要用途是事后分析和排查性能故障的根本原因。
工作流程
与采样技术类似,PT 不需要对源代码进行任何修改。收集跟踪的全部需要就是在支持 PT 的工具下运行程序。一旦启用了 PT 并启动了基准测试,分析工具就会开始将跟踪数据包写入 DRAM。
与 LBR(Last Branch Records)类似,Intel PT 通过记录分支来工作。在运行时,每当 CPU 遇到任何分支指令时,PT 就会记录该分支的结果。对于简单的条件跳转指令,CPU 会记录其是否被执行(T)或未被执行(NT),仅使用 1 位。对于间接调用,PT 将记录目标地址。请注意,由于我们静态知道无条件分支的目标,因此会忽略无条件分支。
示例中展示了一小段指令序列的编码,如图 @fig:PT_encoding 所示。诸如 PUSH、MOV、ADD 和 CMP 等指令被忽略,因为它们不会改变控制流。但是,JE 指令可能会跳转到 .label,因此需要记录其结果。稍后存在一个间接调用,需要保存目标地址。
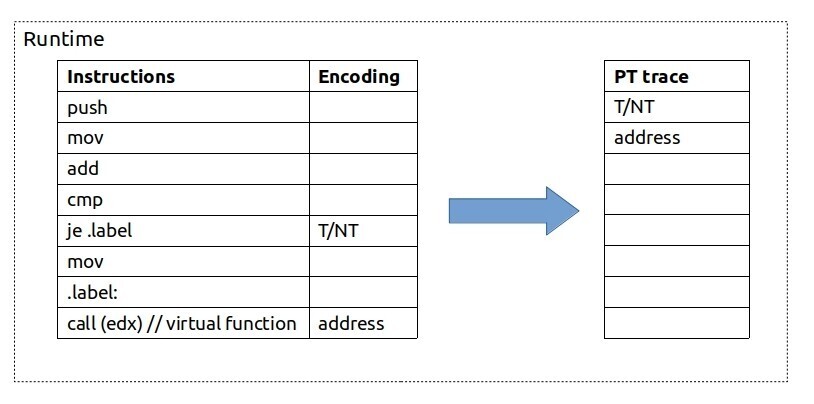
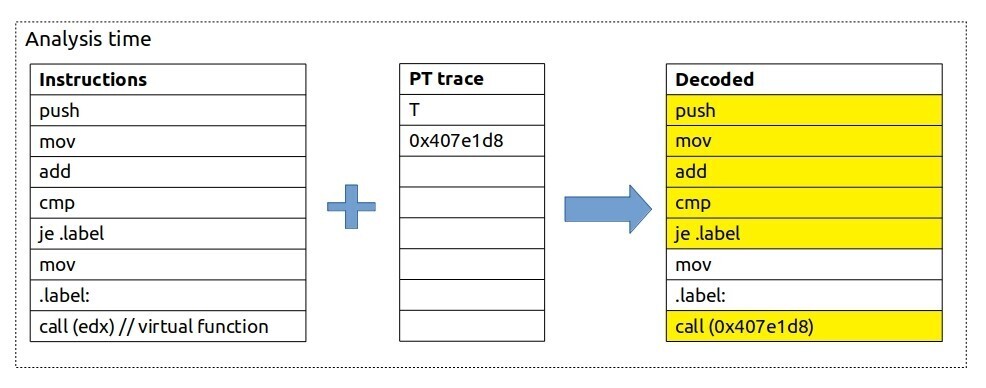
在分析时,我们需要将应用程序二进制文件和收集到的 PT 跟踪数据合并在一起。一个软件解码器需要应用程序二进制文件来重构程序的执行流程。它从入口点开始,然后使用收集到的跟踪数据作为查找参考来确定控制流。图 @fig:PT_decoding 展示了 Intel 处理器跟踪的解码示例。假设 PUSH 指令是应用程序二进制文件的入口点。然后 PUSH、MOV、ADD 和 CMP 等指令被按原样重构,而无需查看编码的跟踪数据。稍后,软件解码器遇到一个 JE 指令,这是一个条件分支,需要查找结果。根据图 @fig:PT_decoding 中的跟踪数据,JE 被执行(T),因此我们跳过下一个 MOV 指令并转到 CALL 指令。同样,CALL(edx) 是一个改变控制流的指令,因此我们在编码的跟踪数据中查找目标地址,即 0x407e1d8。在我们的程序运行时执行的指令用黄色突出显示。请注意,这是程序执行的 精确 重构;我们没有跳过任何指令。稍后,我们可以使用调试信息将汇编指令映射回源代码,并记录逐行执行的源代码日志。
时间数据包
