性能扩展和开销
当处理单线程应用程序时,优化程序的某个部分通常会对性能产生积极的影响。然而,对于多线程应用程序来说,情况并非总是如此。有些应用程序中,线程 A 执行一个长时间运行的操作,而线程 B 则早早地完成了其任务,只是等待线程 A 完成。无论我们如何改进线程 B,应用程序的延迟都不会减少,因为它将受到运行时间较长的线程 A 的限制4。
这种影响被广泛称为安达尔定律6,它规定了并行程序的加速度受其串行部分的限制。图 @fig:MT_AmdahlsLaw 描绘了理论上的加速度极限,作为处理器数量的函数。对于一个其中有 75% 是并行的程序,加速度因子将收敛到 4。
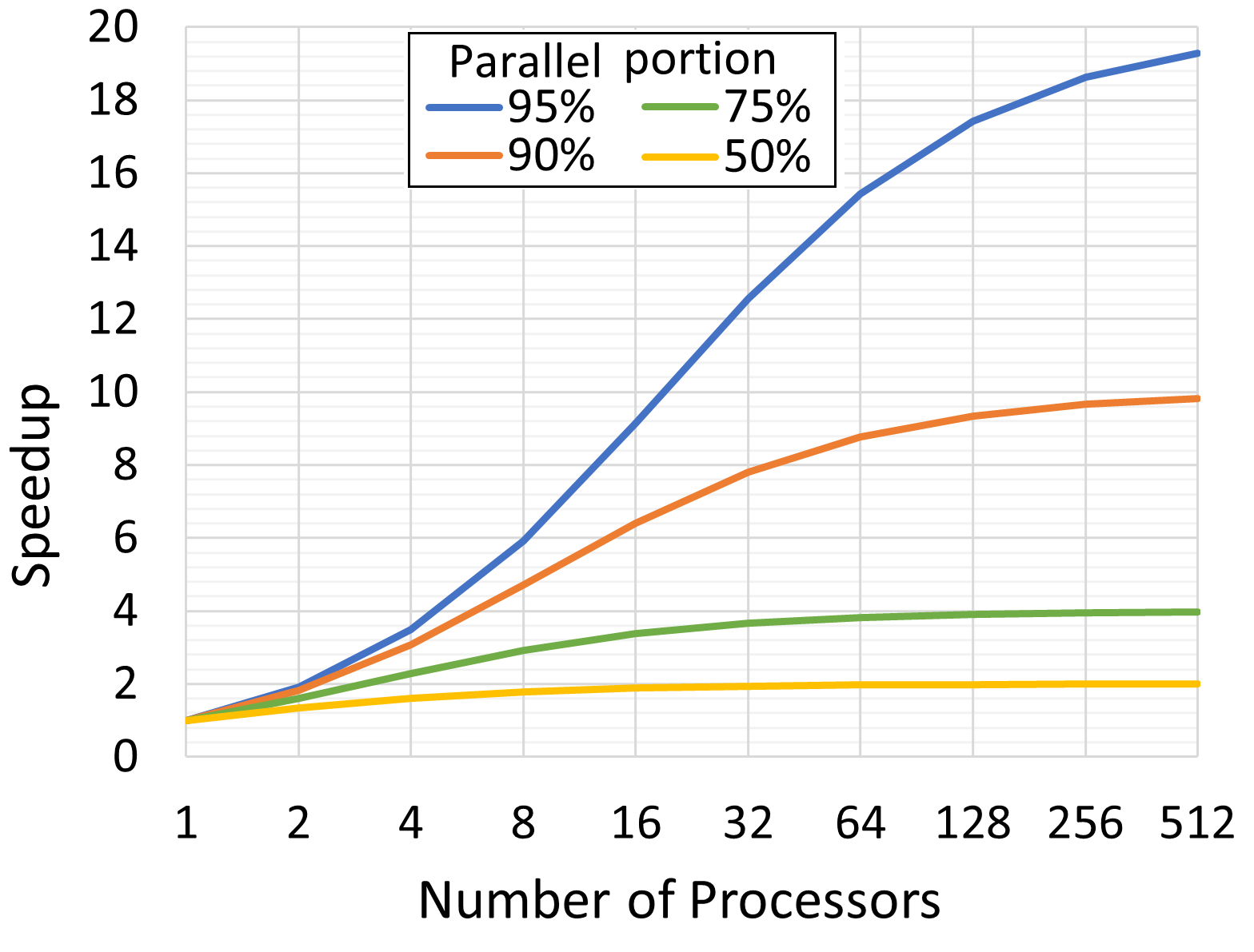
图 @fig:MT_Scaling 显示了来自Starbench 并行基准套件的 h264dec 基准测试的性能扩展情况。我在拥有 4 个核心/8 个线程的 Intel Core i5-8259U 上进行了测试。请注意,在使用了 4 个线程之后,性能并没有显著提高。很可能,获取一个拥有更多核心的 CPU 不会提高性能。7


在 Intel Core i5-8259U 上的 h264dec 基准测试的性能扩展和开销。
事实上,进一步增加计算节点可能会导致逆向加速。这种效应由 Neil Gunther 解释为通用可扩展性法则(Universal Scalability Law)8(USL),它是安达尔定律的一个扩展。USL 描述了计算节点(线程)之间的通信作为性能的另一个限制因素。随着系统的扩展,开销开始阻碍性能的增长。超过临界点后,系统的能力开始下降(见图 @fig:MT_USL)。USL 被广泛用于对系统的容量和可扩展性建模。
*.](https://raw.githubusercontent.com/dendibakh/perf-book/main/img/mt-perf/USL.jpg)
由 USL 描述的减速是由多种因素驱动的。首先,随着计算节点数量的增加,它们开始竞争资源(争用)。这导致额外的时间用于同步这些访问。另一个问题是资源在许多工作线程之间共享。我们需要在许多工作线程之间保持共享资源的一致状态(一致性)。例如,当多个工作线程频繁地更改全局可见对象时,这些更改需要广播到使用该对象的所有节点。突然之间,由于额外的一致性维护需求,通常的操作开始花费更多的时间来完成。在 Intel Core i5-8259U 上,h264dec 基准测试的通信开销可以在图 @fig:MT_cycles 中观察到。请注意,随着我们为任务分配超过 4 个线程,图表表明开销以经过的核心周期数的形式增加。9
优化多线程应用程序不仅涉及到本书迄今描述的所有技术,还涉及到检测和减轻竞争和一致性的前述影响。下一小节将描述针对调优多线程程序的这些额外挑战的技术。
4. 这不一定总是成立。例如,资源在线程/核心之间共享(如缓存)可能限制扩展性。此外,计算密集型基准测试往往只能在物理(而不是逻辑)核心数量上进行扩展,因为两个相邻的硬件线程共享同一个执行引擎。 ↩
6. Amdahl's law - https://en.wikipedia.org/wiki/Amdahl's_law. ↩
7. 然而 ,它会受益于频率更高的 CPU。 ↩
8. 通用可扩展性法则 - http://www.perfdynamics.com/Manifesto/USLscalability.html#tth_sEc1。 ↩
9. 使用 5 和 6 个工作线程时,已完成的指令数量出现了一个有趣的峰值。这应该通过对工作负载进行分析来进行调查。 ↩