使用 Intel PT,不仅可以跟踪执行流,还可以跟踪时间信息。除了保存跳转目标外,PT 还可以发出时间数据包。图 @fig:PT_timings 提供了时间数据包如何用于恢复指令时间戳的可视化示例。与前面的示例类似,我们首先看到 JNZ 没有被执行,因此我们将其及其上方的所有指令的时间戳更新为 0 纳秒。然后我们看到一个 2 纳秒的时间更新和 JE 被执行,因此我们将其及其上方的所有指令(以及下方的 JNZ)的时间戳更新为 2 纳秒。之后是一个间接调用,但没有附加时间数据包,因此我们不更新时间戳。然后我们看到经过了 100 纳秒,并且 JB 没有被执行,因此我们将其上方的所有指令的时间戳更新为 102 纳秒。
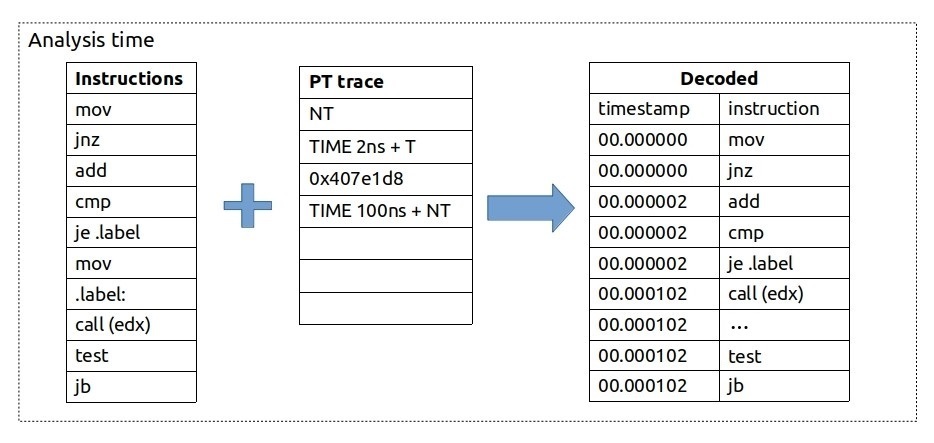
在图 @fig:PT_timings 中展示的示例中,指令数据(控制流)完全准确,但时间信息不太准确。显然,CALL(edx)、TEST 和 JB 指令并不是同时发生的,但我们没有更准确的时间信息。具有时间戳使我们能够将程序的时间间隔与系统中的另一个事件对齐,并且很容易与挂钟时间进行比较。在某些实现中,跟踪时间可以通过一个循环精确模式进一步改进,其中硬件记录了常规数据包之间的周期计数(有关更多详细信息,请参阅 [@IntelOptimizationManual,第 3C 卷,第 36 章]).
收集和解码跟踪
使用 Linux 的 perf 工具可以轻松地收集 Intel PT 跟踪数据:
$ perf record -e intel_pt/cyc=1/u ./a.out
在上面的命令行中,我们要求 PT 机制每个周期更新一次时间信息。但是很可能,这不会显著增加我们的准确性,因为只有在与另一个控制流数据包配对时,才会发送时间数据包。
收集完跟踪数据后,可以通过执行以下命令来获取原始的 PT 跟踪数据:
$ perf report -D > trace.dump
PT 在发出时间数据包之前会捆绑最多 6 个条件分支。自 Intel Skylake CPU 一代以来,时间数据包包含自上一个数据包以来经过的周期数。然后,如果我们查看 trace.dump,可能会看到类似以下的内容:
000073b3: 2d 98 8c TIP 0x8c98 // 目标地址(IP)
000073b6: 13 CYC 0x2 // 时间更新
000073b7: c0 TNT TNNNNN (6) // 6 个条件分支
000073b8: 43 CYC 0x8 // 经过 8 个周期
000073b9: b6 TNT NTTNTT (6)
以上是显示的原始 PT 数据包,对性能分析并不是非常有用。要将处理器跟踪数据解码为人类可读形式,可以执行以下命令:
$ perf script --ns --itrace=i1t -F time,srcline,insn,srccode
以下是可能获得的解码跟踪的示例:
时间戳 源代码行 指令 源代码
...
253.555413143: a.cpp:24 call 0x35c foo(arr, j);
253.555413143: b.cpp:7 test esi, esi for (int i = 0; i <= n; i++)
253.555413508: b.cpp:7 js 0x1e
253.555413508: b.cpp:7 movsxd rsi, esi
...
以上只是来自长时间执行日志的一个小片段。在此日志中,我们有跟踪 每个 执行的指令,而我们的程序正在运行时。我们可以真正观察程序所采取的每一步。这是进一步功能和性能分析的非常强大的基础。
使用情况
- 分析性能故障:由于 PT 捕获了整个指令流,因此可以分析应用程序未响应的小时间段内发生了什么。在 easyperf 博客的一篇文章2中可以找到更详细的示例。
- 事后调试:PT 跟踪数据可以由像
gdb这样的传统调试器进行回放。除此之外,PT 还提供了调用堆栈信息,即使堆栈已损坏,该信息也始终有效。3可以在远程机器上收集 PT 跟踪数据,然后在离线状态下进行分析。这在问题难以重现或系统访问受限时特别有用。 - 审查程序的执行:
- 我们可以立即知道是否未执行某个代码路径。
- 多亏了时间戳,可以计算在尝试获取锁时等待的时间,等等。
- 通过检测特定指令模式进行安全缓解。
磁盘空间和解码时间
即使考虑到跟踪的压缩格式,编码后的数据也会占用大量磁盘空间。 通常,每个指令少于 1 个字节,但考虑到 CPU 执行指令的速度,它仍然很多。 取决于工作负载,CPU 以 100 MB/s 的速度编码 PT 非常常见。 解码的跟踪可能很容易增加十倍(~1GB/s)。 这使得 PT 不适用于长时间运行的工作负载。 但即使是在大工作负载上,运行一小段时间也是负担得起的。 在这种情况下,用户只能在故障发生期间附加到正在运行的进程。 或者他们可以使用循环缓冲区,新跟踪将覆盖旧跟踪,即始终拥有最近 10 秒左右的跟踪。
用户可以通过多种方式进一步限制收集。 他们可以限制仅在用户/内核空间代码上收集跟踪。 此外,还有一个地址范围过滤器,因此可以动态地选择加入和退出跟踪以限制内存带宽。 这使我们能够跟踪单个函数甚至单个循环。
解码 PT 跟踪可能需要很长时间。 在 Intel Core i5-8259U 机器上,对于运行 7 毫秒的工作负载,编码的 PT 跟踪大约消耗 1MB 的磁盘空间。 使用 perf script 解码此跟踪需要大约 20 秒。 使用 perf script -F time,ip,sym,symoff,insn 的解码输出大约占用 1.3GB 的磁盘空间。 截至 2020 年 2 月,使用 perf script -F 以及 +srcline 或 +srccode 解码跟踪变得非常慢,不适合日常使用。 应该改进 Linux perf 的实现。
英特尔 PT 参考资料和链接
- 英特尔® 64 和 IA-32 架构软件开发人员手册 [@IntelOptimizationManual,第 3 卷 C,第 36 章]。
- 白皮书“硬件辅助指令分析和延迟检测” [@IntelPTPaper]。
- Andi Kleen 在 LWN 上的文章,网址: https://lwn.net/Articles/648154。
- 英特尔 PT 微型教程,网址: https://sites.google.com/site/intelptmicrotutorial/。
- simple_pt: Linux 上的简单英特尔 CPU 处理器跟踪,网址: https://github.com/andikleen/simple-pt。
- Linux 内核中的英特尔 PT 文档,网址: https://github.com/torvalds/linux/blob/master/tools/perf/Documentation/intel-pt.txt。
- 英特尔处理器跟踪备忘单,网址: http://halobates.de/blog/p/410。
1. 有关英特尔 PT 额外开销的更多信息,请参见 [@IntelPTPaper]。 ↩
2. 使用英特尔 PT 分析性能故障 - https://easyperf.net/blog/2019/09/06/Intel-PT-part3。 ↩
3. 使用英特尔 PT 进行事后调试 - https://easyperf.net/blog/2019/08/30/Intel-PT-part2。 ↩